
【数据结构】单链表和双链表
赞
踩
一、链表的概念及结构
通过上篇顺序表我们了解到顺序表是一种顺序存储结构,顺序存储结构是用一段物理地址连续的存储单元依次存储数据元素的线性结构,我们一般采用数组来存储。
而本篇我们介绍的链表是链式存储的结构,链式存储结构的特点是:数据的物理地址是非连续的,可以在内存中的任意位置。也就是说逻辑上相邻的数据元素在空间上不一定连续。数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
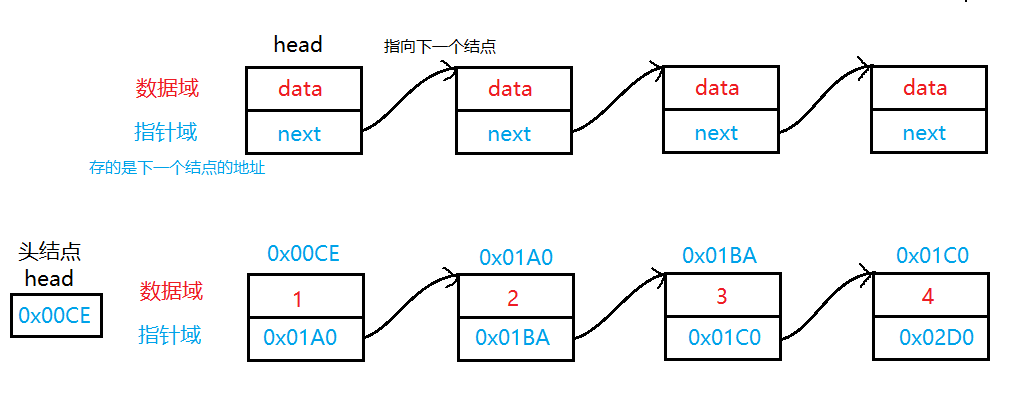
因为链表的每个结点是从堆上动态申请的,每次申请的空间是随机的,所以物理地址不一定是连续的。
二、链表的分类
1.带哨兵位头结点或不带头结点
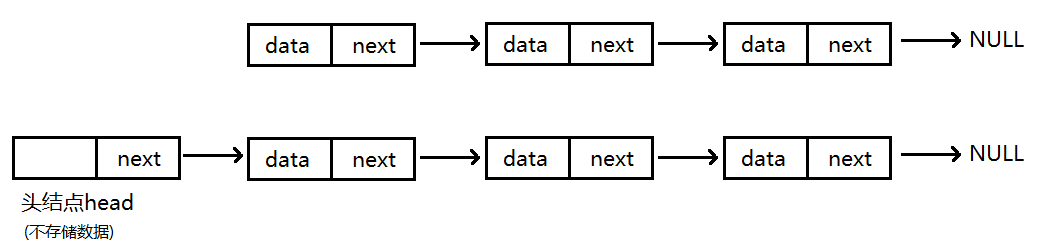
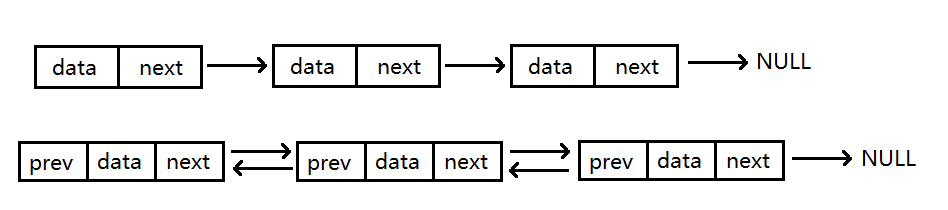
2.单向或双向
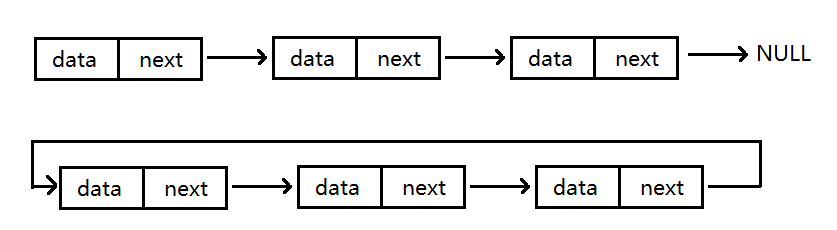
3.非循环或循环
一共有2^3 = 8种链表结构。
八种结构中,我们经常用到的只有两种结构:无头单向非循环链表和带头双向循环链表。
接下来我们就主要介绍这两种链表结构。掌握了这两种结构,其他几种也可以自己写出来了。
下面的内容涉及到结构体和指针等相关知识,忘了的小伙伴可以复习一下前面的知识。
传送门:结构体篇,指针篇,动态内存管理
三、无头单向非循环链表
我们所说的单链表通常是指无头单向非循环链表。
 单链表的定义
单链表的定义
typedef int DataType;//int可以换成char、double或者其他结构体类型
typedef struct SingleListNode
{
DataType data;//存储数据元素
struct SingleListNode* next;//存储下一个结点的地址
}SLNode;
- 1
- 2
- 3
- 4
- 5
- 6
1.单链表创建
//动态申请一个节点
SLNode* BuySLNode(DataType x)
{
SLNode* newNode = (SLNode*)malloc(sizeof(SLNode));
if (NULL == newNode)
{
perror("malloc");
return NULL;
}
newNode->data = x;
newNode->next = NULL;
return newNode;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
注意,单链表是不需要单独初始化的,因为我们每增加一个数据结点,都会动态申请一个空间,在申请的同时会初始化该结点,所以封装成一个函数,方便调用。
2.尾插和头插
现在介绍的是不带哨兵位头结点的单链表,后面的pphead都是单链表头结点的地址,这里的头结点不是指哨兵位头结点,而是指链表的第一个结点,表头的位置,二者是不一样的,具体会在后面介绍双链表时细说。
单链表尾插是将新申请的结点链接到尾结点的后面,但不能直接访问链表的尾结点,因此需要从头结点开始遍历链表到尾结点,然后链接新节点。
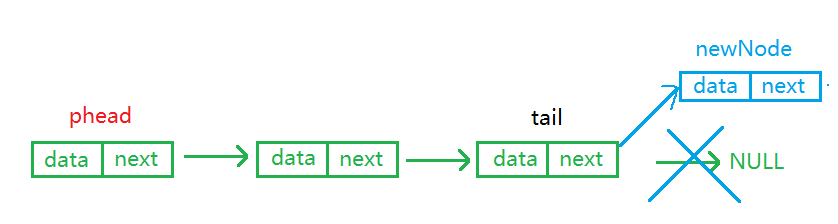 尾插分为两种情况:1.链表为空;2.链表非空
尾插分为两种情况:1.链表为空;2.链表非空
