
- 1去了字节跳动,才知道年薪50W的测试有这么多?_字节跳动年薪50万是什么水平
- 2一个多合一的 AI 大模型客户端,支持本地部署大模型,实现大模型自由_jan.ai 训练自己数据
- 3线性表顺序存储结构的基本实现_通过线性表结构实现电话本模拟程序。编程实现顺序存储结构中的基本操作的实现
- 4微信小程序真机调试和预览无法进入request_真机调试登录不上
- 5使用Postman创建Mock Server_postman创建服务端
- 6Pycharm连接远程服务器进行模型训练——以YOLOv8为例_pycharm autodl yolov8
- 7git干获,从安装到上传项目(详细)_git 安装并上传文件
- 8java 表单重复提交,进行幂等性控制,防止_java接口幂等性,防止重复提交
- 9M系列 Mac安装配置Homebrew_mac homebrew
- 10ChatGPT完美平替!Jan AI:属于你的本地大语言模型!_jan – 免费的 chatgpt 开源替代
NLP——序列标注之命名实体识别_nlp 实体标注法
赞
踩
1.概述
序列标注包括自然语言处理中的分词,词性标注,命名实体识别,关键词抽取,词义角色标注等。解决方案是NN模型(神经网络模型)+CRF
命名实体识别(Named Entity Recognition,简称NER)是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、日期、时间、百分数、货币等。这里就需要理解句子的词性。
词性是词汇的语法属性,是连接词汇到句法的桥梁,一个词的词性与它在句子中的成分密切相关。在传统语法学中,汉语句子主要分为主语、谓语、宾语、定语、状语、补语6个成分。词性分为名词、动词、代词、形容词、数量词、副词等。
例:游泳是一种很好的健身运动
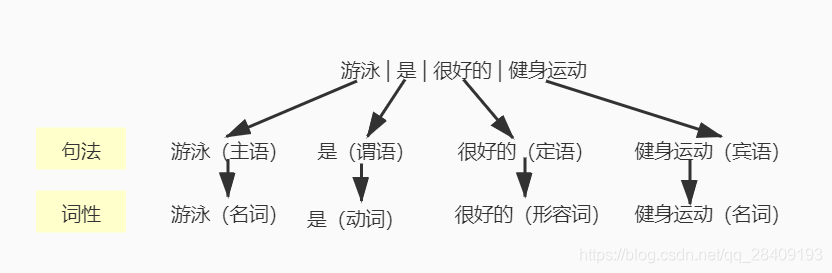
在NLP任务中,中文分词、词性标注、组块标注、浅层语法分析等任务,标记和切分观察序列都是序列结构,解决此类问题的模型基本是概率图模型中的序列算法,这一系列问题通常称为标记序列学习或序列学习。任务的顺序是命名实体识别->词性标注->语义组块标注。但从算法应用策略的复杂性而言,命名实体识别是最复杂的序列标注任务。
词性标注常用算法:最大熵
词性标注常用工具:stanfordNLP
序列标签分成两个部分,第一部分是IOB表示法(或BIO表示法),B代表当前词在一个组块的开始,I代表在当前词在一个组块中,O代表当前词不在任意一个组块中。另一个变种,start/end表示法:
- B代表当前词在一个组块的开始
- I代表在当前词在一个组块内部
- E代表在当前词在一个组块终结
- O代表当前词不在任意一个组块中
- S代表在当前词是一个组块,该组块只有一个词
例如:(快递信息识别)张三18625584663广东省深圳市南山区学府路东百度国际大厦(P代表人名,T是电话号,A是地址,A1是省,A2是市,A3是区,A2是街道(详细地址))
| 文本 | 符号 |
| 张三 | P |
| 18625584663 | T |
| 广东省 | A1 |
| 深圳市 | A2 |
| 南山区 | A3 |
| 学府路东百度国际大厦 | A4 |
用BIO表示法:

从语言分析的全过程来看,命名实体识别属于中文分词中未登录词识别的范畴,也是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。
2.相关算法
2.1 概率图模型
概率图模型分为贝叶斯网络和马尔科夫网络,贝叶斯网络是有向图结构,马尔科夫网络是无向图结构。概率无向图模型又称为马尔科夫随机场,是无向图表示的联合概率分布。
定义:设有联合概率分布P(Y),由无向图G=(V,E)表示,在图G中,结点表示随机变量,边表示随机变量之间的依赖关系。如果联合概率分布P(Y)满足成对、局部和全局马尔科夫性,就成次联合概率分布为概率无向图模型。
- 成对:有两个结点u,v,对应的随机变量是Yu,Yv,其他结点为Yo,在Yo的条件下随机变量Yu,Yv是条件独立
- 局部:有一个结点v,其它与v有边相连的集合是w,其他结点是o,则在Yw的条件下Yv,Yo是独立的
- 全局:结点集合A,B在无向图G中被集合C分开的任意结点集合,则在Yc条件下Ya,Yb条件独立
2.2 条件随机场
在条件概率模型P(Y|X)中,Y是输出变量(表示标记序列),X是输入变量(需要标注的序列),学习时,通过极大似然估计得出条件概率模型,预测时,对于给定的输入序列x,求出条件概率最大的输出序列y。
CRF定义:设X和Y是随机变量,P(Y|X)是给定X的条件下Y的条件概率分布,若随机变量Y构成了一个由无向图G=(V,E)表示的马尔科夫随机场,即
是除v以外的其他结点,
在无向图中与v有边连接的所有结点w。称P(Y|X)为条件随机场。
linear chain CRF定义:设X,Y是线性链表示的随机变量序列,在X的条件下,Y的条件概率分布构成条件随机场,即满足马尔科夫性
序列标注任务除了长句子以外,还有标签之间的依赖性需要关注。与简单的分类任务不同,命名实体识别是需要获取标签之间的依赖关系,例如张三(P-B,P-I)是人名,且张和三存在依赖关系。
如下图,CRF是属于概率图模型,绿点是输入(GRU的输出),红点是输出,点和点之间的边分为两类,一类是x和y之间的连线,表示其相关性,另一类是相邻y之间的相关性。

