
- 1【技术经验分享】计算机毕业设计Python+Spark视频推荐系统 短视频推荐系统 视频流量预测系统 短视频爬虫 视频数据分析 视频可视化 视频大数据 大数据毕业设计 大数据毕设_短视频推荐系统 python源码
- 2Java最短路径算法知识点(含面试大厂题和源码)
- 3Zookeeper学习
- 4C语言——贪吃蛇(详解)_c语言贪吃蛇
- 5springboot+redis实现热搜_redis集成springboot用于查询热点数据
- 6零基础也能用ChatGPT写代码,简直不要太爽_chatgpt能回答代码
- 72019 新年 Flag —— Will 著_手写新年flag图片
- 8实现word2vec训练自己的词向量模型_mitie怎么训练自己的词向量模型
- 9大模型部署实战(四)——ChatGLM2-6B_centos7 部署chatglm2-6b int8模式
- 10【PaddleNLP】使用预训练模型代码解读(Stack,Pad,Tuple、utils.py,偏函数)_from utils import convert_example, create_dataload
神经网络机器翻译技术及应用(上)_机器翻译的神经机器翻译技术的运用
赞
踩
何中军,百度机器翻译技术负责人。本文根据作者2018年12月在全球架构师峰会上的特邀报告整理而成。
本报告分为以下5个部分:
-
机器翻译基本原理,介绍机器翻译原理、主要挑战、发展历程,及评价方法
-
神经网络机器翻译,介绍近年来迅速崛起的神经网络机器翻译
-
技术挑战,尽管神经网络机器翻译取得一系列较大的进展,但是仍然面临诸多挑战;
-
典型应用,机器翻译在生产、生活、学习等方面起到越来越大的作用
-
未来发展,展望未来发展趋势
机器翻译基本原理
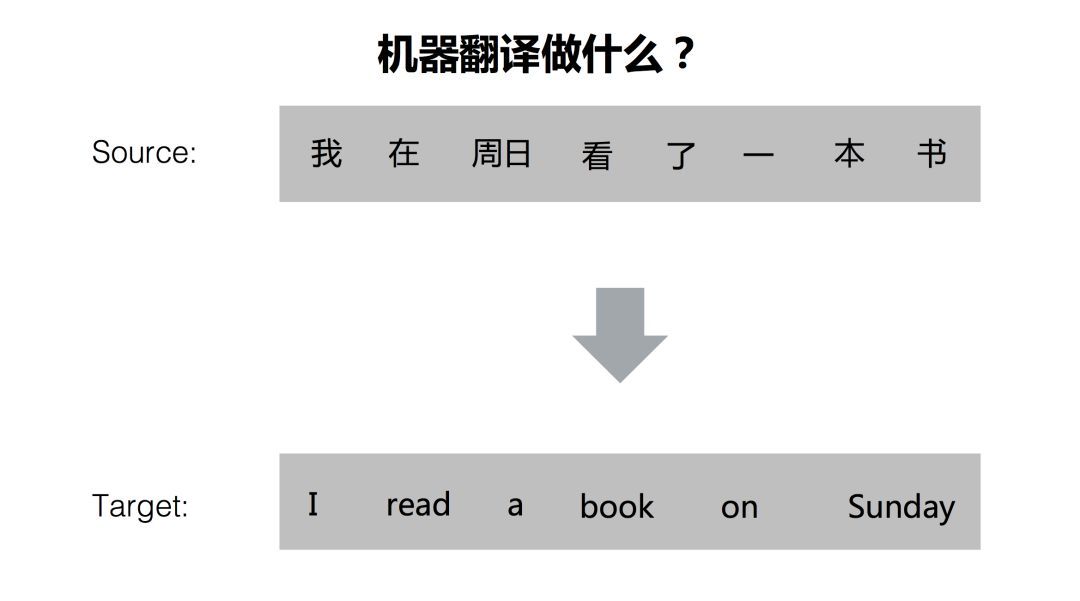
简单来说,机器翻译就是把一种语言翻译成另外一种语言,在这里,我用的例子都是从中文翻译成英文。上面的句子用Source标记,即源语言,下面用Target标记,即目标语言,机器翻译任务就是把源语言的句子翻译成目标语言的句子。
机器翻译是人工智能的终极目标之一,面临如下国际公认的挑战。

第一个挑战,译文选择。在翻译一个句子的时候,会面临很多选词的问题,因为语言中一词多义的现象比较普遍。比如这个例子中,源语言句子中的『看』,可以翻译成『look』、『watch』 『read 』和 『see』等词,如果不考虑后面的宾语『书』的话,这几个译文都对。在这个句子中,只有机器翻译系统知道『看』的宾语『书』,才能做出正确的译文选择,把『看』翻译为『read』 ,『read a book』。译文选择是机器翻译面临的第一个挑战。

