

配置redis
如果想要运行一个内存高效的redis数据库,首先要理解那些在 redis.conf 配置文件中所有内存相关的指令。
redis.conf 为大多数指令提供了丰富的内联文档,大多数redis配置指令可以在运行时通过CONFIG SET进行设置。
rdbchecksum ,默认是yes,将65位循环冗余校验码(CRC64)放置在RDB快照文件的末尾,作为防止文件损坏的一种手段。当redis产生一个子进程将快照保存至磁盘时,对RDB快照进行CRC64校验会增加10%的内存使用。
redis中的主哈希表将主键与对应的值进行关联,若activerehashing=yes,那么该主哈希表每个100毫秒会重新哈希。重新哈希的过程将释放删除了的键占用的操作系统内存。activerehashing 发生在非工作时间,对客户端连接额影响最小。
主从复制
采用主从复制的方式提供高度可靠性、可伸缩性。在集群环境中,通过slave-of 指令将redis实例切换到从模式,此时 从实例 被允许从另一个被指派为主实例的redis中复制数据。内存 和 来自硬件和网络的延迟会直接影响主从实例的性能。
repl-disable-tcp-nodelay 指令可以用来更好地处理redis主从实例间的网络流量拥塞。通过对主从间的密集数据同步和更少的网络流量之间进行权衡,这种复制能够改善高流量情况下的网络性能。
32位redis
在redis.io网站上的官方文档内存优化中,其中有一条建议是在32位模式下编译redis替代默认的64位实例。对于同样小于3GB的数据集,其在32位redis实例中要比在64位版本中的redis中小。
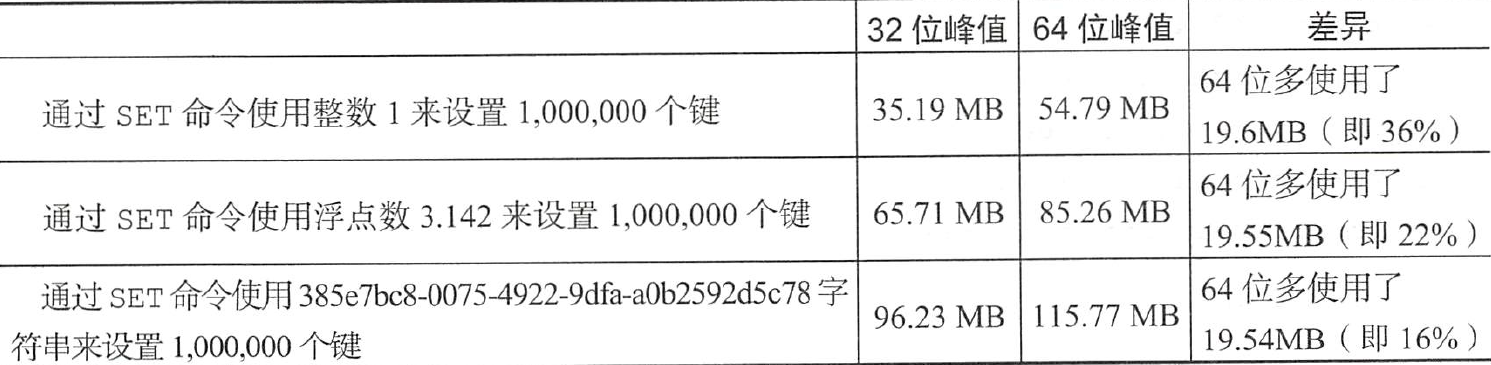
如果应用程序使用整数集合,只要总内存不超过4GB的最大限制,那么32位版本节省的内存是相当可观的。当存入不同大小和类型的值时,redis的32位和64位版本之间的百分比差异意味着节省的内存数量显著降低。对于那些使用集合的应用程序来说,它们较多的使用了字符串,因为64位的redis可能是更好的选择。这是因为在64位版本中的字符串拥有额外的空间及更高效的编码。
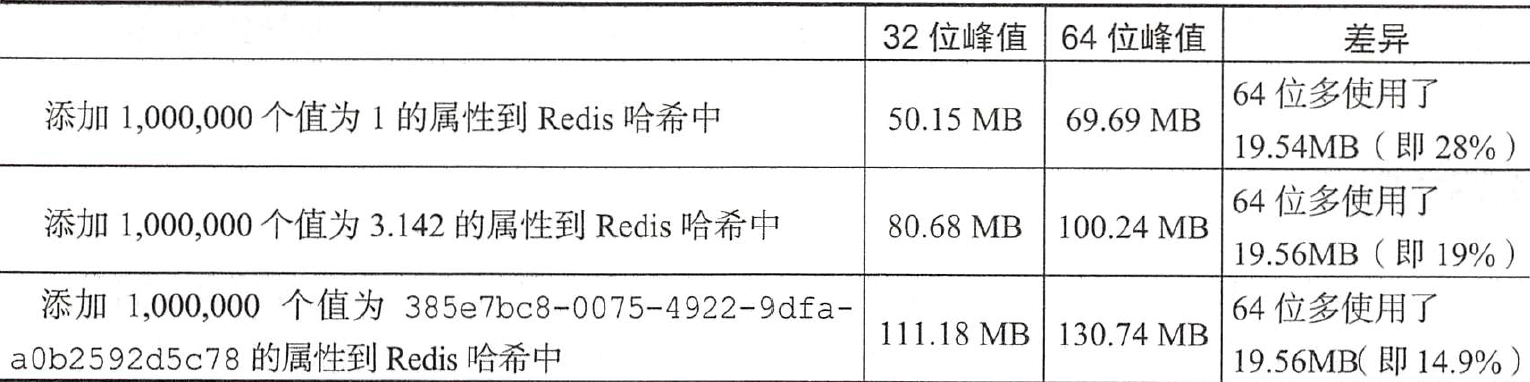
对于哈希数据结构来说,32位和64位redis实例并没有特别大的差异:
