
- 1GPT系列学习笔记:GPT、GPT2、GPT3_gpt2和gpt3
- 2Linux下如何编译C/C++代码?从.c到.exe经历了什么?_c++如何编译linux
- 3unity学习笔记-有关透明材质的一些问题记录_unity半透明材质球
- 4python中tkinter使用Messagebox实现对话框、实现信息提示、是/否提示会话框_python tkinter messagebox
- 5CentOS7搭建FTP(虚拟用户)_setsebool ftp_home_dir
- 6解密Prompt系列6. lora指令微调扣细节-请冷静,1个小时真不够~_lora_alpha
- 7本机windows搭建达摩院与高德联合出品的地理地址自然语言处理模型MGeo实战
- 8python爬虫,看完发小阿水决心去城发展,村花都留不住
- 9OpenAI Sora出炉,视频鉴赏,详细介绍,小白看过来~~立即尝试Sora,开启您的AI视频创作之旅吧!_sora如何访问
- 10python可以使用函数什么打开文件_python – 用于打开具有两个函数的文件的“with”语法...
(ICCV-2021)TransReID:基于transformer的目标重识别
赞
踩
TransReID:基于transformer的目标重识别
paper题目:TransReID: Transformer-based Object Re-Identification
paper是浙大发表在ICCV 2021的工作
paper链接:地址
Abstract
提取稳健的特征表示是目标重识别(ReID)的关键挑战之一。尽管基于卷积神经网络(CNN)的方法已经取得了巨大的成功,但它们一次只能处理一个局部邻域,并受到卷积和下采样操作(如池化和分层卷积)造成的细节信息损失的影响。为了克服这些限制,我们提出了一个纯粹的基于transformer的目标识别框架,名为TransReID。具体来说,我们首先将图像编码为一个patch序列,并通过一些关键的改进建立一个基于transformer的强基线,在几个ReID基准上取得了与基于CNN的方法相竞争的结果。为了进一步加强transformer下的稳健特征学习,我们精心设计了两个新型模块。(i) 拼图模块(JPM)被提出来,通过移位和patch乱序操作重新排列patch嵌入,产生具有改进的判别能力和更多样化的覆盖范围的稳健特征。(ii) 侧面信息嵌入(SIE)被引入,通过插入可学习的嵌入来纳入这些非视觉线索,以减轻对相机/视角变化的特征偏差。据我们所知,这是第一项为ReID研究采用纯transformer的工作。TransReID的实验结果很好,在人和车的ReID基准上都达到了最先进的性能。代码地址:链接
1. Introduction
目标重识别 (ReID) 旨在将特定目标关联到不同的场景和相机视角中,例如在行人 ReID 和车辆 ReID 的应用中。提取鲁棒和判别特征是 ReID 的关键组成部分,并且长期以来一直由基于 CNN 的方法主导 [19、37、36、44、42、5、12、13、53、15]。
通过回顾基于 CNN 的方法,我们发现了两个在目标 ReID 领域没有得到很好解决的重要问题。 (1) 在全局范围内利用丰富的结构模式对于目标 ReID [54] 至关重要。然而,由于有效感受野的高斯分布 [29],基于 CNN 的方法主要关注小的判别区域。最近,已经引入了注意力模块 [54, 6, 3, 21, 1] 来探索长程依赖关系 [45],但大多数都嵌入在深层,并没有解决 CNN 的原理问题。因此,基于注意力的方法仍然更喜欢大的连续区域,并且难以提取多个多样化的判别部分(见图 1)。 (2) 具有详细信息的细粒度特征也很重要。然而,CNN 的下采样算子(例如池化和跨步卷积)降低了输出特征图的空间分辨率,这极大地影响了区分具有相似外观的目标的能力 [37, 27]。如图 2 所示,背包的细节在基于 CNN 的特征图中丢失,难以区分两个人。

