
- 1CCF稀疏向量100分代码(利用输入的顺序,使用队列巧解)_ccfint a[100][100]
- 2Pytorch - CNN、RNN、GRU 分类_pytorch中gru时间序列分类
- 3讲解Canvas中的一些重要方法
- 4模型压缩整理2020.5.6_sparsity ratio
- 5手机运营商二要素验证接口:确保业务操作安全可靠_手机运营商二要素验证接口:确保业务操作安全可靠
- 6基于FPGA的计算器(含源码)_基于fpga的多功能计算器的设计
- 7Java中的内部类(如果想知道Java中有关内部类的知识点,那么只看这一篇就足够了!)
- 8SpringBoot系列之搭建WebSocket应用_spring boot 开放websocket
- 9【重点突破】—— React应用中封装axios(转),2024年最新腾讯+华为+阿里面试真题分享_axios react
- 10基于java中的springboot框架实现智慧图书管理系统设计演示【附项目源码+论文说明】_图书管理系统javaspringboot
FPGA设计优化(1.2)_laguna xilinx
赞
踩
Vritex UltraScale+还引入了HBM(HighBandwidth Memory),有效地增大了数据存储空间及数据传输带宽,其内部布局如图1-16所示,仍然采用了SSI技术,HBM位于单独的一个SLR上。在与其紧邻的SLR内,集成了硬核的HBM控制器。Vritex UltraScale+HBM FPGA内HBM的 容 量 对 比 如 图 1-17 所 示 , 可 以 看 到 , HBM 最 小 为 4GB ( 也 就 是32Gb),最大为16GB(也就是128Gb)。在执行机器学习算法时,通常需要存储大量的权值,而且为了保证足够的并行性,需要同时从存储空间读出多个数据,传统的BRAM和UltraRAM很难满足这一需求,而HBM正好解决了这一问题。

这里不得不提一下Xilinx第二代SSI芯片。Kintex UltraScaleFPGA 只 有 KU085 和 KU115 为 SSI 芯 片 , 均 包 含 2 个 SLR 。 VirtexUltraScale FPGA有4颗芯片为SSI芯片,分别为VU125(2个SLR)、VU160(3个SLR)、VU190(3个SLR)和VU440(3个SLR)。而Virtex
UltraScale+FPGA的芯片绝大多数为SSI芯片。与第一代SSI芯片相比,第二代SSI芯片不仅有专用跨die布线资源(SLL),还有专用跨die寄存器(LAGUNA寄存器),如图1-18所示。在相邻两个die的边界,每个时钟区域内有2列LAGUNA寄存器,SLL起点和SLL终点位于同列不同die的LAGUNA寄存器上。每2列LAGUNA寄存器,也就是die边界的每个时钟区域可提供2880个SLL,在图1-18中,每个SLR位于边界的时钟区域共有6个,因此可提供17280个SLL。

作为第二代嵌入了ARM核的FPGA,Zynq UltraScale+MPSoC的性能进一步提升,共有3个系列:CG、EG和EV。ARM核由Cortex-A9升级为Cortex-A53 , 采 用 双 核 ( CG ) 或 四 核 ( EG 和 EV ) , 扮 演 着 APU(Application Processing Unit,应用处理单元)的角色,主频可达
1.5GHz。同时,嵌入了RPU(Real-time Processing Unit,实时处理单元),采用双核ARM Cortex-R5F,主频最高可达600MHz。EG和EV系列还嵌入了GPU(Graphics Processing Unit,图形处理单元)Mali-400MP2,主频最高可达667MHz。在此基础上,EV系列增强了视频处理
功 能 , 嵌 入 了 硬 核 视 频 编 解 码 处 理 单 元 VCU ( VideoEncoder/Decoder),可支持H.264/H.265,如表1-3所示。以EV系列为例,其内部布局如图1-19所示,图中,灰色部分为PL。