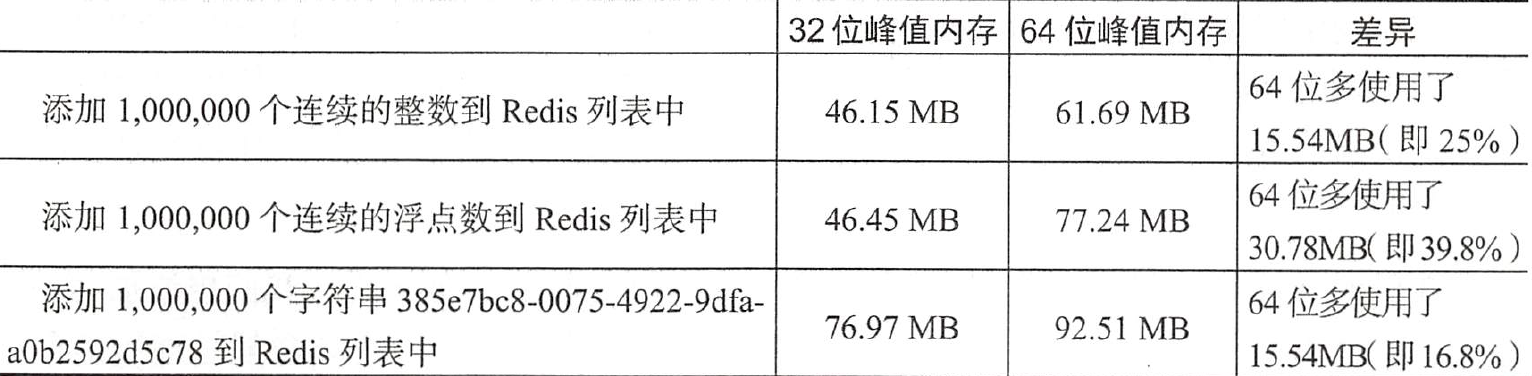
对于32位版本的redis列表来说,在32位限制之下,列表非常适合存储整数和浮点数:
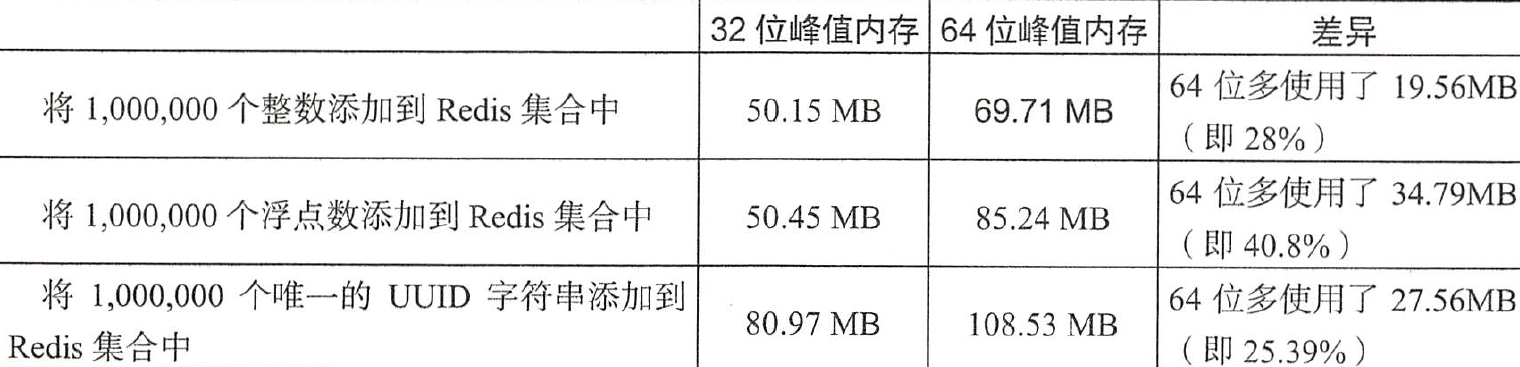
对于redis集合的测试如下:
1) 32位的redis并未在redis用户群中进行广泛部署和测试,因此相较于64位版本可能会有未发现的bug。
2) 诸如bittop、bitcount这样的位操作基于redis的64位版本进行了优化,因此相较于32位则没有那么高效。
3) 在32位redis中设置maxmemory参数更加困难,如果在32位版本的redis中的maxmemory值设置的过于靠近最大值4GB,那么通信、主从复制、I/O缓存都有可能随时导致redis崩溃。
info meory
- 10.143.128.165:6379> info memory
- # Memory
- used_memory:819312
- used_memory_human:800.11K
- used_memory_rss:1904640
- used_memory_peak:2282784
- used_memory_peak_human:2.18M
- used_memory_lua:36864
- mem_fragmentation_ratio:2.32
- mem_allocator:jemalloc-3.6.0
used_memory 分配的字节数大小
used_memory_human 将used_memory格式化为人类可读的值
used_memory_rss 常驻集大小(resident set size) 操作系统中看到的内存分配,
以及top显示的结果
used_memory_peak redis使用的峰值内存
used_memory_peak_human 将used_memory_peak可视化
used_memory_lua redis的lua子系统使用的字节数
mem_fragmentation_ratio used_memory_rss与used_memory的比率
mem_allocator 在编译器redis使用的分配器
键过期
保证redis数据库不会超过可用内存---为键设置超时时间,一旦过了键的超时时限,键就会被自动驱逐。
