
- 1RabbitMQ WEB管理端页面介绍_rabbitmq web管理界面
- 2智慧树知到期末答案python_2020智慧树知到Python程序设计基础(山东联盟)期末答案...
- 3袁庭新ES系列15节|Elasticsearch客户端基础操作
- 4使用ffmpeg从视频中截取图像帧_ffmpeg 指定秒数截取图片
- 5容器安全-镜像扫描
- 6(二)小程序学习笔记——初识:标签、数据绑定、指令介绍
- 7phpMyAdmin将CSV文件导入数据库+PHP数组转JS数组_csv导入phpmyadmin最新
- 8Brew 安装MySQL后,将配置文件my.cnf 添加到/etc/my.cnf后启动服务报错(The server quit without updating PID file……)_brew mysql my.cnf
- 9PaddleHub中的模型_hub.module
- 10【路径规划】DWA动态避障路径规划【含Matlab源码 2356期】_机器人避障路径规划及控制 csdn
3 - 进程 - Windows 10 - Cpython - 多进程通信 - 队列Queue / 管道Pipe / 共享内存Share Memory(Value/Array) / Manager_python 多进程共享内存
赞
踩
测试环境:
操作系统: Window 10
工具:Pycharm
Python: 3.7
- 1
- 2
- 3
一、进程通信概述:
python的进程间通信主要有以下几种方式:消息队列(Queue)、管道(Pipe)、共享内存(Value,Array)、代理(Manager)。
以上分为两个类型,
进程间交互对象:消息队列(Queue)、管道(Pipe)
进程间同步:共享内存(Value,Array)、代理(Manager)
————————————————————————————————————————
二、进程间交互对象 —— 不用加锁
1. 消息队列(Queue)
消息队列常用于单向交互,消息队列操作简单,用于单向交互最方便。
这种就相当于是半双工通信
代码演示:
# test.py
from multiprocessing import Process, Queue
def f(q):
#print("This is f: ",q.get()) # 未在q.put()方法前,就q.get(),会出问题,无限监听
q.put([42, None, 'hello'])
print("This is f: ",q.get())
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
q.put(["test","test"]) # 只能一次 put 一次 get
p.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
一方发送数据了(put),另一方才能收到队列的数据(get),否则将永远接收不到队列数据,从而无法结束这一代码,相当于堵塞了,一方无数据。
2. 管道(Pipe)半双工
这是最常用的一种进程通信方法。
使用方法:
conn1 , conn2 = Pipe() # 创建管道对象
conn1.send([内容]) # 列表内容
conn2.recv() # 接收内容
conn1.close() # 关闭连接
conn2.close() # 关闭连接
- 1
- 2
- 3
- 4
- 5
代码演示:
# test.py
from multiprocessing import Process, Pipe
def f(conn1,conn2):
conn2.close() #子进程只需使用connection1,故关闭connection2
conn1.send([42, None, 'hello'])
print(conn1.recv()) #无数据则阻塞
conn1.close()
if __name__ == '__main__':
conn1, conn2 = Pipe() #建立一个管道,管道返回两个connection,
p = Process(target=f, args=(conn1,conn2))
p.daemon = True #子进程必须和主进程一同退出,防止僵尸进程
p.start()
conn1.close() #主进程只需要一个connection,故关闭一个
print(conn2.recv()) # prints "[42, None, 'hello']"
print(conn2.send(["test"."test"]))
conn2.close() #主进程关闭connection2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行结果:

错误代码测试:
#test.py
from multiprocessing import Process, Pipe
def f(conn1):
conn1.send([42, None, 'hello'])
print(conn1.recv())
#conn1.close()
if __name__ == '__main__':
conn1, conn2 = Pipe()
p = Process(target=f, args=(conn1,))
p.start()
conn2.close()
print(conn1.recv()) # prints "[42, None, 'hello']"
print(conn1.send(["test","test"]))
conn1.close()
p.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
运行结果:

错误代码分析:
误以为conn1 和 conn2 是两个连接,所以只要关掉其中一个连接就好了,但是管道 queue的连接,不是这样子的,管道queue的连接,是要让你将其中一个conn?发送给另一方,由另一方接收管道的另一个管口,意味着你可以将 conn1.close() ,然后将conn2留下来 send() 或 recv(),又或者是将 conn2.close() ,将 conn1 留下来 send() 或 recv(),返回来的是一个通道连接的管口名,但的确Pipe() 确实为我们创建了两个连接,所以我们要把其中一个连接给关闭了,不用浪费连接,毕竟半双工通信只能一方发送,一方等待接收,所以多余的连接是没用的。
关闭连接的步骤是在主进程这边关闭一个管道口名1.close(),在子进程那里再关闭另外的一个管道口名2.close() ,就完成了一次连接关闭(1和 2 是可以颠倒的)。
| 选择 1 | 选择 2 | ||
|---|---|---|---|
| 主进程 | 子进程 | 主进程 | 子进程 |
1.close() | 1 | 1 | 1.close() |
| 2 | 2.close() | 2.close() | 2 |
千万要注意不是只关闭了 1 或 2 的连接就可以了,而是要在两边分别关闭一个 2 或 1 的管道口,各 1 次。
————————————————————————————————————————
三、进程间同步 —— 需加锁,保证数据安全
1. 共享内存 share memory (Value、Array) (默认上锁)
基本特点:
(1)共享内存是一种最为高效的进程间通信方式,进程可以直接读写内存,而不需要任何数据的拷贝。
(2)为了在多个进程间交换信息,内核专门留出了一块内存区,可以由需要访问的进程将其映射到自己的私有地址空间。进程就可以直接读写这一块内存而不需要进行数据的拷贝,从而大大提高效率。(文件映射)
