
- 1xuniren(Fay数字人开源社区项目)NeRF模型训练教程_fay数字人搭建流程
- 2边缘计算盒子与云计算:谁更适合您的业务需求?
- 3这些年来,编程领域有什么重要进展?回顾过去,展望未来
- 4使用FileStream来读取数据_iformfile 读取文件内容
- 5抛弃torch.cat,拥抱AFF_aff注意力
- 6CUDA各版本官方下载地址_cuda12.0下载网址
- 7大模型和向量数据库怎么搭建 RAG 系统?Step by step 例子来了。
- 8spacy包及trained pipelines安装教程_spacy python包
- 9NeurIPS2023 大语言模型(LLM)方向优质论文汇总!_llm模型相关论文
- 102021-07/08收集字节跳动---Java提前批面试题_字节提前批面试 算法
Transformer课程 业务对话机器人Rasa 3.x 生成自然语言理解NLU数据_rasa3 out_of_scope
赞
踩
Transformer课程 业务对话机器人Rasa 3.x Generating NLU Data
Rasa 官网

Generating NLU Data
NLU(自然语言理解)是Rasa开源的一部分,它执行意图分类、实体提取和响应检索。NLU将接受一句话,如“I am looking for a French restaurant in the center of town”,并返回结构化数据,如:
{
"intent": "search_restaurant",
"entities": {
"cuisine": "French",
"location": "center"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
构建NLU模型非常困难,而构建可用于生产的模型则更加困难。下面是一些设计你的NLU训练数据和管道的技巧,让你的机器人发挥最大的作用。
Conversation-Driven Development for NLU
对话驱动开发意味着让实际的用户对话指导您的开发,对于构建伟大的NLU模型,这意味着两件关键的事情:
Gather Real Data
在构建NLU训练数据时,开发人员有时会倾向于使用文本生成工具或模板来快速增加训练示例的数量。这是个坏主意,原因有二:
-
首先,您的合成数据看起来不会像用户实际发送给您的助理的消息,因此您的模型将表现不佳。
-
其次,通过对合成数据进行训练和测试,您会欺骗自己认为您的模型实际上运行得很好,并且不会注意到主要问题。
请记住,如果您使用脚本生成训练数据,那么您的模型唯一可以学习的事情就是如何对脚本进行反向工程。
为了避免这些问题,收集尽可能多的实际用户数据作为训练数据总是一个好主意。真正的用户信息可能会很混乱,包含拼写错误,与你的意图相差甚远。但请记住,这些信息是你要求模型做出预测的!您的助理一开始总是会犯错误,但是对用户数据的训练和评估过程将使您的模型在现实场景中更有效地推广。
Share with Test Users Early
为了收集实际的数据,您需要实际的用户消息。机器人开发人员只能提供有限的示例,用户所说的话总是会让你大吃一惊。这意味着您应该尽早与开发团队之外的测试用户共享您的bot。有关更多详细信息,请参阅完整的对话驱动开发指南。
Avoiding Intent Confusion
意图使用从训练示例中提取的字符和单词级特征进行分类,这取决于您添加到NLU管道中的特征化器。当不同的意图包含以类似方式排序的相同单词时,这可能会造成意图分类器的混淆。
Splitting on Entities vs Intents
当您希望助理的回答取决于用户提供的信息时,往往会出现意图混淆。例如,“How do I migrate to Rasa from IBM Watson?”而不是“I want to migrate from Dialogflow.”
