
热门标签
热门文章
- 1C语言学习 求1到N的和_输入一个数求出由1加至此数的总和 输入格式: 一个正整数n, 处理到文件结束。
- 2修改conda环境安装路径,解决环境默认安装在C盘问题_conda可执行文件路径怎么选
- 3ES简单教程(三)使用ElasticsearchRestTemplate多条件分页查询(简单版)_elasticsearchresttemplate 分页
- 4打印机没有反应计算机管理,电脑重启后打印机驱动无反应怎么办
- 5安装和使用ArchLiunx超详细教程_sudo pacman -s kazam
- 6AI工具合集,互联网人必备百宝箱!
- 7在LLVM中可视化代码结构_llvm 可视化
- 8国产免费代码助手Fitten Code测评
- 9记录安装torchtext会自动更新pytorch版本导致gpu加速失效问题_torch1.8.1 torchtext
- 10[22007] [Microsoft][ODBC Driver 17 for SQL Server][SQL Server]从字符串转换日期和/或时间时,转换失败。 (241)过滤非法日期格式数据_从字符串转换日期和/或时间时,转换失败。
当前位置: article > 正文
多模态商业应用_淘宝视频多模态应用
作者:我家小花儿 | 2024-04-01 17:00:44
赞
踩
淘宝视频多模态应用
最近在研究多模态技术,发现这个领域确实是一片蓝海。所谓多模态,简单的理解就是不同于 CV,NLP 在单个领域的研究,它融合了音频、视频、文本、商品模态等信息,为不同下游任务提供强有力的技术支持。在这篇文章中,我将整理自己最近浏览的知识(也是作为自己回顾的资料)。
短视频多模态应用
代表应用:淘宝视频分类,阿里文娱多模态视频分类,抖音短视频分类
淘宝视频多模态AI算法
在淘宝,短视频业务一直非常重要,视频销售已经成为品牌方最爱的营销方式。如何对规模庞大的视频进行内容化理解并个性化推荐变得极为重要。
算法框架
淘宝短视频的信息是十分丰富的,有视频/封面图/文本/音频/商品等模态,分别刻画短视频不同维度的信息。为了建立高效准确的视频分类算法,淘宝团队提出了以下算法框架:
(1) 预训练模型的选择
(2) 模态融合方法的设计
(3) 多目标的分类器的设计
预训练模型的选择
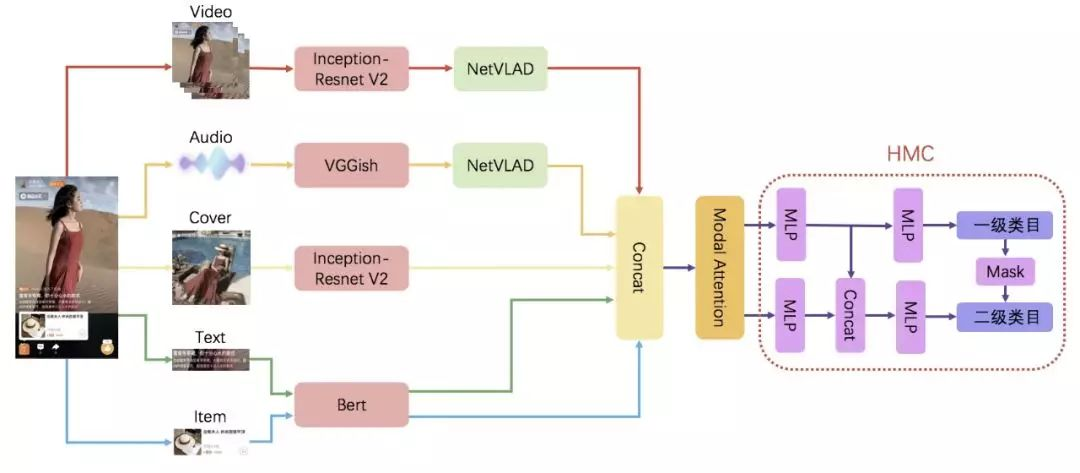
使用预训练模型进行迁移学习能够加速 loss 收敛并显著提升下游任务的准确率。
(1) 视频模态: 在淘宝应用中,视频模态具体指视频和封面图。淘宝团队选择了 Inception-Resnet v2 1 作为视频特征提取的模型,该模型既能通过堆叠不同的 Inception Block 增加网络的宽度提高算法准确度,又通过加入 ResNet 的残差学习单元缓解网格退化问题,有效提高了视频特征的泛化性。
视频特征序列相较于普通的图像特征包含了更加丰富的信息,不同特征之间具有时序相关性。淘宝团队 采用 NetVLAD 2 作为视频特征聚合网络,该网络以 CNN 结构为基础,通过聚类中心将视频序列特征转化为多个视频镜头特征,然后通过学习权重对多个视频镜头加权求和获得全局特征向量。
(2)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/349650
推荐阅读
相关标签