第二个挑战,是词语顺序的调整。由于文化及语言发展上的差异,我们在表述的时候,有时候先说这样一个成份,后面说另外一个成份 ,但是,在另外一种语言中,这些语言成分的顺序可能是完全相反的。比如在这个例子中,『在周日』,这样一个时间状语在英语中习惯上放在句子后面。再比如,像中文和日文的翻译,中文的句法是『主谓宾』,而日文的句法是『主宾谓』,日文把动词放在句子最后。比如中文说『我吃饭』,那么日语呢就会说『我饭吃』。当句子变长时,语序调整会更加复杂。
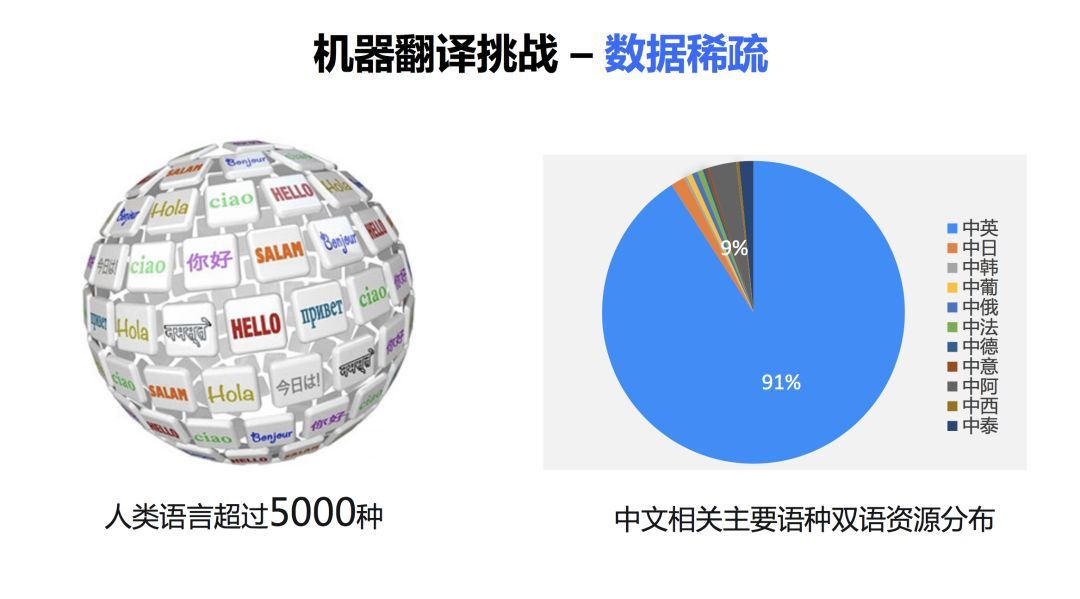
第三个挑战,数据稀疏。据不完全统计,现在人类的语言大约有超过五千种。现在的机器翻译技术大部分都是基于大数据的,只有在大量的数据上训练才能获得一个比较好的效果。而实际上,语言数量的分布非常不均匀的。右边的饼图显示了中文相关语言的一个分布情况,大家可以看到,百分之九十以上的都是中文和英文的双语句对,中文和其他语言的资源呢,是非常少的。在非常少的数据上,想训练一个好的系统是非常困难的。
机器翻译发展历程
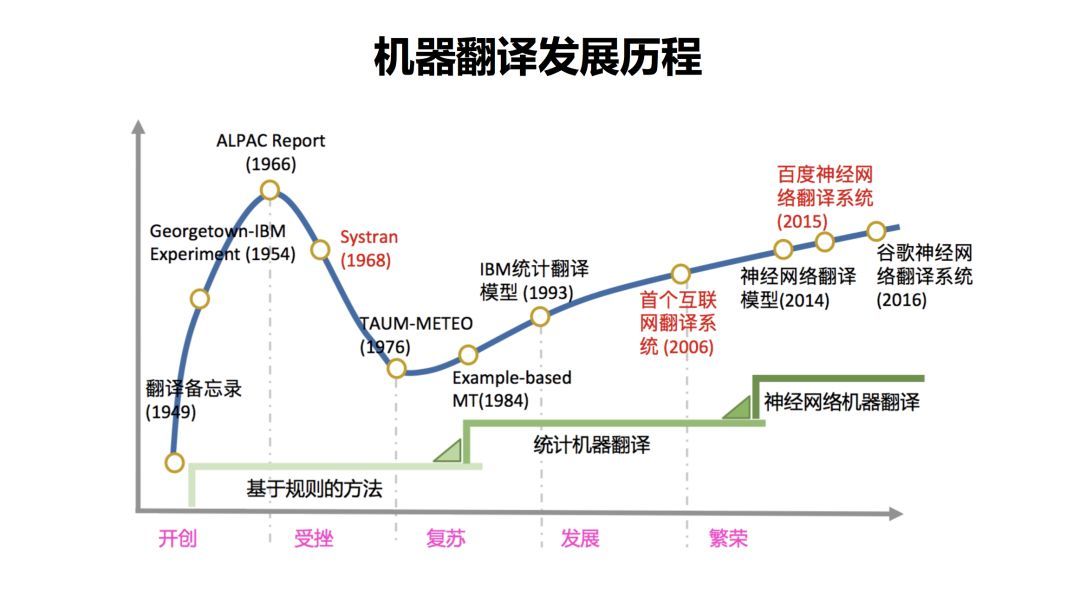
从1949年翻译备忘录提出到现在,大约过了七十多年。这期间,机器翻译经历了多个不同的发展阶段,也涌现出了很多方法。总结起来主要有三类,一开始是基于规则的方法,然后发展为基于统计的方法。一直到最近几年出现的基于神经网络的方法。下面我分别来简单介绍一下这几个方法的原理。

基于规则的翻译,翻译知识来自人类专家。找人类语言学家来写规则,这一个词翻译成另外一个词。这个成分翻译成另外一个成分,在句子中的出现在什么位置,都用规则表示出来。这种方法的优点是直接用语言学专家知识,准确率非常高。缺点是什么呢?它的成本很高,比如说要开发中文和英文的翻译系统,需要找同时会中文和英文的语言学家。要开发另外一种语言的翻译系统,就要再找懂另外一种语言的语言学家。因此,基于规则的系统开发周期很长,成本很高。
此外,还面临规则冲突的问题。随着规则数量的增多,规则之间互相制约和影响。有时为了解决一个问题而写的一个规则,可能会引起其他句子的翻译,带来一系列问题。而为了解决这一系列问题,不得不引入更多的规则,形成恶性循环。
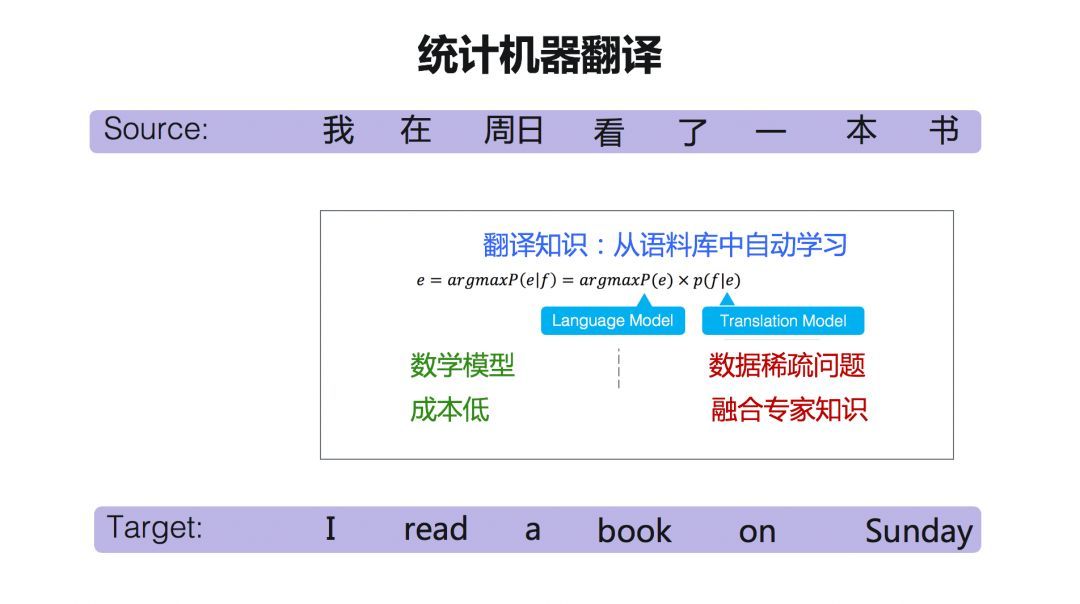
大约到了上世纪九十年代出现了基于统计的方法,我们称之为统计机器翻译。统计机器翻译系统对机器翻译进行了一个数学建模。可以在大数据的基础上进行训练。
它的成本是非常低的,因为这个方法是语言无关的。一旦这个模型建立起来以后,对所有的语言都可以适用。统计机器翻译是一种基于语料库的方法,所以如果是在数据量比较少的情况下,就会面临一个数据稀疏的问题。同时,也面临另外一个问题,其翻译知识来自大数据的自动训练,那么如何加入专家知识? 这也是目前机器翻译方法所面临的一个比较大挑战。