//尾插 void SLNodePushBack(SLNode** pphead, DataType x) { assert(pphead);//防止传错成空指针NULL //*pphead无需assert断言,链表可以为空 SLNode* newNode = BuySLNode(x); if (NULL == *pphead)//空链表情况 { *pphead = newNode; } else { //从第一个结点开始遍历到尾节点 SLNode* tail = *pphead; while (tail->next != NULL) { tail = tail->next; } //在尾结点后面插入新结点 tail->next = newNode; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
注意:链表在传入头结点(第一个结点)时,由于头结点是一个结构体指针类型,函数体中会修改头结点,所以要用二级指针来接收,否则形参的改变不会影响实参。
链表头插是在新结点的后面链接头结点,然后更新头结点。

//头插
void SLNodePushFront(SLNode** pphead, DataType x)
{
assert(pphead);//防止传错成空指针NULL
//空链表可以头插,*pphead无需assert断言
SLNode* newNode = BuySLNode(x);
newNode->next = *pphead;//头结点为空也适用
*pphead = newNode;//头插后更新头结点为第一个的结点
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
总结:
插入不需要assert断言链表是否为空,因为空链表也可以进行插入操作,只需断言传入的参数是否为空,因为要对pphead解引用,NULL不能解引用。
3.尾删和头删
尾删需要两个指针,prev用来指向尾结点的前一个结点,tail用来指向尾结点。
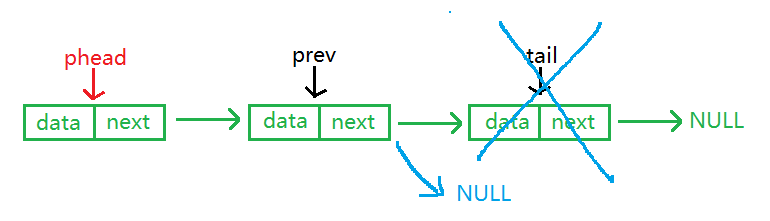
尾删同样需要分两种情况处理:1.链表只有一个结点;2.链表有两个结点及以上
//尾删 void SLNodePopBack(SLNode** pphead) { assert(pphead);//防止传错成空指针NULL assert(*pphead);//空链表不可删除 if (NULL == (*pphead)->next)//头结点下一个结点为空,则只有一个结点 { free(*pphead);//删除结点释放空间 *pphead = NULL; } else //两个以上结点 { SLNode* prev = NULL; SLNode* tail = *pphead; while (tail->next != NULL)//找到尾结点的前一个结点 { prev = tail; tail = tail->next; } prev->next = NULL; free(tail); tail = NULL; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
头删则不用考虑链表是否只有一个结点,只需要将头结点指向下一个结点即可。但是在改变头结点的指向之前要记得保存原来的头结点,是为了释放要删除的结点空间。
