
- 1解决主机有网络但虚拟机没网络连接问题----记录
- 2Linux安装hadoop
- 3Python中selenium库的用法详解_python selenium
- 4Git 打patch (打补丁)的使用_git patch怎么用
- 5android基础知识12:android自动化测试03—基于junit的android测试框架02
- 6Matlab生成随机数的一些命令_matlab随机生成数 并输出
- 7《Python自然语言处理》第二章 习题解答 练习6
- 8借助PLC-Recorder,西门子PLC S7-200SMART实现2ms周期采集的方法(带时间戳采集)_200smart时间超过一天怎么比较
- 9无人机在水利行业的应用
- 10VRay Next (4.0) for SketchUp之AO通道的设置与输出_su渲染ao图参数设置
Nomic Embed:能够复现的SOTA开源嵌入模型_nomic-embed-text
赞
踩
Nomic-embed-text是2月份刚发布的,并且是一个完全开源的英文文本嵌入模型,上下文长度为8192。它在处理短文和长文本任务方面都超越了现有的模型,如OpenAI的Ada-002和text-embedding-3-small。该模型有137M个参数在现在可以算是非常小的模型了。
模型、训练代码以及一个包含2.35亿文本对的大型数据集都已经发布,我们可以复现、审计和重新构建这个先进的嵌入模型。

模型架构
以下是该模型对BERT base应用的架构变化和优化:
- 使用Rotary位置嵌入替代绝对位置编码。
- 使用SwiGLU激活代替GeLU。
- 使用Flash Attention。
- 删除Dropout。
- 词汇大小为64的倍数。
这样就得到了nomic-bert-2048,该模型在所有阶段的最大序列长度为2048。在推断时使用动态NTK插值将模型扩展到8192的序列长度。
BooksCorpus和2023年的Wikipedia转储被用作预训练语料库。每个文档使用bert-base-uncased分词器进行分词,并打包成2048个标记的块。使用30%的掩码率而不是bert的15%。预训练不考虑下一句子预测任务,只进行掩码填充。
无监督对比预训练
无监督对比预训练旨在教会模型区分最相似的文档和其他无关的文档。
论文的数据集使用大量公开可用的数据形成文本对。这些数据集涵盖各种目标和领域,从网页检索到科学文章,总共精选了涵盖29个数据集的470M个文本对。
