
- 1用GVIM/VIM写Verilog——VIM配置分享_gvim svstemverilog 插件
- 2深度学习之RNN循环神经网络(理论+图解+Python代码部分)
- 3数据流分析(一)_数据流分析怎么写
- 4python 之弗洛伊德算法_floyd-warshall算法python代码
- 5FPGA 静态时序分析与约束(2)_quartus unconstrained path
- 6微信小程序开发与应用——字体样式设置_微信小程序style属性
- 7多无人机对组网雷达的协同干扰问题 数学建模
- 8Python实现mysql数据库验证_python3 构建一个源和目的都是mysql的数据校验程序
- 9Win10安装安卓模拟器入坑记_exagear win10
- 10岛屿数量(dfs)
Windows系统保姆级复现Pointnet++算法教程笔记(基于Pytorch)_pointnet++复现
赞
踩
前言
今天复现了PointNet++网络,中途也遇到过好多报错问题,但都一一解决了,最终实现cls、partseg、semseg训练(train)和测试(test)程序的成功跑通。
首先,我参考的论文和所用的源码参考自这篇文章:
3D点云目标检测算法Pointnet++项目实战 Pytorch实现
附代码:
链接:https://pan.baidu.com/s/10Nk4Zd3S_NklY5PJwzmnWA
提取码:6688
论文链接:
https://proceedings.neurips.cc/paper/2017/file/d8bf84be3800d12f74d8b05e9b89836f-Paper.pdf
一、配置环境
按理说复现Pointnet的源码是适用于在Ubuntu下跑,但是我想在Windows实现一下
Windows系统
python 3.8 cuda 11.6 pytorch 1.12.0 torchvision 0.13.0
在这之前要先在anaconda下创建一个pointnet的虚拟环境,python版本选择3.8
- # 创建虚拟环境
- conda create -n pointnet python=3.8.0
- # 激活虚拟环境(切换至这个环境)
- conda activate pointnet
- # 查看已创建的虚拟环境
- conda info -e
然后对应自己CUDA版本下载对应的gpu版的pytorch
- # CUDA 11.6
- pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
这一块虚拟环境的GPU配置就不细说了,如果没有配置过可以参考我这篇文章,基本步骤都差不多:
二、复现步骤
1.先将代码下载下来,目录结构如下:
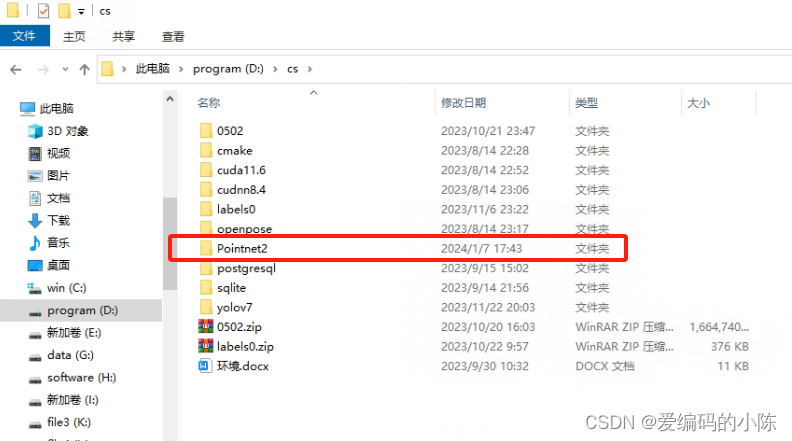
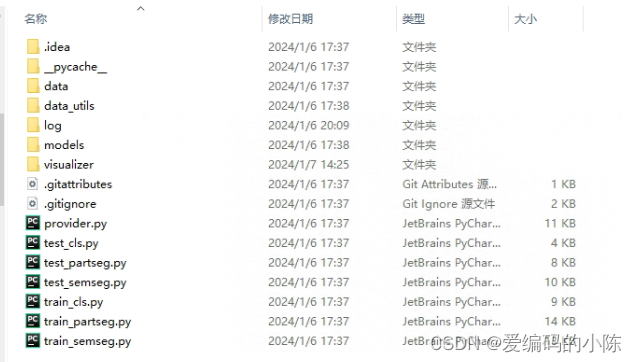
其实这里的东西如果真的想全部能跑是缺了一些东西的,下面具体再说。
2.启动PyCharm打开该项目文件Pointnet2,同时将自己前面创建好的虚拟环境导入进来(具体导入的方法,参考我上面的文章链接,也有步骤)
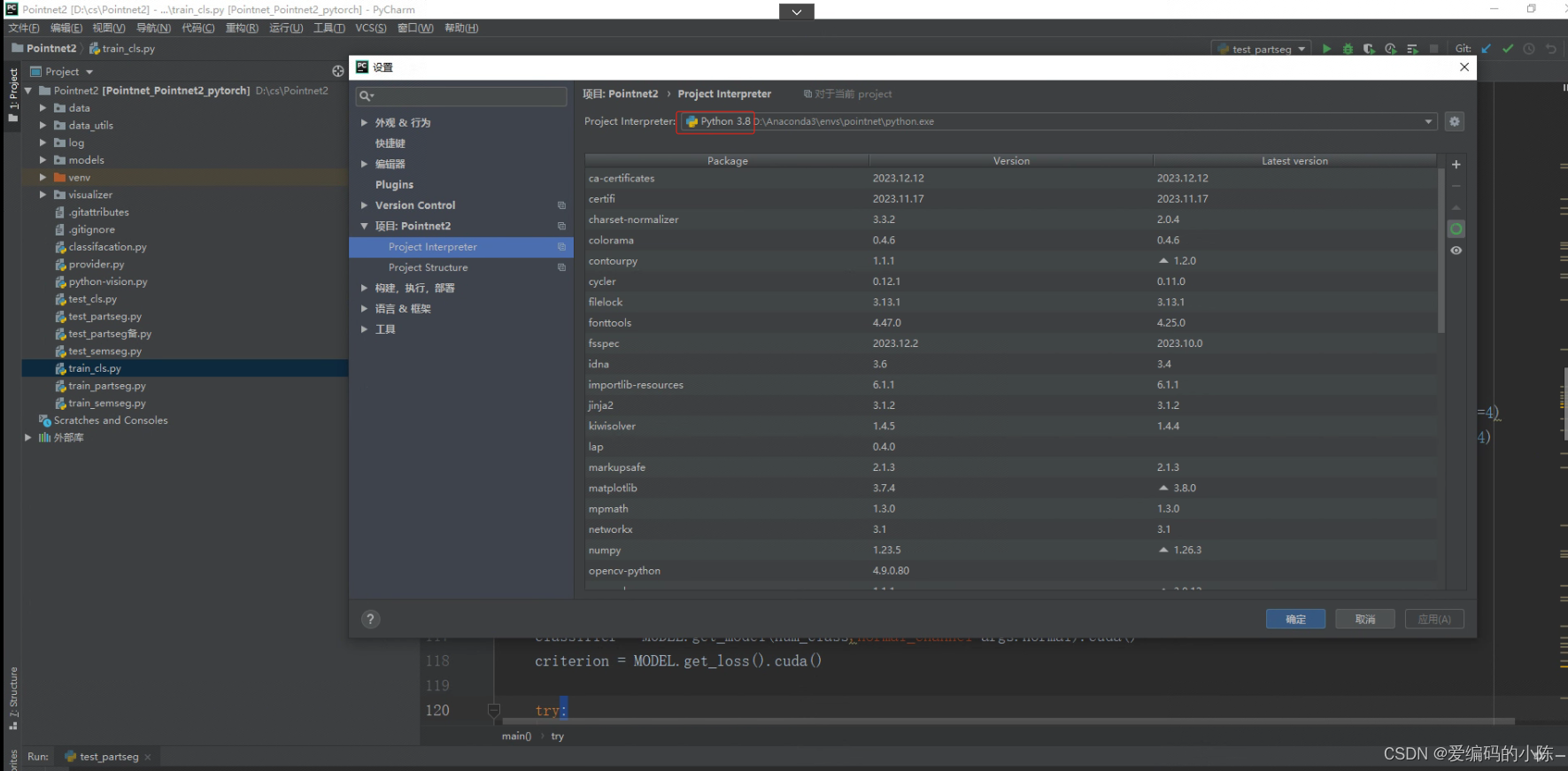
其中环境Python3.8是自己给虚拟环境起的名称,可以在这里面编辑,因为我前面配置过Python3.7的虚拟环境,而这次采用pythonn3.8版本的,一开始导入进来,前面的环境名称还是默认Python3.7,我以为3.8版本的python编译器没有成功导入进来,担心后面因版本问题引起不必要的报错,后来发现编译器python.exe已经是3.8的了,只是虚拟环境名称需要改一下

如果不确定可以跑下面的程序来确认一下python版本(确认一下导入的虚拟环境是对的)
- import sys
- print(sys.version)
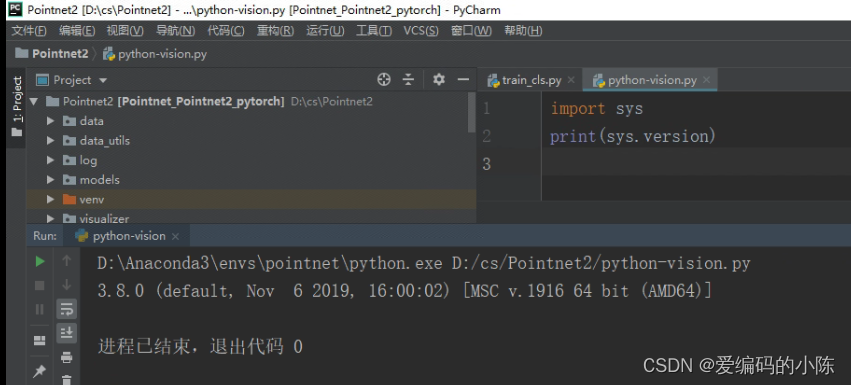
3.接下来我们就可以依次运行train_cls.py、train_partseg.py、train_semseg.py、test_cls.py、test_partseg.py、test_semseg.py是否可以正常跑通,train代表进行模型训练用的,test代表模型测试用的。
首先我把我自己调通的可以跑的程序先放出来
(1)train_cls.py
- from data_utils.ModelNetDataLoader import ModelNetDataLoader
- import argparse
- import numpy as np
- import os
- import torch
- import datetime
- import logging
- from pathlib import Path
- from tqdm import tqdm
- import sys
- import provider
- import importlib
- import shutil
-
- BASE_DIR = os.path.dirname(os.path.abspath(__file__))
- ROOT_DIR = BASE_DIR
- sys.path.append(os.path.join(ROOT_DIR, 'models'))
- """
- 需要配置的参数:
- --model pointnet2_cls_msg
- --normal
- --log_dir pointnet2_cls_msg
- """
-
- def parse_args():
- '''PARAMETERS'''
- parser = argparse.ArgumentParser('PointNet')
- parser.add_argument('--batch_size', type=int, default=8, help='batch size in training [default: 24]')
- parser.add_argument('--model', default='pointnet2_cls_ssg', help='model name [default: pointnet_cls]')
- parser.add_argument('--epoch', default=200, type=int, help='number of epoch in training [default: 200]')
- parser.add_argument('--learning_rate', default=0.001, type=float, help='learning rate in training [default: 0.001]')
- parser.add_argument('--gpu', type=str, default='0', help='specify gpu device [default: 0]')