在Zynq MPSoC的基础上,Xilinx还将射频模数转换器/数模转换器
( Radio Frequency Analog-to-Digital Converter/Digital-toAnalog Converter,RF-ADC/DAC)和软判决前向纠错(Soft DecisionForward Error Correction)集成,形成了Zynq RFSoC FPGA,是业界唯一的单芯片自适应射频平台,其内部布局如图1-20所示。在图1-20中 , 灰 色 部 分 为 PL 。 DDC 为 数 字 下 变 频 器 ( Digital DownConverter),DUC为数字上变频器(Digital Up Converter)。ADC的分辨率为12位(如XCZU25DR)或14位(如XCZU42DR),最多可达16个
(如XCZU29DR)。采样速率最高可达4.096 GSPS(Gigabit SamplesPer Second,每秒千兆次采样),如XCZU25DR。DAC分辨率为14位,最多可达16个,如XCZU29DR,采样速率最高可达9.85 GSPS。SD-FEC仅存在于XCZU21DR、XCZU28DR、ZCZU46DR和XCZU48DR中,共8个。

2019年,Xilinx推出了基于7nm工艺制程的Versal芯片,将其定义为ACAP(Adaptive Compute Acceleration Platform,自适应计算加速平台),而不再是FPGA。ACAP包含三大引擎:标量引擎、自适应引擎和智能引擎,通过可编程片上网络(Programmable Network onChip,可编程NoC)将三者连接在一起,如图1-21所示。其中,标量引擎由双核ARM Cortex-A72和双核ARM Cortex-R5F构成,主频可分别达到1.7GHz和800MHz;自适应引擎由传统的FPGA逻辑资源构成,包括CLB 、 BRAM 和 UltraRAM; 智 能 引 擎 主 要 提 供 计 算 功 能 , 由 AIE(Artificial intelligence Engine)和DSP58构成。

目前,Versal ACAP已推出5个系列:AI Edge系列、AI Core系列、Prime系列、Premium系列和HBM系列,其性能对比如表1-4所示。表1-4中的存储空间是指分布式RAM,即LUTRAM、BRAM和UltraRAM的总和。AI Edge系列嵌入了针对机器学习推理应用而优化的AIE-ML,AI Core系列嵌入的则是第一代AIE。其他系列没有嵌入AIE。

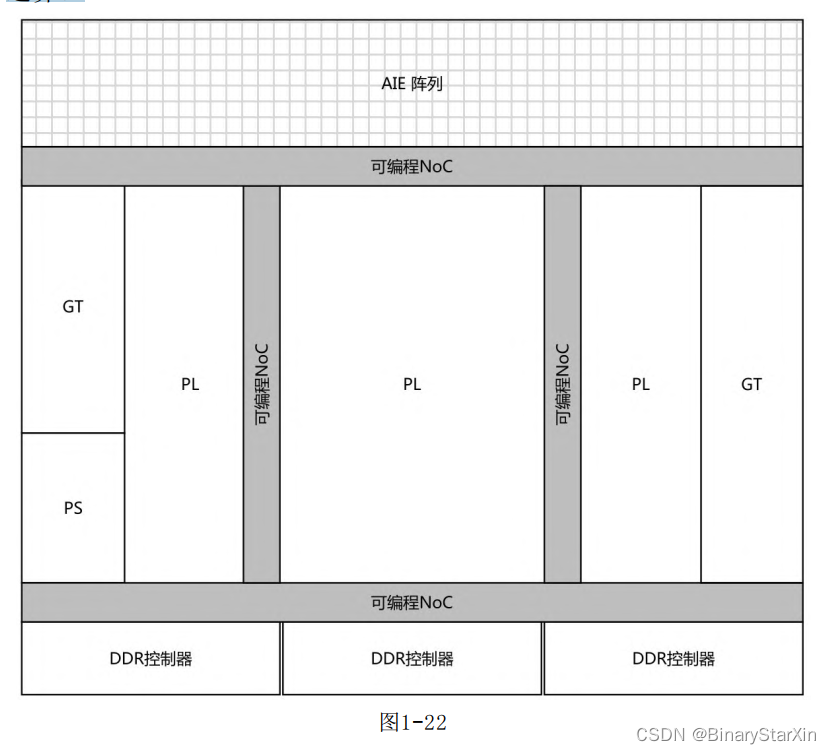
以AI Core系列为例,芯片内部布局如图1-22所示。其中,AIE阵列位于芯片最上方,DDR控制器位于最下方,两者通过可编程NoC实现数据传输。不难看出,与前一代UltraScale+FPGA相比,Versal中的硬核越来越多。为了发挥这些硬核的性能,需要在设计初期研究芯片架构,规划好整个系统的布局。
AIE阵列中的每个AIE核的内部结构如图1-23所示,其核心部分是向量单元,可提供强大的计算能力。例如,其中的乘加器在一个时钟周期内可实现128个8×8有符号数乘法运算或32个16×16有符号数乘法运算。

