
- 1解析泛微Ecology信息泄露&任意用户登录漏洞背后的威胁_ecology10
- 2ArcEngine教程(三)——图层的基本操作_arcengine 加载图层
- 3Centos6.X升级至Centos7.2升至Centos7.9详细步骤和踩过的坑(升级者必看~)_centos6.3升级到7.9
- 4使用druid连接池连接postgre数据库情况下出现Cannot commit when autoCommit is enabled异常解决办法,经过排查结果竟是druid的bug_cannot commit when autocommit is enabled.
- 5Maven系列第3篇:详解maven解决依赖问题_import org.springframework.web.bind.annotation
- 62018人工智能国际学术会议--投稿截止日期汇总_icia投稿时间
- 7pip install tensorflow报错ERROR: Could not find a version that satisfies the requirement tensorflow (f
- 8AI辅写疑似度检测软件大盘点
- 9appium测试ios应用遇到的问题_appium测试ios如何过去sessionid
- 10算法分析 | 回溯法 | 01背包问题_01背包问题回溯法时间复杂度
视觉3D感知(三):双目深度估计
赞
踩
双目感知
优势:
- 单目3D感知依赖于先验知识和几何约束
- 深度学习的算法非常依赖于数据集的规模、质量以及多样性
- 双目系统解决了透视变换带来的歧义性
- 双目感知不依赖于物体检测的结果,对任意障碍物均有效
劣势:
- 硬件:摄像头需要精确配准,车辆运行过程中也要始终保持配准的正确性
- 软件:算法需要同时处理来自两个摄像头的数据,计算复杂度较高
双目深度估计
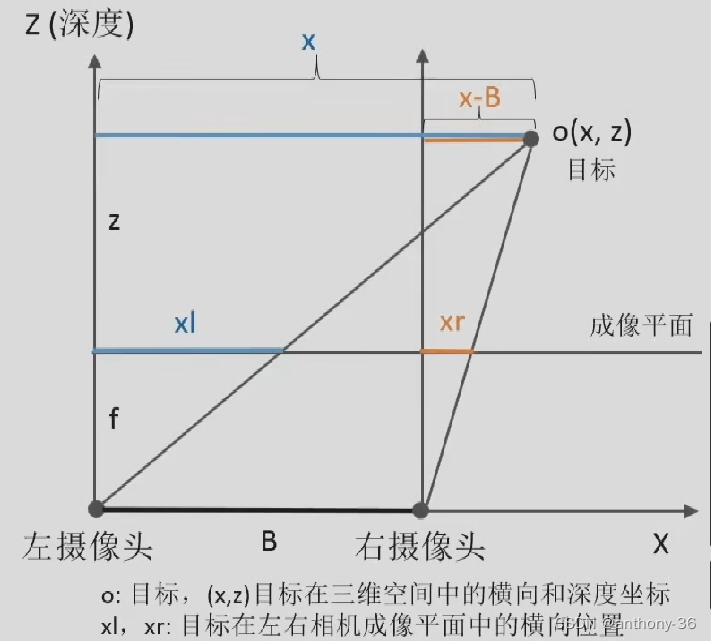
基本原理
1.概念和公式
根据相似三角形,得到
{
f
/
z
=
x
l
/
x
f
/
z
=
x
r
/
x
−
B
只有
x
和
z
是未知变量
根据相似三角形,得到
得到下列式子:
Z = f B / d Z=fB/d Z=fB/d
