
- 1Spring Security 4 使用@PreAuthorize,@PostAuthorize, @Secured, EL实现方法安全(带源码)_preauthorize @el
- 2Git 修改已提交的commit注释
- 3NLP(十八):LLM 的推理优化技术纵览_稀疏llms推理优化研究
- 4线性回归介绍
- 5CodeWhisperer 史上最强大的 AI 编程助手!!_c# ai助手
- 6实现开启和关闭android移动网络(做AppWidget开发的收获)_android studio 打开 和 关闭 数据流量
- 7sqli-labs Less-32、33、34、35、36、37(sqli-labs闯关指南 32、33、34、35、36、37)—宽字节注入_sql-labbypass
- 8Ubuntu介绍、与centos的区别、基于VMware安装Ubuntu Server 22.04、配置远程连接、安装jdk+Tomcat_ubuntu centos
- 9解决TypeError [ERR_INVALID_CALLBACK]: Callback must be a function. Received un defined
- 10SPP(SERIAL PORT PROFILE)
EMNLP 2023评审内幕公开
赞
踩

来自:新智元
进NLP群—>加入NLP交流群
EMNLP 2023放榜,研究人员们纷纷晒出自己成绩单。在欢呼和喝彩声之外,也有网友对今年的评审和结果不一致提出疑问。
EMNLP 2023放榜了!
![]()
一年一度的计算语言学顶级国际会议EMNLP,是NLP四大顶会之一,将在12月6日-10日在新加坡召开。

去年的大会在阿联酋阿布扎比召开,共有投稿4190篇,最终829篇论文被接收(715篇长论文,114篇论文),整收率为20%。
从2012年到2022年10年时间内,收录文章从140篇增长到接近1000篇!

往年论文:https://aclanthology.org/venues/emnlp/
网友纷纷晒出成绩单
就在这两天,EMNLP 2023放出了最新的录用结果。
比如这位西安交大的Wang Yichen同学就连中两篇!
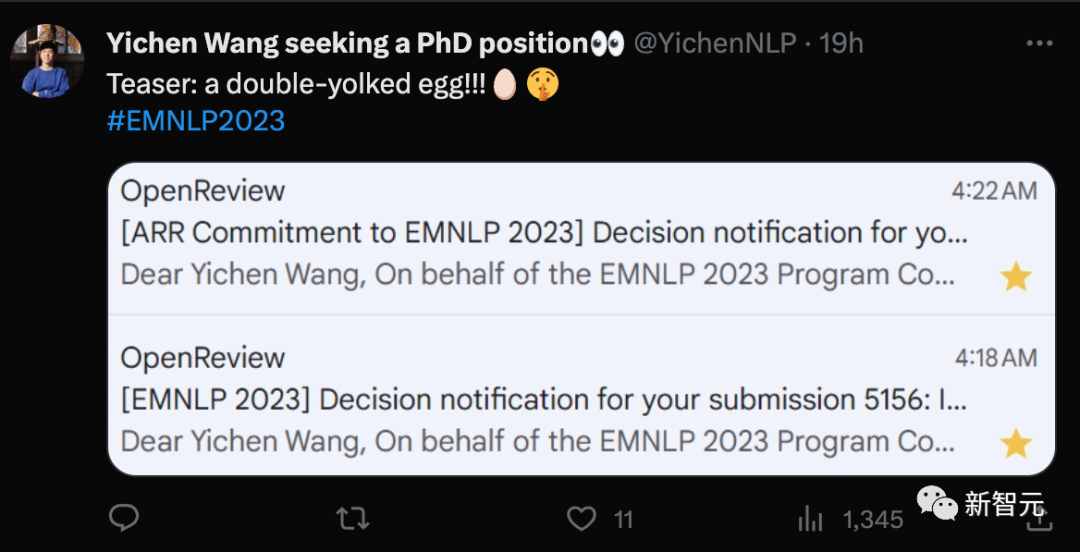
他本科就读于西安交大,今年刚刚大四,目前在UW实习,师从Tianxing He和Prof. Yulia Tsvetkov教授。
在他个人网站上po了两篇参与的论文:

这位港大的Ph.D一下中了4篇,3篇主会一篇Findings。

恰逢昨天阿森纳赢了曼城——5喜临门,这位阿森纳球迷早上应该是笑着醒过来的吧!
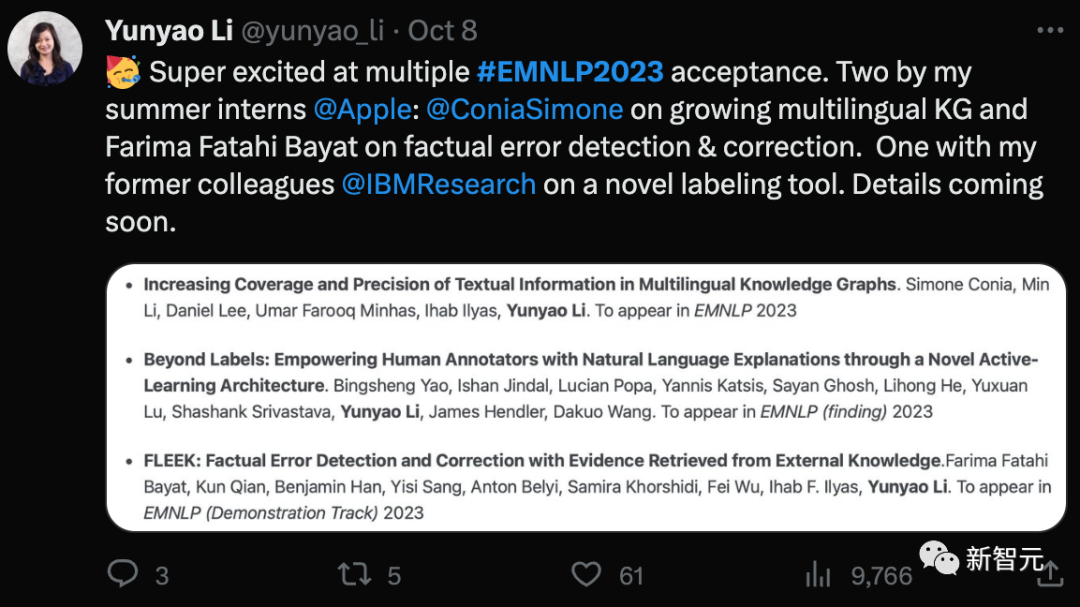
3篇被接收,2篇主会一篇findings,恭喜这位清华的校友Li Yunyao!
她毕业于清华大学,在密歇根大学获得了Ph.D,之后在IBM工作了很长时间,目前是苹果知识平台的主管。
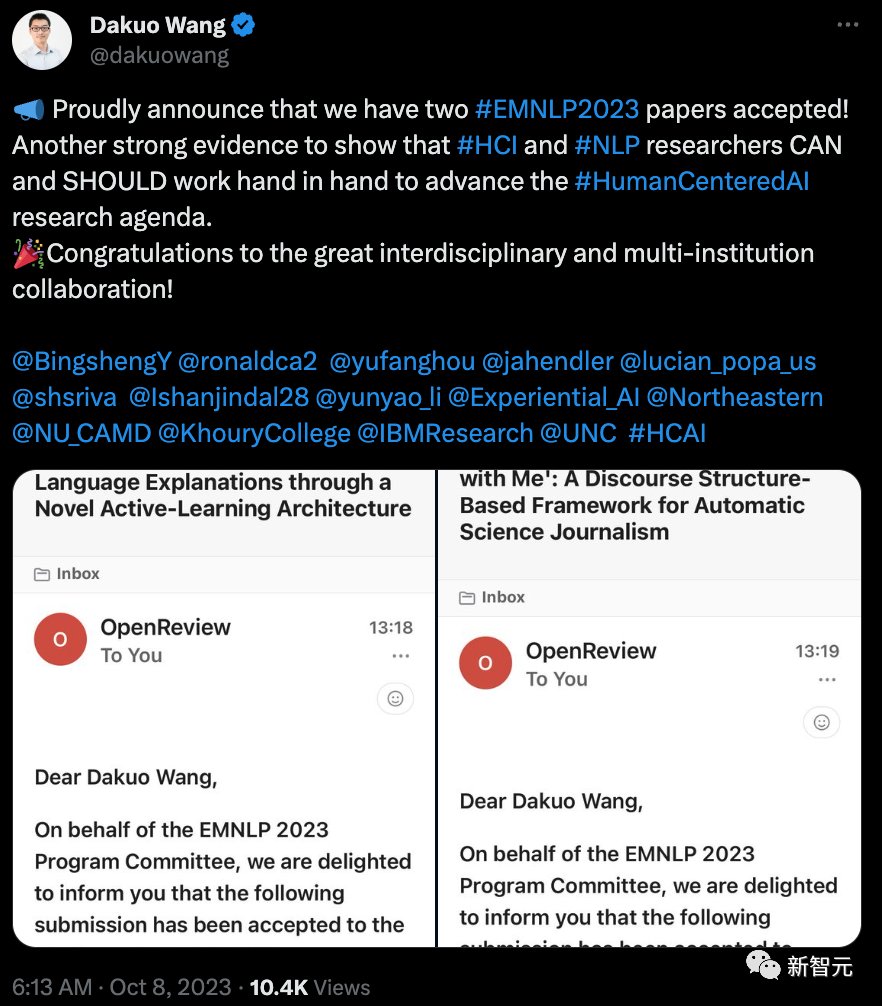
Wang Dakuo教授中了的两篇论文,都强调了跨学科合作研究和多机构研究的意义和成果。
还有网友开心能够以第一作者身份接收了2篇论文。

