
热门标签
热门文章
- 1每周一刷——从斐波那契数列到动态规划
- 2【Python报错&解决】总结记录(1)_error: torch has an invalid wheel, .dist-info dire
- 3Mac与window上谷歌网页滚动截屏(网页整页截屏)_mac chrome浏览器滑动截图
- 4嵌入式1. arm 架构分析_哈佛架构和arm架构
- 5第一次学习Halcon的案例_halcon入门实例
- 6网络状态判断工具类_网络状态监测工具
- 7BLE文档_bledevice
- 8IBeginDragHandler、IDragHandler 和 IEndDragHandler 介绍_idraghandler, ibegindraghandler, ienddraghandler
- 9mysql(一)
- 10有没有大神能够逐行解释一下代码?Delphi_::315b4df935f4775ef5033a4833a9e0e1:7004
当前位置: article > 正文
搭建完全分布式Hadoop_hadoop分布式搭建步骤
作者:很楠不爱3 | 2024-05-18 01:41:09
赞
踩
hadoop分布式搭建步骤
文章目录
一、Hadoop集群规划
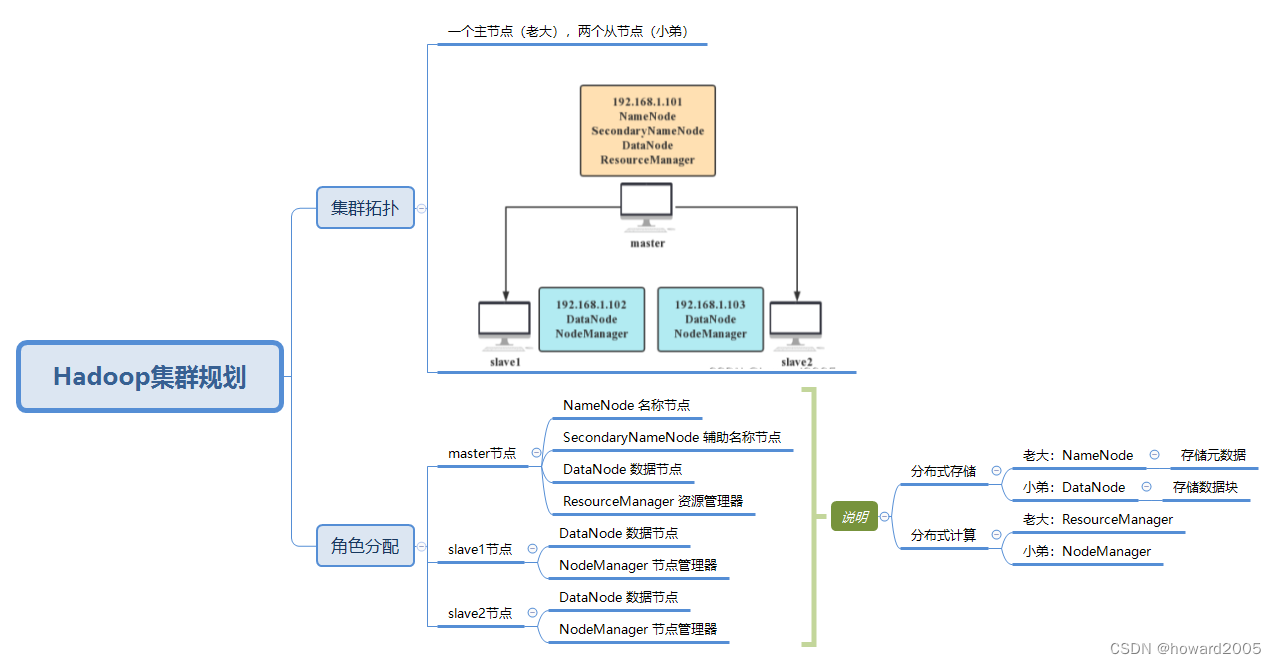
二、在主节点上配置Hadoop
(一)登录虚拟机
- 登录三个虚拟机
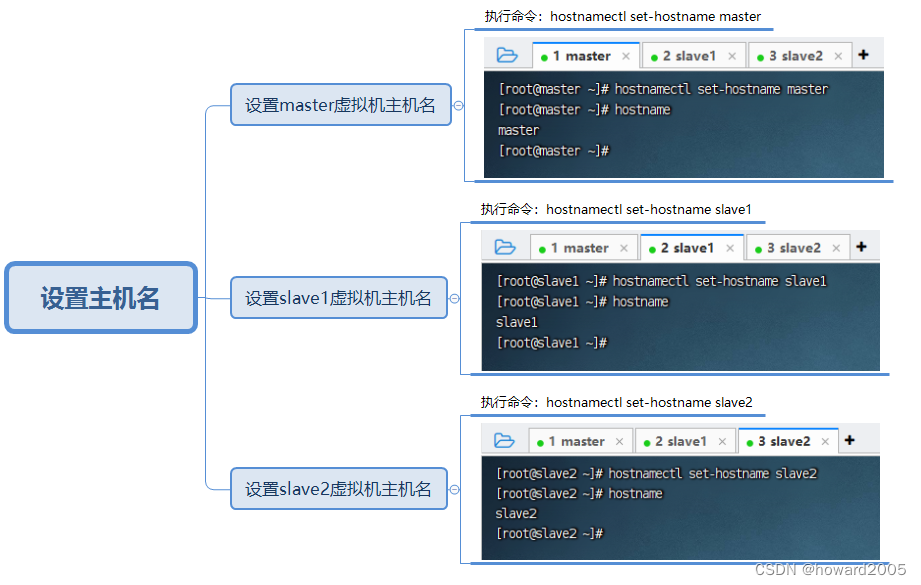
(二)设置主机名
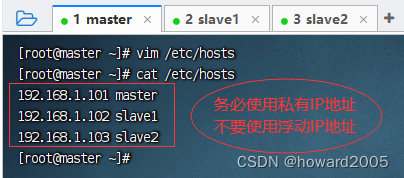
(三)主机名与IP地址映射
- 执行命令:
vim /etc/hosts
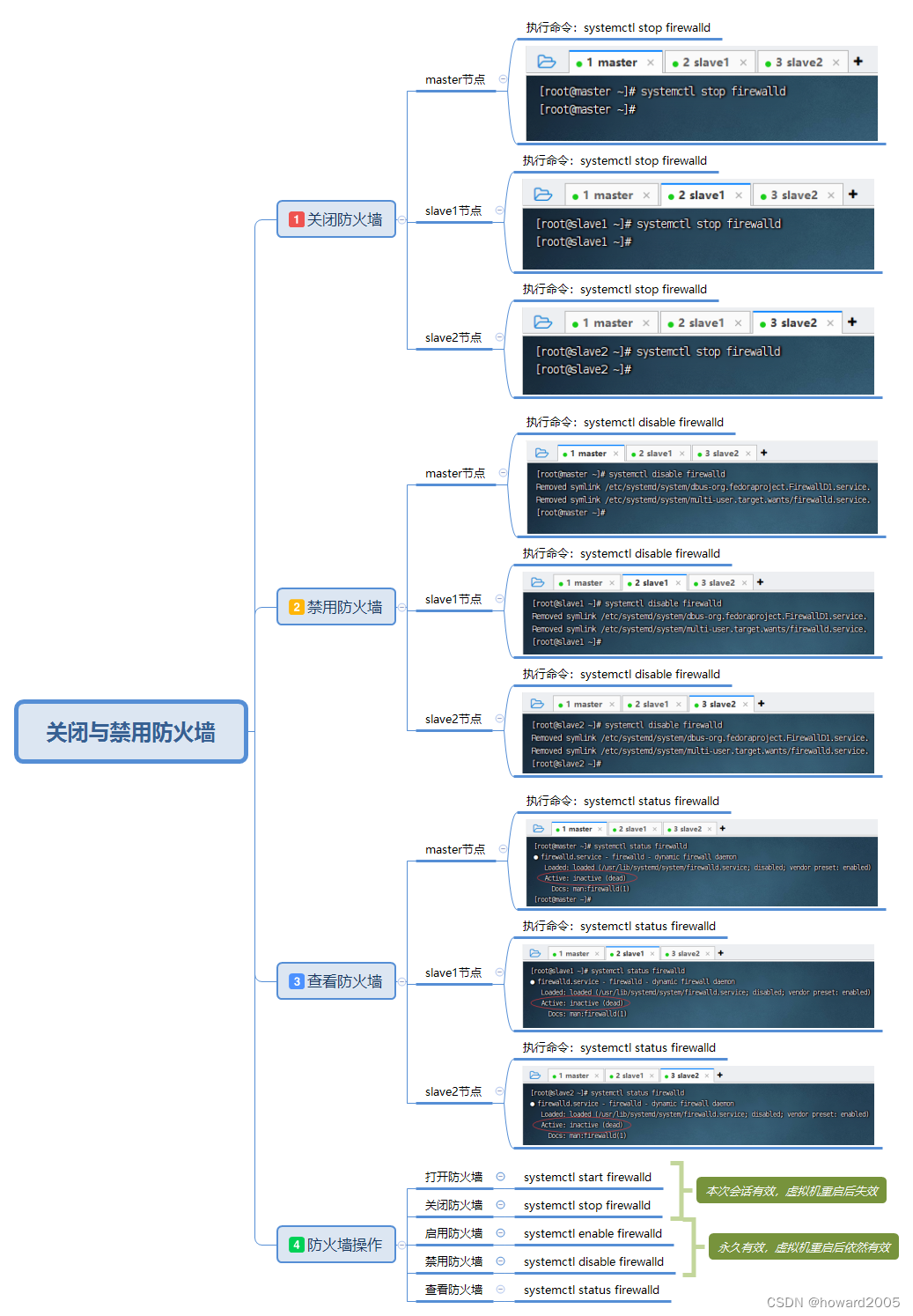
(四)关闭与禁用防火墙
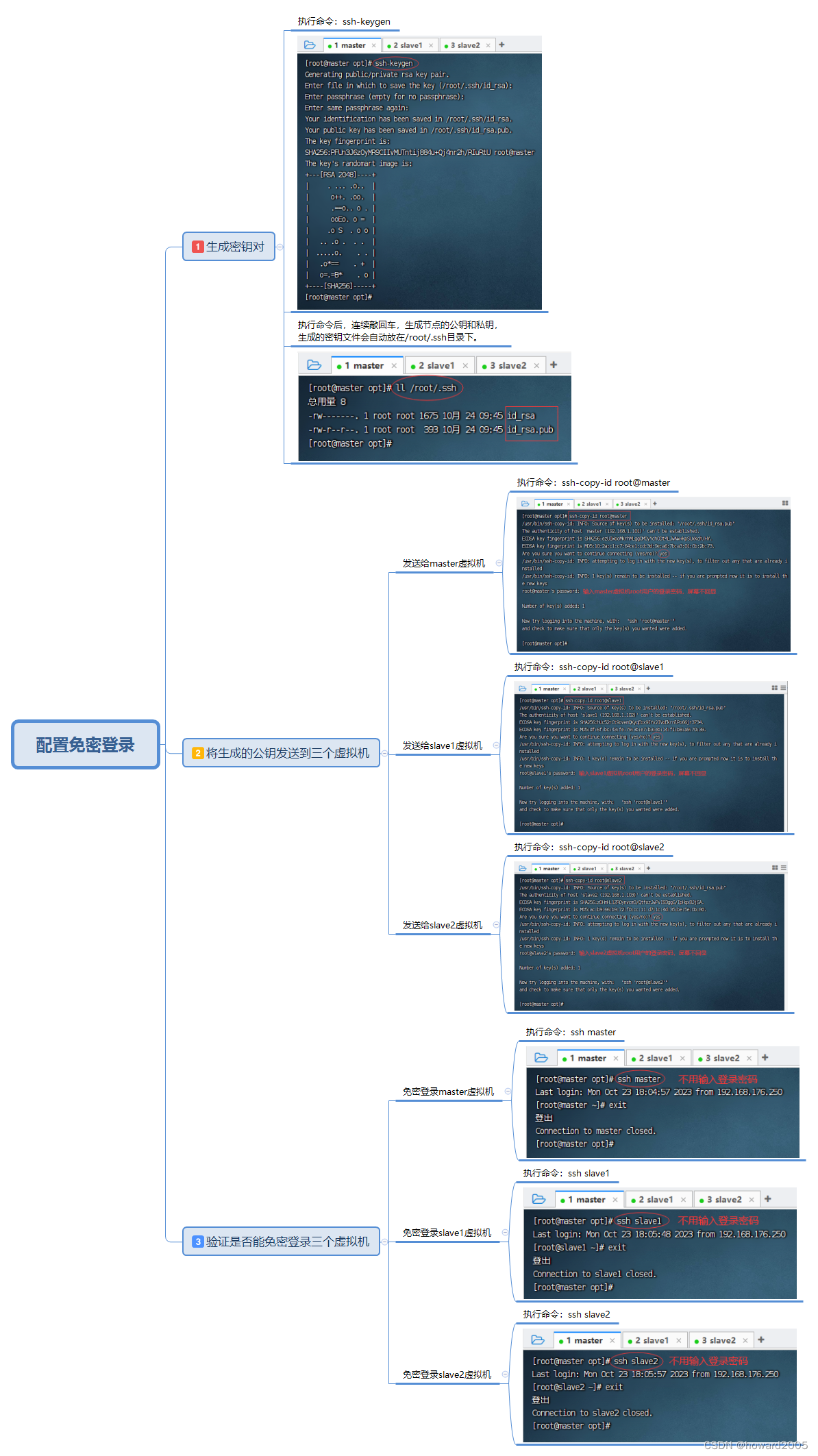
(五)配置免密登录
(六)配置JDK