- parser.add_argument('--num_point', type=int, default=1024, help='Point Number [default: 1024]')
- parser.add_argument('--optimizer', type=str, default='Adam', help='optimizer for training [default: Adam]')
- parser.add_argument('--log_dir', type=str, default=None, help='experiment root')
- parser.add_argument('--decay_rate', type=float, default=1e-4, help='decay rate [default: 1e-4]')
- parser.add_argument('--normal', action='store_true', default=False, help='Whether to use normal information [default: False]')
- return parser.parse_args()
-
- def test(model, loader, num_class=40):
- mean_correct = []
- class_acc = np.zeros((num_class,3))
- for j, data in tqdm(enumerate(loader), total=len(loader)):
- points, target = data
- target = target[:, 0]
- points = points.transpose(2, 1)
- points, target = points.cuda(), target.cuda()
- classifier = model.eval()
- pred, _ = classifier(points)
- pred_choice = pred.data.max(1)[1]
- for cat in np.unique(target.cpu()):
- classacc = pred_choice[target==cat].eq(target[target==cat].long().data).cpu().sum()
- class_acc[cat,0]+= classacc.item()/float(points[target==cat].size()[0])
- class_acc[cat,1]+=1
- correct = pred_choice.eq(target.long().data).cpu().sum()
- mean_correct.append(correct.item()/float(points.size()[0]))
- class_acc[:,2] = class_acc[:,0]/ class_acc[:,1]
- class_acc = np.mean(class_acc[:,2])
- instance_acc = np.mean(mean_correct)
- return instance_acc, class_acc
-
-
- def main(args):
- def log_string(str):
- logger.info(str)
- print(str)
-
- '''HYPER PARAMETER'''
- os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
-
- '''CREATE DIR'''
- #创建文件夹
- timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M'))
- experiment_dir = Path('./log/')
- experiment_dir.mkdir(exist_ok=True)
- experiment_dir = experiment_dir.joinpath('classification')
- experiment_dir.mkdir(exist_ok=True)
- if args.log_dir is None:
- experiment_dir = experiment_dir.joinpath(timestr)
- else:
- experiment_dir = experiment_dir.joinpath(args.log_dir)
- experiment_dir.mkdir(exist_ok=True)
- checkpoints_dir = experiment_dir.joinpath('checkpoints/')
- checkpoints_dir.mkdir(exist_ok=True)
- log_dir = experiment_dir.joinpath('logs/')
- log_dir.mkdir(exist_ok=True)
-
- '''LOG'''
- args = parse_args()
- logger = logging.getLogger("Model")
- logger.setLevel(logging.INFO)
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
- file_handler = logging.FileHandler('%s/%s.txt' % (log_dir, args.model))
- file_handler.setLevel(logging.INFO)
- file_handler.setFormatter(formatter)
- logger.addHandler(file_handler)
- log_string('PARAMETER ...')
- log_string(args)
-
- '''DATA LOADING'''
- log_string('Load dataset ...')
- DATA_PATH = 'data/modelnet40_normal_resampled/'
-
- TRAIN_DATASET = ModelNetDataLoader(root=DATA_PATH, npoint=args.num_point, split='train',
- normal_channel=args.normal)
- TEST_DATASET = ModelNetDataLoader(root=DATA_PATH, npoint=args.num_point, split='test',
- normal_channel=args.normal)
- trainDataLoader = torch.utils.data.DataLoader(TRAIN_DATASET, batch_size=args.batch_size, shuffle=True, num_workers=4)
- testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=args.batch_size, shuffle=False, num_workers=4)
-
- '''MODEL LOADING'''
- num_class = 40
- MODEL = importlib.import_module(args.model)
- shutil.copy('./models/%s.py' % args.model, str(experiment_dir))
- shutil.copy('./models/pointnet_util.py', str(experiment_dir))
-
- classifier = MODEL.get_model(num_class,normal_channel=args.normal).cuda()
- criterion = MODEL.get_loss().cuda()
-
- try:
- checkpoint = torch.load(str(experiment_dir) + '/checkpoints/best_model.pth')
- start_epoch = checkpoint['epoch']
- classifier.load_state_dict(checkpoint['model_state_dict'])
- log_string('Use pretrain model')
- except:
- log_string('No existing model, starting training from scratch...')
- start_epoch = 0
-
-
- if args.optimizer == 'Adam':
- optimizer = torch.optim.Adam(
- classifier.parameters(),
- lr=args.learning_rate,
- betas=(0.9, 0.999),
- eps=1e-08,
- weight_decay=args.decay_rate
- )
- else:
- optimizer = torch.optim.SGD(classifier.parameters(), lr=0.01, momentum=0.9)
-
- scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.7)
- global_epoch = 0
- global_step = 0
- best_instance_acc = 0.0
- best_class_acc = 0.0
- mean_correct = []
-
- '''TRANING'''
- logger.info('Start training...')
- for epoch in range(start_epoch,args.epoch):
- log_string('Epoch %d (%d/%s):' % (global_epoch + 1, epoch + 1, args.epoch))
- # optimizer.step()通常用在每个mini-batch之中,而scheduler.step()通常用在epoch里面,
- # 但也不是绝对的,可以根据具体的需求来做。
- # 只有用了optimizer.step(),模型才会更新,而scheduler.step()是对lr进行调整。
- scheduler.step()
- for batch_id, data in tqdm(enumerate(trainDataLoader, 0), total=len(trainDataLoader), smoothing=0.9):
- points, target = data
- points = points.data.numpy()
- points = provider.random_point_dropout(points) #进行数据增强
- points[:,:, 0:3] = provider.random_scale_point_cloud(points[:,:, 0:3]) #在数值上调大或调小,设置一个范围
- points[:,:, 0:3] = provider.shift_point_cloud(points[:,:, 0:3]) #增加随机抖动,使测试结果更好
- points = torch.Tensor(points)
- target = target[:, 0]
-
- points = points.transpose(2, 1)
- points, target = points.cuda(), target.cuda()
- optimizer.zero_grad()
-
- classifier = classifier.train()
- pred, trans_feat = classifier(points)
- loss = criterion(pred, target.long(), trans_feat) #计算损失
- pred_choice = pred.data.max(1)[1]
- correct = pred_choice.eq(target.long().data).cpu().sum()
- mean_correct.append(correct.item() / float(points.size()[0]))
- loss.backward() #反向传播
- optimizer.step() #最好的测试结果
- global_step += 1
-
- train_instance_acc = np.mean(mean_correct)
- log_string('Train Instance Accuracy: %f' % train_instance_acc)
-
- with torch.no_grad():
- instance_acc, class_acc = test(classifier.eval(), testDataLoader)
-
- if (instance_acc >= best_instance_acc):
- best_instance_acc = instance_acc
- best_epoch = epoch + 1
-
- if (class_acc >= best_class_acc):
- best_class_acc = class_acc
- log_string('Test Instance Accuracy: %f, Class Accuracy: %f'% (instance_acc, class_acc))
- log_string('Best Instance Accuracy: %f, Class Accuracy: %f'% (best_instance_acc, best_class_acc))
-
- if (instance_acc >= best_instance_acc):
- logger.info('Save model...')