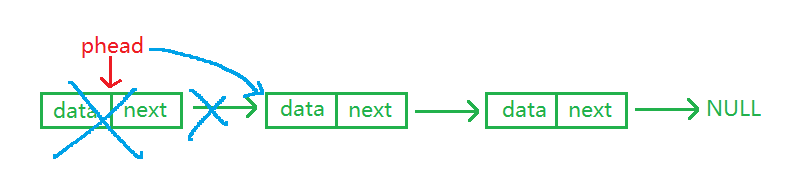
//头删
void SLNodePopFront(SLNode** pphead)
{
assert(pphead);//防止传错成空指针NULL
assert(*pphead);//空链表不可删除
SLNode* head = *pphead;//保存头结点 后续释放
*pphead = head->next;//头结点指向第二个结点
free(head);//释放刚刚保存的头结点
head = NULL;//置空,防止野指针
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
总结:
1.删除操作需要保证链表不为空,所以pphead和*pphead都需要断言判断。
2.结点删除后,需要及时free释放,防止内存泄漏;并置空,防止野指针的形成。
4.打印
遍历一遍链表,将每个结点的data打印。这里以int类型示例。
//打印链表
void SLNodePrint(SLNode* phead)
{
//空链表可以打印,无需assert断言
SLNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;//切忌cur++
}
printf("NULL\n");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5.查找
遍历链表,查找值为x的结点并返回该结点的指针
//查找
SLNode* SLNodeFind(SLNode* phead, DataType x)
{
SLNode* cur = phead;
while (cur != NULL)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
6.插入
插入分为两种情况插入:
1.在pos位置之前插入
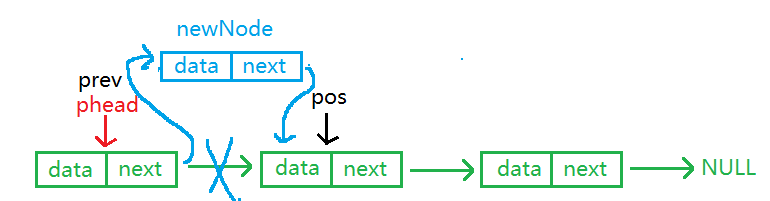
在pos位置之前插入,prev用来找到pos的前一个结点,在prev的后面尾插新结点即可。
//插入pos位置之前 void SLNodeInsert(SLNode** pphead, SLNode* pos, DataType x) { assert(pphead);//防止传错成空指针NULL assert(pos);//检查要插入的位置是否存在 assert(*pphead); if (pos == *pphead)//在头结点之前插入相当于头插 { SLNodePushFront(pphead, x);//头插 } else { SLNode* prev = *pphead; while (prev->next != pos)//找到pos位置的前一个结点 { prev = prev->next; } SLNode* newNode = BuySLNode(x); prev->next = newNode; newNode->next = pos; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.在pos位置之后插入
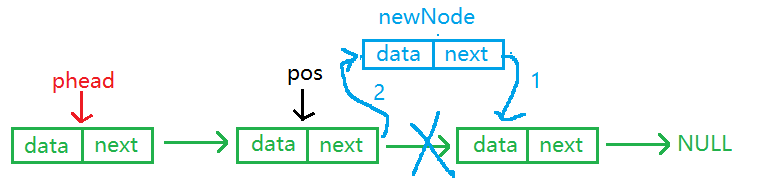
这种情况不需要找到pos的前一个结点,直接在pos后面链接新结点。
//插入pos位置之后
