
- 1python在web可以开发吗_怎么用python进行web开发
- 2git基本使用方法整理_git用法
- 3Keras-5-深度学习用于文本和序列-处理文本数据_keras 预训练网络一维序列分类
- 4MD5加密工具类
- 5二叉树的前中后序遍历_前序遍历 中序遍历 后序遍历
- 6opencv案例实战之工业印刷品数字识别_opencv工业应用实例
- 7snap7_snap7 server
- 8【Pytorch】论文复现 Vision Transformer (ViT)_vit目标跟踪复现
- 9c++ 带超时的线程安全队列 ThreadSafeQueue
- 10【uniapp】uni.switchTab跳转不支持传参,getApp().globalData代替传参_uniapp switchtab
昇思MindSpore 25天学习打卡营|day1
赞
踩
01.基本介绍
昇思MindSpore
昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景统一部署三大目标。
易开发:API友好、调试难度低。
高效执行:计算效率、数据预处理效率和分布式训练效率。
全场景:框架同时支持云、边缘以及端侧场景。
昇思MindSpore总体框架图:
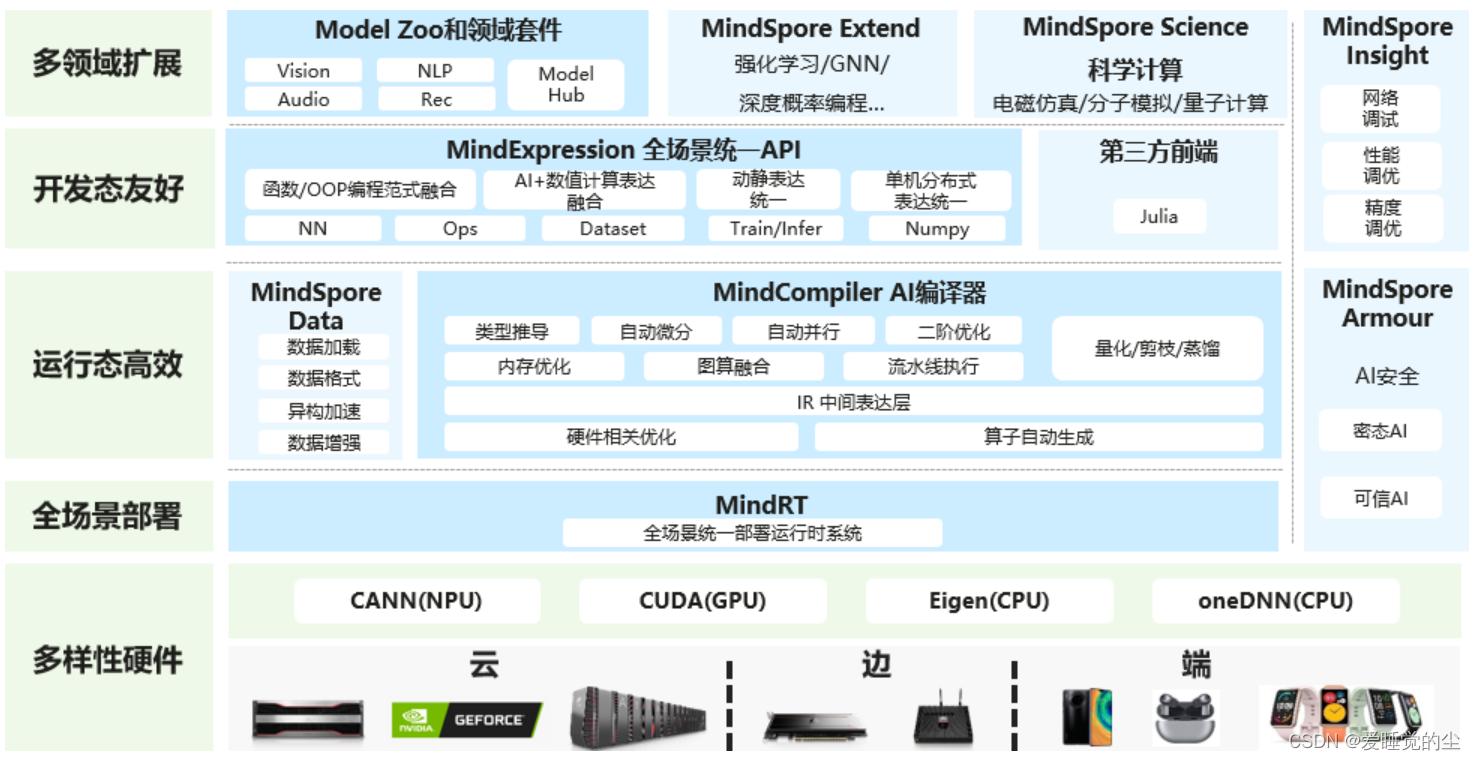
执行流程:
展示各个模块之间整体配合。
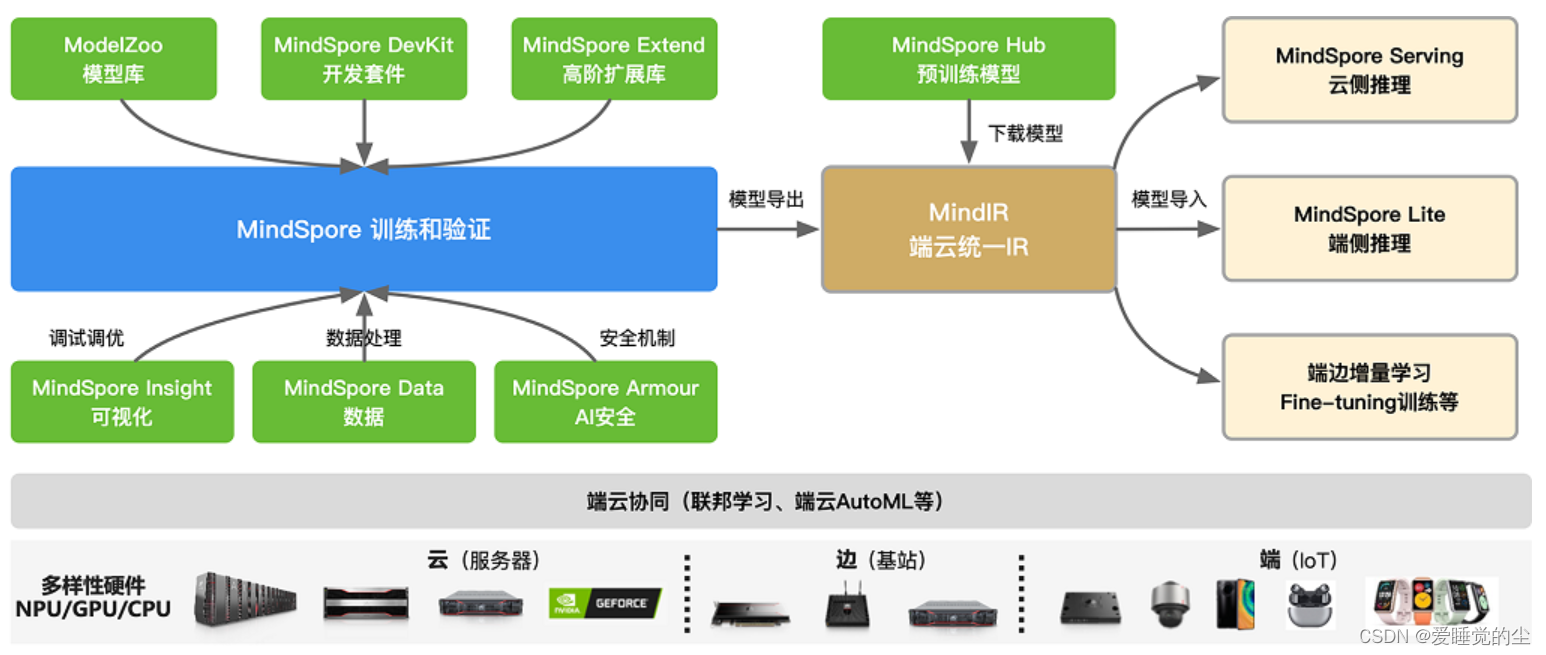
层次结构:
昇思MindSpore向用户提供了3个不同层次的API,支撑用户进行AI应用(算法/模型)开发,从高到低分别为High-Level Python API、Medium-Level Python API以及Low-Level Python API。高阶API提供了更好的封装性,低阶API提供更好的灵活性,中阶API兼顾灵活及封装,满足不同领域和层次的开发者需求。
02.快速入门
通过MindSpore的API来快速实现一个简单的深度学习模型。
处理数据集
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。
在教程中,使用Mnist数据集来训练。使用 mindspore.dataset 提供的数据变换进行预处理
网络构建
mindspore.nn类是构建所有网络的基类,也是网络的基本单元。当用户需要自定义网络时,可以继承 nn.Cell 类,并重写 __init__ 方法和 construct 方法。 __init__ 包含所有网络层的定义,construct 中包含数据(Tensor)的变换过程。