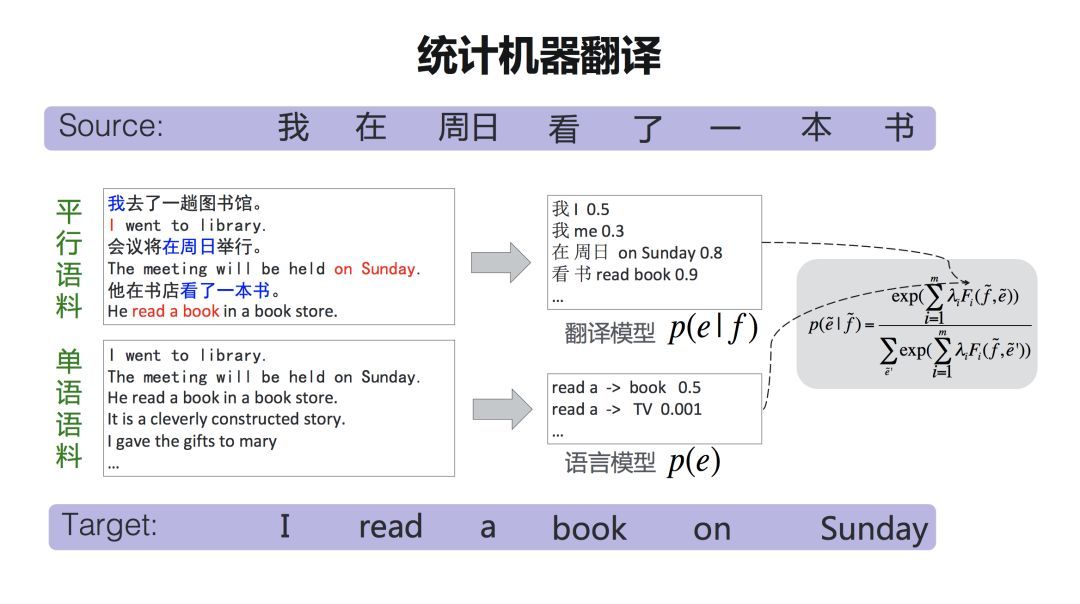
翻译知识主要来自两类训练数据:平行语料,一句中文一句英文,并且这句中文和英文,是互为对应关系的,也叫双语语料;单语语料,比如说只有英文我们叫单语语料。
从平行语料中能学到什么呢?翻译模型能学到类似于词典这样的一个表,一般称为『短语表』。比如说『在周日』可以翻译成『on Sunday』。后面还有一个概率,衡量两个词或者短语对应的可能性。这样,『短语表』就建立起两种语言之间的一种桥梁关系。
那么我们能够用单语语料来做什么呢?我们用单语语料来训练语言模型。语言模型是做什么事情的呢?就是衡量一个句子在目标语言中是不是地道,是不是流利。比如这里说『read a book』,这个表述是没有问题的,『read a 』后面跟一个『book 』这个词的概率可能是0.5,那么如果说『read a TV』呢?可能性就很低。因为这不符合目标语言的语法。
所以,翻译模型建立起两种语言的桥梁,语言模型是衡量一个句子在目标语言中是不是流利和地道。这两种模型结合起来,加上其他的一些特征,就组成了一个统计机器翻译这样的一个公式。
神经网络机器翻译
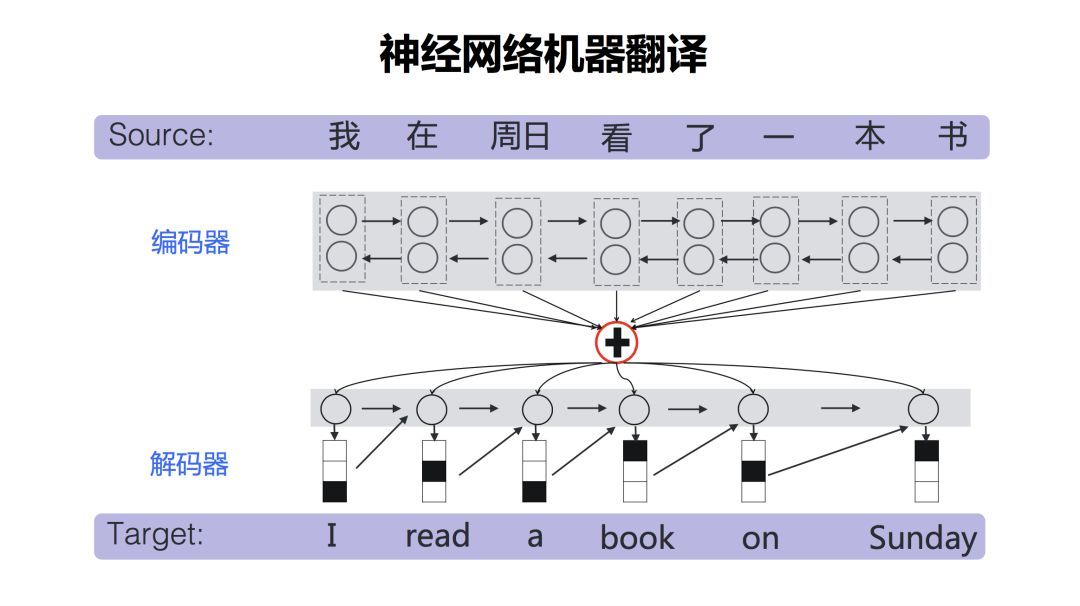
神经网络翻译近年来迅速崛起。相比统计机器翻译而言,神经网络翻译从模型上来说相对简单,它主要包含两个部分,一个是编码器,一个是解码器。编码器是把源语言经过一系列的神经网络的变换之后,表示成一个高维的向量。解码器负责把这个高维向量再重新解码(翻译)成目标语言。
随着深度学习技术的发展,大约从2014年神经网络翻译方法开始兴起。2015年百度发布了全球首个互联网神经网络翻译系统。短短3、4年的时间,神经网络翻译系统在大部分的语言上已经超过了基于统计的方法。
目前,评价机器翻译的译文质量主要有两种方式。第一种,人工评价。一说人工评价,大家第一时间就会想到『信、达、雅』,这是当年严复老先生提出来。我们用『信』来衡量忠实度,语言是为了交流的,『信』衡量译文是不是忠实地反映了原文所要表达的意思。『达』可以理解为流利度,就像刚才语言模型那样衡量的,译文是不是在目标语言中是一个流畅、地道的表达。至于『雅』,相对比较难衡量,这是仁者见仁、智者见智的。目前来说,机器翻译水平还远没有达到可以用『雅』来衡量的状态。

第二种,自动评价。自动评价能够快速地反映出一个机器翻译的质量好还是不好,相比人工评价而言,自动评价成本低、效率高。