void SLNodeInsertAfter(SLNode* pos, DataType x)
{
assert(pos);
SLNode* newNode = BuySLNode(x);
//这两行顺序不能反,否则pos的下个结点会找不到
newNode->next = pos->next;
pos->next = newNode;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意:因为没有用到头结点,所以头结点可以不用传参。因为只改变了pos结点的next的指向,pos结点本身的值并没有改变,所以不需要用二级指针接收。
总结:
1.在pos位置之前插入,则不能进行尾插;在pos位置之后插入,则不能进行头插。
2.插入时要对pos进行检查,pos不能为空。
7.删除
删除pos指针指向的结点
//删除pos位置的结点 void SLNodeErase(SLNode** pphead, SLNode* pos) { assert(pphead);//防止传错成空指针NULL assert(pos);//检查要插入的位置是否存在 assert(*pphead); if (*pphead == pos)//头删 { SLNodePopFront(pphead); } else { SLNode* prev = *pphead; while (prev->next != pos) { prev = prev->next; } prev->next = pos->next; free(pos); //pos = NULL; pos是形参,改变对实参无影响;可以传二级指针,或者在外部置空 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
注意:pos指向的结点free掉之后,为了防止野指针的形成,需要置空处理。 如果传参时pos用的一级指针接收,则需要在外部调用SLNodeErase函数后,自行置空;如果要在函数内部free的同时置空,则需要用二级指针接收pos的地址。按喜好自行选择任意一种即可。
8.销毁
//销毁链表
void SLNodeDestroy(SLNode** pphead)
{
assert(pphead);
SLNode* cur = *pphead;
while (cur != NULL)
{
SLNode* next = cur->next;//先保存下一个结点再销毁
free(cur);
cur = next;
}
*pphead = NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
链表使用完毕不要忘了释放空间。
至此,单链表的内容总结完毕。接下来介绍带头双向循环链表的实现。
四、带头双向循环链表
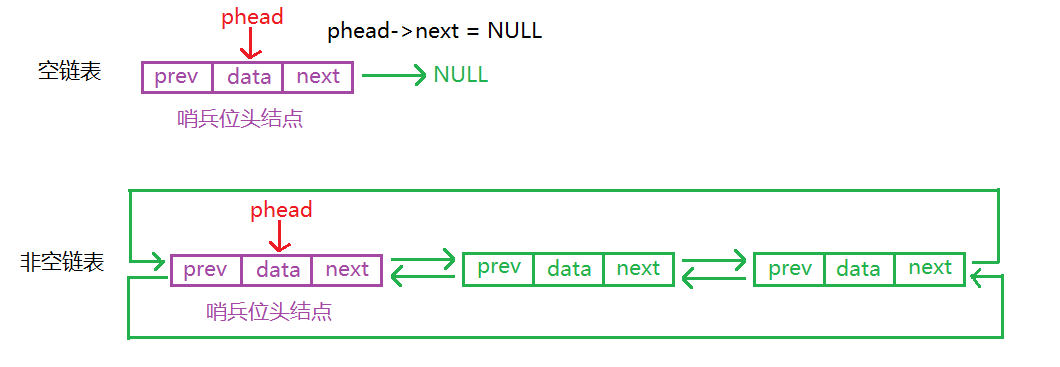 1.“带头”是指带有哨兵位头结点,与前面单链表中的头结点(链表第一个结点)不一样,哨兵位头结点不存储数据,并且next指向链表的第一个结点。这种情况就不需要单独考虑头结点是否为空。代码也更容易写。
1.“带头”是指带有哨兵位头结点,与前面单链表中的头结点(链表第一个结点)不一样,哨兵位头结点不存储数据,并且next指向链表的第一个结点。这种情况就不需要单独考虑头结点是否为空。代码也更容易写。
2.双向链表则比单向链表多一个prev指针,指向前一个结点。
