
- 1利用FreeNas创建iSCSI块级存储_freenas iscsi
- 2PythonWEB框架之Tornado
- 3【问题】vcenter7升级遇到“Exception in invoking authentication handler unidentifiable C++ exception”
- 4QT学习:QTcpServer多线程实现_qt tcp多线程
- 5MySQL主从同步
- 6代码随想录训练营day6|哈希表part01
- 7文心一格聚焦AIGC创作与商业化,打造内容生产创新引擎
- 8小程序海报生成海报【vue】
- 9python运行非常慢的解决-提升Python程序运行效率的6个方法
- 10Linux执行脚本的方法_linux执行脚本命令
2023年开源中文医疗大模型概览_关于医疗方面的开源大模型和产品有哪些
赞
踩
序言
自基于GPT-3.5的ChatGPT版本2022年年底震撼问世以来,如何利用通用大模型的优势,结合各垂直行业与领域专业知识积累及业务流程规范,打造领域大模型,从而有效支撑各领域日常问答、专业咨询乃至解决方案建议,无疑成为大模型应用落地探索的一大方向和趋势。
在医疗领域,国外以Google为代表持续在医疗大模型方面探索发力,由谷歌Research和DeepMind共同打造的多模态生成模型Med-PaLM M于2023年月发布,该模型懂临床语言、懂影像,也懂基因组学,在美国执业医师资格考试(USMLE)中通过率高达85.4%,从技能上已经达到专业医生的水平,令人振奋。
而国内各研发机构、医疗机构及LLM Geeker也不甘落后,以极大的精力与热情,从2023年起,结合中文环境下的、医疗问诊、中药特色以及日趋更为关键的心理学领域进行了大量的尝试,并且总体体现了开放共享,共襄盛世的百花齐放的格局,无论从大模型基座的选择、大模型微调技术、专业领域数据集构建方法、开放专业训练数据集、微调训练推理经济成本考量、中文医疗大模型评价标准和医疗健康在心理健康领域的衍生,都呈现了各自的特色,可谓精彩纷呈。
值得高兴的是,部分开源医疗大模型项目团队作者,不局限于初步成果,持续探索更新,无论在基座灵活支持、中文医疗数据集、微调训练方法及效果评价不断开放提升方面,都继续发力,如DoctorGLM, MedicalGPT、ChatMed及MedQA等项目,尤其是MedQA项目,在复现过程及后续不断推出的更具开放性先进性的IvyGPT-CareLlma等,无疑都展现了该领域研发探索先锋的Geek/Guru风范。
本文根据现有近20个中文医疗领域开源大模型网络众神们的总结分析,结合作者探索行业发展浅见,编制形成本文,意图对发展中的中文医疗大模型提供多方面概览,呈现采撷各自精彩与独特之处,共同推进LLM应用探索与实践,在组织结构及内上也引用了不少附录中(中文综述)专家的成果,在此一并致谢,其中有不尽之处,也敬请海涵指正。
如同各开源模型指出的,这些大模型都是在研发探索阶段,包括AI Ethics的隐忧等,尚不足以成熟到作实际医用诊疗; 但如果这些开放性研发探索,能够从某种程度上,通过中文医疗卫生大模型及其生态应用,加强中文-中药医卫乃至心理咨询方面的大众的专业认知与素养,让具有庞大人口基数的中华14亿大众,身边多个垂手可得的专家,让华佗扁鹊医者仁心的AI Ethics与技艺能够继续洋溢人间,都不啻为一种有益的尝试。
突然脑路清奇想到,按照开源精神及一带一路倡议精神,发端于英文体系,推陈出新意有所为的中文医卫大模型,后续也可能为人口众多但不发达且语种独特的异域特色医卫AI辅助 :-)
开源中文医疗大模型信息一览表
| 模型名称 | 模型基座 | 论文-源码链接 | 开放情况 | 贡献单位 | 初始发布日期 | Github Stars (20230822-20230830统计) |
| MING (原MedicalGPT-zh) | bloomz-7B 指令微调 | 无公开论文/技术报告 源码地址: |