图 1:Grad-CAM [34] 注意力图的可视化:(a) 原始图像,(b) 基于 CNN 的方法,© CNN+注意力方法,(d) 基于 Transformer 的方法,用于捕获全局上下文信息等判别部分。

图 2:具有相似外观的 2 个硬样本的输出特征图的可视化。与基于 CNN 的方法相比,基于 Transformer 的方法在输出特征图上保留背包细节,如红框所示。为了更好的可视化,输入图像被缩放到 1024 × 512 1024 \times 512 1024×512的大小。
最近,Vision Transformer (ViT) [8] 和 Data-efficient image Transformers (DeiT) [40] 表明,在图像识别的特征提取方面,纯transformer可以与基于 CNN 的方法一样有效。随着多头注意力模块和去除卷积和下采样算子,基于transformer的模型适合解决基于CNN的ReID中的上述问题,原因如下。 (1) 与 CNN 模型相比,多头 self-attention 捕获长距离依赖关系并驱动模型关注不同的人体部位(例如图 1 中的大腿、肩膀、腰部)。 (2) 在没有下采样算子的情况下,transformer 可以保存更详细的信息。例如,可以观察到背包周围特征图的差异(图 2 中用红色框标记)可以帮助模型轻松区分两个人。这些优势促使我们在目标 ReID 中引入纯transformer。
尽管如上所述具有巨大的优势,但仍需要专门为目标 ReID 设计转换器以应对独特的挑战,例如图像中的大变化(例如遮挡、姿势的多样性、相机视角)。在基于 CNN 的方法中,已经做出了大量努力来缓解这一挑战。其中,局部特征[37、44、20、48、28]和边信息(如相机和视点)[7、61、35、30]已被证明是增强特征鲁棒性所必需且有效的.学习部分/条带聚合特征使其对遮挡和错位具有鲁棒性[49]。然而,将刚性条纹部分方法从基于 CNN 的方法扩展到纯基于transformer的方法可能会由于全局序列分裂成几个孤立的子序列而破坏长程依赖性。此外,考虑到边信息,例如相机和视角特定信息,可以构建一个不变的特征空间来减少边信息变化带来的偏差。然而,基于 CNN 构建的边信息的复杂设计,如果直接应用于 Transformer,则无法充分利用 Transformer 固有的编码能力。因此,特定设计的模块对于纯transformer成功应对这些挑战是不可避免和必不可少的。
因此,我们提出了一个名为 TransReID 的新目标 ReID 框架来学习鲁棒的特征表示。首先,通过几个关键的调整,我们构建了一个基于纯transformer的强大的基线框架。
其次,为了扩展长期依赖关系并增强特征鲁棒性,我们提出了一个拼图patch模块(JPM),通过移位和混洗操作重新排列patch嵌入并将它们重新分组以进行进一步的特征学习。 JPM 用于模型的最后一层,与不包括此特殊操作的全局分支并行提取鲁棒特征。因此,网络倾向于提取具有全局上下文的扰动不变和鲁棒特征。第三,为了进一步增强鲁棒特征的学习,引入了边信息嵌入(SIE)。我们提出了一个统一的框架,通过可学习的嵌入有效地结合非视觉线索,以减轻相机或视角带来的数据偏差,而不是在基于 CNN 的方法中使用这些非视觉线索的特殊和复杂的设计。以相机为例,所提出的 SIE 有助于解决相机间和相机内匹配之间巨大的成对相似性差异(参见图 6)。 SIE 也可以很容易地扩展到包括除我们展示的线索之外的任何非视觉线索。
据我们所知,我们是第一个研究纯 Transformer 在目标 ReID 领域的应用。本文的贡献总结如下:
-
我们提出了一个强大的基线,它首次利用纯 Transformer 进行 ReID 任务,并实现了与基于 CNN 的框架相当的性能。
-
我们设计了一个拼图patch模块(JPM),由移位和patch混洗操作组成,它有助于目标的扰动不变和鲁棒的特征表示。
-
我们引入了一种边信息嵌入(SIE),它通过可学习的嵌入对边信息进行编码,并被证明可以有效地减轻特征偏差。
-
最终框架 TransReID 在行人和车辆 ReID 基准测试中实现了最先进的性能,包括 MSMT17[46]、Market-1501[55]、DukeMTMC-reID[33]、OccludedDuke[31]、VeRi-776[25] 和VehicleID[24]。
2. Related Work
2.1. Object ReID
目标重识别的研究主要集中在行人重识别和车辆重识别上,大多数最先进的方法都是基于 CNN 结构的。目标 ReID 的一个流行pipeline是设计合适的损失函数来训练用于提取图像特征的 CNN 主干(例如 ResNet [11])。交叉熵损失(ID 损失)[56] 和三元组损失 [23] 在深度 ReID 中应用最为广泛。Luo等人[27] 提出了 BNNeck 来更好地结合 ID 损失和三元组损失。Sun等人[36] 提出了 ID 损失和三元组损失的统一观点。
细粒度特征。已经学习了细粒度特征来聚合来自不同部分/区域的信息。细粒度部分要么通过大致水平条纹自动生成,要么通过语义解析自动生成。像 PCB [37]、MGN [44]、AlignedReID++ [28]、SAN[32] 等方法,将图像划分为多个条带,并为每个条带提取局部特征。使用解析或关键点估计来对齐不同的部分或两个目标也已被证明对行人和车辆 ReID 都有效 [26、30、47、31]。
侧面信息。对于在交叉摄像头系统中捕获的图像,由于不同的摄像头设置和对象视角,在姿势、方向、照明、分辨率等方面存在很大的变化。一些工作 [61, 7] 使用诸如相机 ID 或视角信息等辅助信息来学习不变特征。例如,基于相机的批量归一化(CBN)[61] 强制将来自不同相机的图像数据投影到相同的子空间上,从而大大缩小相机间和相机内对之间的分布差距。Viewpoint/Orientation-invariant 特征学习 [7, 60] 对于行人和车辆 ReID 也很重要。
2.2. Pure Transformer in Vision
在[41]中提出了Transformer模型来处理自然语言处理(NLP)领域的顺序数据。许多研究还显示了它对计算机视觉任务的有效性。Han等人。 [9] 和Salman等人。 [18] 调查了 Transformer 在计算机视觉领域的应用。
纯transformer模型正变得越来越流行。例如,图像处理transformer (IPT) [2] 通过使用大规模预训练来利用transformer,并在超分辨率、去噪和去雨等多个图像处理任务上实现了最先进的性能。最近提出的 ViT [8] 将纯transformer直接应用于图像patch序列。然而,ViT 需要一个大规模的数据集来预训练模型。为了克服这个缺点,Touvron 等人。 [40] 提出了一个名为 DeiT 的框架,该框架引入了一种特定于transformer的师生策略,以加速 ViT 训练,而不需要大规模的预训练数据。
3. Methodology
我们的目标 ReID 框架基于基于 Transformer 的图像分类,但在捕获稳健特征方面进行了多项关键改进(第 3.1 节)。为了进一步提高transformer上下文中的鲁棒特征学习,在第 3.2 节和第 3.3 节中仔细设计了拼图patch模块 (JPM) 和边信息嵌入 (SIE)。这两个模块以端到端的方式联合训练,如图 4 所示。