3.循环链表中,尾结点的后驱结点指向头结点;双向循环链表中,头结点的前驱结点指向尾结点,尾结点的后驱结点指向头结点,整体构成一个环。
双链表的定义
typedef int DataType;
typedef struct DListNode
{
DataType data;
struct DListNode* prev;//存储前一个结点的地址
struct DListNode* next;//存储后一个结点的地址
}DLNode;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.双链表的创建
//申请结点
DLNode* BuyDLNode(DataType x)
{
DLNode* newNode = (DLNode*)malloc(sizeof(DLNode));
if (NULL == newNode)
{
perror("malloc");
return NULL;
}
newNode->data = x;
newNode->prev = NULL;
newNode->next = NULL;
return newNode;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.初始化
初始化将头结点的前驱结点和后驱结点都指向自身
//双链表初始化
DLNode* DLInit()
{
DLNode* phead = BuyDLNode(-1);
phead->prev = phead;
phead->next = phead;
return phead;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.判断链表是否为空
链表为空的条件是:头结点的前驱结点和后驱结点都指向自身,判断一个就行。
bool DLEmpty(DLNode* phead)
{
assert(phead);
return phead->next == phead;//或者return phead->prev == phead;
}
- 1
- 2
- 3
- 4
- 5
4.尾插和头插
尾插的时要注意,先将新结点和尾结点链接起来,再将新结点和头结点链接起来,否则先链接头结点会找不到尾结点。但是如果先将尾结点保存起来,则不用按照顺序。
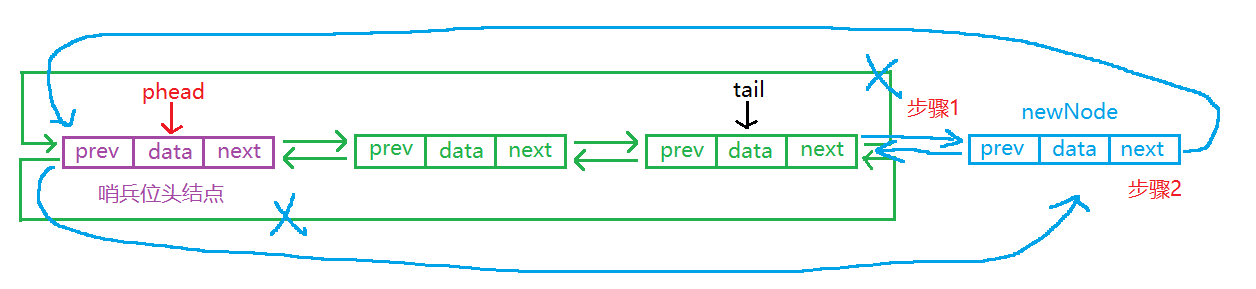
//尾插
void DLPushBack(DLNode* phead, DataType x)
{
assert(phead);//phead不能为空,否则说明传错了
DLNode* newNode = BuyDLNode(x);
DLNode* tail = phead->prev;//一步找到尾结点
tail->next = newNode;
newNode->prev = tail;
newNode->next = phead;
phead->prev = newNode;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
头插也是一样,如果先将第一个结点保存起来,则不需要注意链接顺序。
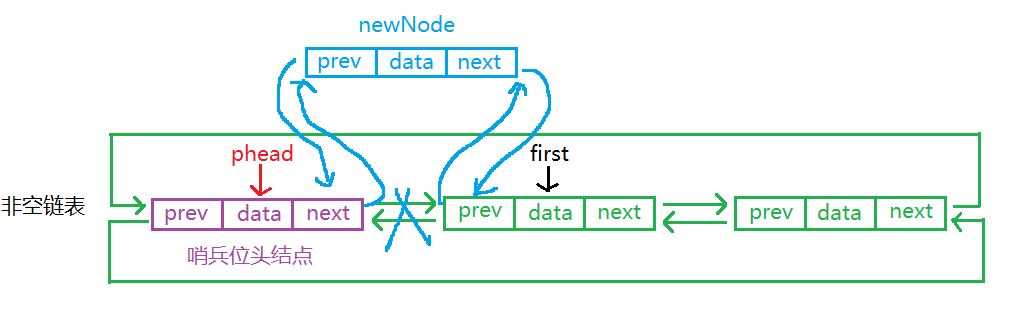
//头插
void DLPushFront(DLNode* phead, DataType x)
{
assert(phead);