一位腾讯算法工程师中了一篇,是关于压缩Prompt,让大模型处理多达2倍的上下文的研究。
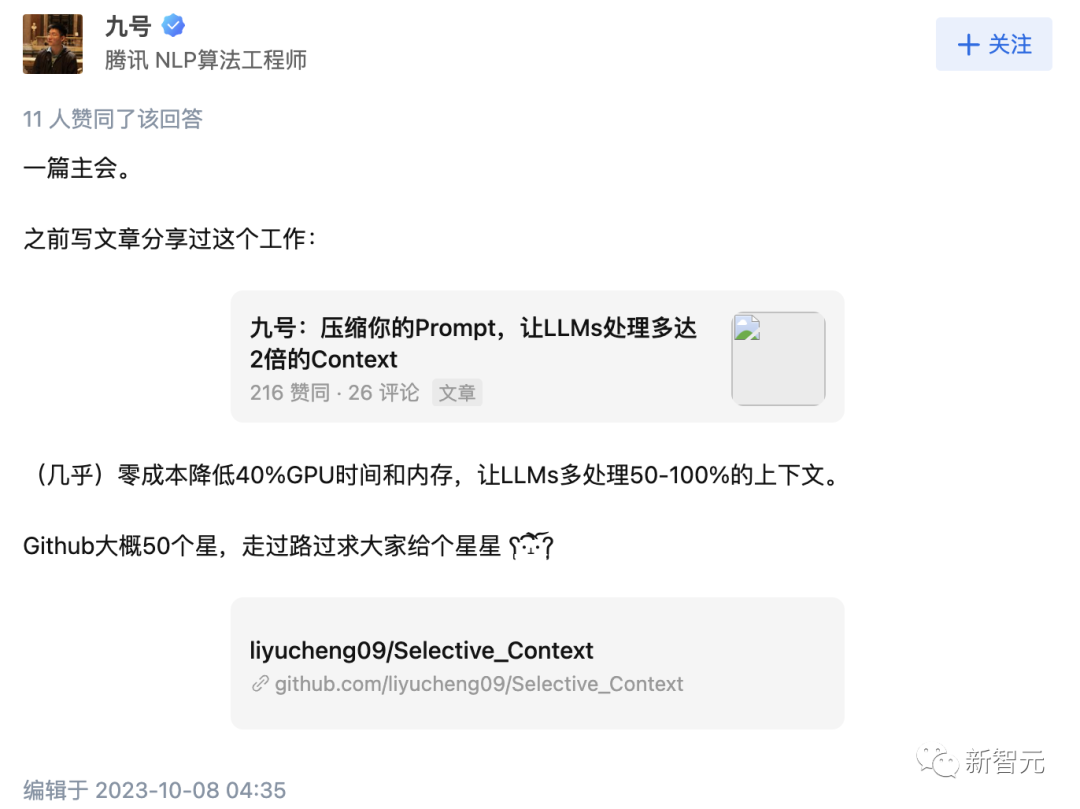