- savepath = str(checkpoints_dir) + '/best_model.pth'
- log_string('Saving at %s'% savepath)
- state = {
- 'epoch': best_epoch,
- 'instance_acc': instance_acc,
- 'class_acc': class_acc,
- 'model_state_dict': classifier.state_dict(),
- 'optimizer_state_dict': optimizer.state_dict(),
- }
- torch.save(state, savepath)
- global_epoch += 1
-
- logger.info('End of training...')
-
- if __name__ == '__main__':
- args = parse_args()
- main(args)
(2)train_partseg.py
- import argparse
- import os
- from data_utils.ShapeNetDataLoader import PartNormalDataset
- import torch
- import datetime
- import logging
- from pathlib import Path
- import sys
- import importlib
- import shutil
- from tqdm import tqdm
- import provider
- import numpy as np
- """
- 训练所需设置参数:
- --model pointnet2_part_seg_msg
- --normal
- --log_dir pointnet2_part_seg_msg
- """
-
- BASE_DIR = os.path.dirname(os.path.abspath(__file__))
- ROOT_DIR = BASE_DIR
- sys.path.append(os.path.join(ROOT_DIR, 'models'))
-
- #各个物体部件的编号
- seg_classes = {'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43], 'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46], 'Mug': [36, 37], 'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27], 'Table': [47, 48, 49], 'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40], 'Chair': [12, 13, 14, 15], 'Knife': [22, 23]}
- seg_label_to_cat = {} # {0:Airplane, 1:Airplane, ...49:Table}
- for cat in seg_classes.keys():
- for label in seg_classes[cat]:
- seg_label_to_cat[label] = cat
-
- def to_categorical(y, num_classes):
- """ 1-hot encodes a tensor """
- new_y = torch.eye(num_classes)[y.cpu().data.numpy(),]
- if (y.is_cuda):
- return new_y.cuda()
- return new_y
-
- def parse_args():
- parser = argparse.ArgumentParser('Model')
- parser.add_argument('--model', type=str, default='pointnet2_part_seg_msg', help='model name [default: pointnet2_part_seg_msg]')
- parser.add_argument('--batch_size', type=int, default=32, help='Batch Size during training [default: 16]')
- parser.add_argument('--epoch', default=2, type=int, help='Epoch to run [default: 251]')
- parser.add_argument('--learning_rate', default=0.001, type=float, help='Initial learning rate [default: 0.001]')
- # parser.add_argument('--gpu', type=str, default='', help='GPU to use [default: GPU 0]')
- parser.add_argument('--gpu', default='', help='cuda gpu, i.e. 0 or 0,1,2,3 or cpu')
- parser.add_argument('--optimizer', type=str, default='Adam', help='Adam or SGD [default: Adam]')
- parser.add_argument('--log_dir', type=str, default=None, help='Log path [default: None]')
- parser.add_argument('--decay_rate', type=float, default=1e-4, help='weight decay [default: 1e-4]')
- parser.add_argument('--npoint', type=int, default=2048, help='Point Number [default: 2048]')
- parser.add_argument('--normal', action='store_true', default=False, help='Whether to use normal information [default: False]')
- parser.add_argument('--step_size', type=int, default=20, help='Decay step for lr decay [default: every 20 epochs]')
- parser.add_argument('--lr_decay', type=float, default=0.5, help='Decay rate for lr decay [default: 0.5]')
-
- return parser.parse_args()
-
- def main(args):
- def log_string(str):
- logger.info(str)
- print(str)
-
- '''HYPER PARAMETER'''
- os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
-
- '''CREATE DIR'''
- timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M'))
- experiment_dir = Path('./log/')
- experiment_dir.mkdir(exist_ok=True)
- experiment_dir = experiment_dir.joinpath('part_seg')
- experiment_dir.mkdir(exist_ok=True)
- if args.log_dir is None:
- experiment_dir = experiment_dir.joinpath(timestr)
- else:
- experiment_dir = experiment_dir.joinpath(args.log_dir)
- experiment_dir.mkdir(exist_ok=True)
- checkpoints_dir = experiment_dir.joinpath('checkpoints/')
- checkpoints_dir.mkdir(exist_ok=True)
- log_dir = experiment_dir.joinpath('logs/')
- log_dir.mkdir(exist_ok=True)
-
- '''LOG'''
- args = parse_args()
- logger = logging.getLogger("Model")
- logger.setLevel(logging.INFO)
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
- file_handler = logging.FileHandler('%s/%s.txt' % (log_dir, args.model))
- file_handler.setLevel(logging.INFO)
- file_handler.setFormatter(formatter)
- logger.addHandler(file_handler)
- log_string('PARAMETER ...')
- log_string(args)
-
- root = 'data/shapenetcore_partanno_segmentation_benchmark_v0_normal/'
-
- TRAIN_DATASET = PartNormalDataset(root = root, npoints=args.npoint, split='trainval', normal_channel=args.normal)
- trainDataLoader = torch.utils.data.DataLoader(TRAIN_DATASET, batch_size=args.batch_size,shuffle=True, num_workers=4)
- TEST_DATASET = PartNormalDataset(root = root, npoints=args.npoint, split='test', normal_channel=args.normal)
- testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=args.batch_size,shuffle=False, num_workers=4)
- log_string("The number of training data is: %d" % len(TRAIN_DATASET))
- log_string("The number of test data is: %d" % len(TEST_DATASET))
- num_classes = 16
- num_part = 50
- '''MODEL LOADING'''
- MODEL = importlib.import_module(args.model)
- shutil.copy('models/%s.py' % args.model, str(experiment_dir))
- shutil.copy('models/pointnet_util.py', str(experiment_dir))
-
- classifier = MODEL.get_model(num_part, normal_channel=args.normal).cuda()
- criterion = MODEL.get_loss().cuda()
-
-
- def weights_init(m):
- classname = m.__class__.__name__
- if classname.find('Conv2d') != -1:
- torch.nn.init.xavier_normal_(m.weight.data)
- torch.nn.init.constant_(m.bias.data, 0.0)
- elif classname.find('Linear') != -1:
- torch.nn.init.xavier_normal_(m.weight.data)
- torch.nn.init.constant_(m.bias.data, 0.0)
-
- try:
- checkpoint = torch.load(str(experiment_dir) + '/checkpoints/best_model.pth')#log/part_seg/pointnet2_part_seg_msg/checkpoints/best_model.pth
- start_epoch = checkpoint['epoch']
- classifier.load_state_dict(checkpoint['model_state_dict'])
- log_string('Use pretrain model')
- except:
- log_string('No existing model, starting training from scratch...')