DLNode* newNode = BuyDLNode(x);
DLNode* newNode first = phead->next;//保存第一个结点
first->prev = newNode;
newNode->next = first;
newNode->prev = phead;
phead->next = newNode;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意:带哨兵位头结点的链表,传参时不需要用二级指针接收,因为从始至终都不会改变头结点本身的值。
5.尾删和头删
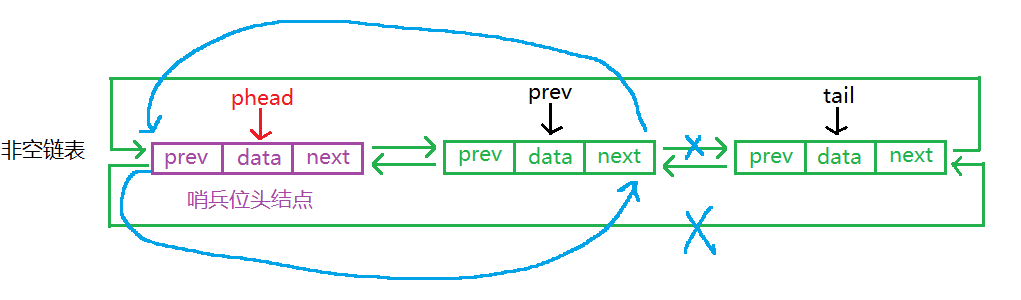
//尾删
void DLPopBack(DLNode* phead)
{
assert(phead);
//链表非空才能删除
assert(!DLEmpty(phead)); //或者写成assert(phead->next != phead);
DLNode* tail = phead->prev;//保存尾结点
DLNode* prev = tail->prev;//保存尾结点的前一个结点
phead->prev = prev;
prev->next = phead;
free(tail);
tail = NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
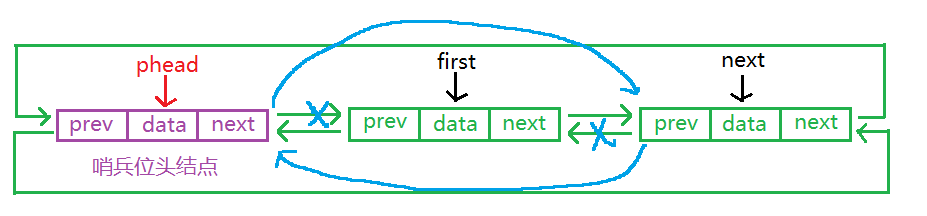
//头删
void DLPopFront(DLNode* phead)
{
assert(phead);
assert(!DLEmpty(phead));//链表为空不能删
DLNode* first = phead->next;//保存第一个结点
DLNode* next = first->next;//保存第一个结点的下一个结点
phead->next = next;
next->prev = phead;
free(first);
first = NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
6.查找
查找值为x的结点并返回指向该结点的指针
//查找
DLNode* DLFind(DLNode* phead, DataType x)
{
assert(phead);
DLNode* cur = phead->next;//cur指向第一个结点
while (cur != phead)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return NULL;//找不到则返回空
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
注意:查找结束的条件是当前结点不等于头结点,相等说明进入下一轮循环。
7.插入
在pos之前插入新结点
//pos位置之前插入
void DLInsert(DLNode* pos, DataType x)
{
assert(pos);
DLNode* newNode = BuyDLNode(x);
DLNode* prev = pos->prev;
prev->next = newNode;
newNode->prev = prev;
newNode->next = pos;