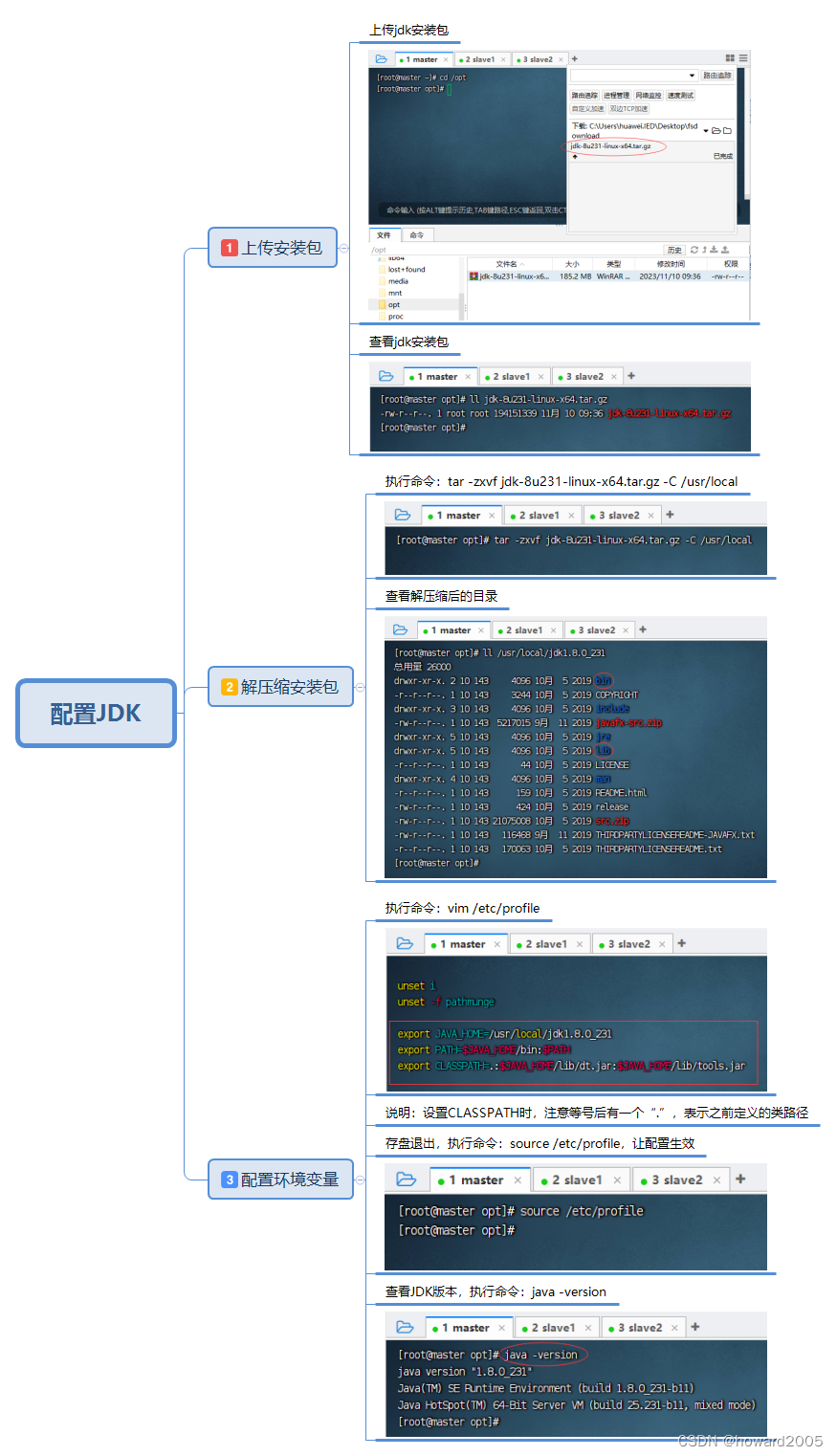
export JAVA_HOME=/usr/local/jdk1.8.0_231
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- 1
- 2
- 3
(七)配置Hadoop
1、上传安装包
- 上传hadoop安装包
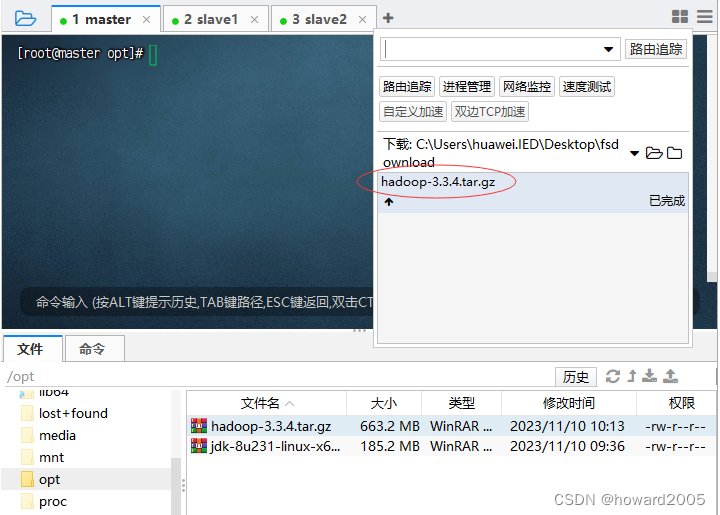
- 查看hadoop安装包
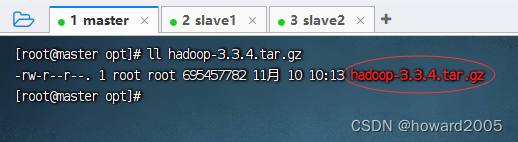
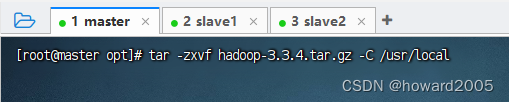
2、解压缩安装包
- 执行命令:
tar -zxvf hadoop-3.3.4.tar.gz -C /usr/local
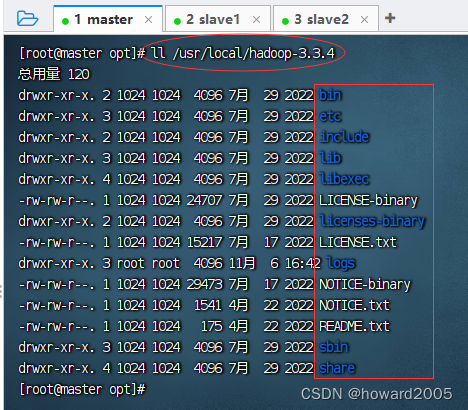
- 查看解压后的目录
3、配置环境变量
- 执行命令:
vim /etc/profile
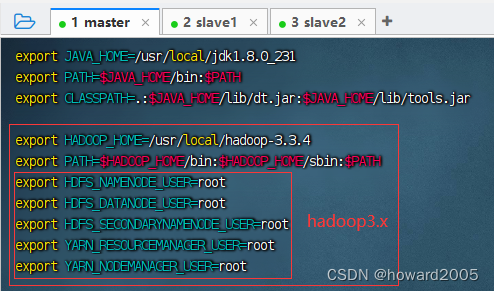
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 存盘退出,执行命令:
source /etc/profile,让配置生效
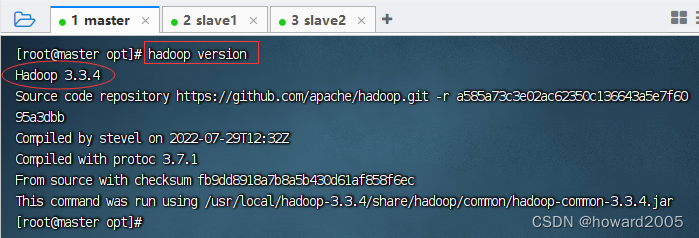
- 查看hadoop版本,执行命令:
hadoop version
4、编辑Hadoop环境配置文件 - hadoop-env.sh
- 进入hadoop配置目录,执行命令:
cd $HADOOP_HOME/etc/hadoop
- 执行命令:
vim hadoop-env.sh
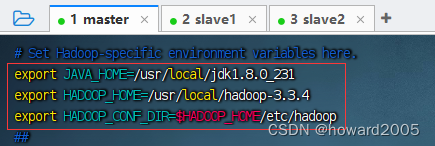
export JAVA_HOME=/usr/local/jdk1.8.0_231