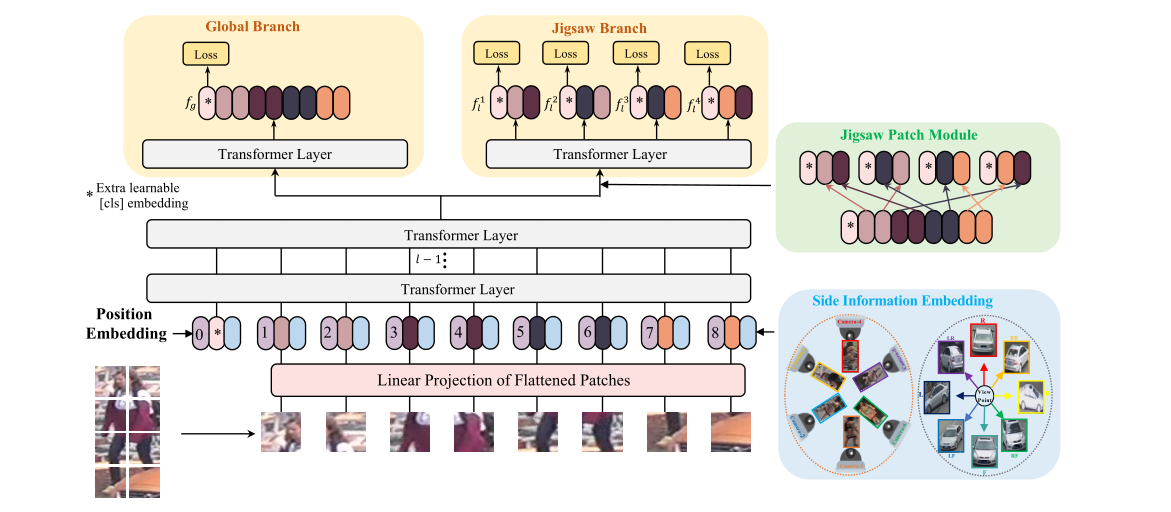
图 4:提出的 TransReID 框架。 Side Information Embedding(浅蓝色)将非视觉信息(例如相机或视角)编码为嵌入表示。它与patch嵌入和位置嵌入一起输入到transformer编码器中。最后一层包括两个独立的transformer层。一种是编码全局特征的标准。另一个包含 Jigsaw Patch Module (JPM),它将所有patch打乱并将它们重新组合成几个组。所有这些组都被输入到一个共享的transformer层以学习局部特征。全局特征和局部特征都会使用 ReID 损失。
3.1. Transformer-based strong baseline
我们遵循目标 ReID [27, 44] 的一般强pipeline,为目标 ReID 构建基于transformer的强基线。我们的方法有两个主要阶段,即特征提取和监督学习。如图 3 所示。给定图像
x
∈
R
H
×
W
×
C
x \in \mathbb{R}^{H \times W \times C}
x∈RH×W×C,其中
H
,
W
,
C
H, W, C
H,W,C分别表示其高度、宽度和通道数,我们将其拆分为
N
N
N个固定大小的patch
{
x
p
i
∣
i
=
1
,
2
,
⋯
,
N
}
\left\{x_{p}^{i} \mid i=1,2, \cdots, N\right\}
{xpi∣i=1,2,⋯,N}。一个额外的可学习的 [cls] 嵌入标记表示为 xcls 被附加到输入序列。输出 [cls] 标记用作全局特征表示
f
f
f。通过添加可学习的位置嵌入来合并空间信息。然后,输入到 Transformer 层的输入序列可以表示为:
Z
0
=
[
x
c
l
s
;
F
(
x
p
1
)
;
F
(
x
p
2
)
;
⋯
;
F
(
x
p
N
)
]
+
P
,
\mathcal{Z}_{0}=\left[x_{\mathrm{cls}} ; \mathcal{F}\left(x_{p}^{1}\right) ; \mathcal{F}\left(x_{p}^{2}\right) ; \cdots ; \mathcal{F}\left(x_{p}^{N}\right)\right]+\mathcal{P},
Z0=[xcls;F(xp1);F(xp2);⋯;F(xpN)]+P,
其中
Z
0
\mathcal{Z}_{0}
Z0表示输入序列嵌入,
P
∈
R
(
N
+
1
)
×
D
\mathcal{P} \in \mathbb{R}^{(N+1) \times D}
P∈R(N+1)×D是位置嵌入。
F
\mathcal{F}
F是将patch映射到 D 维的线性投影。此外,使用 l 个transformer层来学习特征表示。解决了基于 CNN 的方法的有限感受野问题,因为所有的transformer层都有一个全局感受野。也没有下采样操作,因此保留了详细信息。
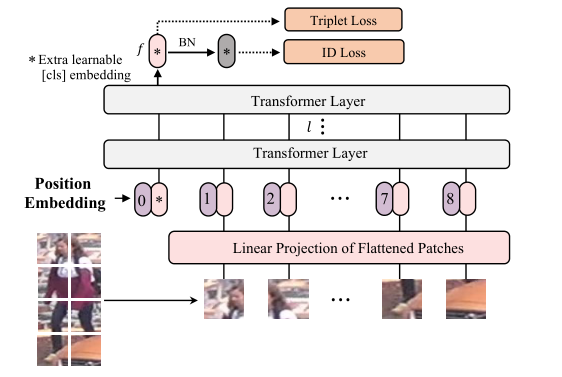
图 3:基于 Transformer 的强基线框架(显示了非重叠分区)。用 ∗ * ∗标记的输出 [cls] 标记用作全局特征 f f f。受 [27] 的启发,我们在 f f f之后引入了 BNNeck。
重叠的patch。纯基于transformer的模型(例如 ViT、DeiT)将图像分割成不重叠的patch,丢失patch周围的局部相邻结构。相反,我们使用滑动窗口来生成具有重叠像素的patch。将步长表示为
S
S
S,patch 的大小表示为
P
(
例如
16
)
P(例如16)
P(例如16),则两个相邻的 patch 重叠区域的形状为
(
P