论文地址:https://arxiv.org/pdf/2304.12102.pdf
3个Good,却被拒稿?
但也有一些结果让人十分哭笑不得。
乍一看非常正面的评语:「作者提出了通过数据扩增实现高效的参数微调方法,进而提升了安全分类器的few-shot泛化能力。4位审稿人中有3位选择了Good(1 位选择了Strong,他/她最初选择了Good)」
然而结果却是——拒稿……
目前,这个帖子已经有超过10万人前来围观。
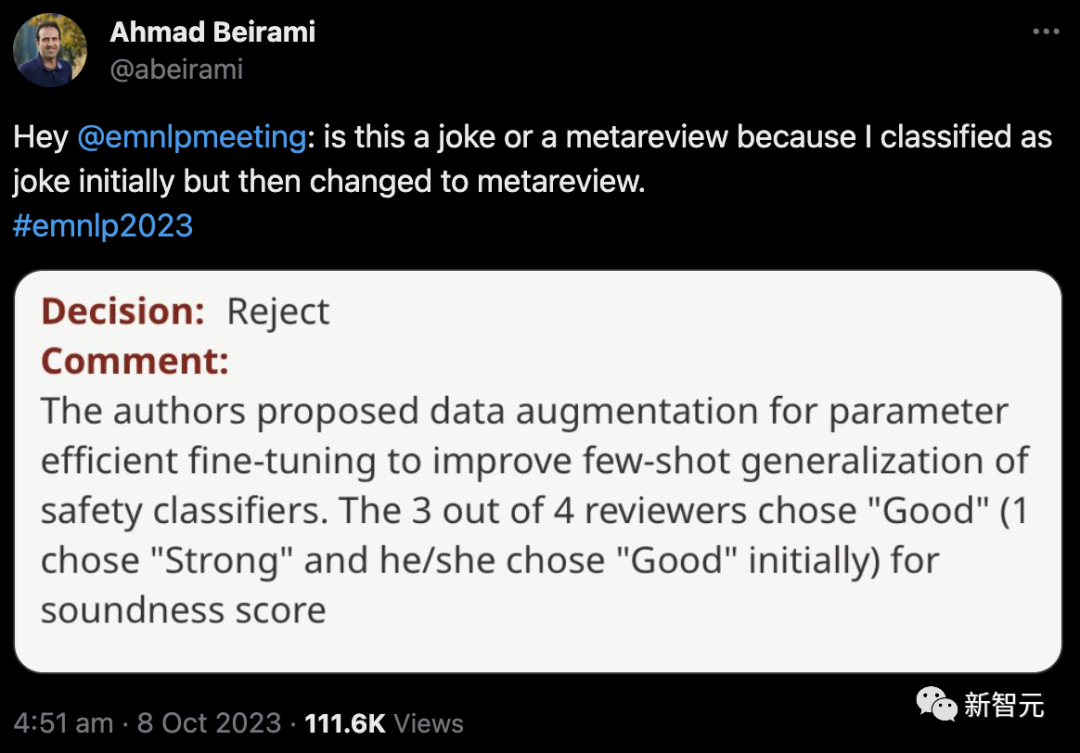