现在一般采用的方法是,基于n-gram(n元语法)的评价方法。通常大家都用BLEU值。一般地,BLEU是在多个句子构成的集合(测试集)上计算出来的。这个测试集可能包含一千个句子或者两千个句子,去整体上衡量机器翻译系统好还是不好。有了这个测试集以后,需要有参考答案(reference)。所谓参考答案就是人类专家给出的译文。这个过程很像考试,通过比较参考答案和系统译文的匹配程度,来给机器翻译系统打分。
为了简便,此处我们用一个句子进行说明。比如说就这个句子而言,reference是『I read a book on Sunday』。那么上图中有两个系统译文,一个是system1 ,一个是system2。显见,system2的得分会更高,因为它的译文跟reference是完全匹配的,system1匹配了一些片段,但是不连续。在计算BLEU得分的时候,连续匹配的词越多,得分越高。
当然,BLEU值也有比较明显的缺点。用一个词来举例,比如『你好』,人给出的一个参考译文是『hello』。机器给出的译文是『how are you』,跟这个reference没有一个词匹配上,从BLEU值的角度来看,它得分是零。但是你能说它错吗?它翻译的很好。所以BLEU值的得分,受reference影响。Reference越多样化,匹配上的可能性就会越大。一般来说,用于评价机器翻译质量的测试集有4个reference,也有的有一个reference,也有的有十几个reference。BLEU分数受测试领域、reference多样性等多种因素的影响,抛开具体的设置,单说一个分数不具有参考性。
基于同一个测试集,针对不同的翻译系统结果,可以依据上述公式计算BLEU值,从而快速比较多个翻译系统的好坏。通常国际评测中,同时采用自动评价和人工评价方法衡量参赛系统。

这张图显示了近年来机器翻译质量的进步。这个BLEU值是在5个reference上计算出来的,衡量我们中英翻译的质量。2014年的时候,我们用的还是统计机器翻译的方法。从2015年到现在,随着神经网络翻译方法的不断进步,翻译质量一直是持续提高的。通常来说,BLEU值提高1个百分点就是非常显著的提高。在统计机器翻译时代,每年BLEU提高1个百分点都是比较大的挑战。而在神经网络翻译上线后的这四年之间,我们大约每年都有5、6个百分点BLEU值的提升。

我们通过一个例子,直观的感受一下神经网络方法的译文质量。这个例子是某一年的大学英语六级考试的翻译真题。这个例子我飘了不同的颜色,表示两种语言句子成分的对应关系。从颜色上我们可以看出来,与原文相比,译文的词语顺序发生了比较大变化。比如说,中文句子中的『尽快』, 在英语端,『as soon as possible』换到后面去了,进行了比较长距离的调序。这在统计机器翻译时代是非常难做的事情,但是神经网络翻译能够把它处理的很好。
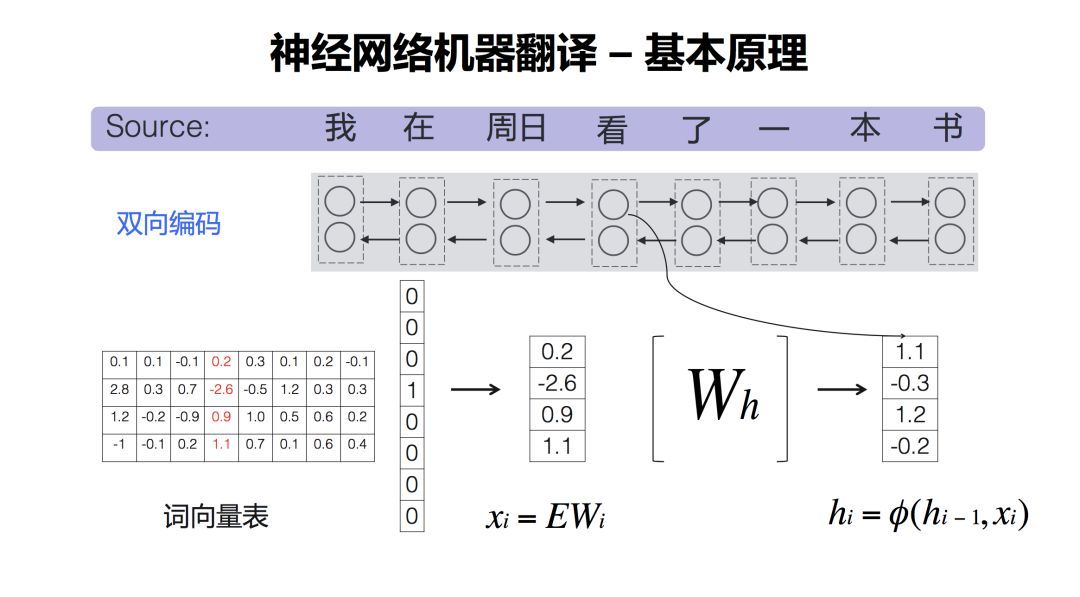