−
S
)
×
P
(P-S) \times P
(P−S)×P。分辨率为
H
×
W
H \times W
H×W的输入图像将被分成 N 个块。
N
=
N
H
×
N
W
=
⌊
H
+
S
−
P
S
⌋
×
⌊
W
+
S
−
P
S
⌋
(
2
)
N=N_{H} \times N_{W}=\left\lfloor\frac{H+S-P}{S}\right\rfloor \times\left\lfloor\frac{W+S-P}{S}\right\rfloor\quad(2)
N=NH×NW=⌊SH+S−P⌋×⌊SW+S−P⌋(2)
其中
⌊
⋅
⌋
\lfloor\cdot\rfloor
⌊⋅⌋是底函数,
S
S
S设置为小于
P
P
P。
N
H
N_{H}
NH和
N
W
N_{W}
NW分别表示高度和宽度上的分裂patch的数量。
S
S
S越小,图像将被分割成的patch越多。直观地说,更多的patch通常会带来更好的性能,但需要更多的计算成本。
位置嵌入。由于 ReID 任务的图像分辨率可能与图像分类中的原始分辨率不同,因此此处无法直接加载 ImageNet 上预训练的位置嵌入。因此,引入了双线性 2D 插值来帮助处理任何给定的输入分辨率。与 ViT 类似,位置嵌入也是可学习的。
监督学习。我们通过为全局特征构建 ID 损失和三元组损失来优化网络。ID损失
L
I
D
\mathcal{L}_{I D}
LID是没有标签平滑的交叉熵损失。对于三元组
{
a
,
p
,
n
}
\{a, p, n\}
{a,p,n},带软margin的三元组损失
L
T
\mathcal{L}_{T}
LT如下所示:
L
T
=
log
[
1
+
exp
(
∥
f
a
−
f
p
∥
2
2
−
∥
f
a
−
f
n
∥
2
2
)
]
\mathcal{L}_{T}=\log \left[1+\exp \left(\left\|f_{a}-f_{p}\right\|_{2}^{2}-\left\|f_{a}-f_{n}\right\|_{2}^{2}\right)\right]
LT=log[1+exp(∥fa−fp∥22−∥fa−fn∥22)]
3.2. Jigsaw Patch Module
尽管基于transformer的强基线可以在目标 ReID 中实现令人印象深刻的性能,但它利用来自整个图像的信息来进行目标 ReID。然而,由于遮挡和错位等挑战,我们可能只能对物体进行部分观察。学习细粒度的局部特征(例如条纹特征)已被广泛用于基于 CNN 的方法来应对这些挑战。
假设输入到最后一层的隐藏特征表示为 Z l − 1 = [ z l − 1 0 ; z l − 1 1 , z l − 1 2 , … , z l − 1 N ] \mathcal{Z}_{l-1}=\left[z_{l-1}^{0} ; z_{l-1}^{1}, z_{l-1}^{2}, \ldots, z_{l-1}^{N}\right] Zl−1=[zl−10;zl−11,zl−12,…,zl−1N]。为了学习细粒度的局部特征,一个简单的解决方案是将 [ z l − 1 1 , z l − 1 2 , … , z l − 1 N ] \left[z_{l-1}^{1}, z_{l-1}^{2}, \ldots, z_{l-1}^{N}\right] [zl−11,zl−12,…,zl−1N]分成 k k k个组,以便连接共享token z l − 1 0 z_{l-1}^{0} zl−10,然后将 k k k个特征组输入用于学习 k k k个局部特征的共享transformer层,表示为 { f l j ∣ j = 1 , 2 , ⋯ , k } \left\{f_{l}^{j} \mid j=1,2, \cdots, k\right\} {flj∣j=1,2,⋯,k} and f l j f_{l}^{j} flj是第 j j j组的输出标记。但它可能无法充分利用transformer的全局依赖性,因为每个局部段只考虑连续patch嵌入的一部分。