为了去除噪声样本,使用gte-base模型进行了一致性过滤。
对于数据集的100万个子样本,每个对都被嵌入为查询和文档。如果文档不在前k个(在这种情况下是2)中,使用余弦相似度,那么该示例将被丢弃。过滤后得到约235M个文本对。
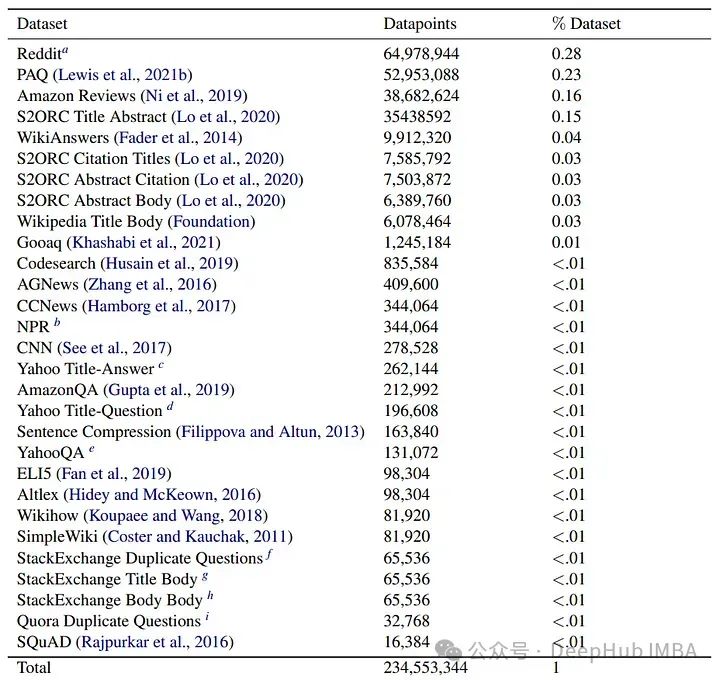
此外,还使用完整的维基百科文章与它们的标题配对,以及来自S2ORC的单篇论文的摘要和全文主体,这样就得到了一个长上下文数据集。
在训练过程中,一次从一个数据源中抽样一对,并且整个批次都用来自单一数据源的样本填充,这样可以防止模型学习特定于源的问题(不让模型走捷径,减少过拟合)。
使用InfoNCE对比损失。对于给定的批次B = (q0, d0), (q1, d1), …, (qn, dn),最小化如下所示:
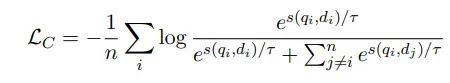
其中,s(q, d)是(q, d)的余弦相似度。
为了打破双编码器的对称性,使用以下特定任务前缀:
- 搜索查询(通常用于问题)
- 搜索文档(通常用于响应)
- 分类(用于与STS相关的任务,如改写)
- 聚类(用于将语义相似的文本组合在一起的任务)
监督对比微调
训练的这个阶段旨在通过利用人工标记的数据集来提高性能。
监督微调在MSMarco、NQ、NLI、HotpotQA、FEVER、MEDI的部分数据、WikiAnswers和Reddit上进行。
配对的对比损失被调整为包含每个批次中的难区分的负样本。作者发现将负样本数量增加到7以上并不能明显提高性能。此外多次训练也会对性能造成了损害。
评估
对BEIR进行了少量样本的评估,获得了在特定数据集上的训练对整体MTEB分数的影响。在FEVER、HotpotQA和MEDI数据集上的训练提高了整体MTEB分数,这表明在训练中选择数据集对于提升性能至关重要。
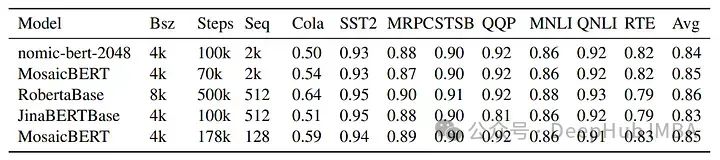
nomic-bert-2048在GLUE基准测试上进行了评估。对于某些任务,它是从MNLI检查点初始化的。nomic-bert-2048在GLUE基准测试上与大小和训练方式相似的模型竞争力相当,与MosaicBERT和JinaBERT在各个任务上的得分也很相似,除了Cola(这个任务中由于模型的序列长度更长)因为在预训练过程中看到更多的标记,所以表现有所不同。
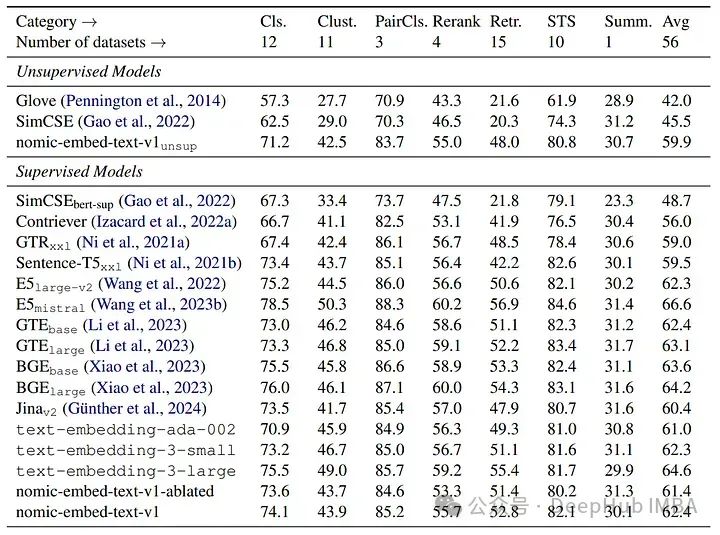
MTEB基准测试