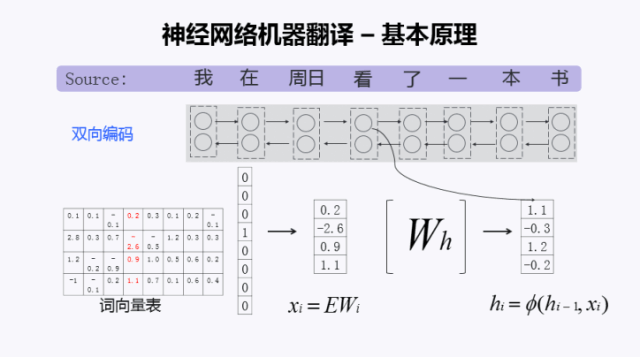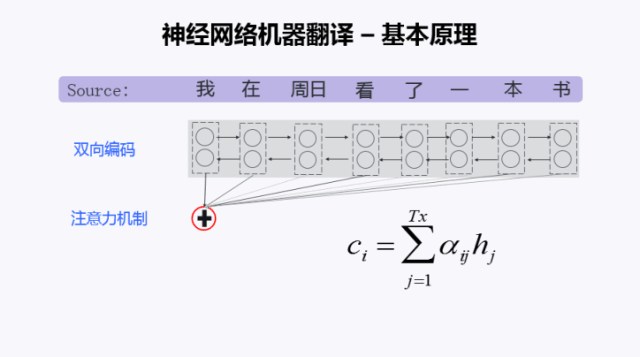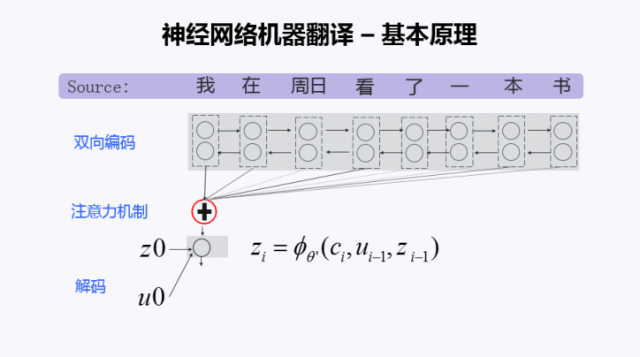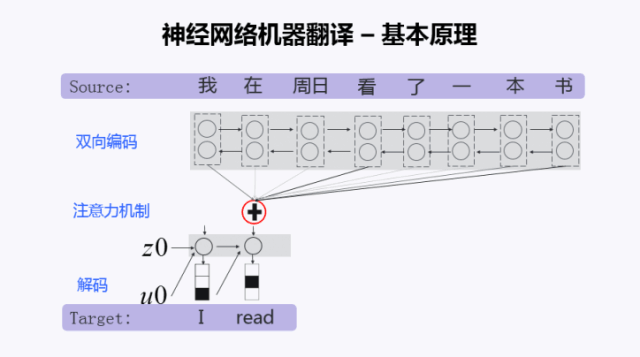
刚才说的它包含编码器和解码器,先来看编码器。它进行了一个双向的编码,双向的编码干了一个什么事情?就是把词用词向量来表示。那么如何做到这一点呢?我们首先有一个词向量表,是通过神经网络训练出来的。源语言句子中的词,可以用一个one hot的向量表示。所谓one hot就是,比如上例中中文句子有8个词。哪个词出现了,就把这个词标为1,其他的词标为0。比如第4个词“看”这个词是1,那么其他的都是0。这两个矩阵这么一乘,相当于一个查表的操作。就把其中这个词向量表的一列取出来了,那么这一列的向量就代表了这个词。神经网络里面所有的词都会用向量来表示。得到词的向量表示后,再经过一个循环神经网络的变换,得到另外一个向量,称为Hidden State(隐状态)。
为什么做了一个双向的编码?是为了充分利用上下文信息。比如说,如果只是从左往右编码,“我在周日看”,看的是什么呢?“看”后面的你不知道,因为你只得到了“看”前面的信息。那么怎么知道后面的信息呢,这时候我们就想那能不能从后面到前面再进行一个编码,那就是“书本一了看”,从后面往前的编码,这时候“看”呢既有前面的信息,也有后面的信息。所以它有了一个上下文的信息,可以进一步提高译文质量。
刚才提到,每个词经过一系列变换,映射为一个向量表示。如果将双向编码的向量结合起来呢? 现在一般采用一个非常简单的方法,将两个向量进行拼接。比如两个256维的向量,拼接完成后得到一个512维的向量,用来表示一个词。
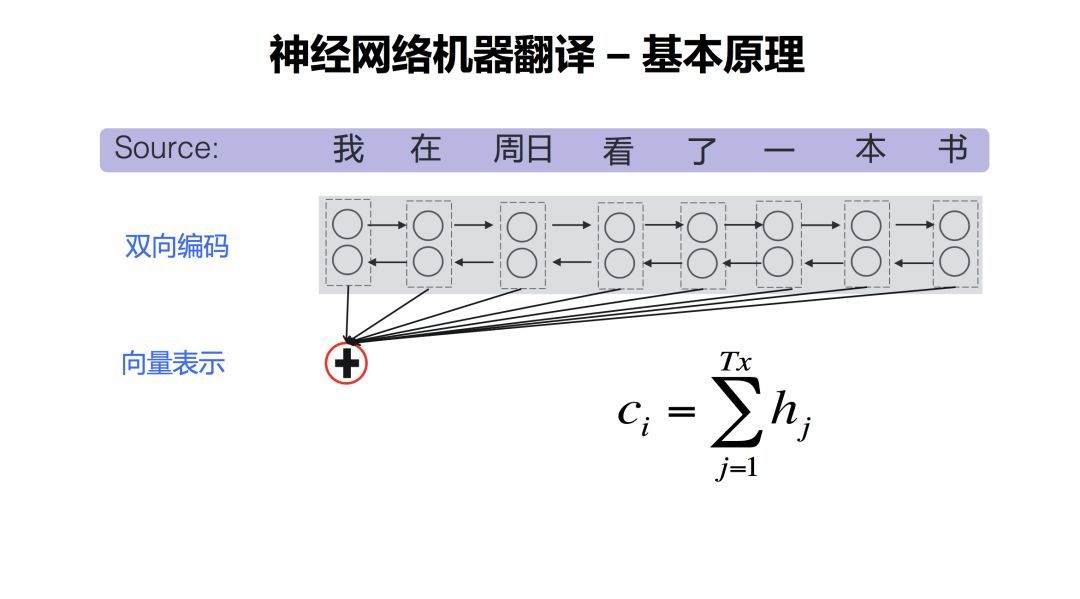
编码完成以后,需要把这个源语言的句子压缩到一个向量里去。这一步是怎么做的?一个最简单的方式是把这所有的向量加起来。但是后来大家发现这样其实不太合理。为什么不太合理,因为每一个词都是被作为相同的权重去对待的,那显然是不合理的,这时候就提出了一个注意力机制,叫Attention。这里用不同深度颜色的线去表示Attention的能量强弱,用以衡量产生目标词时,它所对应的源语言词的贡献大小。所以呢h前面又加一个α,α就表示它的一个权重。
有了句子的向量表示后,就掌握了整个源语言句子的所有的信息。解码器就开始从左到右一个词一个词的产生目标句子。在产生某个词的时候,考虑了历史状态。第一个词产生以后,再产生第二个词,直到产生句子结束符EOS(End of Sentence) ,这个句子就生成完毕了。