由于这些消息中的每一条都会导致不同的响应,因此您的初始方法可能是为每种迁移类型创建单独的意图,例如watson_migration和dialogflow_migration。然而,这些意图试图实现相同的目标(迁移到Rasa),并且可能会使用类似的措辞,这可能会导致模型混淆这些意图。
为了避免意图混淆,将这些训练示例分组为单个迁移意图,并使响应取决于来自实体的分类产品槽的值。这也使得在没有提供实体的情况下很容易处理,例如“How do I migrate to Rasa?”例如:
stories: - story: migrate from IBM Watson steps: - intent: migration entities: - product - slot_was_set: - product: Watson - action: utter_watson_migration - story: migrate from Dialogflow steps: - intent: migration entities: - product - slot_was_set: - product: Dialogflow - action: utter_dialogflow_migration - story: migrate from unspecified steps: - intent: migration - action: utter_ask_migration_product

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
Improving Entity Recognition
使用Rasa Open Source,您可以定义自定义实体,并在您的训练数据中对它们进行注释,以指导您的模型识别它们。Rasa Open Source还提供了提取预训练实体的组件,以及其他形式的训练数据,以帮助您的模型识别和处理实体。
Pre-trained Entity Extractors
名称、地址和城市等公共实体需要大量的训练数据才能有效地概括NLU模型。
Rasa开源为预训练的提取提供了两个很好的选择:SpacEntityExtractor和DucklingEntityExtractor。因为这些提取器已经在大量数据上进行了预训练,所以您可以使用它们来提取它们支持的实体,而无需在训练数据中对它们进行注释。
Regexes
正则表达式对于在结构化模式(如5位美国邮政编码)上执行实体提取非常有用。正则表达式模式可用于生成NLU模型要学习的特征,或作为直接实体匹配的方法。有关详细信息,请参见正则表达式功能。
Lookup Tables
查询表作为regex模式处理,检查训练示例中是否存在任何查询表项。与regex类似,查询表可用于向模型提供特征以提高实体识别,或用于执行基于匹配的实体识别。查找表的有用应用包括冰淇淋的口味、瓶装水的品牌,甚至袜子长度的样式(参见查找表)
Synonyms
在训练数据中添加同义词对于将某些实体值映射到单个规范化实体非常有用。然而,同义词并不是为了提高模型的实体识别,并且对NLU的性能没有影响。
同义词的一个很好的用例是规范化属于不同组的实体。例如,在一个询问用户感兴趣的保险政策的助理中,用户可能会回答 “my truck,” "a car,"或者 “I drive a batmobile.”。将 truck, car,和 batmobile映射到规范化值auto是一个好主意,这样处理逻辑将只需要考虑一个狭窄的可能性集(参见同义词)。
Handling Edge Cases
Misspellings
遇到拼写错误是不可避免的,所以你的机器人需要一个有效的方法来处理这个问题。请记住,我们的目标不是纠正拼写错误,而是正确地识别意图和实体。出于这个原因,虽然拼写检查似乎是一个显而易见的解决方案,但调整特征和训练数据通常就足以解释拼写错误。
添加字符级特征器可以有效地防止拼写错误,因为它只考虑单词的一部分,而不是整个单词。你可以通过使用countvectorsfeatureizer的char_wb分析器将角色级别特征添加到管道中,例如:
pipeline:
# <other components>
- name: CountVectorsFeaturizer
analyze: char_wb
min_ngram: 1
max_ngram: 4
