
热门标签
热门文章
- 1人工智能(AI)技术作为当今科技创新的前沿领域,为创业者提供了广阔的机会和挑战_ai给创业带来的机遇与挑战2000字
- 2ChatGPT等大模型可以代替搜索引擎吗?
- 3关于海康工业相机连接电脑时出现链接速度低于1Ggps解决办法_海康mvs当前网络低于1gps
- 4SQL Server查询数据库表和数据库字段_sql server查询表及字段
- 5【ai】livekit:Agents 3 : pythonsdk和livekit-agent的可编辑模式下的安装_live kit agent
- 6自然语言处理的数据集分析:IMDB与WikiText
- 7c语言----队列
- 8CNN FPGA加速器实现(小型)CNN FPGA加速器实现(小型)_fpga加速cnn
- 9MudBlazor组件意思及对应的标签
- 10各版本Sql Server下载地址全
当前位置: article > 正文
推荐算法炼丹笔记:Facebook向量召回双塔模型
作者:我家小花儿 | 2024-06-19 18:14:58
赞
踩
向量召回中的双塔模型

不知道多少人还记得 《做向量召回 All You Need is 双塔》那篇,那篇介绍了国内外各个大厂做召回的用的双塔模型,其中提到一篇《Embeding-based Retrieval in FaceBook Search》,还跟大家强烈建议,该篇必读,不知道有多少炼丹师认真读了?什么?你还没读!没关系,十方今天就给大家解读这篇论文。
很多炼丹师往往迷恋于各种复杂的网络结构,比如某市值跌了几个“百”的大厂,每年都有各种花里胡哨的论文,这些结构有用吗?既然能发论文肯定有用(手动滑稽)。为什么十方在众多论文中强推"脸书"这篇呢?先给大家看下脸书的"双塔"。
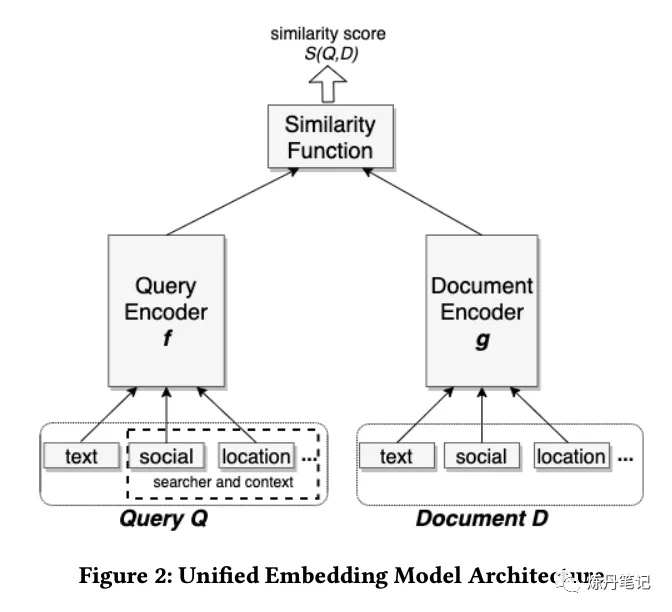
看完结构后,会不会有点劝退,什么!十方你就给我看这个,普普通通的双塔?Attention呢?Bert呢?FM呢?RNN呢?没错,这篇论文的精髓,不是网络结构,而是你在做召回时会遇到的方方面面的问题,以及解决方案,十方给大家慢慢揭晓。
对于一个搜索引擎而言,往往由两个层构成,一个叫召回层,另一个叫排序层。召回层的目的就是在低延时,低资源利用的情况下,召回相关的documents。排序层就是通过很复杂的算法(网络结构)把和query最相关的document排序到前面。论文的题目,简单直白的告诉了大家,用embeding 表示query和document来做召回。
论文提到,召回的难点,主要体现在候选集合非常庞大,处理亿级别的documents都是正常操作。不同于面部识别召回,搜索引擎的召回需要合并字面召回和向量召回两种结果。"脸书"的召回,还有其他难点,"人"的特征,在"脸书"的搜索尤其重要。
先膜拜下"脸书"的召回系统:
推荐阅读
相关标签