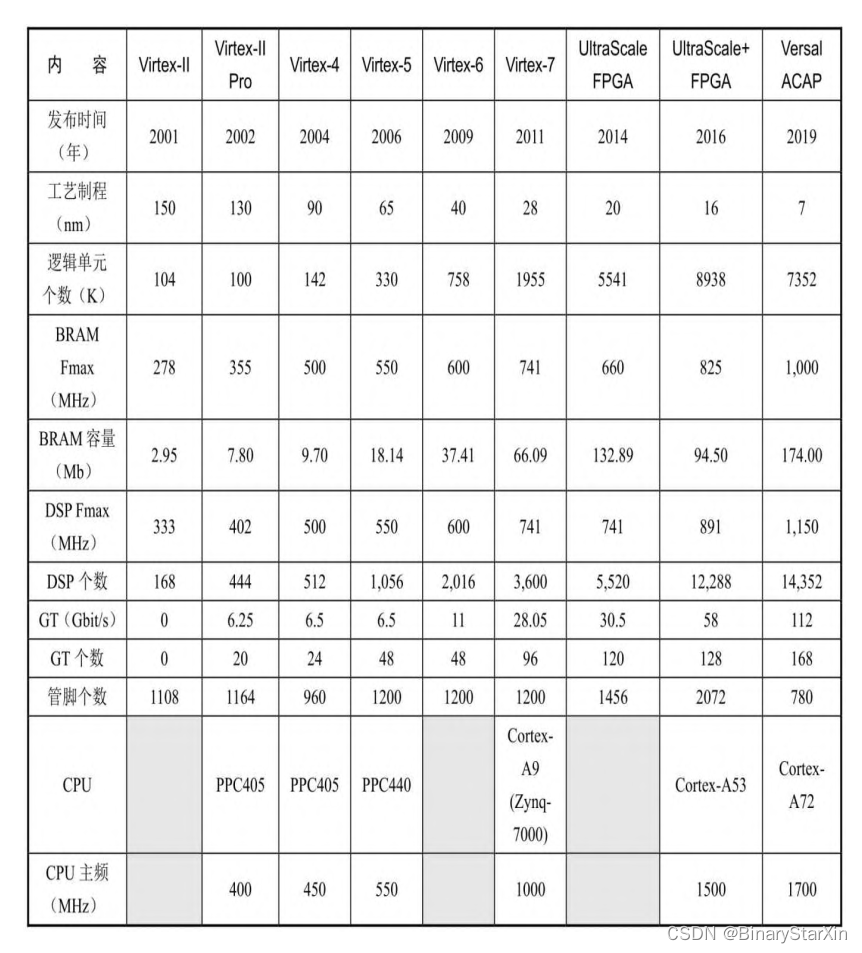
从2001年发布Virtex-II FPGA到2019年发布Versal ACAP,在近20年的时间里,Xilinx先后推出了9代产品,如表1-5所示,平均每两年就会有一代新产品诞生。产品性能不断突破:容量越来越大,速度越来越快。产品架构不断革新:从仅有PL到嵌入CPU,再到嵌入AIE。架构的不断演进使得FPGA除了在传统领域(如原型验证、通信、工业控制、航空航天等)继续保持一定优势,还使得FPGA进入新的领域,如数 据 中 心 , 成 为 数 据 中 心 加 速 器 、 AI 加 速 器 、 SmartNIC ( SmartNetwork Interface Card,智能网卡)及网络基础设施中的加速器。而FPGA厂商除了提供FPGA芯片,还生产制作了各种加速卡,如Xilinx的Alveo加速卡、Varium加速卡,以期在最大限度上满足业务需求,帮助客户缩短研发周期。
1.2 设计方法的演变
FPGA的设计方法是伴随着芯片架构的演变而演变的。在FPGA诞生初期,由于其内部资源较为单一,因此仅仅扮演着胶合逻辑的角色,在整个系统中只能起到协同作用。此时的设计方法也比较简单,如图1-24所示。设计输入使用RTL(Register Transfer Level,寄存器传输级)描述方式,功能仿真也称为前仿或行为级仿真,以验证设计功能是否正确;综合后仿真(Post Synthesis Simulation)则用于验证综合后的电路功能是否正确;时序仿真又称为后仿,仿真时反标了门级延迟和布线延迟信息,用于验证布线后的电路功能是否正确。一般情况下,无论是综合后仿真还是时序仿真,相比于行为级仿真都更为耗时,尤其是当设计规模比较大时,因此,通常当设计出现问题时才会执行综合后仿真和时序仿真。
随着FPGA内部资源越来越丰富,嵌入了BRAM,增大了存储空间,嵌入了乘加器,增强了计算能力,嵌入了高速收发器,提升了数据传输带宽,进行FPGA设计时要结合算法特征,分析哪些算法适合在FPGA上实现,以充分发挥FPGA的性能,从而形成如图1-25所示的开发流程。这里,软/硬件分割是设计的关键点。总体而言,数据流比较单一、运算密集但比较规整的算法(如FIR数字滤波器、FFT等)就非常适合在FPGA上实现。进一步划分,则要采取“缓存-计算-缓存”的模式,以适配FPGA的架构。而分支较多、判断条件复杂、数据路径形成反馈回路的算法更适合在CPU上实现。同时,FPGA更适合处理定点数据类型(尽管目前FPGA也支持浮点数据类型)。图1-25中FPGA部分的顶层 功 能 验 证 过 程 与 图 1-24 一 致 , 可 采 用 Xilinx 开 发 工 具 ISE(Integrated Software Environment)完成。