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
- 1
- 2
- 3
- 存盘退出,执行命令:
source hadoop-env.sh,让配置生效
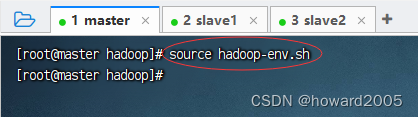
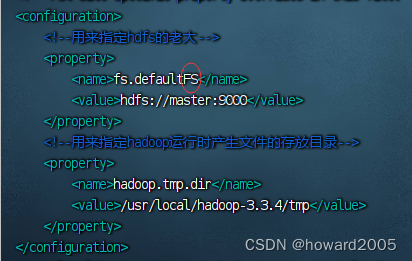
5、编辑Hadoop核心配置文件 - core-site.xml
- 执行命令:
vim core-site
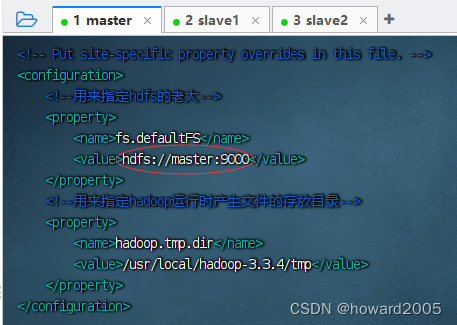
<configuration>
<!--用来指定hdfs的老大-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.3.4/tmp</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
6、编辑HDFS配置文件 - hdfs-site.xml
- 执行命令:
vim hdfs-site.xml
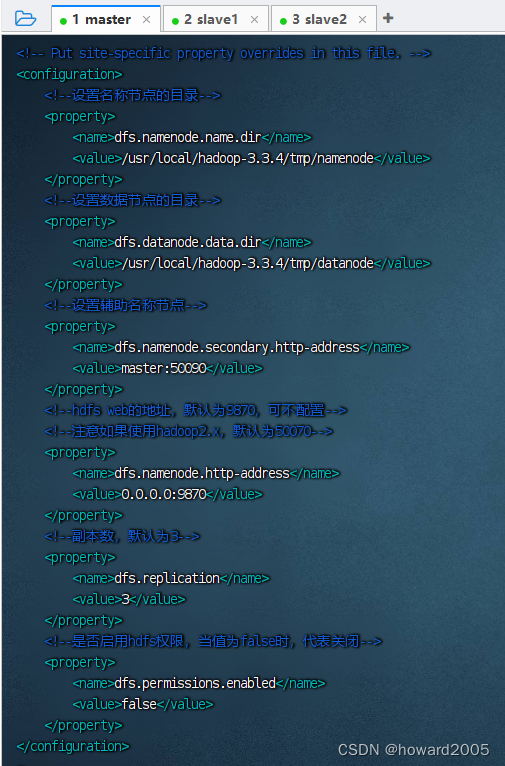
<configuration> <!--设置名称节点的目录--> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop-3.3.4/tmp/namenode</value> </property> <!--设置数据节点的目录--> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop-3.3.4/tmp/datanode</value> </property> <!--设置辅助名称节点--> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <!--hdfs web的地址,默认为9870,可不配置--> <!