| 上海交通大学未来媒体网络协同创新中心和上海人工智能实验室智慧医疗中心 | 2023/07 | 392 |
| DoctorGLM | ChatGLM-6B Lora微调 | 论文及源码 |
| 上海交大 | 2023/06 | 574 |
| 本草BenTaso(原名HuaTuo华驼) | Lalalma Alpaca Bloom 活字 LoRA微调 | 论文及源码: https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese https://arxiv.org/pdf/2304.06975.pdf 相关解读: |
| 哈尔滨工业大学社会计算与信息检索研究中心健康智能组 | 2023年3月创建,5月份更名为本草 | 3.6K |
| Med-ChatGLM (与BenTsao同源) | ChatGLM-6B 指令微调 | 源码地址: | 与本草类似 但公开了训练微调脚本 | 同上 | 2023年3月发布 | 749 |
| HuaTuoGPT(华佗GPT) | 百川7B Ziya-LaMA-13B-Pretrain-v1 SFT微调 | 论文及源码: |
试用地址: | 深圳大数据研究院 香港中文大学 | 2023年4月发布 持续更新中 | 605 |
| MedicalGPT | bloom llama/llama2 chatglm/chatglm2-6B baichuan 7B, 13B 按照ChatGPT training pipeline训练微调(二次预训练、有监督微调、奖励建模、强化学习训练。) | 无技术报告,但github说明较详细 |
| 个人 | 2023年6月发布 持续更新中 | 1.3k |
| ChatMed | LlaMA-7b Lora微调 | https://github.com/michael-wzhu/ChatMed 项目公开了训练数据及训练过程,并没有其它相关的技术报告 |
| 华东师范大学计算机科学与技术学院智能知识管理与服务团队 | 2023/5/05 开源ChatMed-Consult模型 | 198 |
| ShenNong-TCM-LLM - 神农中医药大模型 | LlaMA-7b LoRA微调 | 与ChatMed类似 该团队联合阿里、复旦大学附属华山医院、东北大学、哈工大及同济大学另外推出了两个大模型评价标准:
https://github.com/michael-wzhu/PromptCBLUE
意图建立一个标准化、综合性的中医评测框架 https://github.com/ywjawmw/ShenNong-TCM-Evaluation-BenchMark | 与ChatMed同源 | 2023年6月发布 | 57 | |
| MedQA-ChatGLM | ChatGLM LoRA、P-Tuning V2、Freeze、RLHF等微调 | 技术报告: https://www.wangrs.co/MedQA-ChatGLM/# 源码: |
| 澳门理工大学 | 2023年5月发布 | 232 |
| XrayGLM -首个会看胸部X光片的中文多模态医学大模型 | 借助ChatGPT以及公开的数据集,构造了一个X光影像-诊断报告对的医学多模态数据集 VisualGLM-6B 微调 | 无技术报告,github库中有关键步骤解释描述。 源码: |
| 同上 | 2023年5月发布 | 558 |
| BianQue扁鹊 - 中文医疗对话大模型 | 扁鹊1.0采用的模型基座: 扁鹊2.0采用的模型基座: ChatGLM-6B 全量参数的指令微调 | 无相关论文发布 源码地址: https://github.com/scutcyr/BianQue |
| 华南理工大学未来技术学院 广东省数字孪生人重点实验室 合作单位包括广东省妇幼保健院、广州市妇女儿童医疗中心和中山大学附属第三医院等。 | 2023年4月发布 | 240 |