- start_epoch = 0
- classifier = classifier.apply(weights_init)
-
- if args.optimizer == 'Adam':
- optimizer = torch.optim.Adam(
- classifier.parameters(),
- lr=args.learning_rate,
- betas=(0.9, 0.999),
- eps=1e-08,
- weight_decay=args.decay_rate
- )
- else:
- optimizer = torch.optim.SGD(classifier.parameters(), lr=args.learning_rate, momentum=0.9)
-
- def bn_momentum_adjust(m, momentum):
- if isinstance(m, torch.nn.BatchNorm2d) or isinstance(m, torch.nn.BatchNorm1d):
- m.momentum = momentum
-
- LEARNING_RATE_CLIP = 1e-5
- MOMENTUM_ORIGINAL = 0.1
- MOMENTUM_DECCAY = 0.5
- MOMENTUM_DECCAY_STEP = args.step_size
-
- best_acc = 0
- global_epoch = 0
- best_class_avg_iou = 0
- best_inctance_avg_iou = 0
-
- for epoch in range(start_epoch,args.epoch):
- log_string('Epoch %d (%d/%s):' % (global_epoch + 1, epoch + 1, args.epoch))
- '''Adjust learning rate and BN momentum'''
- lr = max(args.learning_rate * (args.lr_decay ** (epoch // args.step_size)), LEARNING_RATE_CLIP)
- log_string('Learning rate:%f' % lr)
- for param_group in optimizer.param_groups:
- param_group['lr'] = lr
- mean_correct = []
- momentum = MOMENTUM_ORIGINAL * (MOMENTUM_DECCAY ** (epoch // MOMENTUM_DECCAY_STEP))
- if momentum < 0.01:
- momentum = 0.01
- print('BN momentum updated to: %f' % momentum)
- classifier = classifier.apply(lambda x: bn_momentum_adjust(x,momentum))
-
- '''learning one epoch'''
- for i, data in tqdm(enumerate(trainDataLoader), total=len(trainDataLoader), smoothing=0.9):
- points, label, target = data
- points = points.data.numpy()
- points[:,:, 0:3] = provider.random_scale_point_cloud(points[:,:, 0:3])
- points[:,:, 0:3] = provider.shift_point_cloud(points[:,:, 0:3])
- points = torch.Tensor(points)
- points, label, target = points.float().cuda(),label.long().cuda(), target.long().cuda()
- points = points.transpose(2, 1)
- optimizer.zero_grad()
- classifier = classifier.train()
- seg_pred, trans_feat = classifier(points, to_categorical(label, num_classes))
- seg_pred = seg_pred.contiguous().view(-1, num_part)
- target = target.view(-1, 1)[:, 0]
- pred_choice = seg_pred.data.max(1)[1]
- correct = pred_choice.eq(target.data).cpu().sum()
- mean_correct.append(correct.item() / (args.batch_size * args.npoint))
- loss = criterion(seg_pred, target, trans_feat)
- loss.backward()
- optimizer.step()
- train_instance_acc = np.mean(mean_correct)
- log_string('Train accuracy is: %.5f' % train_instance_acc)
-
- with torch.no_grad():
- test_metrics = {}
- total_correct = 0
- total_seen = 0
- total_seen_class = [0 for _ in range(num_part)]
- total_correct_class = [0 for _ in range(num_part)]
- shape_ious = {cat: [] for cat in seg_classes.keys()}
- seg_label_to_cat = {} # {0:Airplane, 1:Airplane, ...49:Table}
- for cat in seg_classes.keys():
- for label in seg_classes[cat]:
- seg_label_to_cat[label] = cat
-
- for batch_id, (points, label, target) in tqdm(enumerate(testDataLoader), total=len(testDataLoader), smoothing=0.9):
- cur_batch_size, NUM_POINT, _ = points.size()
- points, label, target = points.float().cuda(), label.long().cuda(), target.long().cuda()
- points = points.transpose(2, 1)
- classifier = classifier.eval()
- seg_pred, _ = classifier(points, to_categorical(label, num_classes))
- cur_pred_val = seg_pred.cpu().data.numpy()
- cur_pred_val_logits = cur_pred_val
- cur_pred_val = np.zeros((cur_batch_size, NUM_POINT)).astype(np.int32)
- target = target.cpu().data.numpy()
- for i in range(cur_batch_size):
- cat = seg_label_to_cat[target[i, 0]]
- logits = cur_pred_val_logits[i, :, :]
- cur_pred_val[i, :] = np.argmax(logits[:, seg_classes[cat]], 1) + seg_classes[cat][0]
- correct = np.sum(cur_pred_val == target)
- total_correct += correct
- total_seen += (cur_batch_size * NUM_POINT)
-
- for l in range(num_part):
- total_seen_class[l] += np.sum(target == l)
- total_correct_class[l] += (np.sum((cur_pred_val == l) & (target == l)))
-
- for i in range(cur_batch_size):
- segp = cur_pred_val[i, :]
- segl = target[i, :]
- cat = seg_label_to_cat[segl[0]]
- part_ious = [0.0 for _ in range(len(seg_classes[cat]))]
- for l in seg_classes[cat]:
- if (np.sum(segl == l) == 0) and (
- np.sum(segp == l) == 0): # part is not present, no prediction as well
- part_ious[l - seg_classes[cat][0]] = 1.0
- else:
- part_ious[l - seg_classes[cat][0]] = np.sum((segl == l) & (segp == l)) / float(
- np.sum((segl == l) | (segp == l)))
- shape_ious[cat].append(np.mean(part_ious))
-
- all_shape_ious = []
- for cat in shape_ious.keys():
- for iou in shape_ious[cat]:
- all_shape_ious.append(iou)
- shape_ious[cat] = np.mean(shape_ious[cat])
- mean_shape_ious = np.mean(list(shape_ious.values()))
- test_metrics['accuracy'] = total_correct / float(total_seen)
- test_metrics['class_avg_accuracy'] = np.mean(
- np.array(total_correct_class) / np.array(total_seen_class, dtype=np.float))
- for cat in sorted(shape_ious.keys()):
- log_string('eval mIoU of %s %f' % (cat + ' ' * (14 - len(cat)), shape_ious[cat]))
- test_metrics['class_avg_iou'] = mean_shape_ious
- test_metrics['inctance_avg_iou'] = np.mean(all_shape_ious)
-
-
- log_string('Epoch %d test Accuracy: %f Class avg mIOU: %f Inctance avg mIOU: %f' % (
- epoch+1, test_metrics['accuracy'],test_metrics['class_avg_iou'],test_metrics['inctance_avg_iou']))
- if (test_metrics['inctance_avg_iou'] >= best_inctance_avg_iou):
- logger.info('Save model...')