3.算法包
3.1 词性标注和NER
- #词性标注
- import nltk
- pos = nltk.word_tokenize(text)
- pos_ = nltk.pos_tag(pos)
- for i in pos_:
- print(''.join(i))
- pos__ = nltk.ne_chunk(pos_, binary=True)
- for j in pos_:
- print(''.join(j))
3.2 CRF
在paddlenlp中,实现线性链条件随机场。
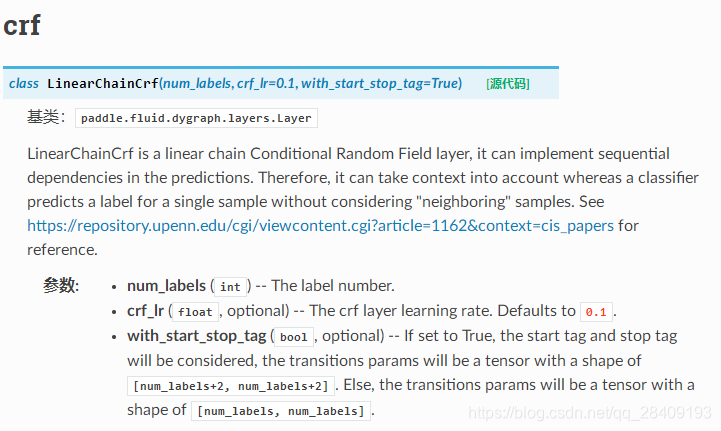
4.实现(快递单信息提取)
(1)读取数据,并将数据转换成paddle可以接受的模型数据
- from paddle.utils.download import get_path_from_url
- URL = "https://paddlenlp.bj.bcebos.com/paddlenlp/datasets/waybill.tar.gz"
- get_path_from_url(URL,"./")
-
- for i, line in enumerate(open('data/train.txt')):
- if 0 < i < 5:
- print ('%d: ' % i, line.split()[0])
- print (' ', line.split()[1])
数据集格式:

(2)转换paddle数据集格式

- 定义trans_func(),直接用map映射,或者是在dataLoader时作为函数传入。
直接map映射,对数据执行convert_example函数里边的操作。
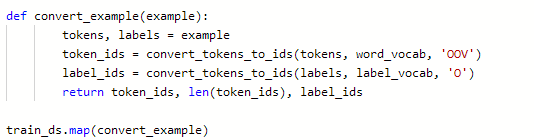
通过partial操作,partial除了函数外,还需指定函数中的参数(tokenizer,max_seq_length),此处函数只做对比,仅参考。

最终将数据转换成有特征和标签的train、dev数据,或只有特征的test数据,快递单信息识别是获取到了快递单信息词向量列表(token_ids),词向量长度(len(token_ids)),标签列表(label_ids)。
- 定义dataLoader
对数据进行转换,相关函数有Pad(对数据进行填充),Stack(对数据进行堆叠),Tuple,对上述过程的2个特征信息,1个标签信息进行转换。

还可以进行随机采样,这里有两种采样方式,在CPU中,使用paddle.io.BatchSampler,在GPU中,使用paddle.io.DistributedBatchSampler。
- if mode == 'train' and use_gpu:
- sampler = paddle.io.DistributedBatchSampler(
- dataset=dataset, batch_size=batch_size, shuffle=True)
- else:
- shuffle = True if mode == 'train' else False
- sampler = paddle.io.BatchSampler(
- dataset=dataset, batch_size=batch_size, shuffle=shuffle)
然后转换成DataLoader。
- dataloader = paddle.io.DataLoader(
- dataset,
- batch_sampler=sampler, #随机采用
- return_list=True,
- collate_fn=batchify_fn #数据转换)
(3)定义模型(包括模型定义、模型优化、损失函数计算等)
此处选择的模型是Bi-GRU+CRF,其中GRU的输出是CRF的输入。

模型其他参数:

ChunkEvaLluator函数是集成了precision、recall和f1的评价指标,常用于序列标记任务。
模型训练、预测、评估不做讲述!!!
具体代码实现:https://aistudio.baidu.com/aistudio/projectdetail/2042911