针对FPGA子系统,要从3个角度考虑,即物理级设计规范、时序设计规范和硬件设计规范,如图1-26所示。其中,物理级设计规范是为芯片选型服务的,根据资源评估、功耗预算和时钟频率确定芯片型号。时序设计规范是指在确定时钟网络拓扑结构(时钟管脚位置、输入时钟频率、输出时钟频率、全局时钟/区域时钟)的基础上,规划I/O时序(尤其是源同步设计和系统同步设计)和跨时钟域路径时序,基于此描述时序约束。硬件设计规范则是指根据数据流合理规划RTL代码层次结构,在此基础上进行各子模块的开发,最终为时序收敛服务。

在硬件设计规范中,RTL代码层次结构是重点,这对综合、布局布线和时序收敛都会产生直接影响,应遵循的原则如下。
• 需 要 实 例 化 的 输 入 / 输 出 单 元 ( 如 IDDR 、 ODDR 、 ISERDES 、OSERDES等)应尽可能靠近设计顶层,尽管IBUF、OBUF、IOBUF和OBUFT可由综合工具自动推断出来,但要确保IOBUF、OBUFT的使能信号和输入/输出信号在同一层次,以确保工具正确推断。
• 将时钟生成模块(通常采用IP Clocking Wizard生成时钟,不建议使用MMCM或PLL原语)放在顶层,方便其他模块使用时钟。
• 在层次边界添加寄存器,确保关键模块是寄存器输出,这样可将关键路径隔离在单一层次或模块之内,对于修复时序违例及设计调试大有裨益。
• 确保需要手工布局的模块在同一层次之内。
图1-27给出了基于上述原则而形成的层次结构,图中,每个子模块的阴影部分表示输出寄存器。