# <other components>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
除了字符级特征化之外,还可以将常见的拼写错误添加到训练数据中。
Defining an Out-of-scope Intent
在bot中定义一个out_of_scope意图总是一个好主意,以捕获bot域之外的任何用户消息。当一个out_of_scope意图被识别时,你可以用诸如“我不确定如何处理那个,这里有一些事情你可以问我……”这样的消息来优雅地引导用户获得支持的技能。
Shipping Updates
像对待代码一样对待数据。就像您永远不会在没有审查的情况下发布代码更新一样,应该仔细审查对您的训练数据的更新,因为它会对您的模型性能产生重大影响。
使用版本控制系统,如Github或Bitbucket来跟踪数据的更改,并在必要时回滚更新。
一定要为NLU模型构建测试,以便在训练数据和超参数变化时评估性能。在CI管道(如Jenkins或Git Workflow)中自动化这些测试,以简化开发过程,并确保只发布高质量的更新。
rasa 官网链接
https://rasa.com/docs/rasa/generating-nlu-data
课程名称: 业务对话机器人Rasa核心算法DIET及TED论文内幕详解

课程内容:
对一个智能业务对话系统而言,语言理解NLU及Policies是其系统内核的两大基石。Rasa团队发布的最重磅级的两篇论文DIET: Lightweight Language Understanding for Dialogue Systems及Dialogue Transformers是其基于在业界落地场景的多年探索而总结出来的解决NLU和Policies最核心的成果结晶: 其中DIET是Intent识别和Entity信息抽取的统一框架,而基于Dialogue Transformers的Transformer Embedding Dialogue (TED)是面向多轮业务对话信息处理和对话Response技术框架。DIET和TED作为Rasa内核已经经过很多版本的迭代优化,即使Rasa 3.x最新一代架构中依然可以看到DIET和TED的核心位置:
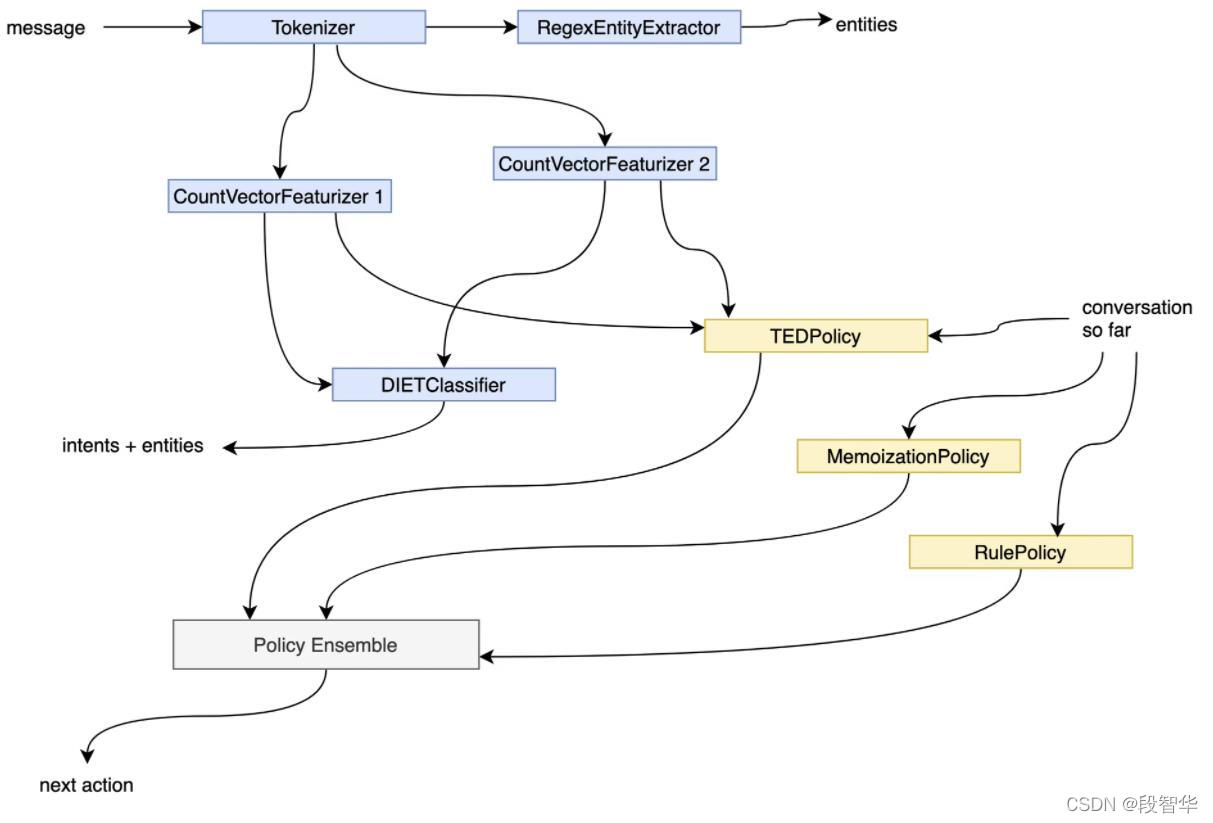
可以这么说,掌握这两篇论文是掌握Rasa精髓及背后设计机制的核心之所在。所以星空对话机器人推出了业务对话机器人Rasa核心算法DIET及TED论文内幕详解课程,以抽丝剥茧的方式来逐句解读这两篇论文中蕴含的一切架构思想、内幕机制、实验分析、及最佳实践等所有的密码,以帮助对基于Transformer的对话机器人感兴趣的朋友掌握Rasa内核精髓。
为了更有效的帮助学员达到从模型算法、架构设计、源码实现等角度融汇贯贯通当今工业级最成功的业务对话机器人平台Rasa,除了在课程中逐行解析Rasa的核心TED Policy近2130行源码及DIET近1825行源码外,课程中还增加了Rasa Internals解密之框架核心graph.py源码完整解析及测试中GraphNode源码逐行解析及Testing分析、GraphModelConfiguration、ExecutionContext、GraphNodeHook源码解析、GraphComponent源码回顾及其应用源码。

课程名称:业务对话机器人Rasa 3.x Internals内幕详解及Rasa框架定制实战

课程介绍:
以Rasa 3.x提出的全新一代Graph Computational Backend为核心,从Rasa版本迭代中的Milestones出发来完全解密“One Graph to Rule Them All”背后的技术衍化过程及根本原因,然后以GraphComponent为核心解密其架构内幕机制和运行流程,并抽丝剥茧的剖析自定义Rasa Open Source平台的接口实现、组件源码、组件注册及使用的每一个步骤,最后用一个完整的案例来做示例,并透过Rasa的核心TED Policy近2130行源码剖析及DIET近1825行源码剖析,让学习者不仅有定制Rasa框架能力,更有大量源码鉴赏的能力及高级的对话系统架构设计思维。
课程内容:
第1课:Rasa 3.x Internals解密之Retrieval Model剖析
1,什么是One Graph to Rule them All
2,为什么工业级对话机器人都是Stateful Computations?