为了解决上述问题,我们提出了一个拼图patch模块(JPM)来打乱patch嵌入,然后将它们重新分组到不同的部分,每个部分包含整个图像的几个随机patch嵌入。此外,训练中引入的额外扰动也有助于提高对象 ReID 模型的鲁棒性。受 ShuffleNet [52] 的启发,patch嵌入通过移位操作和patch混洗操作进行混洗。序列嵌入 Z l − 1 \mathcal{Z}_{l-1} Zl−1混洗如下:
-
Step1:移位操作。前 m m m个patch([cls] 标记除外)被移到末尾,即 [ z l − 1 1 , z l − 1 2 , … , z l − 1 N ] \left[z_{l-1}^{1}, z_{l-1}^{2}, \ldots, z_{l-1}^{N}\right] [zl−11,zl−12,…,zl−1N]以 m m m步移动变为 [ z l − 1 m + 1 , z l − 1 m + 2 , … , z l − 1 N , z l − 1 1 , z l − 1 2 , … , z l − 1 m ] \left[z_{l-1}^{m+1}, z_{l-1}^{m+2}, \ldots, z_{l-1}^{N}, z_{l-1}^{1}, z_{l-1}^{2}, \ldots, z_{l-1}^{m}\right] [zl−1m+1,zl−1m+2,…,zl−1N,zl−11,zl−12,…,zl−1m]。
-
Step2:patch shuffle操作。移位的patch通过 k k k组的patch混洗操作进一步混洗。
通过 shift 和 shuffle 操作,局部特征 f l j f_{l}^{j} flj可以覆盖来自不同车身或车辆部件的patch,这意味着局部特征具有全局判别能力。
如图 4 所示,与拼图patch并行,另一个全局分支是标准transformer,将
Z
l
−
1
\mathcal{Z}_{l-1}
Zl−1编码为
Z
l
=
[
f
g
;
z
l
1
,
z
l
2
,
…
,
z
l
N
]
\mathcal{Z}_{l}=\left[f_{g} ; z_{l}^{1}, z_{l}^{2}, \ldots, z_{l}^{N}\right]
Zl=[fg;zl1,zl2,…,zlN],其中
f
g
f_{g}
fg用作基于 CNN 的方法的全局特征。最后,使用 LID 和 LT 训练全局特征
f
g
f_{g}
fg和
k
k
k局部特征。总损失计算如下:
L
=
L
I
D
(
f
g
)
+
L
T
(
f
g
)
+
1
k
∑
j
=
1
k
(
L
I
D
(
f
l
j
)
+
L
T
(
f
l
j
)
)
\mathcal{L}=\mathcal{L}_{I D}\left(f_{g}\right)+\mathcal{L}_{T}\left(f_{g}\right)+\frac{1}{k} \sum_{j=1}^{k}\left(\mathcal{L}_{I D}\left(f_{l}^{j}\right)+\mathcal{L}_{T}\left(f_{l}^{j}\right)\right)
L=LID(fg)+LT(fg)+k1j=1∑k(LID(flj)+LT(flj))
在推理过程中,我们将全局特征和局部特征 [ f g , f l 1 , f l 2 , … , f l k ] \left[f_{g}, f_{l}^{1}, f_{l}^{2}, \ldots, f_{l}^{k}\right] [fg,fl1,fl2,…,flk]作为最终的特征表示。仅使用 f g f_{g} fg是一种具有较低计算成本和轻微性能下降的变体。