(3)由于多个进程共享一段内存,因此也需要依靠某种同步机制。(默认自动加锁 —— 同步锁)
优缺点:
优点:快速在进程间传递数据
缺点: 数据安全上存在风险,内存中的内容会被其他进程覆盖或 者篡改
注: 经常和同步互斥配合使用
这一点有点类似多线程的数据共享,系统给了进程一个共享内存操作,可以像是单进程代码定义变量后后,去获取变量值。只不过,既然提供了和线程相似的办法了,那么就得用线程的办法来控制数据安全 —— 线程锁 (五种线程锁)。
单单靠线程锁其实还是难以保证数据的安全,因为你无法猜到会轮到哪一个进程处理,如果是调用同一个执行函数的多进程还好控制,如果是调用不同执行函数的多进程,就会很难控制了。
一种方法是使用线程睡眠sleep()提升控制力,可以指定线程锁在一定时间内属于某个进程,而不被释放,这就可以有效保证不同执行函数的进程会很难控制,不过这只是笔者的见解,具体看实际情况分析。
共享内存要符合C语言的使用语法
Value 和 Array 的语法格式:
Value(typecode_or_type, *args, lock=True)
- 1
功能 :
- 得到一个共享内存对象,并且存入初始值,
method of multiprocessing - 返回
Returns a synchronized shared object(同步共享对象) typecode_or_type:定义了返回类型(转换成C语言中存储类型),它要么是一个ctypes类型,要么是一个代表ctypes类型的code。*args:开辟一个空间,并赋一个args值,值得类型不限lock默认自动上锁(同步锁)
注:
ctypes是python的一个外部函数库,它提供了和C语言兼容的数据类型,可以调用DLLs或共享库的函数,能被用作在python中包裹这些库。
Array(typecode_or_type, size_or_initializer, *, lock=True)
- 1
功能 :
- 使用基本类似于
Value,Returns a synchronized shared array(是一个可迭代对象) typecode_or_type:定义转换成C语言的存储类型;size_or_initializer:初始化共享内存空间,- 若为数字,表示开辟的共享内存中的空间大小,(
Value表示为该空间绑定一个数值) - 若为数组,表示在共享内存中存入数组
lock默认自动上锁(同步锁)
Value、Array 数据存储类型参数介绍:
| Type code | C Type | Python Type | Minimum size in bytes |
|---|---|---|---|
'b' | signed char | int | 1 |
'B' | unsigned char | int | 1 |
'u' | Py_UNICODE | Unicode character | 2 |
'h' | signed short | int | 2 |
'H' | unsigned short | int | 2 |
'i' | signed int | int | 2 |
'I' | unsigned int | int | 2 |
'l' | signed long | int | 4 |
'L' | unsigned long | int | 4 |
'q' | signed long long | int | 8 |
'Q' | unsigned long long | int | 8 |
'f' | float | float | 4 |
'd' | double | float | 8 |
初级 - 共享内存Value、Array 实例代码演示:
# test.py
from multiprocessing import Process, Value, Array
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行结果:
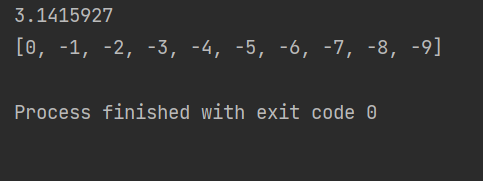
可以像是在代码内定义好的全局变量,供主进程和子进程使用,只需要知道传递的是一个Value和Array对象,值是对象内部的一个变量,我们要做的就是调用这个变量,其值默认被内核储存在一个专门的内存区了。
中级 - 共享内存 Array 样例代码:(代码内有4种初始化Array赋值的方法,可以自行测试)
# test.py
from multiprocessing import Process, Value, Array
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = a[i]+1
if __name__ == '__main__':
num = Value('d', 0.0)
# 1
# arr = Array('i', 10) # [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# 2
print(type(range(10))) # <class 'range'>
print(range(10)) # range(0, 10)
arr = Array('i', range(10)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 3
# arr = Array('i', [0]*10) # [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# 4
# arr = Array('i', [0, 1, 2, 3, 100]) # [0, 1, 2, 3, 100]
print("range(): ".format(arr))
print(arr[:])
p = Process(target=f, args=(num, arr))
p.start()
p.join() # 这里使用 time.sleep() 线程睡眠也是可以的,只不过要预判好时间
# 主进程要比子进程慢
print("Process Value: {}".format(num.value))
print("Process Array: {}".format(arr[:]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
参考链接:
python学习笔记——多进程中共享内存Value & Array
8.7. array — Efficient arrays of numeric values
2. 服务器进程 - 共享全局变量之Manager() (手动上锁,非默认)
由
Manager()返回的管理器对象控制一个服务器进程,该进程保存Python对象并允许其他进程使用代理操作它们。
Manager()返回的管理器支持类型:list、dict、Namespace、Lock、
RLock、Semaphore、BoundedSemaphore、Condition、Event、
Barrier、Queue、Value和Array。
代码演示:
# test.py
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这里的上锁,其实最应该上线程锁的是为了防范不同执行函数的进程,去调用共享变量,从而导致出现的数据安全问题,因而同一个进程其实上不上锁,归根到底都是在处理使用同一个执行函数,处理的过程都一样的,就好比如,完美理想状态下,你用100台相同的机器生产出来的东西难道就不一样吗?不要杠!差别在于顺序罢了,都已经放在同一个仓库里,还需要按顺序吗?这里是同种产品。
当然可能我没碰到过这种特别的情况,或许以后会来补充说明,就先告一段落。


