
- 1世界上有没有与chatgpt相媲美的模型
- 2Hi3516DV300开发板——4.开发板挂载NFS服务_hi3516d mount
- 3Property or method “btn“ is not defined on the instance but referenced during render. 报错原因及解决措施_button is not defined
- 4Django的django.contrib.auth.models模块中的AbstractUser类介绍。
- 5【深度学习】最强算法模型之:潜在狄利克雷分配(LDA)
- 6子表单扫码录入,显著节省填写时间
- 7VSCode中6个AI顶级插件_vscode ai插件
- 8基于神经网络的依存句法分析_神经网络 依存句法分析
- 9[嵌入式AI从0开始到入土]15_orangepi_aipro欢迎界面、ATC bug修复、镜像导出备份
- 10jieba包的基本使用方法(python)_jieba.cut参数
【Pytorch学习笔记】10.如何快速创建一个自己的Dataset数据集对象(继承Dataset类并重写对应方法)_随机生成一个dataset
赞
踩
我们在做实际项目时,经常会用到自己的数据集,需要将它构造成一个Dataset对象让pytorch能读取使用。
我们之前经常调用 torchvision 库中的数据集对象直接获得常用数据集,如:torchvision.datasets.FashionMNIST(),这样获得的一个Dataset对象属于 torch.utils.data.Dataset 类。获得Dataset对象后传入DataLoader就可以加载批量数据参与训练了。
如果我们有自己的数据集该怎么定制一个自己的Dataset呢?
继承Dataset类,并重写对应方法创建自己的Dataset
我们看官方文档:
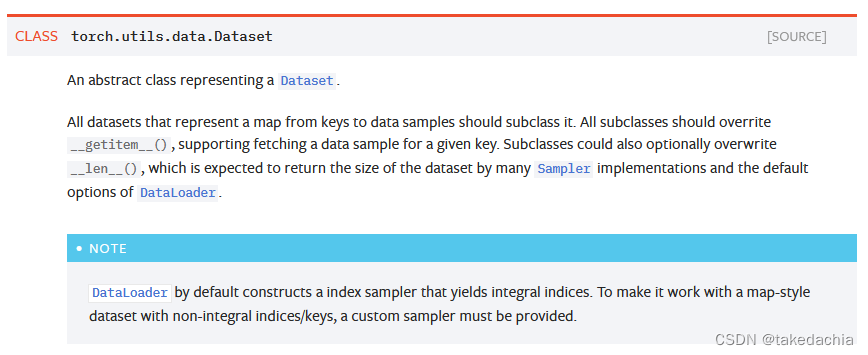
文档中描述了构建一个自己的dataset,需要重写魔法方法__getitem__()来指定索引访问数据的方法,同时需要重写__len__()来获取数据集的长度(数量)。
我们直接看个简单的例子,就非常一目了然了:
# 创建数据集对象
class text_dataset(Dataset): #需要继承Dataset类
def __init__(self, words, labels):
self.words = words
self.labels = labels
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
label = self.labels[idx]
word = self.words[idx]
return word, label
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上面我们创建一个数据集对象,对一个单词指定一个情感的标签。
words传入的是各个单词,为一个List。
labels则是各个单词对应的标签,为一个List。
- 在__init__中,我们将传入的序列指定为类的属性
- 在__len__中,我们设定数据集的长度
- 在__getitem__,我们使用参数idx,指定索引访问元素的方法,并指定返回元素
我们有如下数据源:
words = ['Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
dataset_words = text_dataset(words, labels)
dataset_words[0]
# 返回:
# ('Happy', 'Positive')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
就可以传入我们创建的dataset,实例化一个新的dataset。可通过下标访问数据。
接着就可以传入一个DataLoader:
train_iter = DataLoader(dataset_words, batch_size=2)
X, y = next(iter(train_iter))
X, y
# 返回:
# (('Happy', 'Amazing'), ('Positive', 'Positive'))
- 1
- 2
- 3
- 4
- 5
这样,一个简单的Dataset就创建好了。
下面讲一个创建图片数据集的实例。
实例:用自己的图片数据集创建
例子使用的是 动手学深度学习 中的树叶分类项目,地址:https://www.kaggle.com/competitions/classify-leaves
图片数据集长什么样
我们把数据集解压后发现下面一个子文件夹image里存放了共27153张图片,其中标号前18353张图片为训练集,后8800张图片为测试集(测试集没有给label)。
训练集的标签信息在train.csv中,有176类。
我们发现图片的信息和label信息没有直接对应起来,最好是一个图片张量对应一个label类才行。
所以这样的数据集需要处理一下才能读入Dataset中。
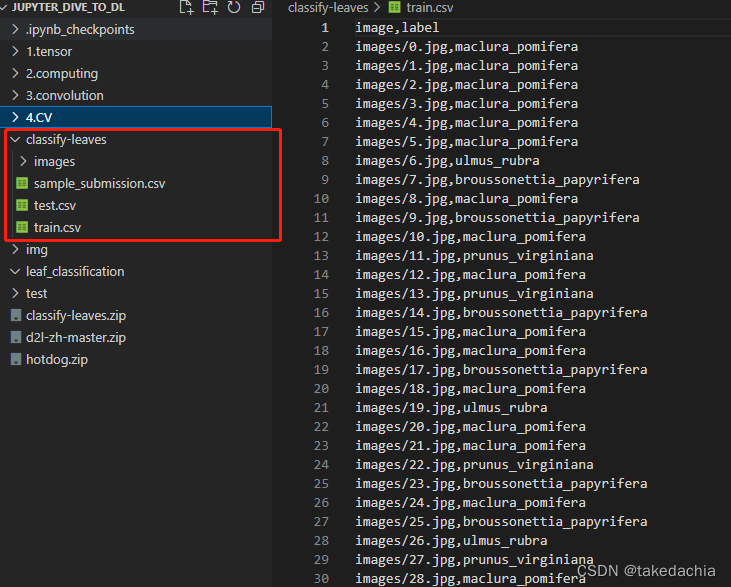