近年来,神经网络机器翻译的蓬勃发展,除了得益于强大的算力、创新的算法、海量的数据外,还有一个重要因素,是开源工具和平台,大大降低了系统开发成本。国内外均有优秀的深度学习平台供大家使用。国外的有Google的Tensorflow、Facebook的PyTorch等,国内,我们也推出了首个自主研发的深度学习平台PaddlePaddle,并开放了多个业界领先的模型。这些开源平台的出现,大大降低了开发门槛。无论是研究人员,还是开发者,都可以在开源平台上方便的开展研究、开发系统。

去年以来出现了一个大杀器,TRANSFORMER。基本上取得了目前来说神经网络机器翻译最好的效果。TRANSFORMER的改进在哪里,来源一篇谷歌的论文,叫“Attention Is All You Need”。上文提到有一个注意力机制,这篇论文所提出的方法,可以只用注意力机制就把翻译搞定了。
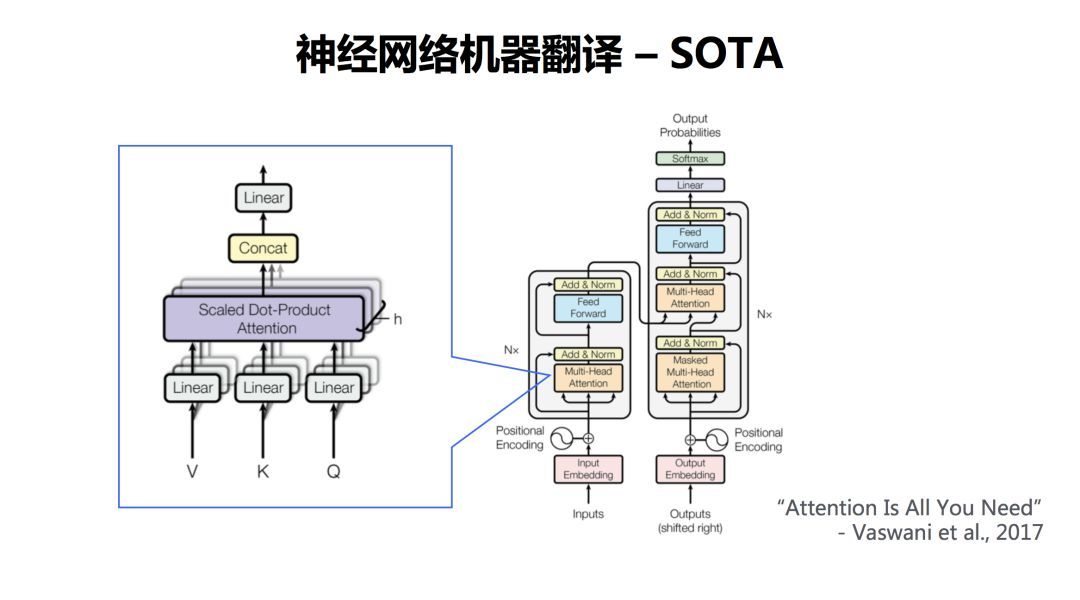
那么它是怎么来做的呢?它其实也有一个编码器和一个解码器,这个是架构是没有变的。其中编码器和解码器都有多层。下面我们通过一个具体例子,来简单解释一下其原理。
我们这个句子就包含两个词 『看书』。
论文中,把每一个词都用三个向量表示,一个叫Query(Q),一个叫Key(K),另外一个是Value(V)。那怎么得到一个词的Query、Key和Value呢?左边有三个矩阵,WQ、WK和WV,只要跟每一词向量相乘,就能够把这个词转换成三个向量表示。那么目标是什么,我们想把『看』这样一个词,通过一系列的网络变换,抽象到高维的向量表示。
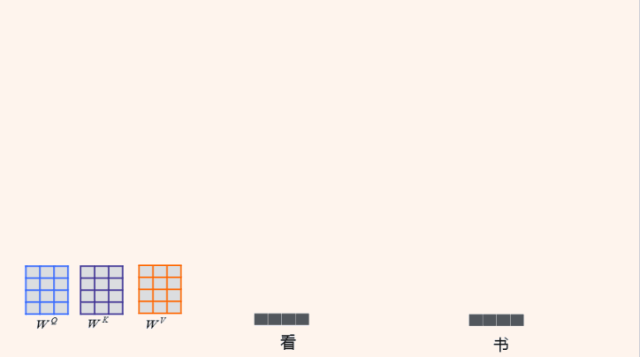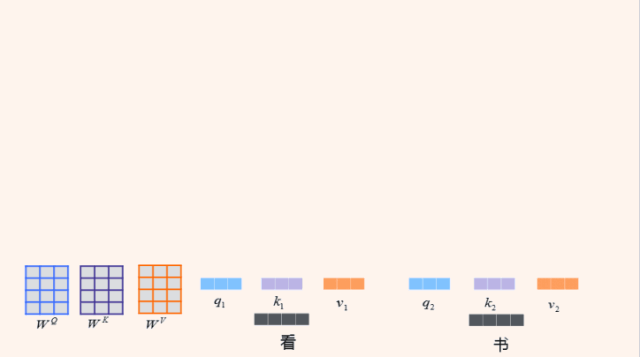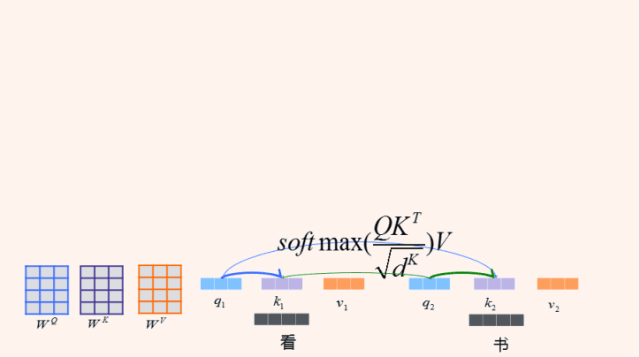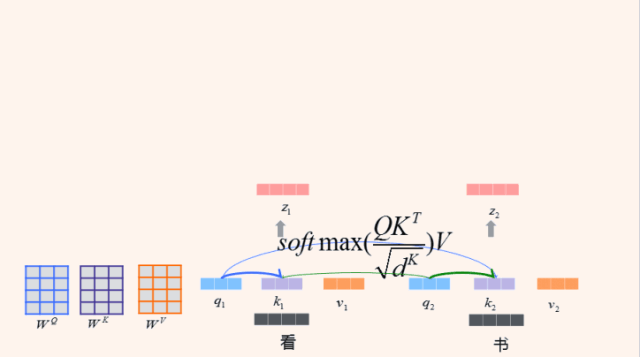
通过Q和K进行点积,并通过softmax得到每个词的一个attention权重,在句子内部做了一个attention,称作Self Attention。Self Attention可以刻画句子内部各成分之间的联系,比如说“看”跟“书”之间就建立了联系。这样,每个词的向量表示(Z)就包含了句子里其他词的关联信息。

作者认为只有这一个QKV不太够,需要从多个角度去刻画。如何做呢?提出了“Multi-head”。在里面论文里面定义了8组QKV的矩阵,当然也可以定义16个,这个数值可以自定义。在通过一系列变换,最终得到了每个词的向量表示。这只是encoder一层。那么这一层的输出做为下一层的输入,再来一轮这样的表示,就是Encoder-2,那么再来一轮就是第三层,如此一直到第N层。Decoder也是类似,不再解释。感兴趣的可以阅读原文。