| SoulChat灵心健康大模型 | ChatGLM-6B 全量参数的指令微调 | 无相关技术报告,虽然作者预期会后续发布 项目源码https://github.com/scutcyr/SoulChatscutcyr/SoulChat · Hugging Face 项目同时给出了内测网址灵心 |
| 同上 | 2023年4月发布 | 139 |
| 孙思邈中文医疗大模型(Sunsimiao) | baichuan-7B ChatGLM-7B 微调(参照LLaMA-Efficient-Tuning:) | 尚无论文发布 公开源码见: |
| 华东理工大学信息科学与工程学院 | 2023年6月发布 | 32 |
| Mindchat漫谈中文心理大模型 | baichuan-13B Qwen-7B InternLM-7B 微调
| 项目尚未发布相关论文。 公开源码部分见:https://github.com/X-D-Lab/MindChat MindChat体验地址: MindChat-创空间 |
| 同上 | 2023年6月发布 | 82 |
| QiZhenGPT启真医学大模型 | Chinese-LLaMA-Plus-7BCaMA-13BChatGLM-6B 指令微调 | 项目尚未发布论文 公开源码地址: |
| 浙江大学、网新数字健康联合研究中心 | 2023年5月 | 424 |
| PULSE中文医疗大模型 | QLoRa微调 | 无相关论文 相关代码及模型:https://github.com/openmedlab/PULSEOpenMEDLab/PULSE-7bv5 · Hugging Face 关联开源生态应用: |
| 上海人工智能实验室、上海交通大学-清源研究院、华东理工大学-自然语言处理与大数据挖掘实验室 | 2023年6月 | 313 |
| CareLlama关怀羊驼中文医疗大模型 (TBD) | TBD | CareLlama在线体验版:https://huggingface.co/spaces/wangrongsheng/CareLlama 其它待作者再次开放后补充 |
| 澳门理工大学 | 2023年8月 (后又宣布闭源1个月,估计9月份再次开放) | TBD |
1)MedicalGPT-zh - 一个基于ChatGLM的在高质量指令数据集微调的中文医疗对话语言模型 (2023年7月更名为MING)
项目简介
项目最初开源了基于ChatGLM-6B LoRA 16-bit指令微调的中文医疗通用模型。基于共计28科室的中文医疗共识与临床指南文本,从而生成医疗知识覆盖面更全,回答内容更加精准的高质量指令数据集。以此提高模型在医疗领域的知识与对话能力。
项目由上海交通大学未来媒体网络协同创新中心和上海人工智能实验室智慧医疗中心合作研发。
2023年7月MedicalGPT-zh更名为MING,相关基础模型及微调训练数据等等做了全新的更新。
论文及开源地址
开源地址原为:
https://github.com/MediaBrain-SJTU/MedicalGPT-zh
会自动重定位到
https://github.com/MediaBrain-SJTU/MING
数据集构建
本项目数据主要分为两个部分:情景对话与知识问答
| 数据类型 | 描述 | 数量 | 占比(%) |
| 情景对话 | 在具体场景下的医患诊疗对话 | 52k | 28.57 |
| 知识问答 | 医学知识问题的解释性回答 | 130k | 71.43 |
| 总计 | - | 182k | 100 |
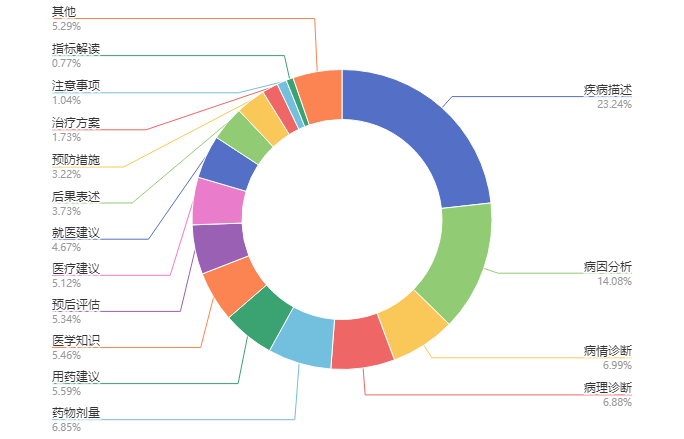
情景对话:主要参考BELLE的指令数据集生成方式,将医学指令按照诊疗情景的不同主要分为16种大类,通过100条情景对话种子任务生成的52k条情景对话数据。 提供了情景对话种子任务及生成情景对话数据的程序,最终生成的52k情景对话数据医学指令类型及其分布如图所示。