有网友安慰作者说可能是审稿人点错了。论文作者希望无论真实情况是怎么样,这几个审稿人审的很好,以后就不要再审了。
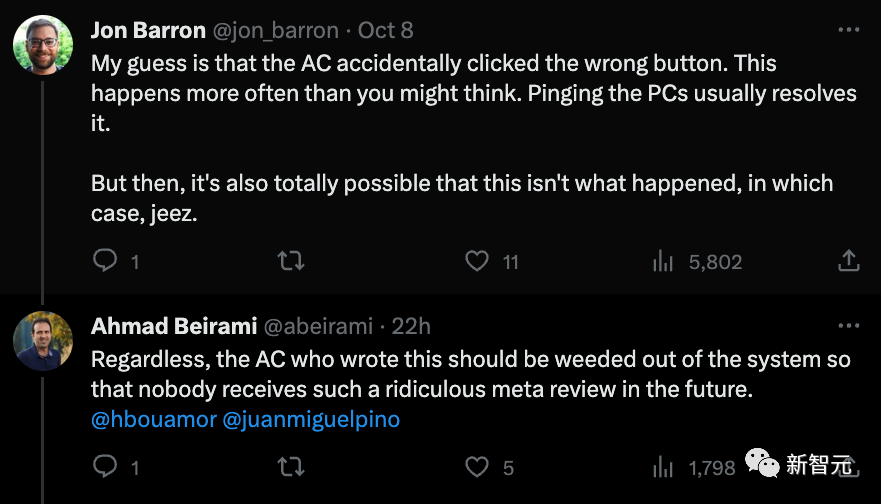
作者同时也找到另外一篇评审意见非常积极,但是依然被拒的论文。
推特下方,CMU的一位副教授提醒作者可以写邮件再次确认论文是否被接收。
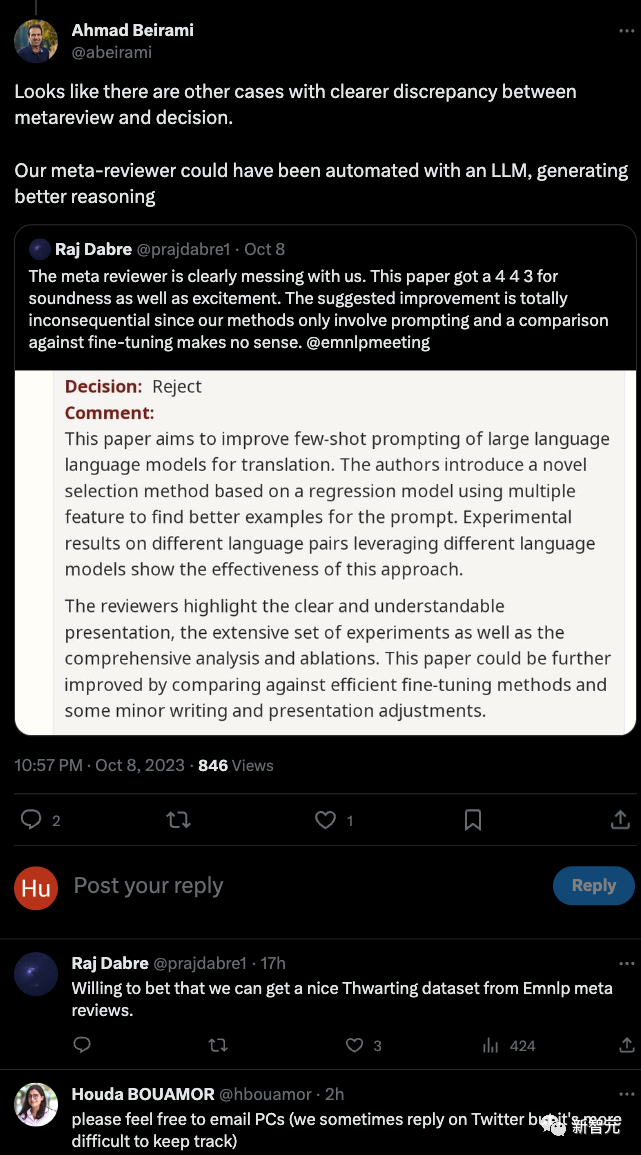
什么样的论文能被成功收录