--注意如果使用hadoop2.x,默认为50070--> <property> <name>dfs.namenode.http-address</name> <value>0.0.0.0:9870</value> </property> <!--副本数,默认为3--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--是否启用hdfs权限,当值为false时,代表关闭--> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
7、编辑MapReduce配置文件 - mapred-site.xml
- 执行命令:
vim mapred-site.xml

<configuration>
<!--配置MR资源调度框架YARN-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
8、编辑YARN配置文件 - yarn-site.xml
- 执行命令:
vim yarn-site.xml
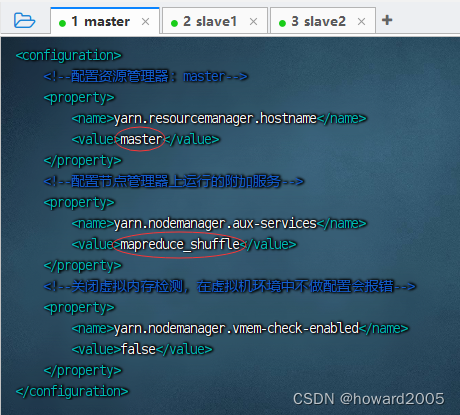
<configuration> <!--配置资源管理器:master--> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <!--配置节点管理器上运行的附加服务--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--关闭虚拟内存检测,在虚拟机环境中不做配置会报错--> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
9、编辑数据节点文件 - workers
- 执行命令:
vim workers
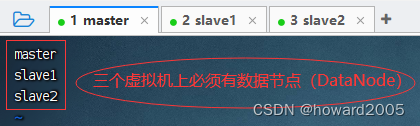
三、从主节点分发到从节点
(一)从master节点分发到slave1节点