- savepath = str(checkpoints_dir) + '/best_model.pth'
- log_string('Saving at %s'% savepath)
- state = {
- 'epoch': epoch,
- 'train_acc': train_instance_acc,
- 'test_acc': test_metrics['accuracy'],
- 'class_avg_iou': test_metrics['class_avg_iou'],
- 'inctance_avg_iou': test_metrics['inctance_avg_iou'],
- 'model_state_dict': classifier.state_dict(),
- 'optimizer_state_dict': optimizer.state_dict(),
- }
- torch.save(state, savepath)
- log_string('Saving model....')
-
- if test_metrics['accuracy'] > best_acc:
- best_acc = test_metrics['accuracy']
- if test_metrics['class_avg_iou'] > best_class_avg_iou:
- best_class_avg_iou = test_metrics['class_avg_iou']
- if test_metrics['inctance_avg_iou'] > best_inctance_avg_iou:
- best_inctance_avg_iou = test_metrics['inctance_avg_iou']
- log_string('Best accuracy is: %.5f'%best_acc)
- log_string('Best class avg mIOU is: %.5f'%best_class_avg_iou)
- log_string('Best inctance avg mIOU is: %.5f'%best_inctance_avg_iou)
- global_epoch+=1
-
- if __name__ == '__main__':
- args = parse_args()
- main(args)
-
(3)train_semseg.py
- """
- Author: Benny
- Date: Nov 2019
- """
- import argparse
- import os
- from data_utils.S3DISDataLoader import S3DISDataset
- import torch
- import datetime
- import logging
- from pathlib import Path
- import sys
- import importlib
- import shutil
- from tqdm import tqdm
- import provider
- import numpy as np
- import time
-
- BASE_DIR = os.path.dirname(os.path.abspath(__file__))
- ROOT_DIR = BASE_DIR
- sys.path.append(os.path.join(ROOT_DIR, 'models'))
-
-
- classes = ['ceiling','floor','wall','beam','column','window','door','table','chair','sofa','bookcase','board','clutter']
- class2label = {cls: i for i,cls in enumerate(classes)}
- seg_classes = class2label
- seg_label_to_cat = {}
- for i,cat in enumerate(seg_classes.keys()):
- seg_label_to_cat[i] = cat
-
-
- def parse_args():
- parser = argparse.ArgumentParser('Model')
- parser.add_argument('--model', type=str, default='pointnet_sem_seg', help='model name [default: pointnet_sem_seg]')
- parser.add_argument('--batch_size', type=int, default=16, help='Batch Size during training [default: 16]')
- parser.add_argument('--epoch', default=128, type=int, help='Epoch to run [default: 128]')
- parser.add_argument('--learning_rate', default=0.001, type=float, help='Initial learning rate [default: 0.001]')
- parser.add_argument('--gpu', type=str, default='0', help='GPU to use [default: GPU 0]')
- parser.add_argument('--optimizer', type=str, default='Adam', help='Adam or SGD [default: Adam]')
- parser.add_argument('--log_dir', type=str, default=None, help='Log path [default: None]')
- parser.add_argument('--decay_rate', type=float, default=1e-4, help='weight decay [default: 1e-4]')
- parser.add_argument('--npoint', type=int, default=4096, help='Point Number [default: 4096]')
- parser.add_argument('--step_size', type=int, default=10, help='Decay step for lr decay [default: every 10 epochs]')
- parser.add_argument('--lr_decay', type=float, default=0.7, help='Decay rate for lr decay [default: 0.7]')
- parser.add_argument('--test_area', type=int, default=5, help='Which area to use for test, option: 1-6 [default: 5]')
-
- return parser.parse_args()
-
- def main(args):
- def log_string(str):
- logger.info(str)
- print(str)
-
- '''HYPER PARAMETER'''
- os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
-
- '''CREATE DIR'''
- timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M'))
- experiment_dir = Path('./log/')
- experiment_dir.mkdir(exist_ok=True)
- experiment_dir = experiment_dir.joinpath('sem_seg')
- experiment_dir.mkdir(exist_ok=True)
- if args.log_dir is None:
- experiment_dir = experiment_dir.joinpath(timestr)
- else:
- experiment_dir = experiment_dir.joinpath(args.log_dir)
- experiment_dir.mkdir(exist_ok=True)
- checkpoints_dir = experiment_dir.joinpath('checkpoints/')
- checkpoints_dir.mkdir(exist_ok=True)
- log_dir = experiment_dir.joinpath('logs/')
- log_dir.mkdir(exist_ok=True)
-
- '''LOG'''
- args = parse_args()
- logger = logging.getLogger("Model")
- logger.setLevel(logging.INFO)
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
- file_handler = logging.FileHandler('%s/%s.txt' % (log_dir, args.model))
- file_handler.setLevel(logging.INFO)
- file_handler.setFormatter(formatter)
- logger.addHandler(file_handler)
- log_string('PARAMETER ...')