「A Diffusion Weighted Graph Framework for New Intent Discovery」论文提出了一种用于无监督意图发现的方法,目的是从没有标注的对话数据中自动发现新的意图,而无需人工标注数据。
论文主要创新点是,是联合利用预训练语言模型和对比学习进行无监督的意图发现,以及后续的精调过程。实验结果显示,最新方法可以从非标注数据中发现高质量的新意图。

论文地址:https://arxiv.org/abs/2205.12914
南洋理工孙爱欣博士团队的论文关于大模型在少样本信息抽取任务上的表现。发现LLM直接做少样本抽取时效果不佳,因为对hard sample的判断较差。
但LLM是一个好的re-ranker,可以用来重新排列其他抽取模型输出的候选结果。
论文中,他们提出了一种少样本信息抽取框架,首先用传统模型生成候选,然后用LLM做re-rank。
实验过程中,在多个数据集上验证了该框架,结果显示与只用LLM直接做抽取相比,准确率明显提高。总体而言,LLM的价值在于重新评估候选,而非完全替代传统方法。

南加大华人Ph.D的论文:「CoAnnotating: Uncertainty-Guided Work Allocation between Human and Large Language Models for Data Annotation」
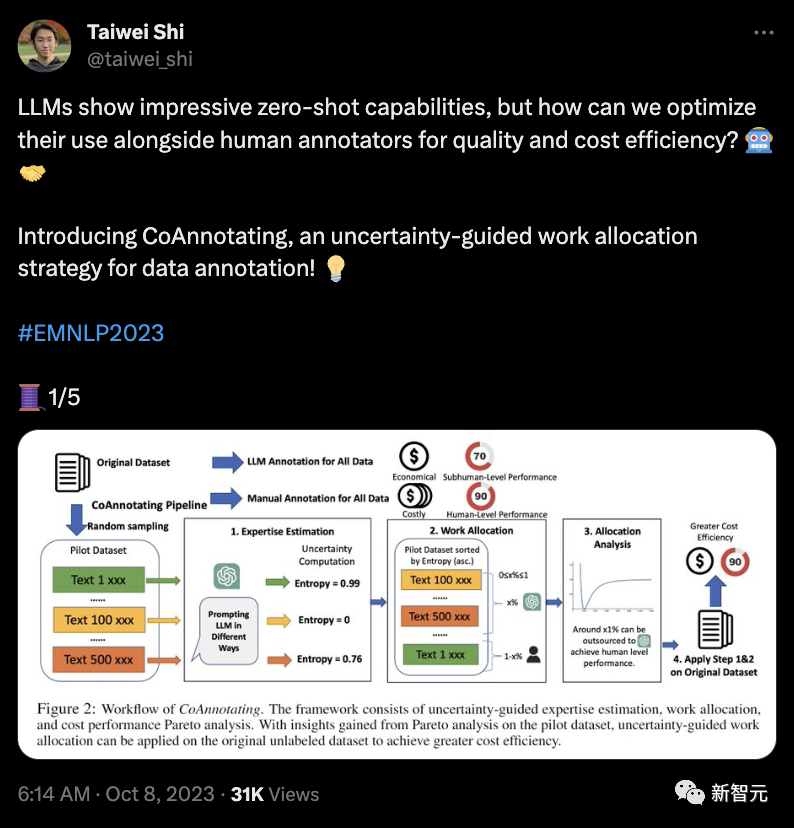
研究提出了CoAnnotating——这是一种用于数据注释的不确定性引导工作分配策略,来优化LLM与人类注释者协作的质量和成本效率。
研究人员认识到人类和LLM各自的优势,为高质量以及具有成本效益的注释开创了和谐的合作伙伴关系。他们通过实例来量化LLM的注释专业知识。
即使没有黄金标准数据,研究人员还是可以用不确定性,通过LLM自我报告的置信度得分和熵来衡量LLM的注释准确性。
研究人员根据LLM在相同样本和提示下不同预测的频率来计算熵。
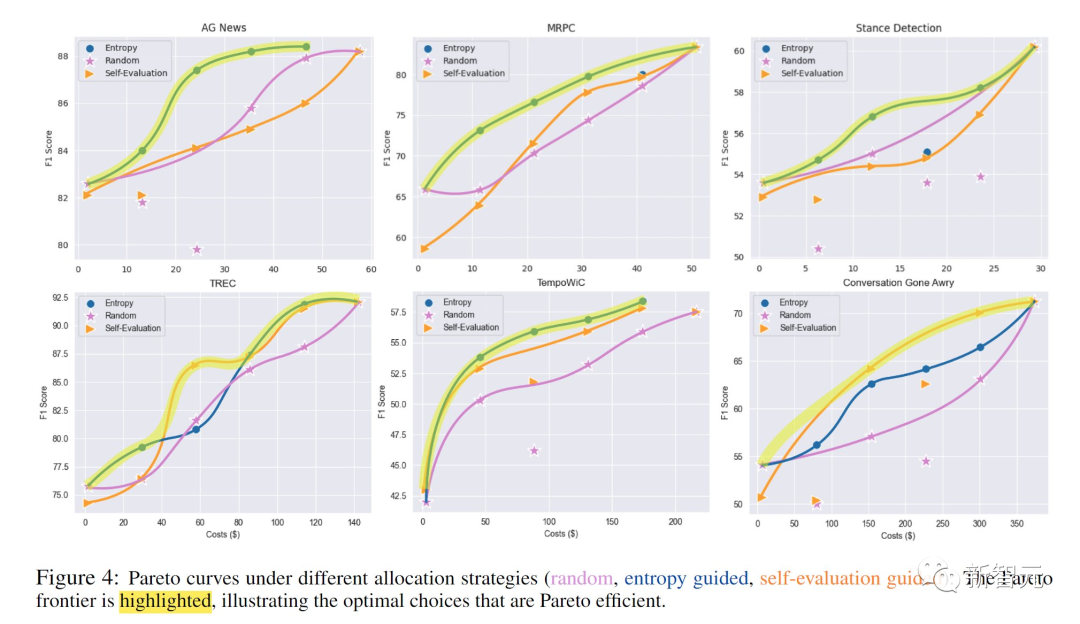
然后,研究人员可以将数据注释视为多目标优化挑战,旨在最大限度地提高质量,同时最大限度地降低成本。
通过研究帕累托前沿,研究人员使从业者能够可视化地权衡并为他们的项目选择完美的数据分配比率。
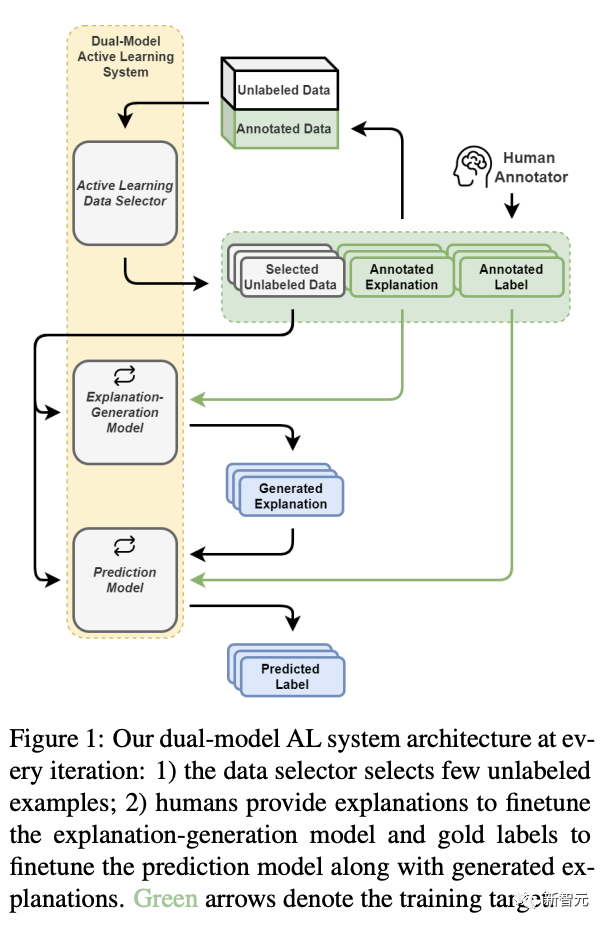
上文介绍过的Wang Dakuo教授的一篇论文,也是关于数据注释的。

