
- 1C++使用namespace解决命名冲突_using namespace解决重名问题
- 2idea项目提交到github 怎么去除.idea文件和target文件_gitlab怎么设置不把target和.idea文件上传
- 33万字细说数据仓库体系(建议收藏)
- 4ERROR: KeeperErrorCode = NoNode for /hbase/master 问题
- 5stable-diffusion-webui手动安装详细步骤(AMD显卡)_stable-diffusion-webui-directml
- 6python基础篇-for循环_python for循环
- 7RTSP/Onvif视频安防监控平台EasyNVR调用接口返回匿名用户名和密码的原因排查
- 8springboot高校大学生学科竞赛管理系统的设计与实现 计算机毕设源码53135_学科竞赛管理系统 的设计与实现
- 9蓝桥杯上岸考点清单 (冲刺版)!!!_蓝桥杯考前冲刺
- 10【darknet-yolo系列】在colab上训练yolo模型(详细操作流程)_在colab中训练好的模型放在哪里
LLM各层参数详细分析(以LLaMA为例)_llm参数
赞
踩
网上大多分析LLM参数的文章都比较粗粒度,对于LLM的精确部署不太友好,在这里记录一下分析LLM参数的过程。
首先看QKV。先上transformer原文

也就是说,当h(heads) = 1时,在默认情况下,
W
i
Q
W_i^Q
WiQ、
W
i
K
W_i^K
WiK、
W
i
V
W_i^V
WiV都是2维方阵,方阵维度是
d
m
o
d
e
l
×
d
m
o
d
e
l
d_{model} \times d_{model}
dmodel×dmodel.
结合llama源码 (https://github.com/facebookresearch/llama/blob/main/llama/model.py)
class ModelArgs: dim: int = 4096 n_layers: int = 32 n_heads: int = 32 n_kv_heads: Optional[int] = None vocab_size: int = -1 # defined later by tokenizer multiple_of: int = 256 # make SwiGLU hidden layer size multiple of large power of 2 ffn_dim_multiplier: Optional[float] = None norm_eps: float = 1e-5 max_batch_size: int = 32 max_seq_len: int = 2048 # ... class Attention(nn.Module): """Multi-head attention module.""" def __init__(self, args: ModelArgs): """ Initialize the Attention module. Args: args (ModelArgs): Model configuration parameters. Attributes: n_kv_heads (int): Number of key and value heads. n_local_heads (int): Number of local query heads. n_local_kv_heads (int): Number of local key and value heads. n_rep (int): Number of repetitions for local heads. head_dim (int): Dimension size of each attention head. wq (ColumnParallelLinear): Linear transformation for queries. wk (ColumnParallelLinear): Linear transformation for keys. wv (ColumnParallelLinear): Linear transformation for values. wo (RowParallelLinear): Linear transformation for output. cache_k (torch.Tensor): Cached keys for attention. cache_v (torch.Tensor): Cached values for attention. """ super().__init__() self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads model_parallel_size = fs_init.get_model_parallel_world_size() self.n_local_heads = args.n_heads // model_parallel_size self.n_local_kv_heads = self.n_kv_heads // model_parallel_size self.n_rep = self.n_local_heads // self.n_local_kv_heads self.head_dim = args.dim // args.n_heads