技术挑战
尽管神经网络带来了翻译质量的巨大提升,然而仍然面临许多挑战。
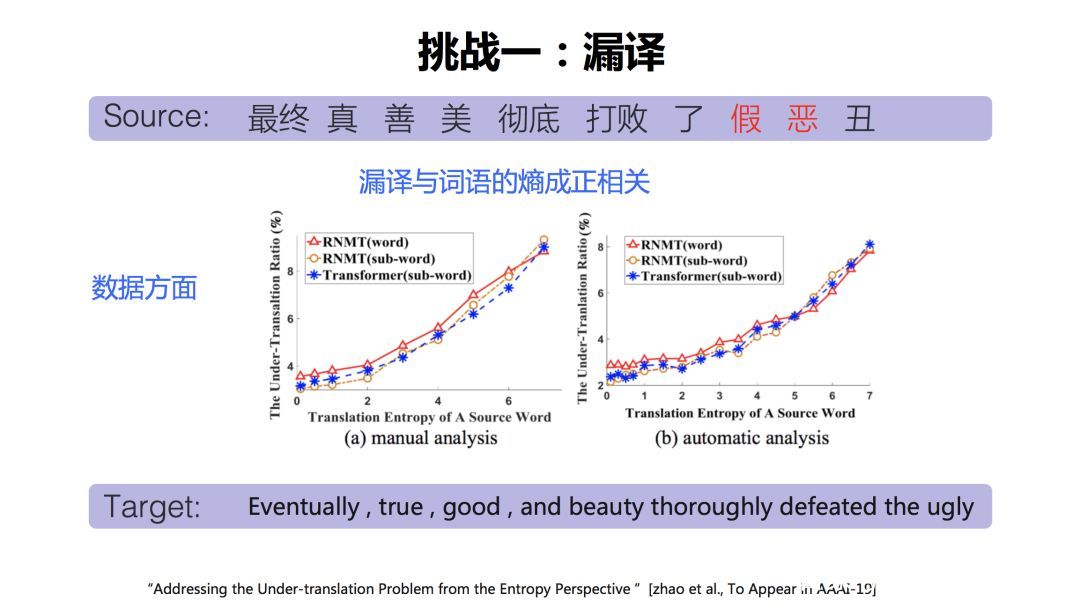
第一个挑战就是漏译,很多时候,原语言句子有些词没有被翻译出来,比如说在这个句子里面,『假』和『恶』没有被翻译出来。甚至有的时候输入一个长句子有逗号分隔,有几个子句都没有翻译出来。这确实是神经网络翻译面临的一个问题。通过刚才的讲解知道,翻译模型把原文句子整体读进去以后形成了一个向量,然后再对这个向量进行解码。翻译模型认为有些词不应该产生,从而漏掉了译文。
漏译的原因是什么,如何解决这个问题?这方面有很多工作,下面我就从几个方面去讲一下。我们今年有一篇论文从数据方面去分析。我们发现漏译与词语的熵成正相关关系,这个词的熵越大,漏译的可能性越大。它所对应的目标语言词越多,概率越分散(熵越大),越有可能被漏译。
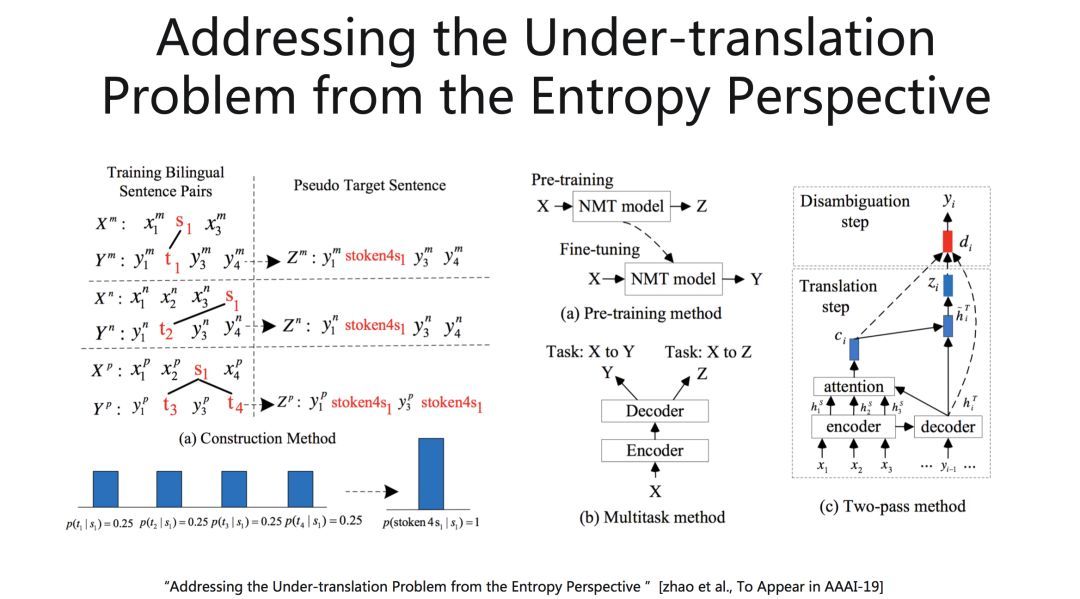
左边的例子,S1对应3种不同的翻译,(s1,t1) (s1,t2) (s1, t3 t4),它的熵就比较大。我们把所有对应的翻译统一替换为一个特殊词『stoken4s1』,以降低词语翻译的熵值。右边呢是我们提出来的三种方法,去改善翻译结果,包括pre-training, multitask learning, two-pass decoding。大家有兴趣的话,可以去看论文。
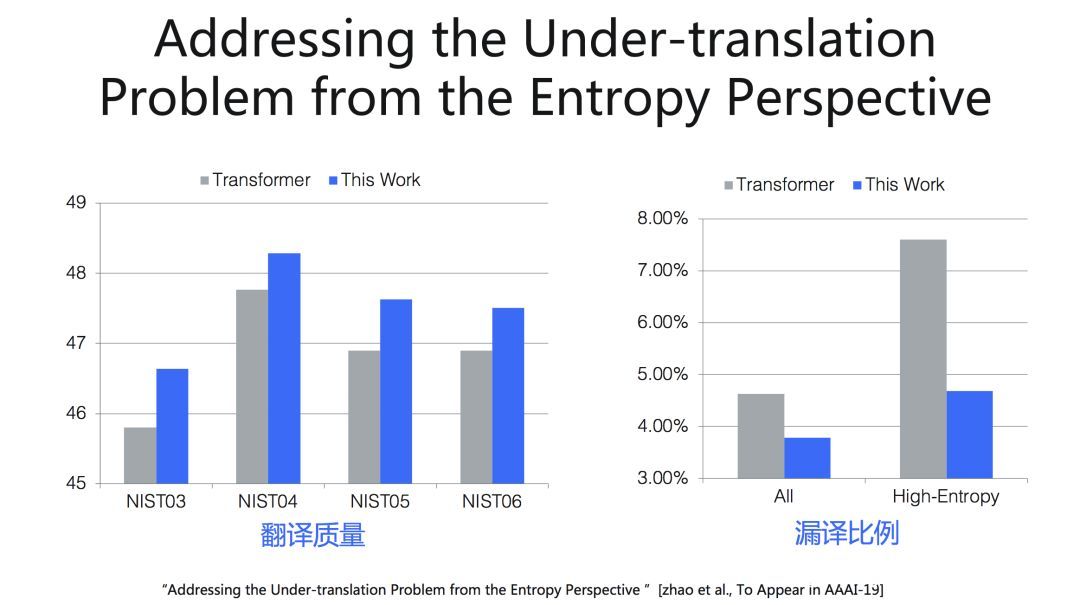
从实验结果来看,相比Transformer,在中英翻译质量上有显著提高,高熵值词语的漏译比例显著下降。
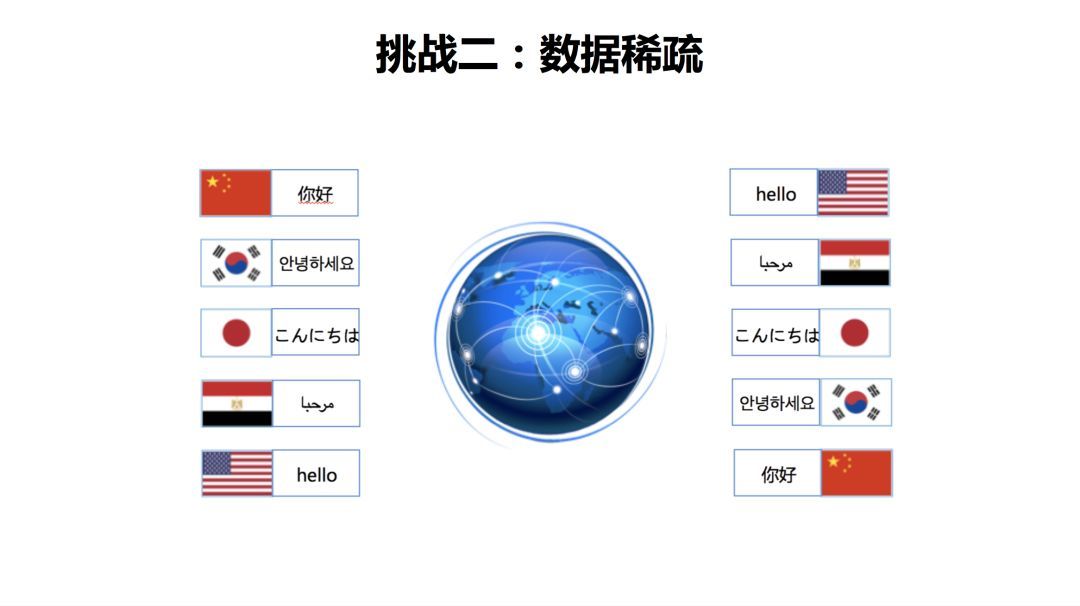
第二个挑战就是数据稀疏。相比于统计机器翻译,这个问题对神经网络翻译而言,更严重。实验表明,神经网络对于数据量更敏感。
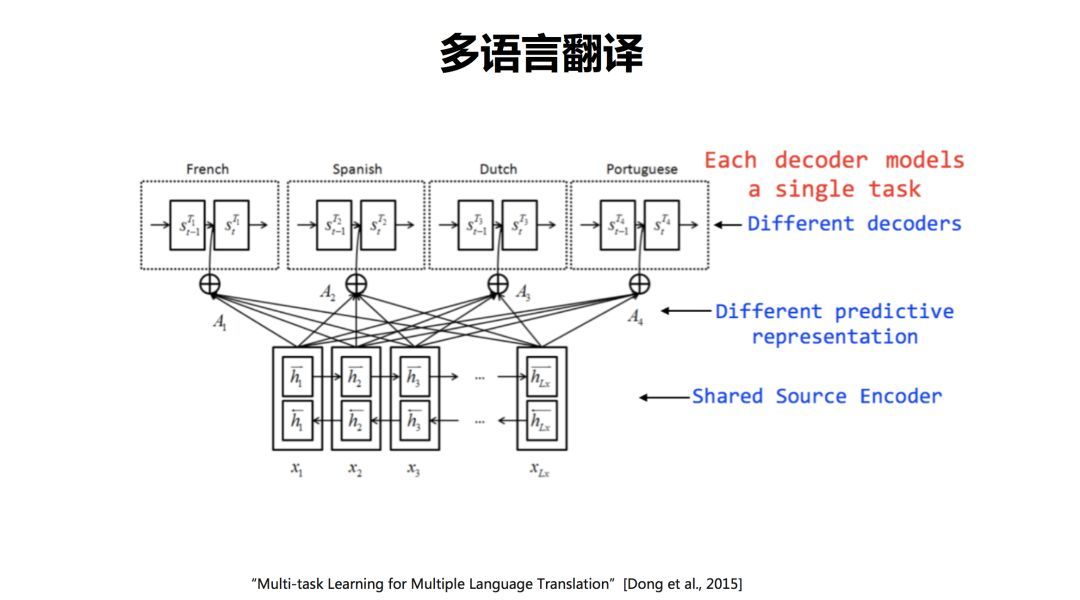
针对数据稀疏问题,我们提出了一个多任务学习的多语言翻译模型。在进行多语言翻译的时候,源语言共享编码器,在解码端,不同的语言,使用不同的解码器。这样在源语言端就会共享编码器的信息,从而缓解数据稀疏问题。后来,加拿大蒙特利尔大学、Google等在此方向上陆续开展了多个工作。

实验表明,我们的方法收敛更快,翻译质量也明显提高。更多细节,请阅读论文。
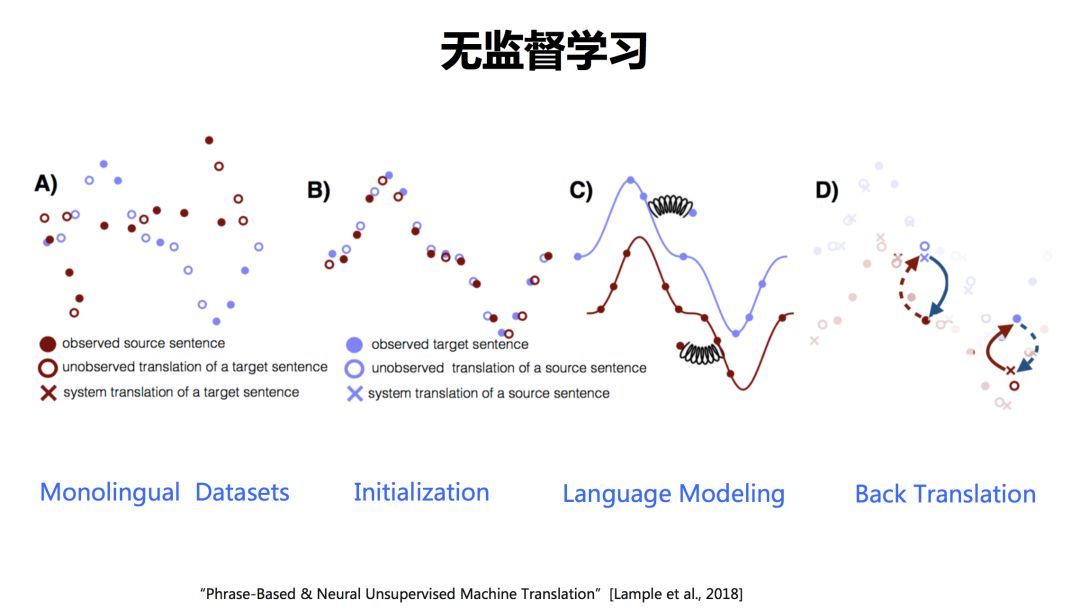
这篇论文是2018年EMNLP上的best paper,提出了一个统一的框架。A)里面蓝色的点和红色的点分别代表两种不同的语言句子。如何通过两种语言的单语数据构建翻译系统呢?