3,Rasa引入Retrieval Model内幕解密及问题解析
第2课:Rasa 3.x Internals解密之去掉对话系统的Intent内幕剖析
1,从inform intent的角度解析为何要去掉intent
2,从Retrieval Intent的角度说明为何要去掉intent
3,从Multi intents的角度说明为何要去掉intent
4,为何有些intent是无法定义的?
第3课:Rasa 3.x Internals解密之去掉对话系统的End2End Learning内幕剖析
1,How end-to-end learning in Rasa works
2,Contextual NLU解析
3,Fully end-to-end assistants
第4课:Rasa 3.x Internals解密之全新一代可伸缩DAG图架构内幕
1,传统的NLU/Policies架构问题剖析
2,面向业务对话机器人的DAG图架构
3,DAGs with Caches解密
4,Example及Migration注意点
第5课:Rasa 3.x Internals解密之定制Graph NLU及Policies组件内幕
1,基于Rasa定制Graph Component的四大要求分析
2,Graph Components解析
3,Graph Components源代码示范
第6课:Rasa 3.x Internals解密之自定义GraphComponent内幕
1,从Python角度分析GraphComponent接口
2,自定义模型的create和load内幕详解
3,自定义模型的languages及Packages支持
第7课:Rasa 3.x Internals解密之自定义组件Persistence源码解析
1,自定义对话机器人组件代码示例分析
2,Rasa中Resource源码逐行解析
3,Rasa中ModelStorage、ModelMetadata等逐行解析
第8课:Rasa 3.x Internals解密之自定义组件Registering源码解析
1,采用Decorator进行Graph Component注册内幕源码分析
2,不同NLU和Policies组件Registering源码解析
3,手工实现类似于Rasa注册机制的Python Decorator全流程实现
第9课:基于Transformer的Rasa Internals解密之自定义组件及常见组件源码解析
1,自定义Dense Message Featurizer和Sparse Message Featurizer源码解析
2,Rasa的Tokenizer及WhitespaceTokenizer源码解析
3,CountVectorsFeaturizer及SpacyFeaturizer源码解析
第10课:基于Transformer的Rasa Internals解密之框架核心graph.py源码完整解析及测试
1,GraphNode源码逐行解析及Testing分析
2,GraphModelConfiguration、ExecutionContext、GraphNodeHook源码解析
3,GraphComponent源码回顾及其应用源码
第11课:基于Transformer的Rasa Internals解密之框架DIETClassifier及TED