- # Define model
- class Network(nn.Cell):
- def __init__(self):
- super().__init__()
- self.flatten = nn.Flatten()
- self.dense_relu_sequential = nn.SequentialCell(
- nn.Dense(28*28, 512),
- nn.ReLU(),
- nn.Dense(512, 512),
- nn.ReLU(),
- nn.Dense(512, 10)
- )
-
- def construct(self, x):
- x = self.flatten(x)
- logits = self.dense_relu_sequential(x)
- return logits
-
- model = Network()
- print(model)

模型训练与测试
- # Instantiate loss function and optimizer
- loss_fn = nn.CrossEntropyLoss()
- optimizer = nn.SGD(model.trainable_params(), 1e-2)
-
- # 1. Define forward function
- def forward_fn(data, label):
- logits = model(data)
- loss = loss_fn(logits, label)
- return loss, logits
-
- # 2. Get gradient function
- grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
-
- # 3. Define function of one-step training
- def train_step(data, label):
- (loss, _), grads = grad_fn(data, label)
- optimizer(grads)
- return loss
-
- def train(model, dataset):
- size = dataset.get_dataset_size()
- model.set_train()
- for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
- loss = train_step(data, label)
-
- if batch % 100 == 0:
- loss, current = loss.asnumpy(), batch
- print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
- def test(model, dataset, loss_fn):
- num_batches = dataset.get_dataset_size()
- model.set_train(False)
- total, test_loss, correct = 0, 0, 0
- for data, label in dataset.create_tuple_iterator():
- pred = model(data)
- total += len(data)
- test_loss += loss_fn(pred, label).asnumpy()
- correct += (pred.argmax(1) == label).asnumpy().sum()
- test_loss /= num_batches
- correct /= total
- print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
-
- epochs = 3
- for t in range(epochs):
- print(f"Epoch {t+1}\n-------------------------------")
- train(model, train_dataset)
- test(model, test_dataset, loss_fn)
- print("Done!")
训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。打印每一轮的loss值和预测准确率(Accuracy),可以看到loss在不断下降,Accuracy在不断提高。
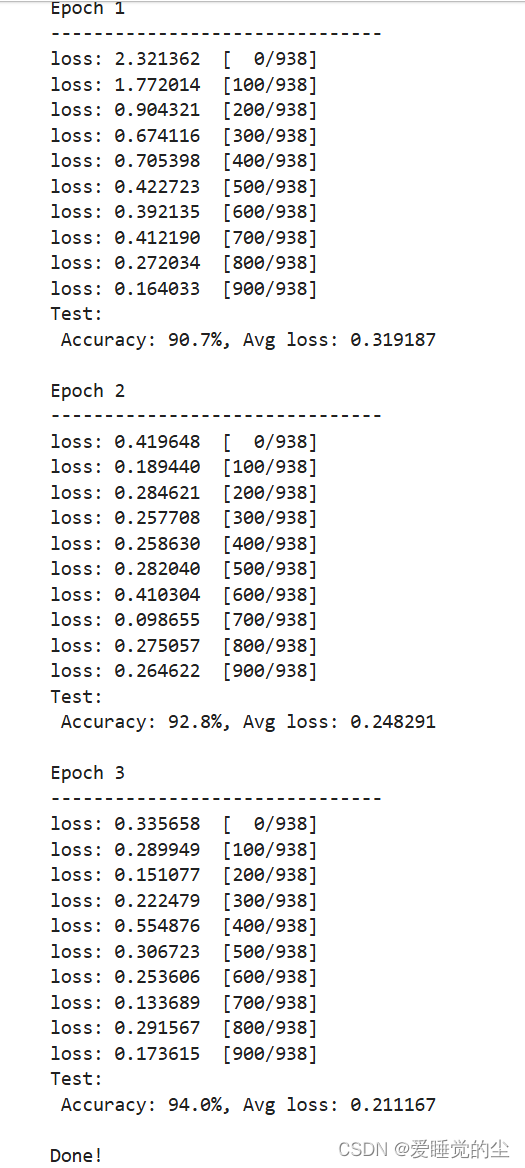
训练结果及完成时间:
学习心得:这是我第一次接触Mindspore,与pytorch不同的是Mindspore旨在提供易开发、高效执行和全场景覆盖,注重开发效率和执行性能,在性能优化方面有优势。而MindSpore 提供了特定的工具,可以将 PyTorch 模型转换为 MindSpore 模型,以利用其特定硬件优化。通过训练一个简单的Mindspore模型,了解了一些训练步骤和机制。对于Mindspore有更深的兴趣。