2.视差估计:对于左图中的每个像素点。需要找到右图中与其匹配的点。
- 对于每个可能的视差(范围有限),计算匹配误差,因此得到的三维误差数据称为Cost Volume。、
- 计算匹配误差时考虑像素点附近的局部区域,比如对局部区域内所有对应像素值的差进行求和。
- 通过Cost Volume可以得到每个像素处的视差(对应最小匹配误差的),从而得到深度值。
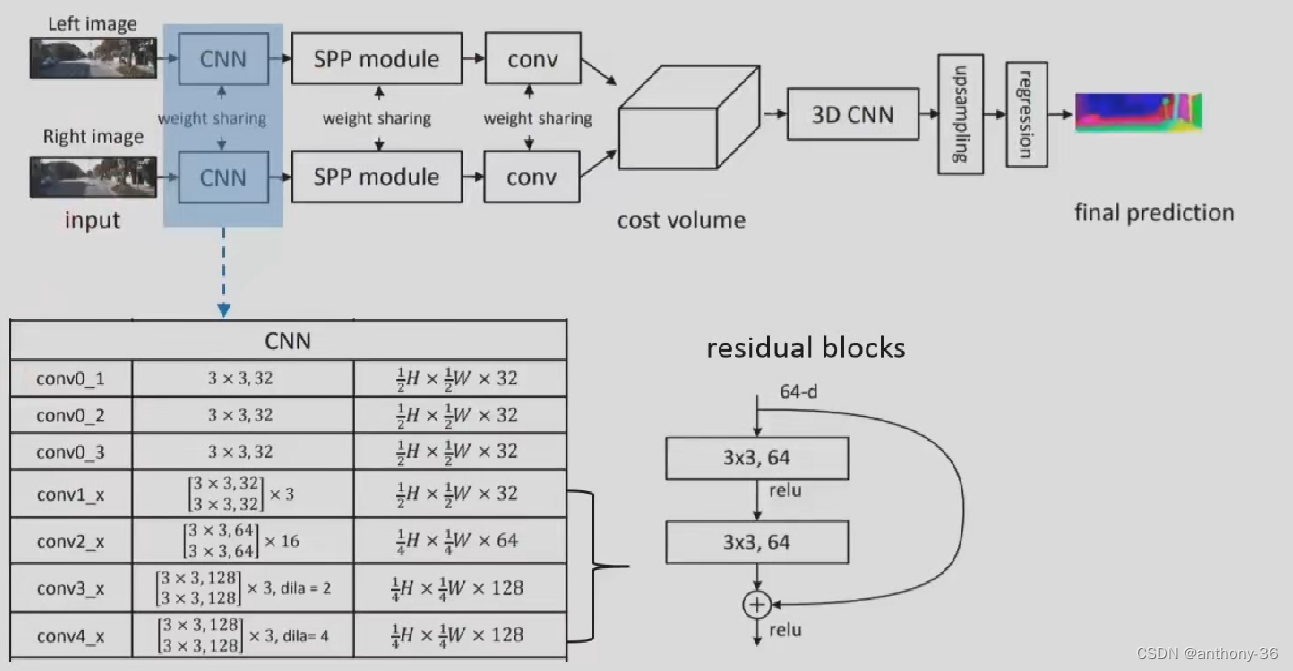
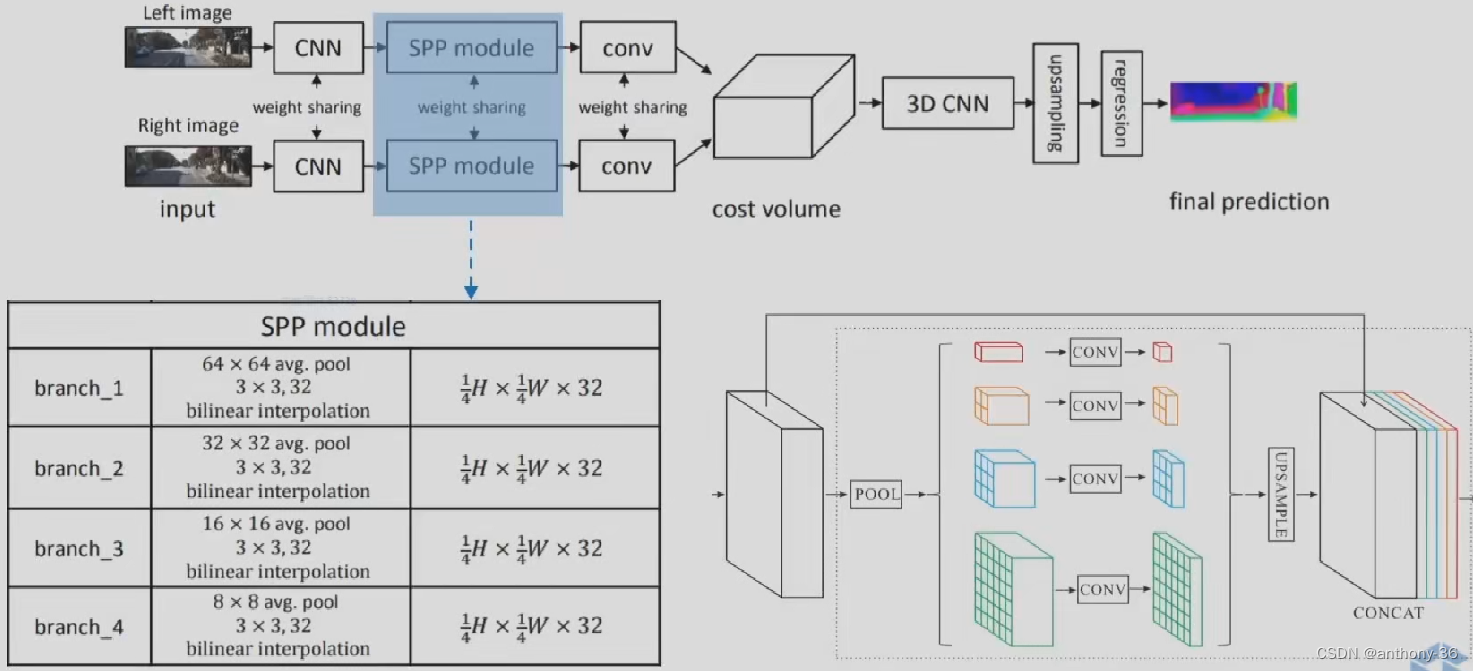
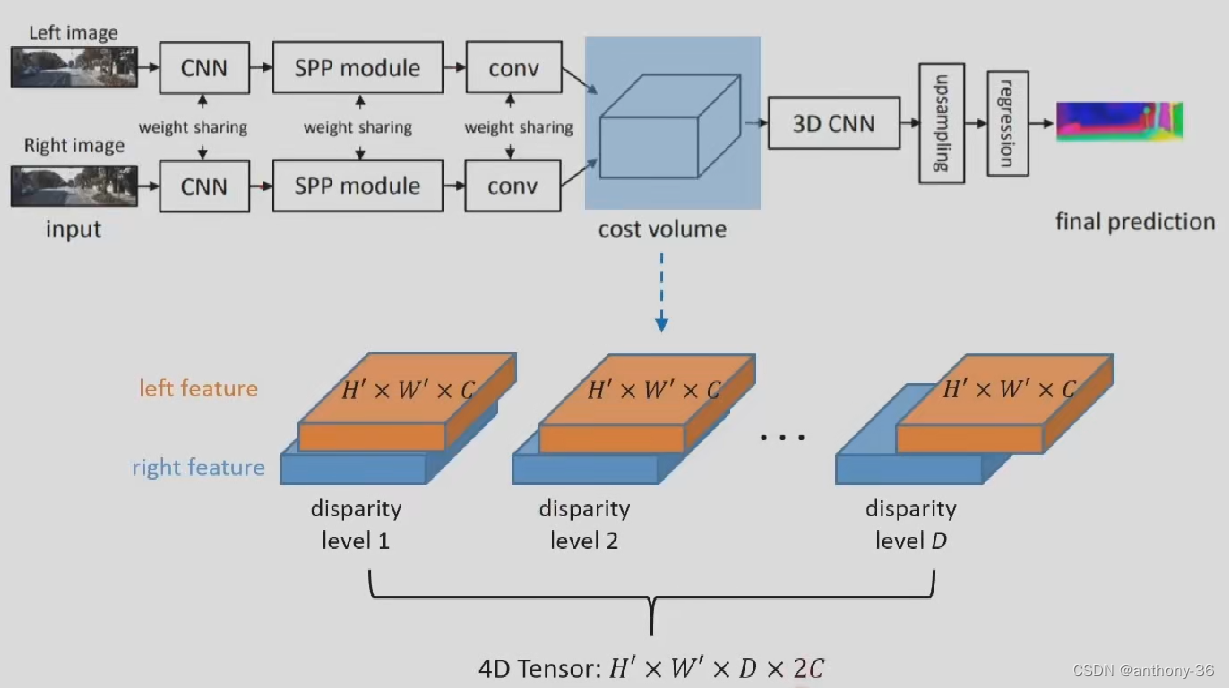
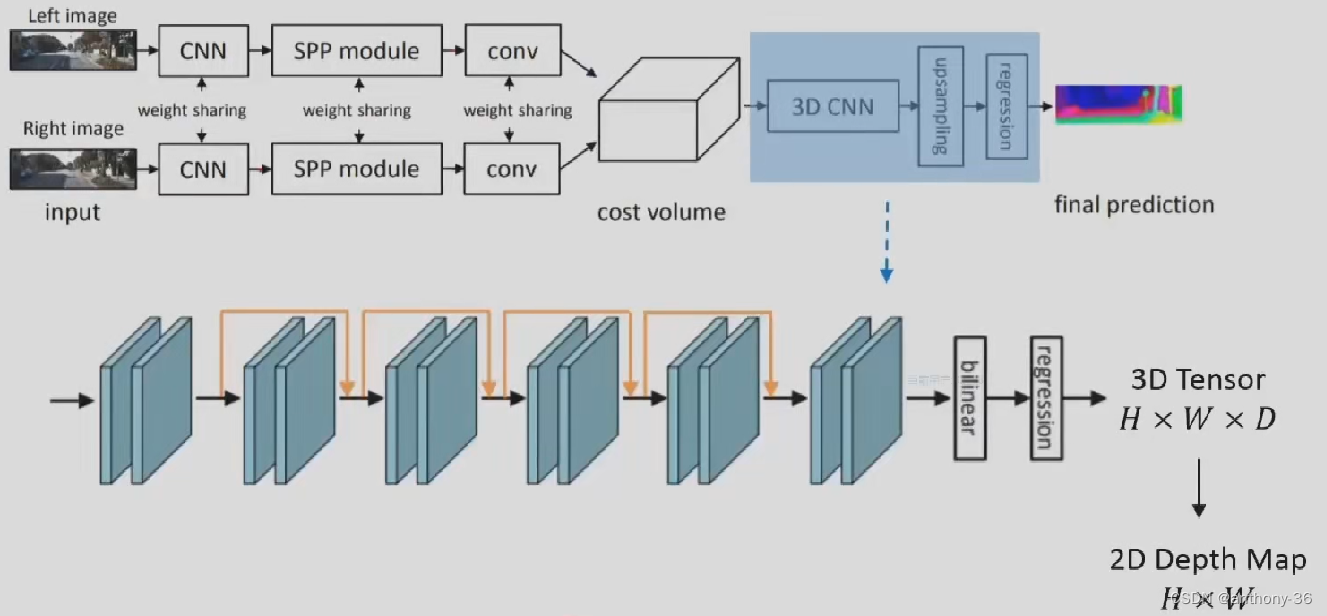
PSMNET
1.左右图像上采用共享的卷积网络进行特征提取
- 包括下采样,金字塔结构和空洞卷积来提取多分辨率的而信息并扩大感受野
2.左右特征图构建Cost Volume
3.3D卷积提取左右特征图以及不同视差级别之间的信息
4.上采样到原始分辨率,找到匹配误差最小的视差值
5.过程