当在键上调用EXPIRE命令设置过期时间时,该超时只能通过删除或者替换键的方式清除。之后,任何改变值的命令都是无法更改或者清楚之前设置的超时的。
- 10.143.128.165:6379> set name yinn
- OK
- 10.143.128.165:6379> expire name 60
- (integer) 1
- 10.143.128.165:6379> get name
- "yinn"
- 10.143.128.165:6379> ttl name
- (integer) 53
- 10.143.128.165:6379> append name nana
- (integer) 8
- 10.143.128.165:6379> get name
- "yinnnana"
- 10.143.128.165:6379> get name
- (nil)
如果在设置了超时的键上调用set或者getset(键过期之前),那么超时会被清除,键不会从数据库中驱逐:
- 10.143.128.165:6379> set name yin
- OK
- 10.143.128.165:6379> expire name 30
- (integer) 1
- 10.143.128.165:6379> set name xian
- OK
- 10.143.128.165:6379> ttl name
- (integer) -1
也可以使用 persist 命令清楚键上的超时设定:
- 10.143.128.165:6379> set name yinn
- OK
- 10.143.128.165:6379> expire name 60
- (integer) 1
- 10.143.128.165:6379> ttl name
- (integer) 51
- 10.143.128.165:6379> persist name
- (integer) 1
- 10.143.128.165:6379> ttl name
- (integer) -1
在一个已经设置过超时的键上调用expire命令将会清楚并重新设定超时:
- 10.143.128.165:6379> expire name 90
- (integer) 1
- 10.143.128.165:6379> ttl name
- (integer) 87