- log_string(args)
-
- root = 'data/stanford_indoor3d/'
- NUM_CLASSES = 13
- NUM_POINT = args.npoint
- BATCH_SIZE = args.batch_size
-
- print("start loading training data ...")
- TRAIN_DATASET = S3DISDataset(split='train', data_root=root, num_point=NUM_POINT, test_area=args.test_area, block_size=1.0, sample_rate=1.0, transform=None)
- print("start loading test data ...")
- TEST_DATASET = S3DISDataset(split='test', data_root=root, num_point=NUM_POINT, test_area=args.test_area, block_size=1.0, sample_rate=1.0, transform=None)
- trainDataLoader = torch.utils.data.DataLoader(TRAIN_DATASET, batch_size=BATCH_SIZE, shuffle=True, num_workers=0, pin_memory=True, drop_last=True, worker_init_fn = lambda x: np.random.seed(x+int(time.time())))
- testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=BATCH_SIZE, shuffle=False, num_workers=0, pin_memory=True, drop_last=True)
- weights = torch.Tensor(TRAIN_DATASET.labelweights).cuda()
-
- log_string("The number of training data is: %d" % len(TRAIN_DATASET))
- log_string("The number of test data is: %d" % len(TEST_DATASET))
-
- '''MODEL LOADING'''
- MODEL = importlib.import_module(args.model)
- shutil.copy('models/%s.py' % args.model, str(experiment_dir))
- shutil.copy('models/pointnet_util.py', str(experiment_dir))
-
- classifier = MODEL.get_model(NUM_CLASSES).cuda()
- criterion = MODEL.get_loss().cuda()
-
- def weights_init(m):
- classname = m.__class__.__name__
- if classname.find('Conv2d') != -1:
- torch.nn.init.xavier_normal_(m.weight.data)
- torch.nn.init.constant_(m.bias.data, 0.0)
- elif classname.find('Linear') != -1:
- torch.nn.init.xavier_normal_(m.weight.data)
- torch.nn.init.constant_(m.bias.data, 0.0)
-
- try:
- checkpoint = torch.load(str(experiment_dir) + '/checkpoints/best_model.pth')
- start_epoch = checkpoint['epoch']
- classifier.load_state_dict(checkpoint['model_state_dict'])
- log_string('Use pretrain model')
- except:
- log_string('No existing model, starting training from scratch...')
- start_epoch = 0
- classifier = classifier.apply(weights_init)
-
- if args.optimizer == 'Adam':
- optimizer = torch.optim.Adam(
- classifier.parameters(),
- lr=args.learning_rate,
- betas=(0.9, 0.999),
- eps=1e-08,
- weight_decay=args.decay_rate
- )
- else:
- optimizer = torch.optim.SGD(classifier.parameters(), lr=args.learning_rate, momentum=0.9)
-
- def bn_momentum_adjust(m, momentum):
- if isinstance(m, torch.nn.BatchNorm2d) or isinstance(m, torch.nn.BatchNorm1d):
- m.momentum = momentum
-
- LEARNING_RATE_CLIP = 1e-5
- MOMENTUM_ORIGINAL = 0.1
- MOMENTUM_DECCAY = 0.5
- MOMENTUM_DECCAY_STEP = args.step_size
-
- global_epoch = 0
- best_iou = 0
-
- for epoch in range(start_epoch,args.epoch):
- '''Train on chopped scenes'''
- log_string('**** Epoch %d (%d/%s) ****' % (global_epoch + 1, epoch + 1, args.epoch))
- lr = max(args.learning_rate * (args.lr_decay ** (epoch // args.step_size)), LEARNING_RATE_CLIP)
- log_string('Learning rate:%f' % lr)
- for param_group in optimizer.param_groups:
- param_group['lr'] = lr
- momentum = MOMENTUM_ORIGINAL * (MOMENTUM_DECCAY ** (epoch // MOMENTUM_DECCAY_STEP))
- if momentum < 0.01:
- momentum = 0.01
- print('BN momentum updated to: %f' % momentum)
- classifier = classifier.apply(lambda x: bn_momentum_adjust(x,momentum))
- num_batches = len(trainDataLoader)
- total_correct = 0
- total_seen = 0
- loss_sum = 0
- for i, data in tqdm(enumerate(trainDataLoader), total=len(trainDataLoader), smoothing=0.9):
- points, target = data
- points = points.data.numpy()
- points[:,:, :3] = provider.rotate_point_cloud_z(points[:,:, :3])
- points = torch.Tensor(points)
- points, target = points.float().cuda(),target.long().cuda()
- points = points.transpose(2, 1)
- optimizer.zero_grad()
- classifier = classifier.train()
- seg_pred, trans_feat = classifier(points)
- seg_pred = seg_pred.contiguous().view(-1, NUM_CLASSES)
- batch_label = target.view(-1, 1)[:, 0].cpu().data.numpy()
- target = target.view(-1, 1)[:, 0]
- loss = criterion(seg_pred, target, trans_feat, weights)
- loss.backward()
- optimizer.step()
- pred_choice = seg_pred.cpu().data.max(1)[1].numpy()
- correct = np.sum(pred_choice == batch_label)
- total_correct += correct
- total_seen += (BATCH_SIZE * NUM_POINT)
- loss_sum += loss
- log_string('Training mean loss: %f' % (loss_sum / num_batches))
- log_string('Training accuracy: %f' % (total_correct / float(total_seen)))
-
- if epoch % 5 == 0:
- logger.info('Save model...')
- savepath = str(checkpoints_dir) + '/model.pth'
- log_string('Saving at %s' % savepath)
- state = {
- 'epoch': epoch,
- 'model_state_dict': classifier.state_dict(),
- 'optimizer_state_dict': optimizer.state_dict(),
- }
- torch.save(state, savepath)
- log_string('Saving model....')