但是!
这里我先把这些jpg文件重命名一下,文件名不满5位数的前面填0,因为届时用torchvision.datasets.ImageFolder读取文件是按字符串顺序读取的(ImageFolder的著名坑)。改成如图形式:
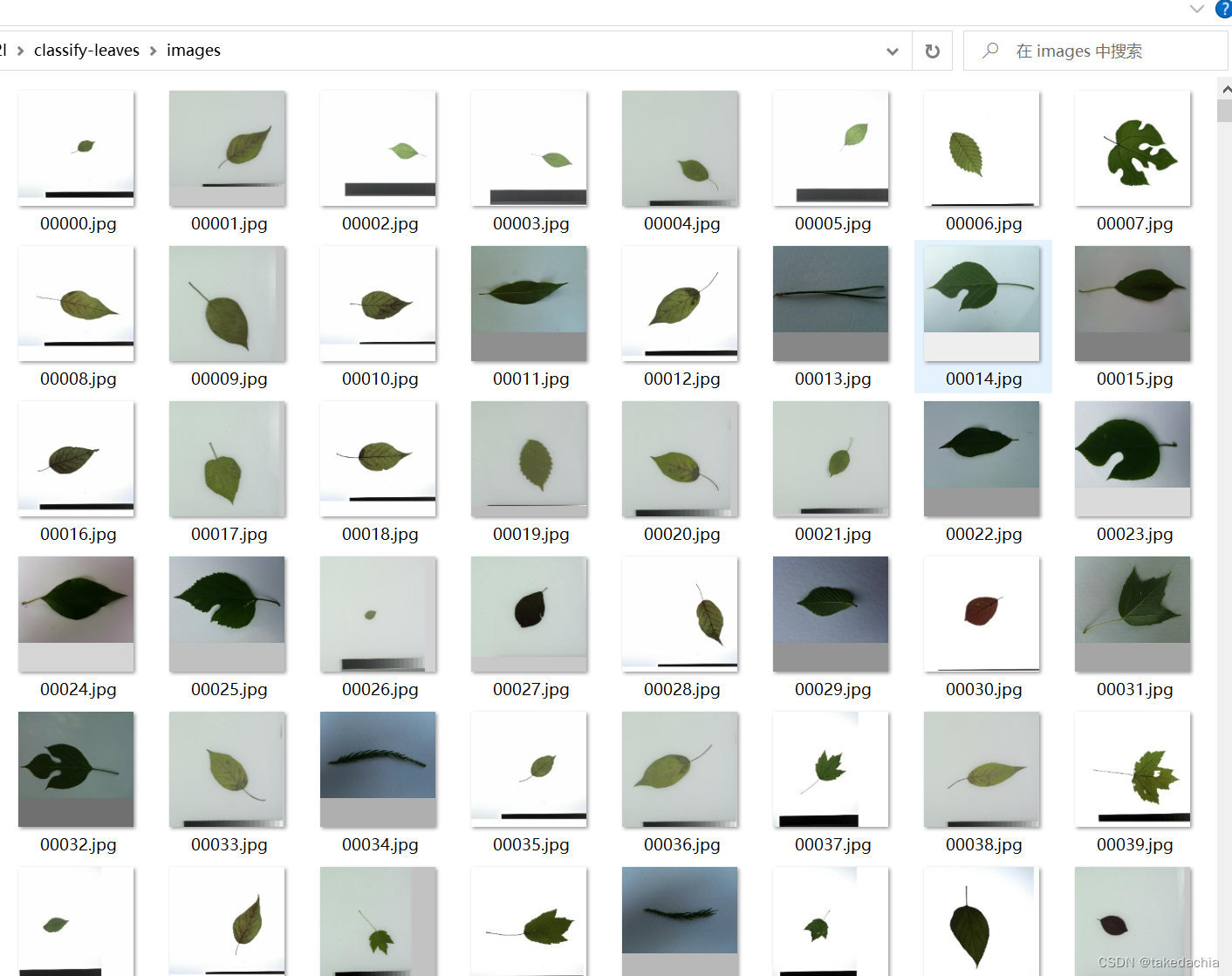
文件批量重命名代码:
# 先给文件名称重命名一下,数字不满5位的一律补全0,因为届时用ImageFolder读取是按字符串顺序读取的
# 即 3.jpg → 00003.jpg
import os
path = '../classify-leaves/images'
file_list = os.listdir(path)
for file in file_list:
front, end = file.split('.') # 取得文件名和后缀
front = front.zfill(5) # 文件名补0,5表示补0后名字共5位
new_name = '.'.join([front, end])
# print(new_name)
os.rename(path + '\\' + file, path + '\\' + new_name)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
数据预处理
我们先使用torchvision.datasets.ImageFolder把image下的图片读入一个临时的Dataset,data_images
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision.datasets import ImageFolder
from torchvision import transforms
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
train_augs = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor()
])
data_images = ImageFolder(root='../classify-leaves', transform=train_augs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
再读取训练集的标签信息。
train_csv = pd.read_csv('../classify-leaves/train.csv')
print(len(train_csv))
train_csv
- 1
- 2
- 3