- 10.143.128.165:6379> expire name 20
- (integer) 1
- 10.143.128.165:6379> ttl name
- (integer) 17
- 10.143.128.165:6379> get name
- (nil)
LRU键驱逐策略
通过maxmemory指令将最大内存设置为1MB以创建一个小内存的redis实例。maxmemory指令允许设定内存大小的硬性上限,运行时的redis实例受限于此。
- 10.143.128.165:6379> flushall ##清楚数据库
- OK
- 10.143.128.165:6379>config set maxmemory 1024
- OK
当redis内存耗尽时,默认生效的是永不过期策略(noeviction policy):

默认的maxmemory-policy策略是永不过期。在noeviction策略中,没有键设置为过期。如果redis没有可用内存,任何写操作都会导致redis错误。
- 10.143.128.165:6379> config get maxmemory
- 1) "maxmemory"
- 2) "1024
- 10.143.128.165:6379>config get maxmemory-policy
- 1) "maxmemory-policy"
- 2) "noeviction"
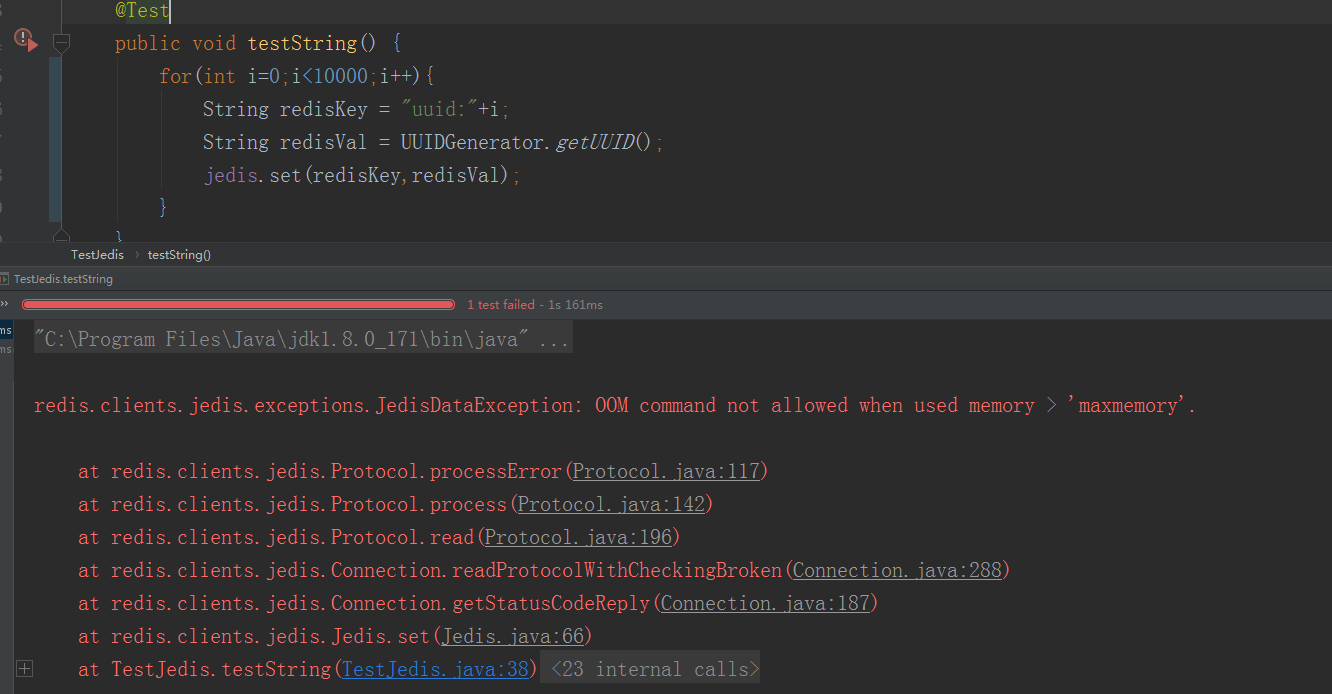
第一种过期LRU策略名为 volatile-lru,它将最近较少使用的键驱逐出去。这些键必须通过 expire set 命令设置了超时的。当redis内存耗尽时,redis开始删除那些设置了过期时间的键,即便该键仍然有剩余时间。
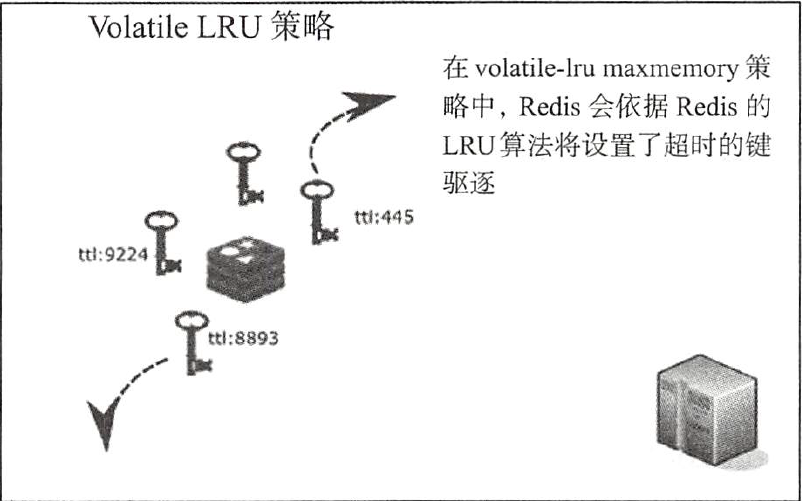
下一个策略是 allkeys-lru ,会删除redis中任何一个键,而且没有办法限制哪些键被删除。
redis的LRU算法是不准确的,因为redis并不会自动选择最佳的候选键来驱逐,例如最少使用的键或者最早访问的键。相反,redis默认行为是选取5个键的samples,并驱逐当中最少使用的那个。如果想要增加LRU算法的精确性,可以更改redis.conf文件中的maxmemory-samples指令,或者在运行时通过config set maxmemory-samples命令进行设置。