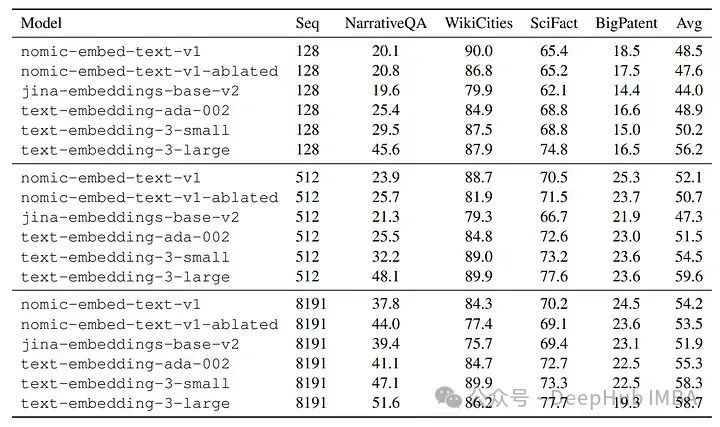
Jina 长上下文语境测试
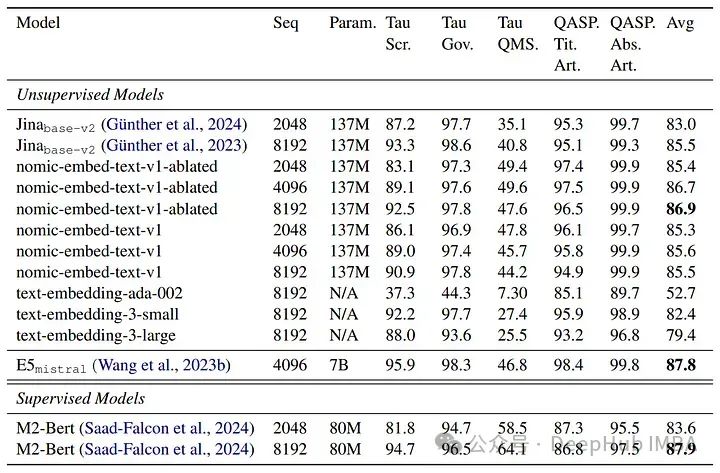
LoCo基准测试
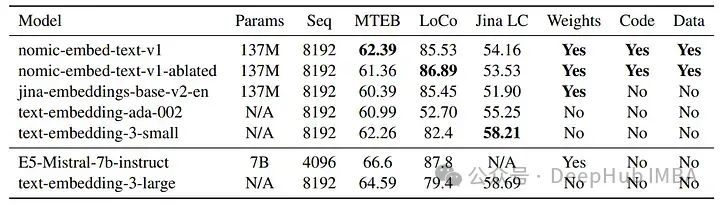
nomic-embed-text-v1与其他模型如text-embedding-ada-002和jina-embeddings-v2-base-en的比较。nomic-embed-text-v1在MTEB上的表现超过了text-embedding-ada-002和jina-embeddings-v2-base-en。它在长上下文基准测试(LoCo和Jina长上下文基准测试)上一致优于jina-embeddings-v2-base-en,展现出对长序列更优越的性能。
Nomic Embed 1.5

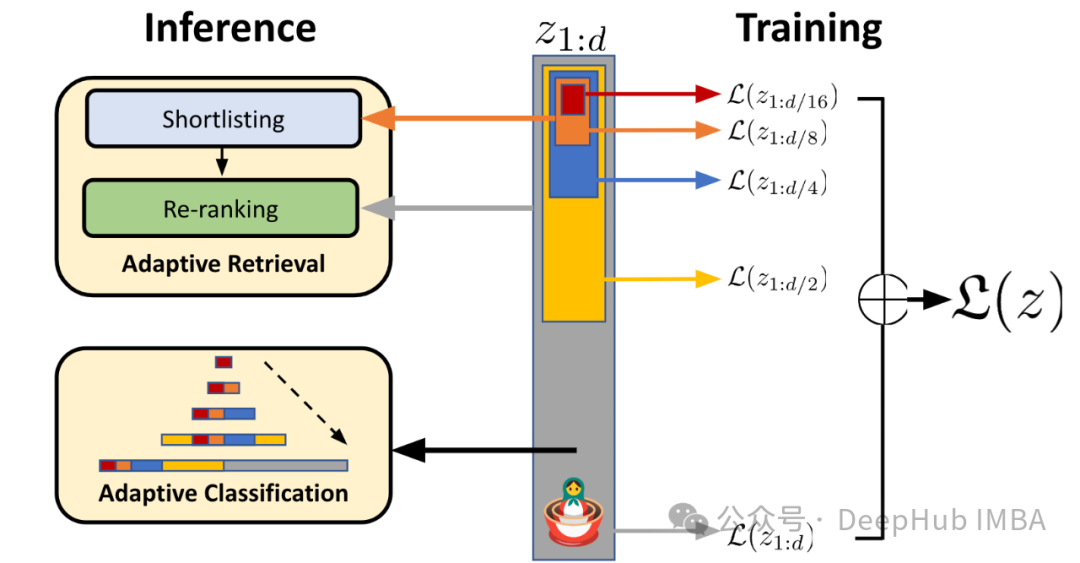
Nomic Embed v1.5是Nomic Embed模型的增强版本,它融合了Matryoshka Representation Learning,允许在单个模型中调整嵌入维度。训练过程从对弱相关文本对进行无监督对比训练开始,逐渐转向在更高质量的标记数据集上进行微调。
nomic-embed-text-unsupervised 在 nomic-embed-text微调数据集上使用MRL进行微调。
Nomic Embed v1.5支持嵌入维度从64到768,在512和768维度上表现优于其他模型。与以前的版本相比,它实现了显著的内存减少,同时保持了与其他高级模型(如MiniLM-L6-v2)相当的性能水平。
这里简单介绍一下Matryoshka Representation Learning:
Matryoshka Representation Learning是一种使我们的模型具有可变嵌入维度的技术。类似于俄罗斯套娃,我们明确地训练模型来学习在不同嵌入维度下的嵌套表示。这使我们能够从完整大小截断嵌入以减少它们的内存占用,同时保持性能。
总结
很高兴能够看到有关文本嵌入的最新论文,这篇论文也说明了在模型很小的情况下还是可以得到更好的测试结果,这对我们应用来说非常重要,另外就是现在嵌入的研究方向变为了动态维度表示,但是我个人认为目前这方面还可以有更大的发展。
论文:
https://avoid.overfit.cn/post/2ed4f1b0173a444f836ccfaee424db0d
作者:Ritvik Rastogi