随着FPGA中嵌入ARM核构成SoC芯片,如Zynq-7000,SoC的设计方法应运而生,如图1-28所示。在软/硬件分割阶段,根据算法特征和系统需求(是否运行操作系统)将系统分为两大模块:硬件模块(在PL上实现)和软件模块(在PS上实现)。硬件开发依然采用传统的FPGA开 发 模 式 。 软 件 开 发 则 需 要 借 助 Xilinx 开 发 工 具 SDK ( Software Development Kit)。

芯片架构和设计方法的演变也催生了Xilinx新一代开发工具Vivado的问世,随之问世的还有高层次综合工具Vivado HLS(现更名为Vitis HLS),Vivado反过来又影响了设计方法。如图1-29所示,Vivado提出了以IP为核心的设计理念,进一步强调了设计的可复用性。在设计输入阶段,设计源文件可以是传统的RTL代码,可以是C/C++或OpenCL模型(采用Vitis HLS开发),也可以是Simulink下的AIE模型、HDL模型(原System Generator)或HLS模型(这3个模型隶属 于 同 一 个 开 发 工 具 Vitis Model Composer , 该 开 发 工 具 嵌 入 在Simulink中)。其中,以高级语言(C/C++或OpenCL)描述的模型和以Vitis Model Composer搭建的模型均为高抽象度模型,需要借助相应的工具将其转化为HDL(Hardware Description Language)代码。而Vitis HLS或Vitis Model Composer最终都将其封装为IP,同时,传统的RTL代码描述的模型也可以通过IP封装器(IP Packager)封装为IP,这些IP均可直接嵌入Vivado IP Catalog当作常规IP使用,也可以直接在IP集成器(IP Integrator,IPI)中以模块方式使用。这样,在IPI中进行设计开发就像搭积木一样。基于IPI开发设计形成的文件为.bd文件,为了实现IPI模型的可复用,Vivado又引入了BDC(BlockDesign Container)功能,即可以在一个IPI模型中实例化另一个IPI模型。在设计调试方面,可以借助VLA(Vivado Logic Analyzer,Vivado逻辑分析仪)。VLA取代了ISE时代的ChipScope。使用VLA需要在设计中添加ILA(Integrated Logic Analyzer)或VIO(Virtual
Input/Output)。有3种方式可以完成这一操作:①在RTL代码中实例化ILA和VIO(VIO仅支持代码实例化);②在综合后的网表中插入ILA;③在布线后的网表中采用ECO(Engineering Change Order,工程变更命令)方式修改ILA。

对比图1-29和图1-24不难发现,Vivado要求在综合之后就要对设计进行时序分析,确保建立时间收敛或接近收敛,这实际上是一个重大变化。这意味着若综合后依然存在建立时间违例,那么布线后时序收敛的可能性也不会大。
在软件开发方面,Xilinx于2019年推出了统一的软件开发平台Vitis,取代了原有的SDAccel,同时,其功能进一步增强。SoC、MPSoC、AIE均可在Vitis下进行开发。
无论工具如何推陈出新,功能如何变化,到目前为止,FPGA设计始终遵循的一个思路就是提高设计的可复用性。简而言之,对于一些常用模块,通过参数化处理,使其可以适配不同项目的需求,提高设计的可复用性。这样的好处是避免了重复开发,从而缩短开发周期,同时因为这些模块已经经过实际项目的验证,所以在功能和质量方面都有所保障。这其实就是用户自己开发的IP。我们把“可复用性”的理 念 进 一 步 扩 大 , 如 图 1-30 所 示 。 设 计 输 入 阶 段 , 从 RTL 代 码 到
C/C++代码,再到Model Composer模型,都可以做成参数化形式。相应的 功 能 仿 真 阶 段 用 到 的 HDL 测 试 平 台 、 C/C++ 测 试 平 台 和 ModelComposer测试平台也可以做成参数化形式。

本书提供的很多VHDL代码均已做参数化处理,可以方便快捷地实现设计复用。