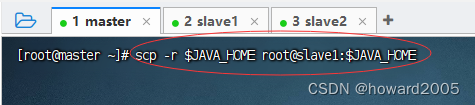
1、分发JDK
- 执行命令:
scp -r $JAVA_HOME root@slave1:$JAVA_HOME(注意,拷贝目录,一定要加-r选项)
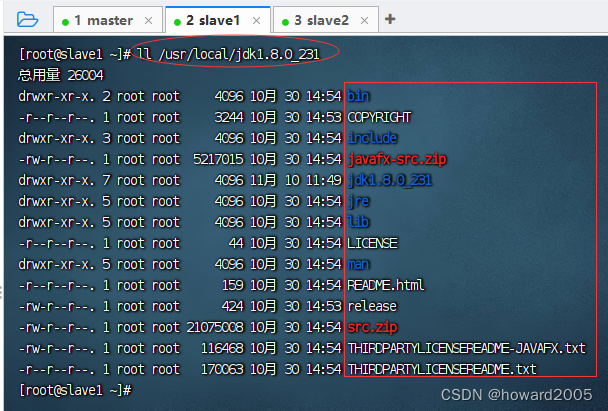
- 在slave1节点上查看拷贝的JDK目录
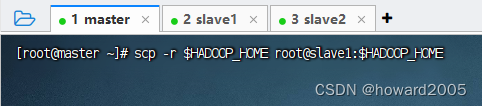
2、分发Hadoop
- 执行命令:
scp -r $HADOOP_HOME root@slave1:$HADOOP_HOME
- 在slave1节点上查看拷贝的hadoop目录
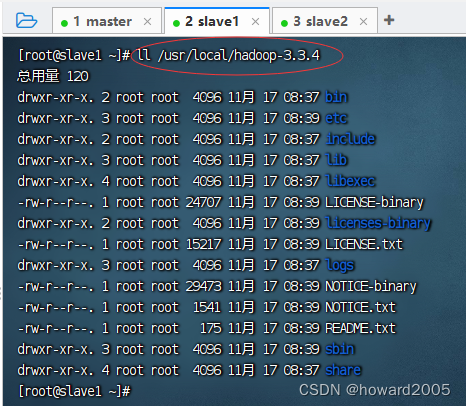
3、分发环境配置文件
- 执行命令:
scp /etc/profile root@slave1:/etc/profile

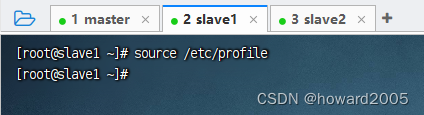
4、刷新环境配置文件
- 在slave1节点上执行命令:
source /etc/profile
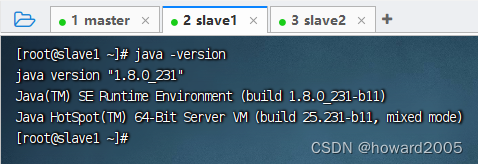
5、查看jdk和hadoop版本
- 在slave1节点上执行命令:
java -version
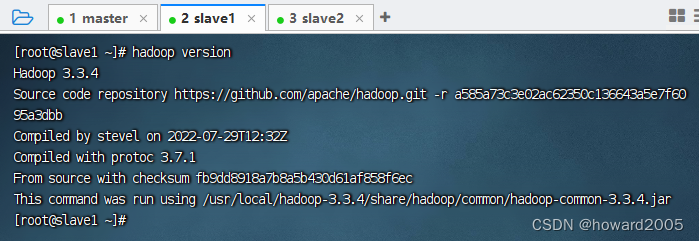
- 在slave1节点上执行命令:
hadoop version
6、分发主机名IP地址映射文件
- 执行命令:
scp /etc/hosts root@slave1:/etc/hosts

(二)从master节点分发到slave2节点
1、分发JDK
- 执行命令:
scp -r $JAVA_HOME root@slave2:$JAVA_HOME(注意,拷贝目录,一定要加-r选项)
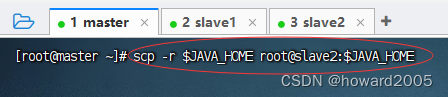
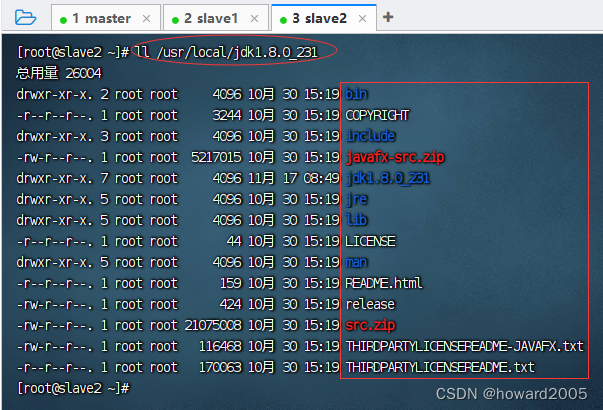