pos->prev = newNode;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
实现该函数后,头插和尾插可以用一行代码解决:
DLInsert(phead->next, x);//头插:在头结点的下个结点(第一个结点)之前插入
DLInsert(phead, x);//尾插:在头结点的前面(尾结点的后面)插入
- 1
- 2
8.删除
//pos位置删除
void DLErase(DLNode* phead, DLNode* pos)
{
assert(pos);
assert(pos != phead);//不能删除头结点
pos->next->prev = pos->prev;
pos->prev->next = pos->next;
free(pos);//外部置空
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
同样,实现该函数后,头删和尾删可以用一行代码解决:
DLErase(phead, phead->next);//头删
DLErase(phead, phead->prev);//尾删
- 1
- 2
9.销毁
//链表销毁
void DLDestroy(DLNode* phead)
{
assert(phead);
DLNode* cur = phead->next;
while (cur != phead)
{
DLNode* next = cur->next;//先保存待销毁结点的下一个结点
free(cur);
cur = NULL;
cur = next;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
五、总结
1.通过本篇,掌握不带头单向非循环链表和带头双向循环链表之后,大概也能类推写出其他六种链表结构。
2.不带头的链表传参数需要二级指针来接收,因为函数中可能会改变头结点(第一个结点)的值,例如链表为空时的操作。带头的链表传参时只需一级指针接收即可,因为并不会改变头结点(哨兵位头结点)的值。
3.双向链表插入删除操作时,如果不事先保存结点的前后结点,则需要注意链接顺序,否则会找不到原来的结点。
4.在pos位置进行删除操作时,要么传入二级指针置空,要么在外部调用函数完自行置空,否则会形成野指针。
5.链表的头插尾插和头删尾删可以不用写,都可以用插入和删除函数实现。
链表和顺序表的对比
顺序表存储方式是顺序存储,即在内存中连续存储数据元素,通过下标来访问元素。
链表存储方式是链式存储,即数据元素在内存中不一定连续,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表的优点:
1.任意位置插入和删除只需修改指针指向,效率很高,时间复杂度为O(1)。
2.需要一个结点就申请一个空间,空间利用率高。
链表的缺点:
不支持随机访问,对结点的操作需要从头指针开始遍历,效率低。
顺序表的优点:
可以根据下标随机访问任意位置的元素,效率为O(1),尾插尾删效率很高。
顺序表的缺点:
1.任意位置插入和删除需要移动元素位置,效率很低,时间复杂度为O(N)。
2.扩容有一定的消耗,可能会有一定空间的浪费。
可以发现,顺序表和链表的优缺点是互补的。对于数据元素较少,访问频繁,插入、删除情况较少的场景选择顺序表,对于数据元素较多,插入、删除操作频繁的场景选择链表。