首先我要做一个初始化,B)是初始化。首先构建一个词典,把这两种语言之间的词做一下对齐。C)是语言模型,基于单语数据,可以训练语言模型,用来衡量这个语言的流利度。那么D)是什么? D)是一个称作Back Translation的技术,是目前大家常用的一个用于增强数据的方法。
用B)初始化后构建的一个词典,就可以从一种语言翻译为另外一种语言,哪怕是先基于词的翻译。然后,用另外一种语言的语言模型去对译文进行衡量。然后把得分高的句子挑出来,再翻译回去,这一过程称作Back Translation,然后再用原来那种语言的语言模型去衡量这个句子好还是不好。这样一轮一轮的迭代,数据就会变得越来越好,系统翻译质量也会越来越好。
第三个挑战就是引入知识,如何将更多丰富的知识引入翻译模型是机器翻译长期面临的挑战。这个例子中,中文句子中『横流』对应到目标语言端是没有翻译出来的,用一个特殊的记号叫UNK(Unknown Word)来标记。
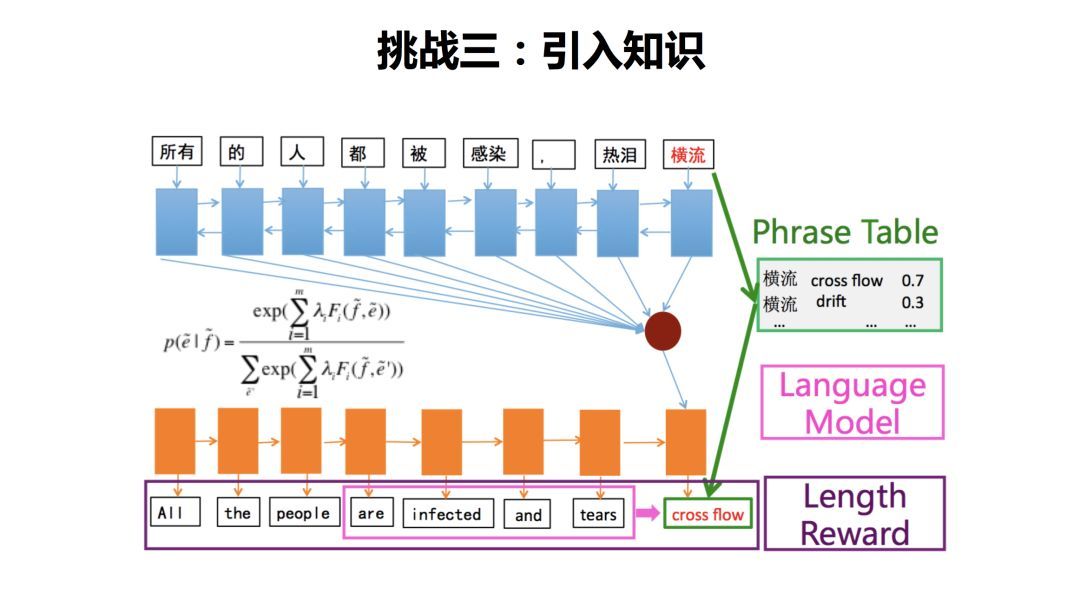
那么我们做一个什么样的工作呢?我们引入了几种知识,第一种就是叫短语表或者叫词表。如果发现『横流』这个词没有被翻译出来,我们就去查这个词典,这个词典就作为一个外部知识被引入进来了。同时,那我们还引入了一个语言模型,语言模型去衡量目标语言的这个句子是不是流畅。同时,我们引入一个长度奖励特征去奖励长句子。因为句子越长,可能漏掉的信息就越少。这个工作首次将统计机器翻译中的特征引入神经网络翻译,可以作为引入知识的一个框架。

但是目前来说,引入知识还是比较表层的。知识的引入,还需要更多更深入的工作。比如说这个例子, 这个句子是存在歧义的。『中巴』 在没有给上下文的时候,是无法判断『巴』是哪个国家的简称。
但是下面的句子,有一个限定,“金砖框架”。这个时候,人们就知道该如何翻译了。但是,机器能不能知道?大家可以去翻译引擎上去验证。因为人是知道中国跟哪些国家是金砖国家,但是机器没有这个知识。怎么把这个知识交给机器去做,这是一个非常挑战的问题。

还有一个挑战,是可解释性:神经网络翻译到底是神还是神经?虽然人们可以设计和调整网络结构,去优化系统,提高质量。但是对于该方法还缺乏深入的理解。
也有很多工作去试图研究网络内部工作机理。清华大学有一篇文章从注意力的角度去进行研究。

比如左边的例子,出现了一个UNK,那个UNK是怎么产生的,它虽然没有被翻译出来,但是出现在正确的位置,占了一个位置。通过Attention对应关系,可以看到这个UNK对应到『债务国』。右边例子是一个重复翻译的现象。神经网络机器翻译除了经常漏翻译之外,还会经常重复翻译。比如说出现了两个“history”。那么通过这个对应关系我们就可以看到,第6个位置上的“history”是重复出现的,它的出现不仅跟第一个位置“美国人”和第二个位置“历史”相关,还跟第5个位置“the”相关。因为产生了一个定冠词“the”,模型认为这个地方应该出现一个“history”,这篇文章对这样的例子进行了大量的分析,并且给出了一些分析结果和解决方案。如需进一步了解,可以看原始论文。
还有第五个挑战 ,是机器翻译长期以来面临的挑战,语篇翻译。大部分的翻译系统现在所使用的翻译方法都是基于句子,以句子作为单位,一个句子一个句子的进行翻译。单看这三个句子翻译还可以接受。但是连起来看就觉得生硬不连贯。

我们的方法输出的结果。可以看到,定冠词、代词的加入提升了句子间的连贯性。
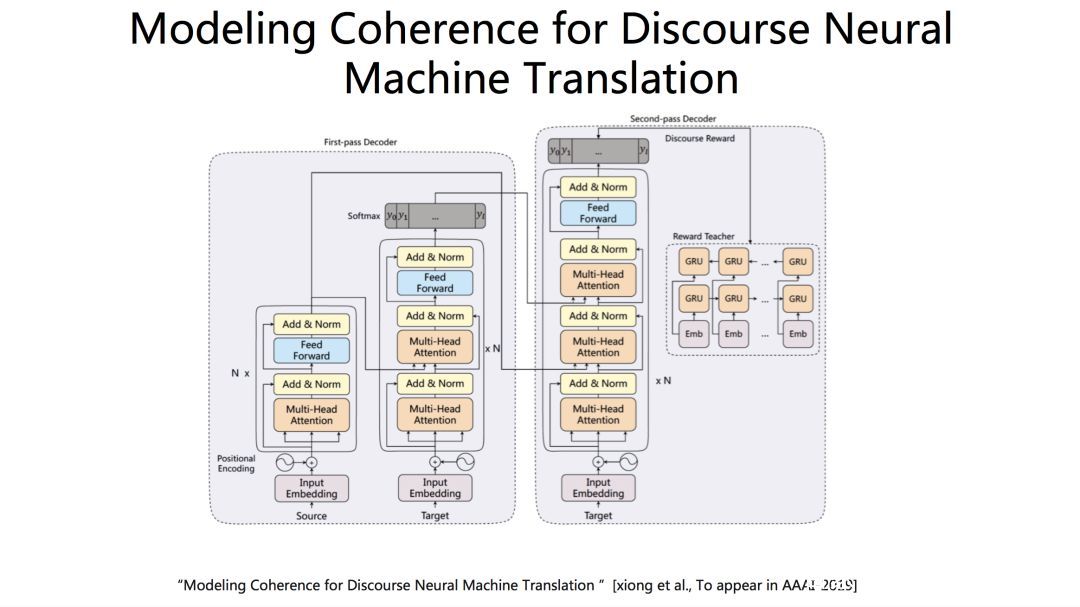
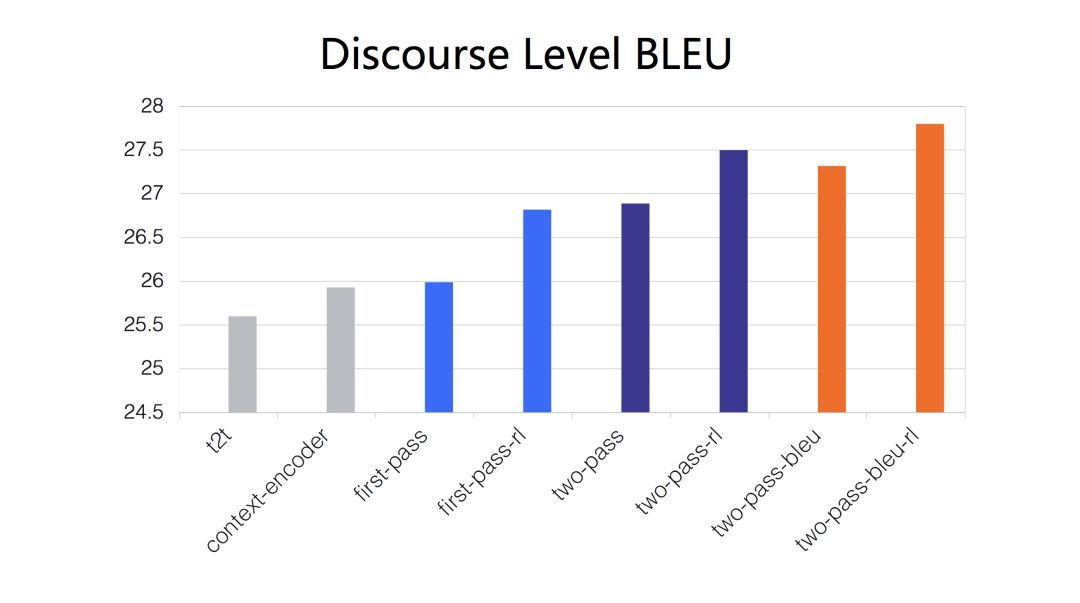
我们提出了一个两步解码的方法。在第一轮解码中单独生成每个句子的初步翻译结果,在第二轮解码中利用第一轮翻译的结果进行翻译内容润色,并且提出使用增强式学习模型来奖励模型产生更流畅的译文。这是我们系统输出的一个结果,整体上,流畅度提高了。 具体细节,可以去看论文。
至此,“神经网络机器翻译技术及应用”的技术介绍篇结束,下期即将推出下篇,介绍神经网络机器翻译的典型应用及未来展望,敬请期待。