1,作为GraphComponent的DIETClassifier和TED实现了All-in-one的Rasa架构
2,DIETClassifier内部工作机制解析及源码注解分析
3,TED内部工作机制解析及源码注解分析
第12课:Rasa 3.x Internals解密之TED Policy近2130行源码剖析
1,TEDPolicy父类Policy代码解析
2,TEDPolicy完整解析
3,继承自TransformerRasaModel的TED代码解析
第13课:Rasa 3.x Internals解密之DIET近1825行源码剖析
1,DIETClassifier代码解析
2,EntityExtractorMixin代码解析
3,DIET代码解析
课程名称:30小时解密10篇NLP领域最高质量的对话机器人经典论文及源码答疑课

课程介绍:基于Gavin做星空智能业务对话机器人过程中阅读的超过3000篇NLP论文中挑选出过去五年最经典、最高质量的10篇NLP对话机器人相关论文,涵盖多轮对话、状态管理、小数据技术等智能对话机器人领域所有关键技术及思想架构。所有内容都是抽丝剥茧、层层递进的方式展开,授课老师Gavin提供一年围绕10篇论文的技术答疑服务。
课程内容:
30小时的视频、10篇论文的Gavin批注版本、及直接和Gavin交流的一年技术答疑服务。课程具体包含以下论文:
Annotated ConveRT Efficient and Accurate Conversational Representations from Transformers
Annotated Dialogue Transformers
Annotated A Simple Language Model for Task-Oriented Dialogue
Annotated DIET Lightweight Language Understanding for Dialogue Systems
Annotated BERT-DST Scalable End-to-End Dialogue State Tracking with Bidirectional Encoder Representations from Transformer
Annotated Few-shot Learning for Multi-label Intent Detection
Annotated Fine-grained Post-training for Improving Retrieval-based Dialogue Systems
Annotated Poly-encoders architectures and pre-training Pro
Annotated TOD-BERT Pre-trained Natural Language Understanding for Task-Oriented Dialogue
Annotated Recipes for building an open-domain chatbot
同时,为了解决大家的基础问题,课程中附赠了“第1课:星空对话BERT Paper 论文解密、数学推导及完整源码实现 ”。
任何技术问题都会有Gavin老师亲自答疑。
课程名称:Bayesian Transformer:架构、算法、数学、源码、NLP比赛