论文地址:https://arxiv.org/pdf/2305.12710.pdf
研究提出了一种新颖的主动学习(active learning,AL)架构,以支持和减少低资源场景下对标签和解释的人工注释。这个AL架构融合了一个解释生成模型,该模型能够明确生成用于预测模型以及协助人类在现实世界中做决策的自然语言解释。
在这个AL框架中,研究人员设计了一种基于数据多样性的AL数据选择策略,该策略利用解释注释。自动化的AL模拟评估表明,我们的数据选择策略始终优于传统的基于数据多样性的策略。
大牛们的openreview体验分享
来自中科院计算所的知友龘龘丶分享了一波自己评审论文的感受,强调了做研究动机的重要性。问题重要,结果好,实验严谨,提出了重要的见解,就能获得高分。

来自哥大的知友:晴天的芝麻饭团说起审稿,觉得自己看的论文题材很单调,如果关于ChatGPT的文章只写GPT或者prompt,没有更多的思考,是拿不到高分的。

如何科学地rebuttal涨分
很多网友在热烈地讨论评分和焦急地等待自己论文的结果,知友:长门僧根据ACL2023的分数分布情况写了一个计算长文中稿概率的脚本:
https://github.com/changmenseng/accept_prob
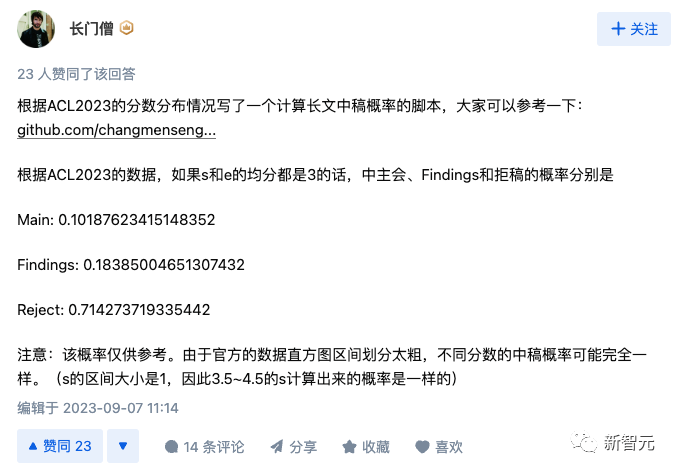
知友:不为法华转,更新了自己做的一个统计,看看Rebuttal之后自己的分数有没有变化。
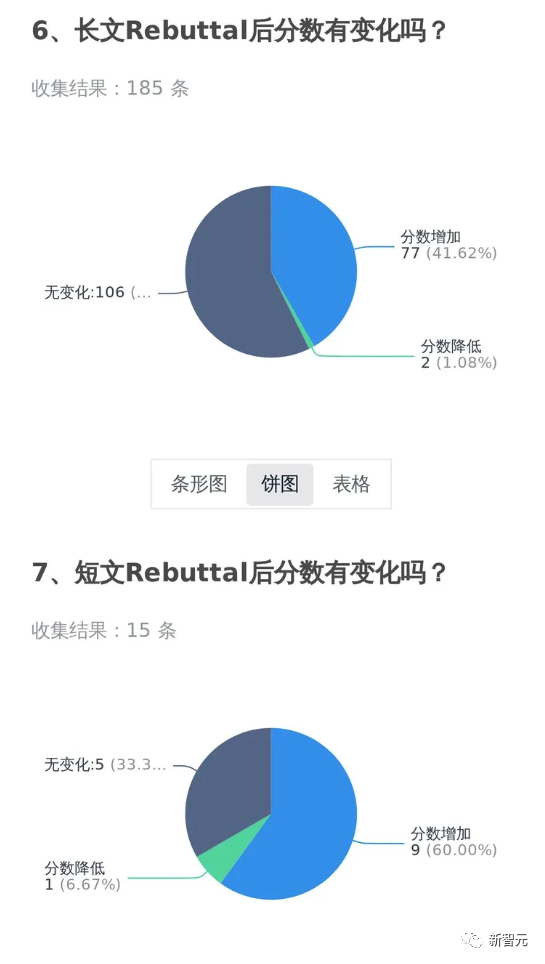
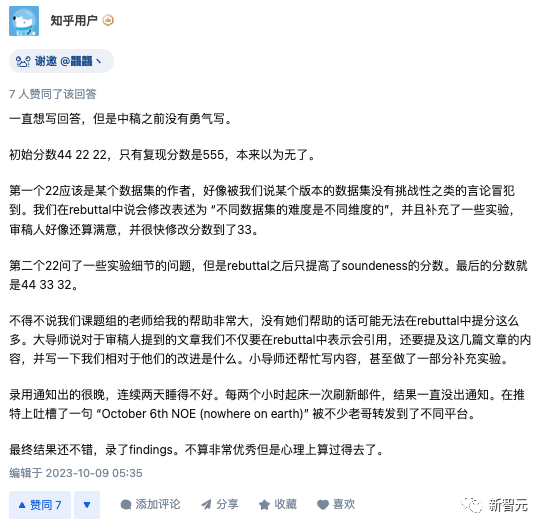
这位知乎用户也更新了一些自己rebuttal的经历。
知友「信息门下大天狗」贡献了一些自己rebuttal涨分的经验,他觉得EMNLP审稿人愿意积极和论文作者沟通,很好的解决作者和审稿人之间的误解,顺利涨分。
但是自己作为审稿人,在打分过程中发现其他审稿人很难对自己不熟悉的领域进行理性的评估,往往会给一个积极的分数,这样对其他论文的作者不是很公平。

参考资料:
https://twitter.com/search?q=%23EMNLP2023&src=typed_query&f=top
https://www.zhihu.com/question/616053965
加下方微信(id:DLNLPer),
备注:昵称-学校(公司)-方向,进入技术群;
昵称-学校(公司)-会议(eg.ACL),进入投稿群。
方向有很多:LLM、模型评测、CoT、多模态、NLG、强化学习等。

记得备注呦