3.3. Side Information Embeddings
在获得细粒度的特征表示后,特征仍然容易受到相机或视角变化的影响。换句话说,训练后的模型很容易因为场景偏差而无法从不同的角度区分同一个目标。因此,我们提出了一种边信息嵌入(SIE),将非视觉信息(例如相机或视角)合并到嵌入表示中以学习不变特征。
受位置嵌入的启发,位置嵌入对采用可学习嵌入的位置信息进行编码,我们插入可学习的一维嵌入以保留边信息。特别的,如图 4 所示,SIE 与patch嵌入和位置嵌入一起被插入到transformer编码器中。具体来说,假设总共有 N C N_{C} NC摄像机ID,我们将可学习的边信息嵌入初始化为 S C ∈ R N C × D \mathcal{S}_{C} \in \mathbb{R}^{N_{C} \times D} SC∈RNC×D。如果图像的相机 ID 为 r r r,则其相机嵌入可以表示为 S C [ r ] \mathcal{S}_{C}[r] SC[r]。与在patch之间变化的位置嵌入不同,相机嵌入 S C [ r ] \mathcal{S}_{C}[r] SC[r]对于图像的所有patch都是相同的。此外,如果目标的视角可用,无论是通过视角估计算法还是人工注释,我们还可以将视角标签 q q q编码为图像的所有patch的 S V [ q ] \mathcal{S}_{V}[q] SV[q],其中 S V ∈ R N V × D \mathcal{S}_{V} \in \mathbb{R}^{N_{V} \times D} SV∈RNV×D和 N V N_{V} NV表示视角 ID 的数量。
现在的问题是如何整合两种不同类型的信息。一个简单的解决方案可能是直接将两个嵌入相加,例如 S C [ r ] + \mathcal{S}_{C}[r]+ SC[r]+ S V [ q ] \mathcal{S}_{V}[q] SV[q]。但是,由于冗余或对抗性信息,它可能会使两个嵌入相互抵消。我们建议将相机和视点联合编码为 S ( C , V ) ∈ R ( N C × N V ) × D \mathcal{S}_{(C, V)} \in \mathbb{R}^{\left(N_{C} \times N_{V}\right) \times D} S(C,V)∈R(NC×NV)×D。
最后,相机 ID 为
r
r
r和视角 ID 为
q
q
q的输入序列被送入transformer层,如下所示:
Z
0
′
=
Z
0
+
λ
S
(
C
,
V
)
[
r
∗
N
V
+
q
]
,
\mathcal{Z}_{0}^{\prime}=\mathcal{Z}_{0}+\lambda \mathcal{S}_{(C, V)}\left[r * N_{V}+q\right],
Z0′=Z0+λS(C,V)[r∗NV+q],
其中
Z
0
\mathcal{Z}_{0}
Z0是公式 2 中的原始输入序列,
λ
\lambda
λ是用于平衡 SIE 权重的超参数。由于每个patch的位置嵌入不同,但在不同图像之间相同,并且
S
(
C
,
V
)
\mathcal{S}_{(C, V)}
S(C,V)对于每个patch是相同的,但对于不同的图像可能具有不同的值。 Transformer 层能够对具有不同分布属性的嵌入进行编码,然后可以直接添加这些嵌入。
在这里,我们仅演示了 SIE 与相机和视角信息的用法,它们都是分类变量。在实践中,SIE 可以进一步扩展以编码更多种类的信息,包括分类变量和数值变量。在我们对不同基准的实验中,相机和视角信息都包含在任何可用的地方。
参考文献



