
热门标签
热门文章
- 1Elasticsearch学习(四)Elasticsearch基础数据介绍_elasticsearch 数据情况
- 2收藏这篇Midjourney使用方法,你也能轻松定义视觉风格
- 3K8S篇之实现利用Prometheus监控pod的实时数据指标_kube-state-metrics prometheus
- 4Linux安装MySQL与DBeaver的远程连接_dbeaver linux
- 5leetcode的高频SQL50题基础版(答案和要点)_sql高级查询50道题
- 6AI 入门指南五 :提示词编写技巧(上)_ai 提示词工程 教程
- 7第四章、网络层_层次化路由
- 8cv::Mat一些基本初始化_cv::mat 初始化
- 9python获取android手机信息_python shell获取安卓id
- 10机器学习笔记-第二章模型评估与选择2_二项检验 机器学习
当前位置: article > 正文
BERT文本分类——基于美团外卖评论数据集_外卖评价数据
作者:我家小花儿 | 2024-07-18 19:14:36
赞
踩
外卖评价数据
一.BERT模型介绍
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以能生成深度的双向语言表征。BERT论文发表时提及在11个NLP(Natural Language Processing,自然语言处理)任务中获得了新的state-of-the-art的结果。下面我们看看整个的BERT模型是什么样的,结构如下图所示。
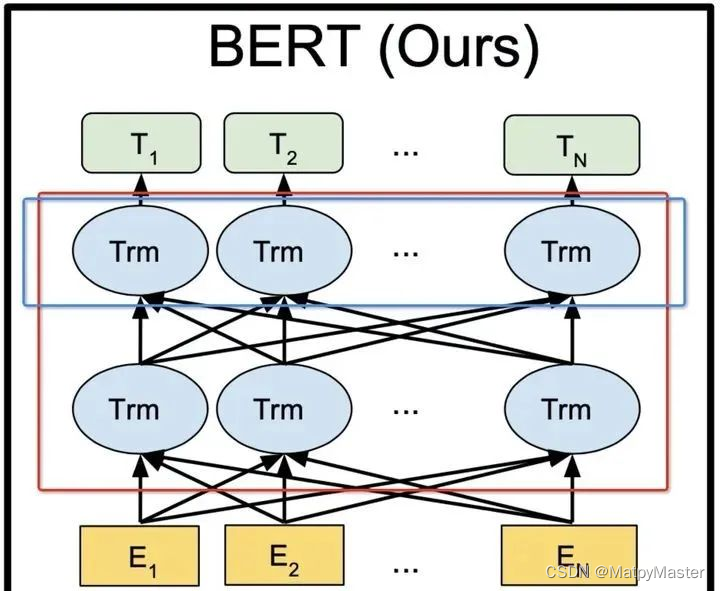
二.代码实现
1.下载预训练模型
BERT-Chinese:
https://huggingface.co/bert-base-chinese
美团外卖的用户评论数据集:
https://huggingface.co/datasets/XiangPan/waimai_10k/blob/main/waimai_10k.csv
2. 训练代码
- import pandas as pd
- import torch
- from torch.utils.data import DataLoader
- import datasets
- from transformers import AutoTokenizer
- from transformers import AutoModelForSequenceClassification
- from torchkeras import KerasModel
- import evaluate
-
- df = pd.read_csv("waimai_10k.csv")
- ds = datasets.Dataset.from_pandas(df)
- ds = ds.shuffle(42) #打乱顺序
- ds = ds.rename_columns({"review":"text","label":"labels"})
-
- tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese') #需要和模型一致
- if __name__ == '__main__':
- ds_encoded = ds.map(lambda example:tokenizer(example["text"],
- max_length=50,truncation=True,padding='max_length'),
- batched=True,
- batch_size=20,
- num_proc=2) #支持批处理和多进程map
- # 转换成pytorch中的tensor
- ds_encoded.set_format(type="torch", columns=["input_ids", 'attention_mask', 'token_type_ids', 'labels'])
- # 分割成训练集和测试集
- ds_train_val, ds_test = ds_encoded.train_test_split(test_size=0.2).values()
- ds_train, ds_val = ds_train_val.train_test_split(test_size=0.2).values()
- # 在collate_fn中可以做动态批处理(dynamic batching)
- def collate_fn(examples):
- return tokenizer.pad(examples)
- dl_train = torch.utils.data.DataLoader(ds_train, batch_size=16, collate_fn=collate_fn)
- dl_val = torch.utils.data.DataLoader(ds_val, batch_size=16, collate_fn=collate_fn)
- dl_test = torch.utils.data.DataLoader(ds_test, batch_size=16, collate_fn=collate_fn)
- for batch in dl_train:
- break
- # 加载模型 (会添加针对特定任务类型的Head)