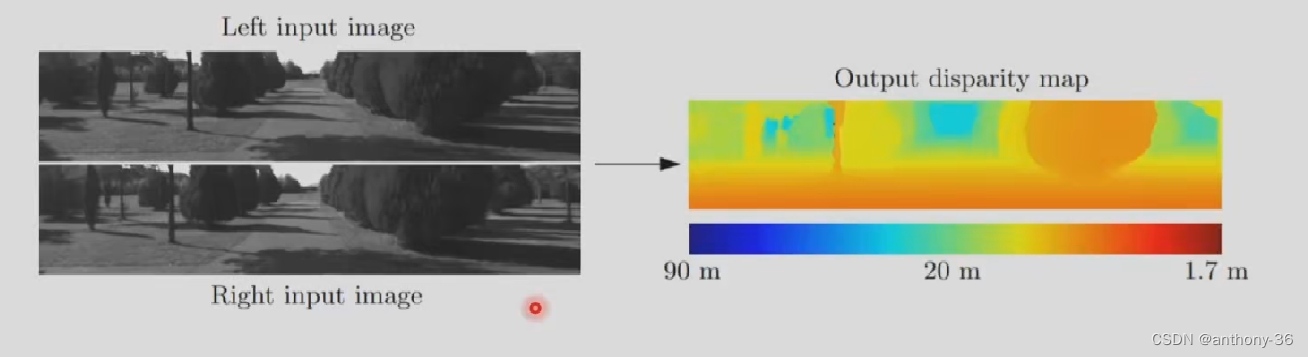
6.结果分析(KITTI数据集)
- 物体和背景上出现误差

原因分析:虽然特征包含了邻域信息,但是缺乏高层语义信息的监督信号,无法理解场景。
改进方法:用物体检测和语义分割的结果进行后处理,或者多个任务
- 距离过长出现的误差

| 距离 | 0-10m | 10-30m | 30-60m | 60-inf | 0-inf |
|---|---|---|---|---|---|
| 深度误差(RMSE) | 0.268 | 1.203 | 6.056 | 16.604 | 2.605 |
原因分析:远距离的视差值较小,在离散的图像像素上难以区分
Z
=
f
B
/
d
Z=fB/d
Z=fB/d
改进方法:①提高图像的空间分辨率(长焦),使得远距离物体也有较多的像素覆盖
②增加基线长度,从而增加视差的范围
- 低纹理或者低光照的区域,深度估计误差较大

原因分析:在该区域内无法有效提取特征,用于计算匹配误差
改进方法:提高摄像头的动态范围,或者采用可以测距的传感器
具体的仿真过程记录在下一篇里面有。