- 在slave2节点上查看拷贝的JDK目录
2、分发Hadoop
- 执行命令:
scp -r $HADOOP_HOME root@slave2:$HADOOP_HOME
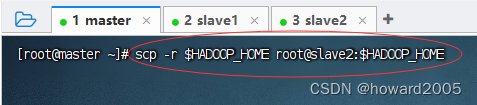
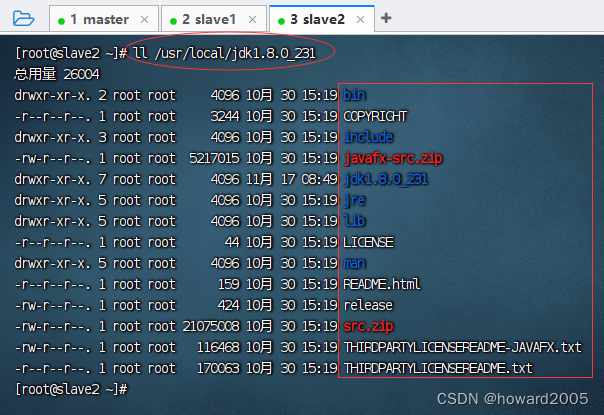
- 在slave2节点上查看拷贝的hadoop目录
3、分发环境配置文件
- 执行命令:
scp /etc/profile root@slave2:/etc/profile
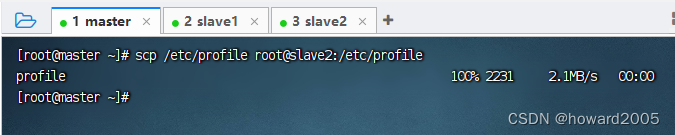
4、刷新环境配置文件
- 在slave2节点上执行命令:
source /etc/profile
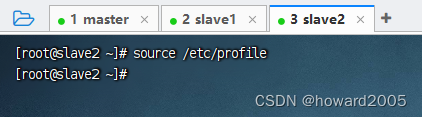
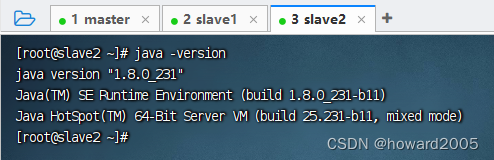
5、查看jdk和hadoop版本
-
在slave2节点上执行命令:
java -version
-
在slave2节点上执行命令:
hadoop version
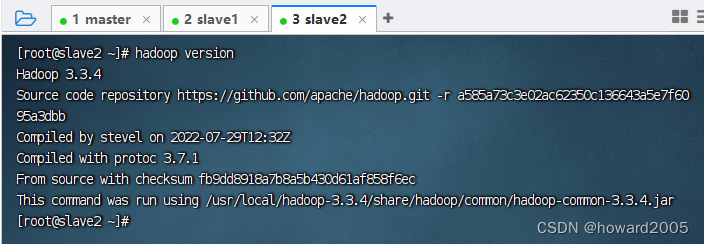
6、分发主机名IP地址映射文件
- 执行命令:
scp /etc/hosts root@slave2:/etc/hosts

四、格式化名称节点
- 执行命令:
hdfs namenode -format
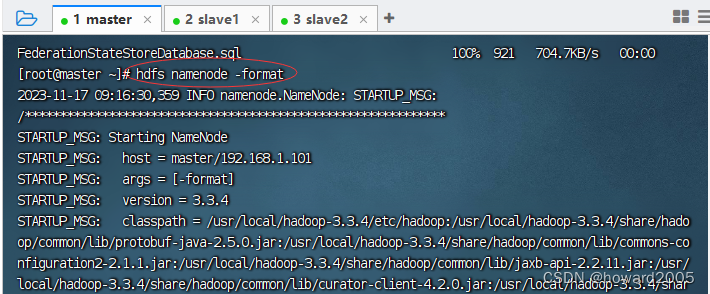
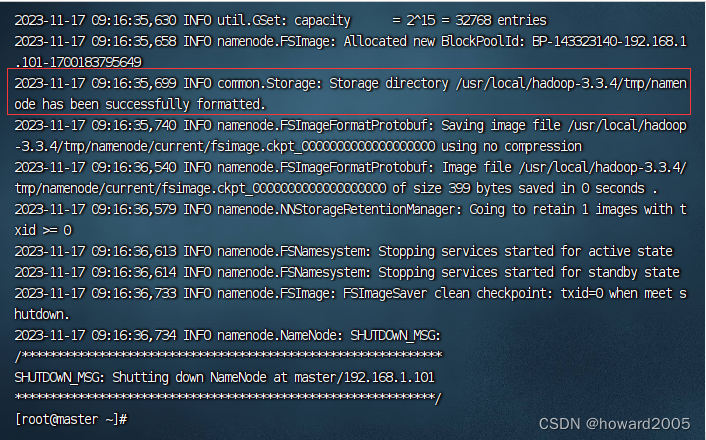
common.Storage: Storage directory /usr/local/hadoop-3.3.4/tmp/namenode has been successfully formatted.表明名称节点格式化成功。
五、启动Hadoop集群