我们知道类别信息届时在训练时是需要转成独热编码的,所以需要先把类别信息的label转成类别号。
train_csv.label.unique()可得到所有类别名,其为一个有序的numpy数组,可通过查询的方法来取得索引号,索引号就可以当作类别号。
# 获取某个元素的索引的方法:
# 这个class_to_num可以存起来,之后可作为类别号到类别名称的映射
class_to_num = train_csv.label.unique()
np.where(class_to_num == 'quercus_montana')[0][0] # 取两次[0]取到序号
- 1
- 2
- 3
- 4

建立类别号信息:
(上面这个class_to_num可以存起来,之后可作为类别号到类别名称的映射)
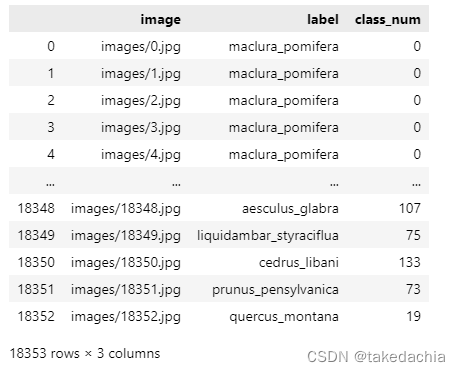
train_csv['class_num'] = train_csv['label'].apply(lambda x: np.where(class_to_num == x)[0][0])
train_csv
- 1
- 2
创建Dataset
# 创建数据集对象 —— leaf class leaf_dataset(Dataset): # 需要继承Dataset类 def __init__(self, imgs, labels): self.imgs = imgs self.labels = labels def __len__(self): return len(self.labels) def __getitem__(self, idx): label = self.labels[idx] data = self.imgs[idx][0] # 届时传入一个ImageFolder对象,需要取[0]获取数据,不要标签 return data, label imgs = data_images labels = train_csv.class_num

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这里将之前用ImageFolder建立的临时Dataset直接作为参数imgs,因为ImageFolder取到图片数据需要再取个0(取1则是label,在这个例子中是“image”),所以在写__getitem__时在取data时后面加个[0]。
下面创建Dataset,传入DataLoader,并显示一下数据:
Leaf_dataset = leaf_dataset(imgs=imgs, labels=labels)
train_iter = DataLoader(dataset=Leaf_dataset, batch_size=256, shuffle=True)
X, y = next(iter(train_iter))
X[0].shape, y[0]
- 1
- 2
- 3
- 4

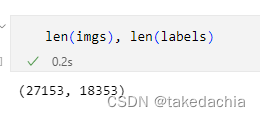
这里,细心的同学可能会问:imgs长度是27153,labels长度是18353:
这样不等长传入一个数据集没问题吗?
事实上一对不等长序列传入Dataset会有本身的问题,但传入DataLoader之后会自动筛掉不等长的部分,最后载入的数据长度依然会是训练集的18353。
还是建议先把Dataset整理一下,可以使用torch.utils.data.Subset方法直接取前18353个元素(也可以在Dataset类内自己修改成想要的样子):
indices = range(len(labels))
Leaf_dataset_tosplit = torch.utils.data.Subset(Leaf_dataset, indices)
- 1
- 2
最后展示一下图片:
# 展示一下
toshow = [torch.transpose(X[i],0,2) for i in range(16)]
def show_images(imgs, num_rows, num_cols, scale=2):
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
for i in range(num_rows):
for j in range(num_cols):
axes[i][j].imshow(imgs[i * num_cols + j])
axes[i][j].axes.get_xaxis().set_visible(False)
axes[i][j].axes.get_yaxis().set_visible(False)
return axes
show_images(toshow, 2, 8, scale=2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

总结
我们常用继承 torch.utils.data.Dataset 类的方法来构造一个自己的Dataset,同时需要重写以下几个魔法方法:
- 在__init__中,将传入的数据序列指定为类的属性
- 在__len__中,设定数据集的长度
- 在__getitem__,使用参数idx,指定索引访问元素的方法,并指定返回元素
之后就可以传入DataLoader进行读取使用了。
(本文所用代码也可看我的Github)