课程介绍:
“一种架构、统治一切”是吴恩达(Andrew Ng)在2021年底回顾整个AI领域的最新进展中提对Transformer评价(https://read.deeplearning.ai/the-batch/issue-123/) . Transformer现在已经成为人工智能NLP等各大领域底层通用的引擎,尤其是2018以来学术界的各类AI研究及工业界的具体应用都是直接或者间接的基于Transformer。
本课程是星空对话机器人创始人Gavin对Transformer多年的研究和使用的智慧结晶,是全球NLP培训课程领域第一个从Bayesian的视角来解密Transformer从体系架构、模型算法、源码剖析、案例实战等方方面面的内容,尤其是通过打开Transformer中神经网络内部的“黑盒”来抽丝剥茧的讲解Transformer一般学习者和使用者不易理解的硬核技术及细微但对实践有重大意义的局部细节。 透过底层最宏大的数学原理Bayesian出发,Transformer的一切架构、逻辑、实践等都环环相扣、浑然天成。
本课程不仅有Transformer、GPT、BET的完整源码实现逐行剖析,更是通过实战的角度通过Transformer对影评数据的分析及Kaggle上NLP阅读理解比赛完整代码解密帮助大家完全驾驭Transformer。所有代码找授课老师Gavin获取。
课程提供1年的技术答疑服务,Gavin老师负责所有课程技术问题的答疑。
课程内容:
第1课 Bayesian Transformer思想及数学原理完整论证
第2课 Transformer论文源码完整实现
第3课 Transformer语言模型架构、数学原理及内幕机制
第4课 GPT自回归语言模型架构、数学原理及内幕机制
第5课 BERT自编码语言模型架构、数学原理及内幕机制
第6课 BERT预训练源码实现详解
第7课 BERT Fine-tuning数学原理及案例源码解析
第8课 BERT Fine-tuning命名实体识别NER原理解析及源码实战
第9课 BERT多任务深度优化及案例(数学原理、层次化网络内幕及高层CLS分类等)
第10课 使用BERT对影评数据分析(数据处理、模型代码、线上部署)
第11课 BERT Paper 论文解密、数学推导及完整源码实现
第12课 Transformer在Kaggle中NLP比赛的案例实战
课程风格示例:
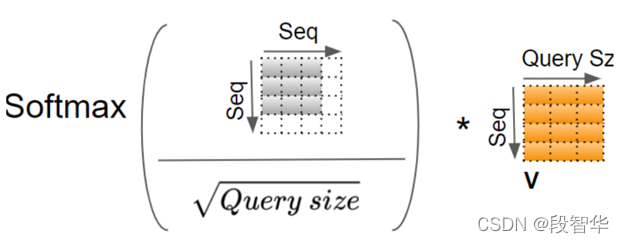
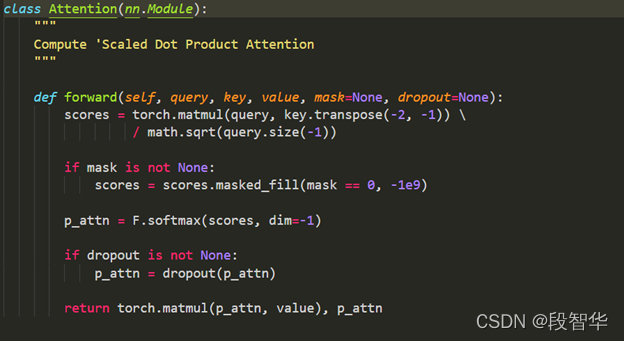
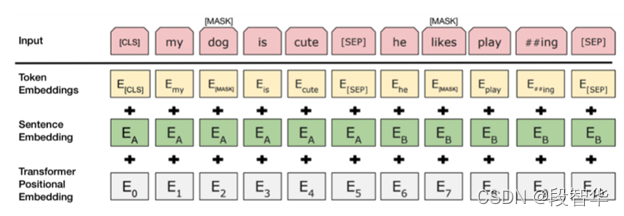
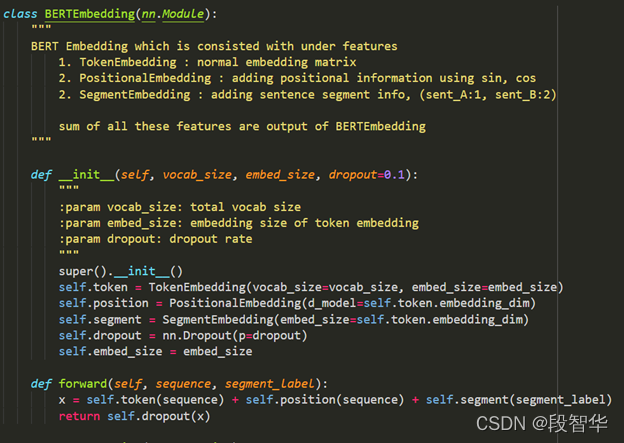
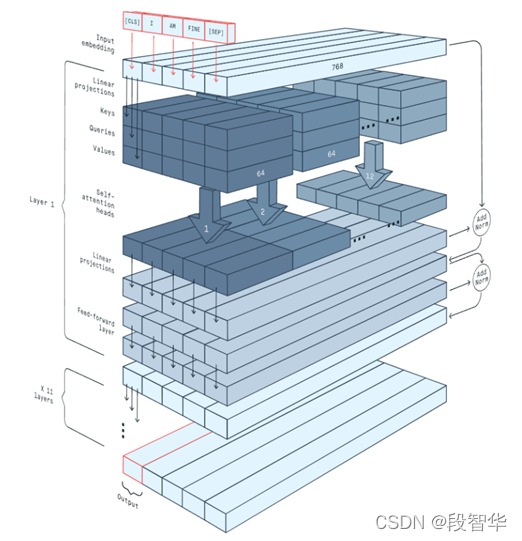
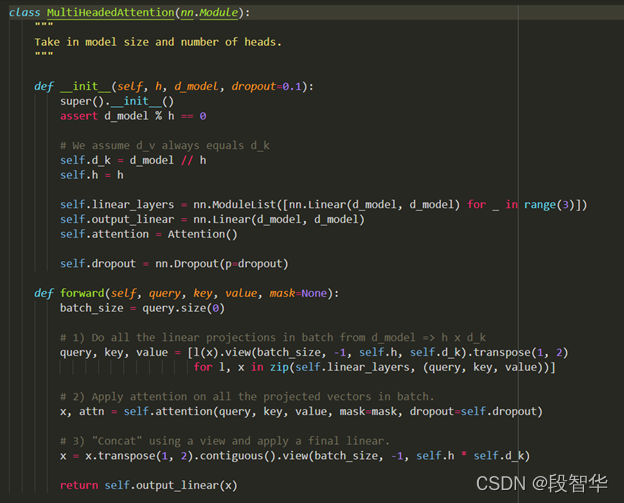
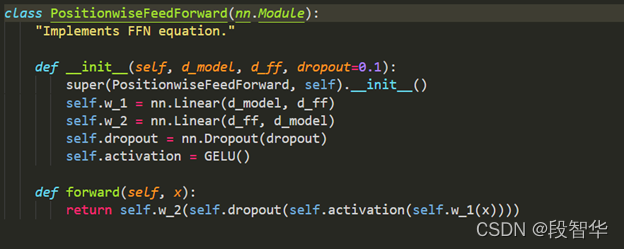
“一种架构,统治一切”( 来自Gavin大咖的Transformer硅谷杂谈系列) 第一季

“一种架构,统治一切”( 来自Gavin大咖的Transformer硅谷杂谈系列)
第一季:新一代的Rasa 3.x到底新在什么地方?
