
- 1ICLR 2021 | 腾讯 AI Lab 入选论文解读
- 2【论文笔记】Medical Dialogue Response Generation with Pivotal Information Recalling
- 32024数字科技前沿应用趋势报告:智能科技、跨界相变(附下载链接)
- 4LLMの推理过程
- 5PathCore:IAD文献解读
- 6全球首个AI软件工程师Devin:编程领域的革命者_devin人工智能
- 7【第八章】PyQt5 widgets(pyqt5 部件)_widge box
- 8终端上的GitHub Copilot以及IDE上的GitHub Copilot_mac 安装copilot in the cli
- 9使用自定义数据集在PyTorch中训练Yolo进行对象检测_folder structure 数据集
- 102024年AI辅助研发趋势深度解析:科技革新与效率提升的双重奏
每天五分钟深度学习:深度学习中数据样本和标签的符号化表示
赞
踩
本文重点
在深度学习的研究与应用中,数据样本和标签的符号化表示是至关重要的一环。通过合理的符号化表示,我们可以将现实世界中的数据转化为计算机能够理解和处理的形式,从而为后续的模型训练和推理提供基础。本文将对深度学习中数据样本和标签的符号化表示进行详细的探讨,从定义、表示方法、应用案例等方面展开。
数据样本和标签的定义
在深度学习中,数据样本通常指的是用于训练和测试模型的一组数据点。这些数据点可以是图像、文本、音频、视频等多种形式,它们包含了模型需要学习的信息。标签则是与数据样本相关联的某种信息,用于指示数据样本的类别、属性或其他相关信息。在监督学习中,标签通常用于指导模型的训练过程,使模型能够学习到从输入数据到输出标签的映射关系。
数据样本的符号化表示
向量表示法
对于数值型数据,我们可以将每个数据样本表示为一个向量。向量的每个维度对应数据样本的一个特征。例如,在图像处理中,我们可以将一张图像展平为一个一维向量,其中每个像素的灰度值或颜色通道值作为向量的一个元素。这种表示法简单直观,但可能会忽略数据样本中的空间结构信息。
张量表示法
对于具有复杂结构的数据样本,如图像、视频等,我们可以使用张量(Tensor)来进行表示。张量是向量的扩展,可以表示多维度的数据。在图像处理中,一张图像可以被表示为一个二维张量(或称为矩阵),其中每个元素表示一个像素的值。对于视频数据,我们可以将其表示为一个三维张量,其中除了图像的宽和高之外,还增加了时间维度。张量表示法能够更好地保留数据样本的空间结构信息。
序列表示法
对于文本数据,我们可以将其表示为一个序列。序列中的每个元素可以是一个字符、单词或短语,具体取决于任务的需求。这种表示法能够捕捉到文本中的顺序信息,对于自然语言处理任务非常有用。
标签的符号化表示
类别标签
在分类任务中,标签通常表示数据样本所属的类别。我们可以使用整数、独热编码(One-hot Encoding)或嵌入向量(Embedding Vector)来表示类别标签。整数表示法简单直观,但无法反映类别之间的相似性;独热编码可以将每个类别表示为一个只包含一个1和多个0的向量,便于计算类别之间的距离;嵌入向量则可以通过学习得到每个类别的低维表示,能够捕捉到类别之间的语义关系。
回归标签
在回归任务中,标签通常是一个连续的数值。我们可以直接使用这个数值作为标签的表示。例如,在房价预测任务中,标签可以是房屋的实际售价。
多任务学习标签
在多任务学习中,一个数据样本可能对应多个标签。这些标签可以是不同类型的,如分类标签和回归标签的组合。在这种情况下,我们需要为每个任务分别定义标签的表示方法,并将它们组合在一起作为数据样本的标签。
本专栏的符号表示
这个课程,包括后面的课程中,我们都将以下面的方式来表示样本的各项特征。
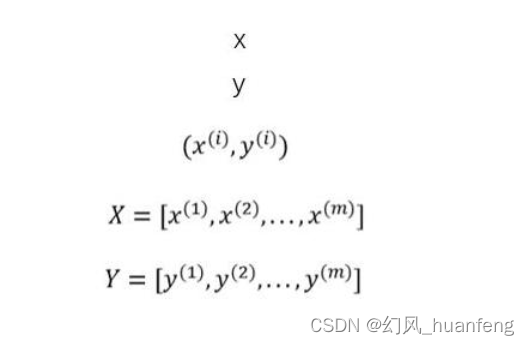
其中x表示样本的特征,是一个向量,假如有nx个特征,那么维度就是(nx,1),在图像处理中,我们可以将一张图像展平为一个一维向量,其中每个像素的灰度值或颜色通道值作为向量的一个元素。
其中y表示样本的标签,标签也有可能是向量,也有可能是一个实数值
其中(x(i),y(i))表示第i个样本,包含样本特征和样本标签
X、Y表示矩阵化的形式
其中X表示所有的样本数据特征,m表示样本数目,维度是(nx,m)

然后还可以这样
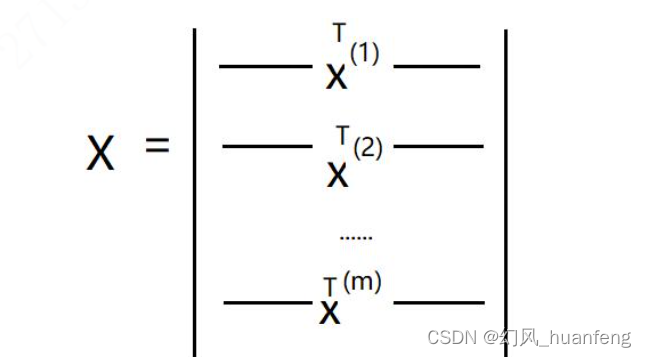
此时的维度是(m,nx)
其中Y表示所有的样本数据标签,维度是(1,m)(当标签值是一个实数的时候)
总结
深度学习中数据样本和标签的符号化表示是模型训练和推理的基础。通过合理的表示方法,我们可以将现实世界中的数据转化为计算机能够理解和处理的形式。