- 启动hadoop服务,执行命令:
start-all.sh
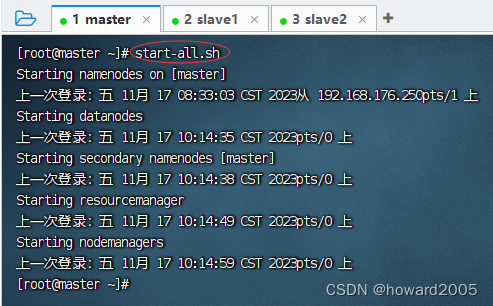
- 查看进程,执行命令:
jps
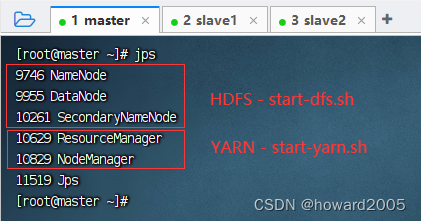
- 如果缺少进程,大多是因为响应的配置文件有问题,请仔细对照检查
hadoop-env.sh没有刷新,导致HADOOP_CONF_DIR环境变量找到不到core-site.xml,fs.defaultFS写成了fs.defaultFs,导致启动Hadoop之后,没有HDFS的三个进程:NameNode、SecondaryNameNode、DateNode
六、初试HDFS Shell

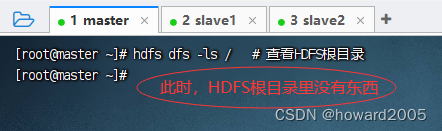
(一)查看目录
1、命令
- hdfs dfs -ls <路径>
2、演示
- 执行命令:
hdfs dfs -ls /
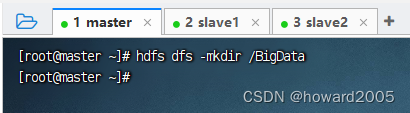
(二)创建目录
1、创建单层目录
(1)命令
- hdfs dfs -mkdir <单层目录>
(2)演示
- 执行命令:
hdfs dfs -mkdir /BigData
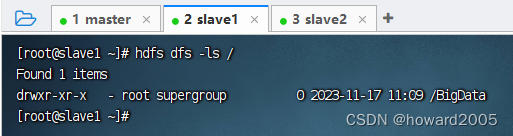
- 在slave1节点上查看新建的目录
2、创建多层目录
(1)命令
- hdfs dfs -mkdir
-p<多层目录>
(2)演示
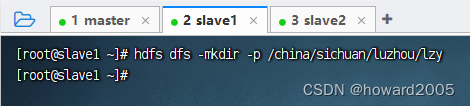
- 在slave1节点上执行命令:
hdfs dfs -mkdir -p /china/sichuan/luzhou/lzy
- 在master节点上查看新建的多层目录,执行命令:
hdfs dfs -ls -R /china
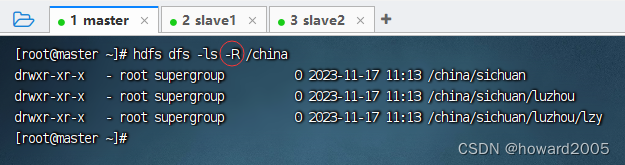
- 说明:
-R(- recursive)表示递归查看目录里全部东西
(三)上传文件
1、命令
- hdfs dfs -put <文件> <路径>
2、演示
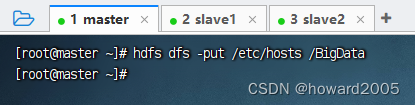
- 执行命令:
hdfs dfs -put /etc/hosts /BigData
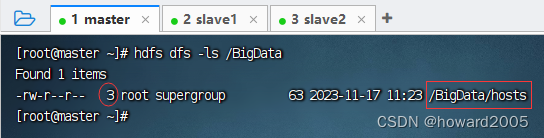
- 查看上传的文件
- 执行命令:
hdfs dfs -D dfs.replication=2 -put /etc/profile /BigData(上传文件时指定副本数)

- 查看上传的文件
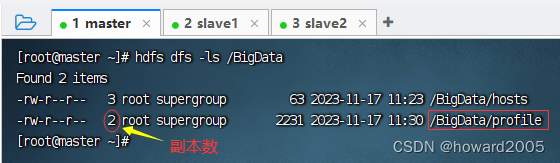
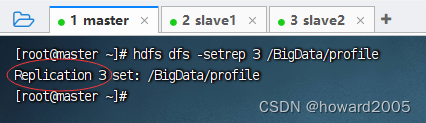
- 修改副本数,执行命令:
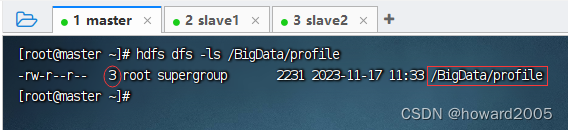
hdfs dfs -setrep 3 /BigData/profile
- 检验副本数是否已修改
(四)查看文件内容
1、命令
- hdfs dfs -cat <文件>
2、演示
- 执行命令:
hdfs dfs -cat /BigData/hosts
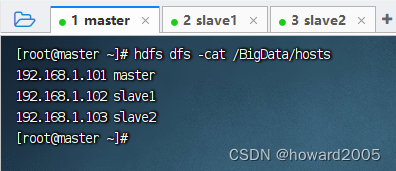
(五)删除文件
1、命令
- hdfs dfs -rm <文件>
2、演示
- 执行命令:
hdfs dfs -rm /BigData/hosts
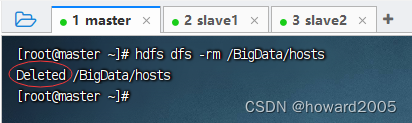
- 查看文件是否真的被删除
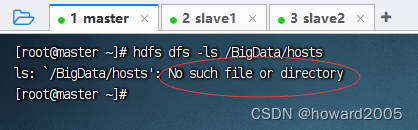
(六)删除目录
七、查看Hadoop WebUI
八、运行MR应用 - 词频统计
九、关闭Hadoop集群
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