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
计算出
self.n_kv_heads = h = 32
self.head_dim = 4096/32=128
所以
W
i
Q
W_i^Q
WiQ、
W
i
K
W_i^K
WiK、
W
i
V
W_i^V
WiV 大小都为(4096, 128).(在未拆分前
W
Q
W^Q
WQ,
W
K
W^K
WK和
W
V
W^V
WV都是
(
d
i
m
,
d
i
m
)
=
(
4096
,
4096
)
(dim, dim) = (4096,4096)
(dim,dim)=(4096,4096)大小)。
Q
,
K
,
V
Q,K,V
Q,K,V的大小都是
(
n
c
t
x
,
d
i
m
)
=
(
2048
,
4096
)
(n_{ctx}, dim) = (2048,4096)
(nctx,dim)=(2048,4096) (在多头公式里。在self-attention里,其实他们都是同一个值:输入X),所以
Q
×
W
i
Q
Q×W_i^Q
Q×WiQ 和
K
×
W
i
K
K×W_i^K
K×WiK 和
Q
×
W
i
Q
Q×W_i^Q
Q×WiQ 都是
(
n
c
t
x
,
d
k
)
=
(
2048
,
128
)
(n_{ctx}, d_k)=(2048,128)
(nctx,dk)=(2048,128)。带入原文attention公式后,大小为(2048, 128)不变。Attention不改变大小(在默认
d
k
=
d
v
d_k=d_v
dk=dv情况下)。
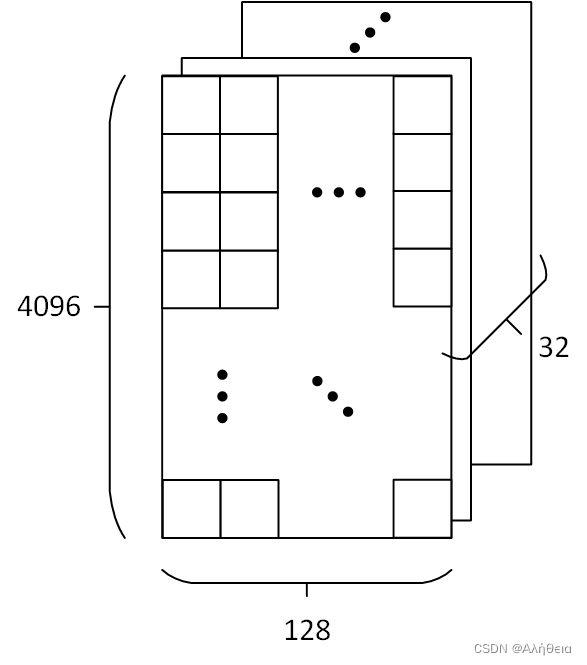
经过Cancat,分开的头又合并,大小变为(2048, 4096)矩阵,经过 W O W^O WO (大小是(4096,4096))全连接,还是(2048, 4096)矩阵。
然后看Feed forward.根据源码,
class FeedForward(nn.Module): def __init__( self, dim: int, hidden_dim: int, multiple_of: int, ffn_dim_multiplier: Optional[float], ): """ Initialize the FeedForward module. Args: dim (int): Input dimension. hidden_dim (int): Hidden dimension of the feedforward layer. multiple_of (int): Value to ensure hidden dimension is a multiple of this value. ffn_dim_multiplier (float, optional): Custom multiplier for hidden dimension. Defaults to None. Attributes: w1 (ColumnParallelLinear): Linear transformation for the first layer. w2 (RowParallelLinear): Linear transformation for the second layer. w3 (ColumnParallelLinear): Linear transformation for the third layer. """ super().__init__() hidden_dim = int(2 * hidden_dim / 3) # custom dim factor multiplier if ffn_dim_multiplier is not None: hidden_dim = int(ffn_dim_multiplier * hidden_dim) hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of) self.w1 = ColumnParallelLinear( dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x ) self.w2 = RowParallelLinear( hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x ) self.w3 = ColumnParallelLinear( dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x ) def forward(self, x): return self.w2(F.silu(self.w1(x)) * self.w3(x))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
multiattention layer过后,经过加法和normlayer(RMS norm),进入feed_forward前馈网络。注意这里的前馈网络其中一个维度会有8/3≈2.7的放缩,然后multiple_of又保证必须是256的倍数,所以这里算出来hidden_dim是256的倍数中与8/3*4096最接近的,是11008。以这里的w1,w3大小为(4096,11008),w2大小为(11008,4096). 输出结果大小
整个decode layer计算如图所示,
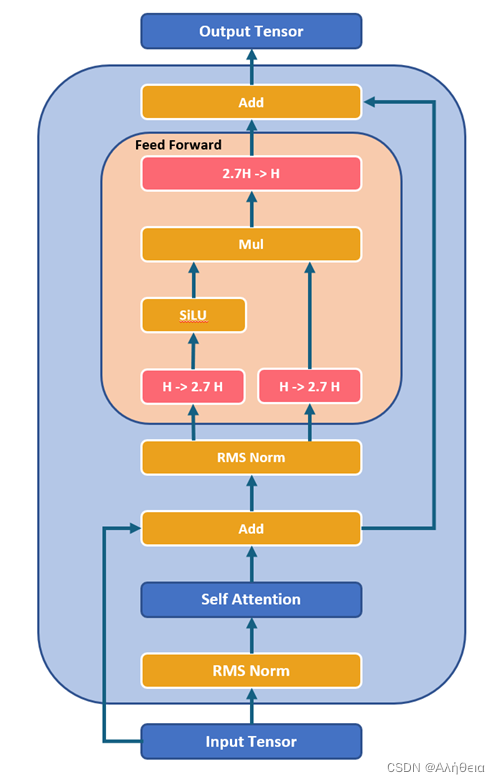
来源:https://github.com/microsoft/Llama-2-Onnx/blob/main/Images/DecoderLayer.png


{kind=link}