将maxmemory-samples增加到10,从而提升redisLRU算法的性能,效果接近真实LRU算法,但是副作用就是消耗更多的CPU计算能力。将maxmemory-samples降至3,从而减少了redisLRU算法的精确性,不过相应地加快了处理速度。
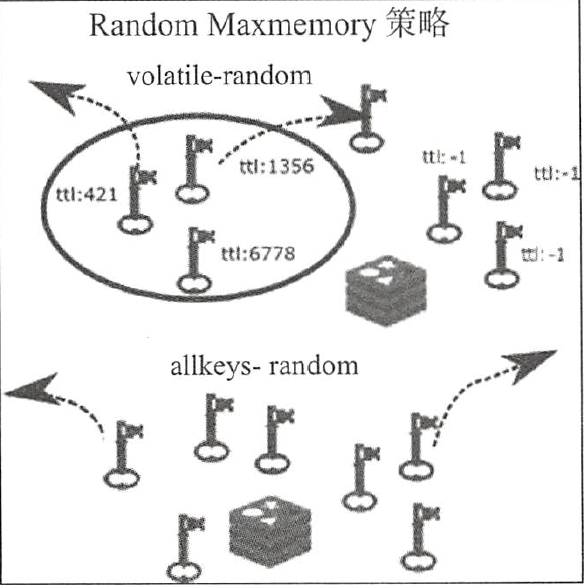
接下来是两种最大内存驱逐策略:volatile-random和allkeys-random。它们与volatile-lru和allkeys-lru相似,但是不采用LRU算法。volatile-random 基于键上设置的过期状态随机驱逐一个键,需要O(n)时间复杂度的操作来计算创建的这些键是否已被驱逐。对于allkeys-random,整个键空间都是开放的。
最后一个最大内存策略是volatile-ttl,redis会尝试根据键的剩余时间(TTL)清除键。
创建内存高效的redis数据结构
小巧的哈希、列表、集合、有序集合
对于哈希、列表、有序集合来说,这种特殊编码方法基于ziplist(压缩列表):
压缩列表是一种特殊的双向链表,专为内存高效进行设计的。它存储了字符串和整数值,其中整数是以真正的整数值而非字符串形式进行存储的。它允许在列表的任意一端以O(1)时间复杂度进行push和pop操作。但是,由于每次操作都需要为ziplist使用的内存进行重新分配,实际上的复杂度与ziplist所使用的内存大小有关。
根据大小、类型以及数据结构的内容,ziplist编码方式为redis数据库极大地节约了内存使用。
redis中ziplist的实现通过为每个节点只存储3份数据实现较小的内存占用:第一份是前一个节点的长度,第二份是当前节点的长度,第三份是存储的值。
对于哈希表来说,hash-max-ziplist-entries 指令设置了总共有多少字段是可以被特殊编码为ziplist,默认是512。hash-max-ziplist-value指令设置了从ziplist转变为哈希表所要达到的最大大小,默认64.
把位、字节和redis字符串用作随机访问数组
在集合中通过使用整数代替字符串,可以将集合的大小显著地降低,但是 位图仍然要比集合小一个数量级、更节省内存。
优化哈希,高效存储
待续P90

