
- 1Flutter 中的 ScrollNotification 为啥收不到_flutter scrollnotification
- 2One Model Structure for All Sub-Tasks KBQA System
- 3java轻型卡车零部件销售平台(ssm框架毕业设计)
- 4操作系统 MIT 6.S081_mit6s》081 实验源码
- 5产品经理的AI大模型实战指南:驾驭未来,引领创新
- 6Android Studio 更换国内源下载依赖库_android studio更换国内源
- 7基于微信小程序/APP的校园生活服务系统设计与实现_基于微信小程序的校园生活助手的设计与实现
- 8偷偷称为一名炼丹师、掌握核心参数然后惊艳所有人!_lora和locn,loha
- 9php 5.0入门系列教程 pdf,ThinkPHP5.0-快速入门手册(新手教程版).pdf
- 10Java 程序结构 -- Java 语言的变量、方法、运算符与注释
K-Means聚类算法(含Python代码)_pythonkmeans聚类算法代码
赞
踩
K-Means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近其相似度就越大。
1.算法过程
1)从N个样本数据中随机选取K个对象作为初始的聚类中心。
2)分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中。
3)所有对象分配完成后,重新计算K个聚类的中心。
4)与前一次计算得到的K个聚类中心比较,如果聚类中心发生变化,转过程2),否则转过程5)。
5)当质心不发生变化时停止并输出聚类结果。
聚类的结果可能依赖于初始聚类中心的随机选择,可能使得结果严重偏离全局最优分实践中,为了得到较好的结果,通常选择不同的初始聚类中心,多次运行K-Means算类。法。在所有对象分配完成后,重新计算K个聚类的中心时,对于连续数据,聚类中心取该簇的均值,但是当样本的某些属性是分类变量时,均值可能无定义,可以使用K-众数方法。
2.数据类型与相似度度量
(1)连续属性
对于连续属性,要先对各属性值进行零-均值规范,再进行距离的计算。在K-Means聚类算法中,一般需要度量样本之间的距离、样本与簇之间的距离以及簇与簇之间的距离。
度量样本之间的相似性最常用的是欧几里得距离、曼哈顿距离和闵可夫斯基距离;样本与簇之间的距离可以用样本到簇中心的距离 ;簇与簇之间的距离可以用簇中心的距离。
具体计算公式如下图:

(2)文档数据
对于文档数据使用余弦相似性度量,先将文档数据整理成文档-词矩阵格式,如下图:

文档之间计算公式如下:

3.目标函数
使用误差平方和 SSE作为度量聚类质量的目标函数,对于两种不同的聚类结果,选择误差平方和较小的分类结果。
符号说明:

连续属性的SSE计算公式为:
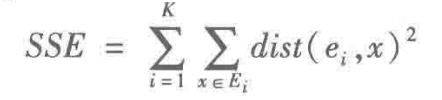
文档数据的 SSE 计算公式为:
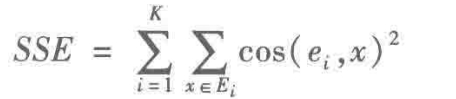
簇的聚类中心计算公式:

4. 实例
部分餐饮客户的消费行为特征数据如下。根据这些数据将客户分类成不同客户群并评价这些客户群的价值。

采用K-Means聚类算法,设定聚类个数K为3,最大迭代次数为500次,距离函数取欧氏距离。
K-Means聚类算法的Python 代码如下所示:
1.导入数据
- import pandas as pd
- #导入数据
- inputfile = r'D:\daily\data1\consumption_data.xls' #销量及其他属性数据
- k = 3 #聚类的类别
- iteration = 500 #聚类最大循环次数
- data = pd.read_excel(inputfile, index_col = 'Id') #读取数据
2.数据标准化
data_zs = 1.0*(data - data.mean())/data.std() #数据标准化3.建立模型
- from sklearn.cluster import KMeans
- model = KMeans(n_clusters = k,n_init='auto',max_iter = iteration)
- model.fit(data_zs) #开始聚类
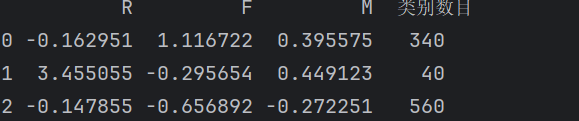
4.打印结果
简单打印:
- r1 = pd.Series(model.labels_).value_counts() #统计各个类别的数目
- r2 = pd.DataFrame(model.cluster_centers_) #找出聚类中心
- r = pd.concat([r2, r1], axis = 1)
- r.columns = list(data.columns) + [u'类别数目']
- print(r)
输出详细结果到excel表:
- #详细输出原始数据及其类别
- outputfile = r'D:\daily\data1\data_type.xlsx'
- r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1)
- r.columns = list(data.columns) + [u'聚类类别']
- r.to_excel(outputfile) #保存结果
运行结果如下所示:

5.分群的概率密度函数图

分群1特点:R间隔相对较小,主要集中在0~30天;消费次数集中在10~25次;消费金额在 500~ 2000。
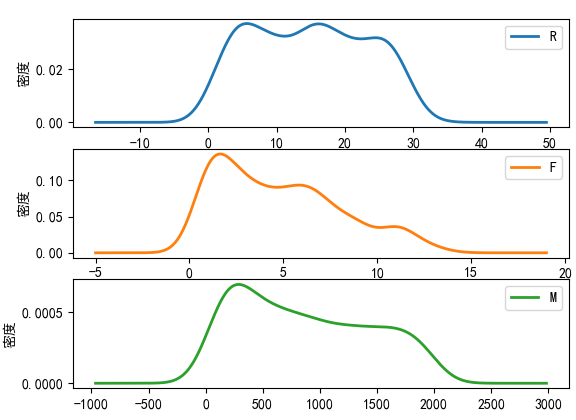
分群2特点:R间隔分布在0~30天;消费次数集中在0~12次;消费金额在0~1800。
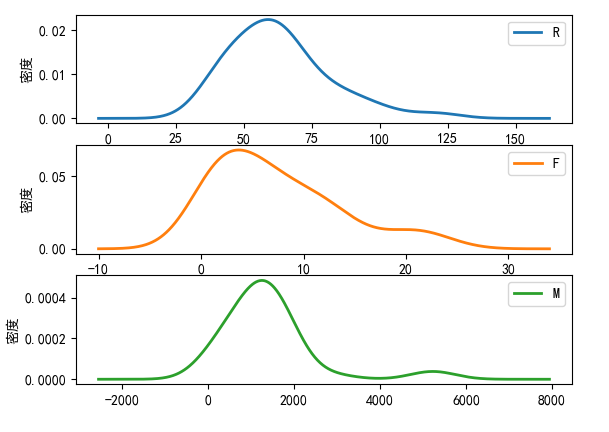
分群3特点:R间隔相对较大,间隔分布在30~80天;消费次数集中在0~15次;消费金额在0~ 2000。
对比分析:分群1时间间隔较短,消费次数多,而且消费金额较大,是高消费、高价值人群。分群2的时间间隔、消费次数和消费金额处于中等水平,代表着一般客户分群3的时间间隔较长,消费次数较少,消费金额也不是特别高,是价值较低的客户群体。
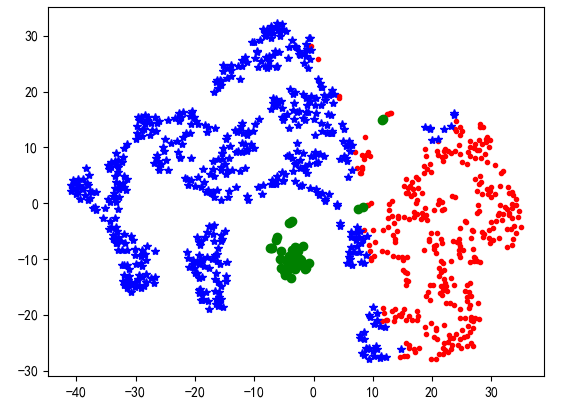
6.聚类结果可视化
TSNE是高维数据的可视化,能够直观地展示研究结果。然而,通常来说输入的特征数是高维的(大于3维),一般难以直接以原特征对聚类结果进行展示。而TSNE 提供了一种有效的数据降维方式,让我们可以在2维或者3维的空间中展示聚类结果。下面我们用 TSNE 对上述K-Means 聚类的结果以二维的方式展示出来。
- from sklearn.manifold import TSNE
- import matplotlib.pyplot as plt
- plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
- plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
- tsne = TSNE()
- tsne.fit_transform(data_zs) #进行数据降维
- tsne = pd.DataFrame(tsne.embedding_, index = data_zs.index) #转换数据格式
- d = tsne[r[u'聚类类别'] == 0]
- plt.plot(d[0], d[1], 'r.')
- d = tsne[r[u'聚类类别'] == 1]
- plt.plot(d[0], d[1], 'go')
- d = tsne[r[u'聚类类别'] == 2]
- plt.plot(d[0], d[1], 'b*')
- plt.show()
运行结果如下所示:
整体代码:
- import pandas as pd
- from sklearn.cluster import KMeans
- from sklearn.manifold import TSNE
- import matplotlib.pyplot as plt
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
- plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
-
- inputfile = r'D:\daily\data1\consumption_data.xls'
- outputfile = r'D:\daily\data1\data_type.xlsx'
- k = 3 #聚类的类别
- iteration = 500 #聚类最大循环次数
- data = pd.read_excel(inputfile, index_col = 'Id') #读取数据
- data_zs = 1.0*(data - data.mean())/data.std() #数据标准化
- model = KMeans(n_clusters = k,n_init='auto',max_iter = iteration)
- model.fit(data_zs) #开始聚类
- #简单打印结果
- r1 = pd.Series(model.labels_).value_counts() #统计各个类别的数目
- r2 = pd.DataFrame(model.cluster_centers_) #找出聚类中心
- r = pd.concat([r2, r1], axis = 1)
- r.columns = list(data.columns) + [u'类别数目']
- print(r)
- #详细输出原始数据及其类别
- r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出
- r.columns = list(data.columns) + [u'聚类类别']
- r.to_excel(outputfile)
- #自定义作图函数
- def density_plot(data):
- import matplotlib.pyplot as plt
- plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
- plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
- p = data.plot(kind='kde', linewidth = 2, subplots = True, sharex = False)
- [p[i].set_ylabel(u'密度') for i in range(k)]
- plt.legend()
- return plt
- pic_output = r'D:\daily\data1\pd_' #概率密度图文件名前缀
- for i in range(k):
- density_plot(data[r[u'聚类类别']==i]).savefig(u'%s%s.png' %(pic_output, i))
-
- tsne = TSNE()
- tsne.fit_transform(data_zs) # 进行数据降维
- tsne = pd.DataFrame(tsne.embedding_, index=data_zs.index) # 转换数据格式
- d = tsne[r[u'聚类类别'] == 0]
- plt.plot(d[0], d[1], 'r.')
- d = tsne[r[u'聚类类别'] == 1]
- plt.plot(d[0], d[1], 'go')
- d = tsne[r[u'聚类类别'] == 2]
- plt.plot(d[0], d[1], 'b*')
- plt.show()