其中提到的BELLE, Be Everyone's Large Language model Engine(开源中文对话大模型),地址为:
https://github.com/LianjiaTech/BELLE
https://github.com/LianjiaTech/BELLE/blob/main/docs/Towards%20Better%20Instruction%20Following%20Language%20Models%20for%20Chinese.pdf、https://github.com/LianjiaTech/BELLE/blob/main/docs/A%20Comparative%20Study%20between%20Full-Parameter%20and%20LoRA-based.pdf
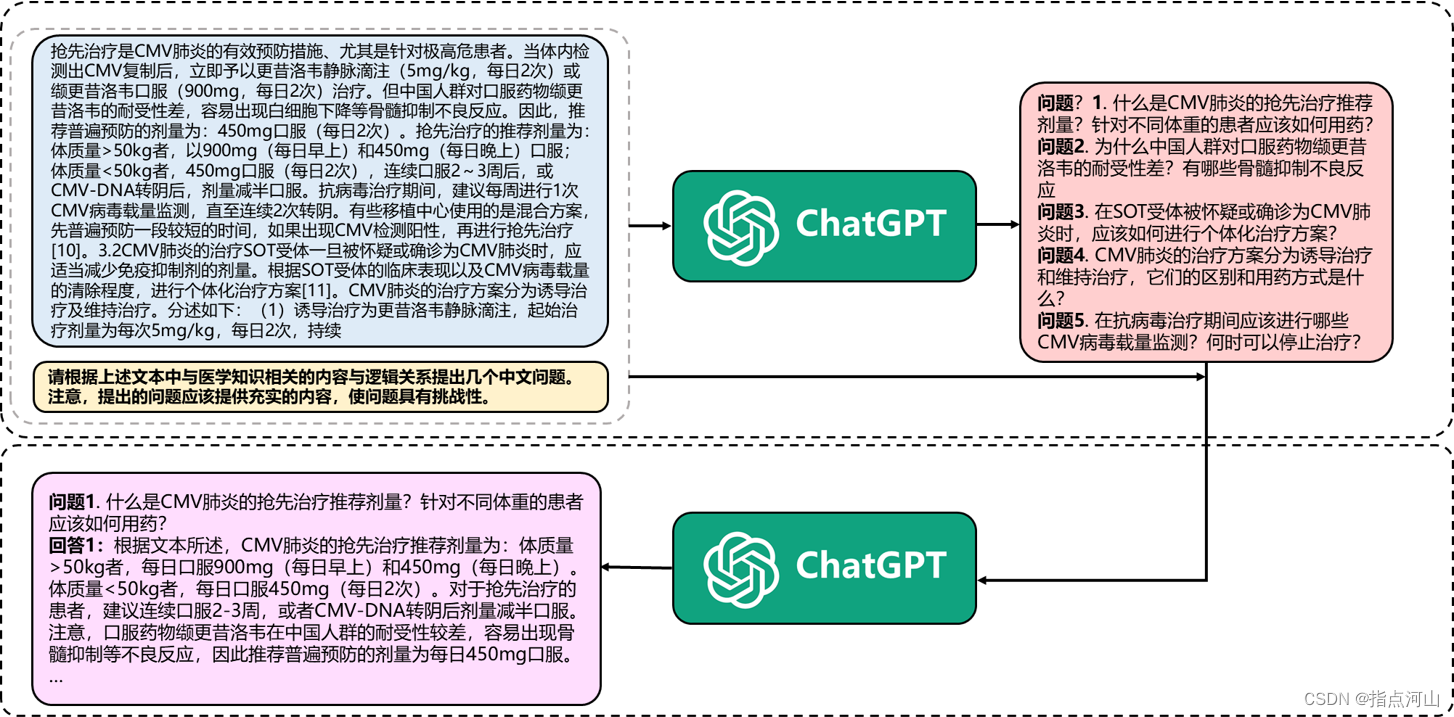
知识问答:医学知识来源于自建的医学数据库。通过提供具体的医疗共识与临床指南文本,先让ChatGPT生成与该段医学知识内容与逻辑关系相关的若干问题,再通过“文本段-问题”对的方式让ChatGPT回答问题,从而使ChatGPT能够生成含有医学指南信息的回答,保证回答的准确性。知识问答与医疗指南、依据医疗指南生成的知识问答样例都有提供, 并提供了知识问答数据生成的程序。其中,医疗共识与临床指南中文本段涵盖28个科室共计32k个文本段。 各科室及其分布如图所示。

模型输出样例

模型训练
项目训练代码采用模型并行算法,可以在最少4张3090显卡上完成对ChatGLM LoRA 16-bit的指令微调。
开放程度
项目初始发布时,github上给出了数据集的构建程序、模型训练程序及运行命令行代码,可直接运行。 2023年7月份,相关的程序库都已消失,变成了如下的更为概略的MING模型。
保留该模型的目的,仅仅是从其原有开放资料中,了解借鉴相关的技巧方法,。
2)明医 (MING)——中文医疗问诊大模型
项目简介
这是MediaCPT-zh的最新替代版(2023年7月25日)。 该问诊大模型提供了两种功能:
- 医疗问答:对医疗问题进行解答,对案例进行分析。
- 智能问诊:多轮问诊后给出诊断结果和建议。

论文及源码
项目仅给出了部分代码库,如下:
https://github.com/MediaBrain-SJTU/MING
并没有论文或者技术报告支撑。
数据集构建
数据集主要由四个部分构成:
| 数据类型 | 数据构成 | 数量 | 占比(%) |
| 医疗知识问答 | 基于临床指南和医疗共识的知识问答 | 168k | 48.88 |
| 基于医师资格考试题的知识问答 | 77k | ||
| 真实医患问答 | 140k | ||
| 基于结构化医疗图谱的知识问答 | 160k | ||
| 多轮情景诊断与案例分析 | 基于HealthCareMagic构造的多轮情景问答与诊断 | 200k | 21.52 |
| 基于USMLE案例分析题的格式化多轮问诊 | 20k | ||
| 多轮病人信息推理与诊断 | 20k | ||
| 任务指令 | 医疗指令 | 150k | 26.91 |
| 通用指令 | 150k | ||
| 安全性数据 | 敏感性问题 | 15k | 2.69 |
| 医疗反事实 | 15k | ||
| 总计 | - | 1.12M | 100.00 |
git库中并没有相关的数据源说明。
样本生成方式
与MedicalGPT相比,MING的说明中并没有详细的微调训练样本的说明, 给出的代码是采用FastChat平台进行的。
模型训练
该模型采用的是基于bloomz-7B的指令微调,最后生成MING-7B。
| 模型 | 基座 | HuggingFace |
| MING-7B | Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。
|