- model = AutoModelForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=2)
- dict(model.named_children()).keys()
- output = model(**batch)
- class StepRunner:
- def __init__(self, net, loss_fn, accelerator, stage="train", metrics_dict=None,
- optimizer=None, lr_scheduler=None
- ):
- self.net, self.loss_fn, self.metrics_dict, self.stage = net, loss_fn, metrics_dict, stage
- self.optimizer, self.lr_scheduler = optimizer, lr_scheduler
- self.accelerator = accelerator
- if self.stage == 'train':
- self.net.train()
- else:
- self.net.eval()
- def __call__(self, batch):
- out = self.net(**batch)
- # loss
- loss = out.loss
- # preds
- preds = (out.logits).argmax(axis=1)
- # backward()
- if self.optimizer is not None and self.stage == "train":
- self.accelerator.backward(loss)
- self.optimizer.step()
- if self.lr_scheduler is not None:
- self.lr_scheduler.step()
- self.optimizer.zero_grad()
- all_loss = self.accelerator.gather(loss).sum()
- labels = batch['labels']
- acc = (preds == labels).sum() / ((labels > -1).sum())
- all_acc = self.accelerator.gather(acc).mean()
- # losses
- step_losses = {self.stage + "_loss": all_loss.item(), self.stage + '_acc': all_acc.item()}
- # metrics
- step_metrics = {}
- if self.stage == "train":
- if self.optimizer is not None:
- step_metrics['lr'] = self.optimizer.state_dict()['param_groups'][0]['lr']
- else:
- step_metrics['lr'] = 0.0
- return step_losses, step_metrics
- KerasModel.StepRunner = StepRunner
- optimizer = torch.optim.AdamW(model.parameters(), lr=3e-5)
- keras_model = KerasModel(model,
- loss_fn=None,
- optimizer=optimizer
- )
-
- keras_model.fit(
- train_data=dl_train,
- val_data=dl_val,
- ckpt_path='bert_waimai.pt',
- epochs=100,
- patience=10,
- monitor="val_acc",
- mode="max",
- plot=True,
- wandb=False,
- quiet=True
- )
- model.eval()
- model.config.id2label = {0: "差评", 1: "好评"}
- model.save_pretrained("waimai_10k_bert")
- tokenizer.save_pretrained("waimai_10k_bert")

3. 训练展示
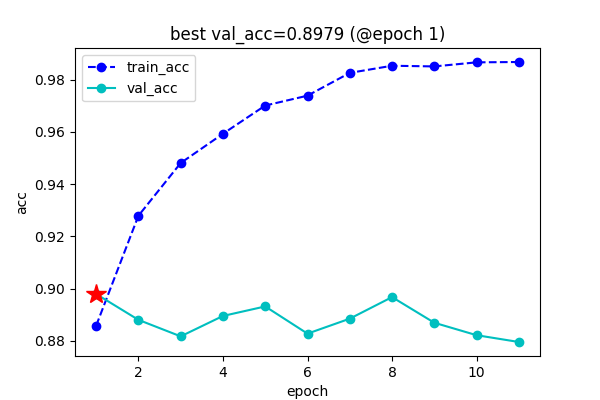
4. 测试代码
- from transformers import pipeline
- classifier = pipeline("text-classification", model="waimai_10k_bert")
- while True:
- text = input("请输入一句话(或输入q退出):")
- if text == "q":
- break
- result = classifier(text)
- print(result)

最后:
训练曲线和测试结果,并且得到了训练权重,喜欢的小伙伴可关注公众号回复“BERT美团”获取源代码和训练好的权重文件。会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/847265
推荐阅读
相关标签