第1讲:Rasa 3.x解除了Model和Framework的架构耦合
第2讲:Rasa 3.x新一代计算后端、状态管理等
第3讲:Rasa 3.x全新一代的Graph Architecture解析
第4讲:Rasa 3.x的Graph Architecture带来的具体价值有哪些?
第5讲: 通过Jieba及DIET源码来说明具体如何进行Rasa 3.x自定义组件的版本迁移
第6讲:Rasa 3.x 全新的Slot管理实现机制
第7讲:Rasa 3.x的Global Slot管理带来的核心价值是什么?
第8讲: Rasa 3.x中Slot源码实现解析
第9讲:Rasa 3.x中Slot对Conversation影响力内幕源码解密
第10讲: Rasa 3.x中关于Slot对Conversation产生Influence疑惑解析
第11讲:Rasa 3.x中不同类型Slot解析
第12讲:Rasa 3.x中Custom Slot Types完整实例详解
第13讲:Rasa 3.x中Slot Mappings及Mapping Conditions解析
第14讲:Rasa 3.x中关于Slot的from_entity及其在form的应用限制解析
第15讲:Rasa 3.x中Slot的from_text、from_entity及from_trigger_intent解析
第16讲:Rasa 3.x中Custom Slot Mappings及Initial slot values解析
第17讲:Rasa 3.x中关于ValidationAction及FormValidationAction介绍及文档的错误分析
第18讲:Rasa 3.x中FormAction中关于对Slot操作的源码分析
第19讲:Rasa 3.x中对Slot操作的extract_requested_slot源码分析
第20讲:Rasa 3.x中对Slot操作的extract_custom_slots源码分析
第21讲:Rasa 3.x中衡量对话机器人质量的全新一代技术Markers解密
课程名称:第二季:透彻理解NLP底层内核信息熵(Shannon Entropy)

内容介绍:
Entropy是NLP领域进行信息衡量和模型优化最核心的概念,掌握Entropy底层内核能够极大的提升对自然语言处理本质的理解并带来深度的技术洞察力。
本系列视频从示例入手来一步步完整再现Shannon’s Entropy的整个实现过程及应用。内容包括:
第1讲:为何信息熵(Shannon Entropy)是NLP自然语言底层最核心的硬核概念?
第2讲:信息熵(Shannon Entropy)中的Amount of information解析
第3讲:信息熵(Shannon Entropy)中的Information和Data联系和区别及Data表达信息的问题剖析
第4讲:信息熵(Shannon Entropy)中的absolute minimum amount信息存储和传输解析
第5讲:信息熵(Shannon Entropy)中的Entropy内涵解析
第6讲:信息熵(Shannon Entropy)用具体示例来说明信息量的内涵
第7讲:信息熵(Shannon Entropy)具体如何从数学量化的角度来对信息进行压缩?
Entropy: amount of information
Storage and transmission of information
Shannon’s entropy
Concept of “Amount” of Information
Quantifying the Amount of Information
Example of Information Quantity
The Entropy Formula
Mathematical Approximation of Required Storage
课程标题:Advanced Python事件驱动及异步编程实战

课程介绍:本课程以工业级Rasa源码分析为背景,以Python Coroutine编程为基石,以CPU-Bound和IO-Bound场景为核心,抽丝剥茧的解密Python高阶技能中的Generator、Coroutine、Event Loop、Events, Conditions、Awaitable、Future、Task、Gather、Locks、Semaphore、Notification、Decorator、Muti-threading、Executor等异步编程内幕,帮助学员完成从Python工程师到编程高手的蜕变。

Rasa系列博客:
- 业务对话机器人Rasa 3.x Internals及Rasa框架定制实战
- 业务对话机器人Rasa核心算法DIET及TED论文详解
- 业务对话机器人Rasa 3.x部署安装初体验
- 业务对话机器人Rasa 3.x Playground
- 业务对话机器人Rasa 3.x Command Line Interface
- 业务对话机器人Rasa 3.x 命令 rasa shell 及rasa run
- 业务对话机器人Rasa 3.x 命令rasa run actions、rasa test、rasa data split 、rasa data convert nlu
- 业务对话机器人Rasa 3.x 命令rasa data migrate、rasa data validate、rasa export、rasa evaluate markers、rasa x
- 业务对话机器人Rasa 3.x 会话驱动开发(Conversation-Driven Development)