-
- '''Evaluate on chopped scenes'''
- with torch.no_grad():
- num_batches = len(testDataLoader)
- total_correct = 0
- total_seen = 0
- loss_sum = 0
- labelweights = np.zeros(NUM_CLASSES)
- total_seen_class = [0 for _ in range(NUM_CLASSES)]
- total_correct_class = [0 for _ in range(NUM_CLASSES)]
- total_iou_deno_class = [0 for _ in range(NUM_CLASSES)]
- log_string('---- EPOCH %03d EVALUATION ----' % (global_epoch + 1))
- for i, data in tqdm(enumerate(testDataLoader), total=len(testDataLoader), smoothing=0.9):
- points, target = data
- points = points.data.numpy()
- points = torch.Tensor(points)
- points, target = points.float().cuda(), target.long().cuda()
- # device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- # print("Using device:", device)
- # classifier = classifier.to(device)
- # points, target = points.float().to(device), target.long().to(device)
-
- points = points.transpose(2, 1)
- classifier = classifier.eval()
- seg_pred, trans_feat = classifier(points)
- pred_val = seg_pred.contiguous().cpu().data.numpy()
- seg_pred = seg_pred.contiguous().view(-1, NUM_CLASSES)
- batch_label = target.cpu().data.numpy()
- target = target.view(-1, 1)[:, 0]
- loss = criterion(seg_pred, target, trans_feat, weights)
- loss_sum += loss
- pred_val = np.argmax(pred_val, 2)
- correct = np.sum((pred_val == batch_label))
- total_correct += correct
- total_seen += (BATCH_SIZE * NUM_POINT)
- tmp, _ = np.histogram(batch_label, range(NUM_CLASSES + 1))
- labelweights += tmp
- for l in range(NUM_CLASSES):
- total_seen_class[l] += np.sum((batch_label == l) )
- total_correct_class[l] += np.sum((pred_val == l) & (batch_label == l) )
- total_iou_deno_class[l] += np.sum(((pred_val == l) | (batch_label == l)) )
- labelweights = labelweights.astype(np.float32) / np.sum(labelweights.astype(np.float32))
- mIoU = np.mean(np.array(total_correct_class) / (np.array(total_iou_deno_class, dtype=np.float) + 1e-6))
- log_string('eval mean loss: %f' % (loss_sum / float(num_batches)))
- log_string('eval point avg class IoU: %f' % (mIoU))
- log_string('eval point accuracy: %f' % (total_correct / float(total_seen)))
- log_string('eval point avg class acc: %f' % (
- np.mean(np.array(total_correct_class) / (np.array(total_seen_class, dtype=np.float) + 1e-6))))
- iou_per_class_str = '------- IoU --------\n'
- for l in range(NUM_CLASSES):
- iou_per_class_str += 'class %s weight: %.3f, IoU: %.3f \n' % (
- seg_label_to_cat[l] + ' ' * (14 - len(seg_label_to_cat[l])), labelweights[l - 1],
- total_correct_class[l] / float(total_iou_deno_class[l]))
-
- log_string(iou_per_class_str)
- log_string('Eval mean loss: %f' % (loss_sum / num_batches))
- log_string('Eval accuracy: %f' % (total_correct / float(total_seen)))
- if mIoU >= best_iou:
- best_iou = mIoU
- logger.info('Save model...')
- savepath = str(checkpoints_dir) + '/best_model.pth'
- log_string('Saving at %s' % savepath)
- state = {
- 'epoch': epoch,
- 'class_avg_iou': mIoU,
- 'model_state_dict': classifier.state_dict(),
- 'optimizer_state_dict': optimizer.state_dict(),
- }
- torch.save(state, savepath)
- log_string('Saving model....')
- log_string('Best mIoU: %f' % best_iou)
- global_epoch += 1
-
-
- if __name__ == '__main__':
- args = parse_args()
- main(args)
-
(4)test_cls.py
- from data_utils.ModelNetDataLoader import ModelNetDataLoader
- import argparse
- import numpy as np
- import os
- import torch
- import logging
- from tqdm import tqdm
- import sys
- import importlib
-
- BASE_DIR = os.path.dirname(os.path.abspath(__file__))
- ROOT_DIR = BASE_DIR
- sys.path.append(os.path.join(ROOT_DIR, 'models'))
-
- """
- 配置参数:
- --normal
- --log_dir pointnet2_cls_msg
- """
-
- def parse_args():
- '''PARAMETERS'''
- parser = argparse.ArgumentParser('PointNet')
- parser.add_argument('--batch_size', type=int, default=24, help='batch size in training')
- parser.add_argument('--gpu', type=str, default='0', help='specify gpu device')
- parser.add_argument('--num_point', type=int, default=1024, help='Point Number [default: 1024]')
- parser.add_argument('--log_dir', type=str, default='pointnet2_ssg_normal', help='Experiment root')
- parser.add_argument('--normal', action='store_true', default=True, help='Whether to use normal information [default: False]')
- parser.add_argument('--num_votes', type=int, default=3, help='Aggregate classification scores with voting [default: 3]')
- return parser.parse_args()
-
- def test(model, loader, num_class=40, vote_num=1):
- mean_correct = []
- class_acc = np.zeros((num_class,3))
- for j, data in tqdm(enumerate(loader), total=len(loader)):
- points, target = data
- target = target[:, 0]
- points = points.transpose(2, 1)
- points, target = points.cuda(), target.cuda()
- classifier = model.eval()
- vote_pool = torch.zeros(target.size()[0],num_class).cuda()
- for _ in range(vote_num):
- pred, _ = classifier(points)
- vote_pool += pred
- pred = vote_pool/vote_num
- pred_choice = pred.data.max(1)[1]
- for cat in np.unique(target.cpu()):
- classacc = pred_choice[target==cat].eq(target[target==cat].long().data).cpu().sum()
- class_acc[cat,0]+= classacc.item()/float(points[target==cat].size()[0])
- class_acc[cat,1]+=1
- correct = pred_choice.eq(target.long().data).cpu().sum()
- mean_correct.append(correct.item()/float(points.size()[0]))
- class_acc[:,2] = class_acc[:,0]/ class_acc[:,1]
- class_acc = np.mean(class_acc[:,2])
- instance_acc = np.mean(mean_correct)
- return instance_acc, class_acc
-
-
- def main(args):
- def log_string(str):
- logger.info(str)
- print(str)
-
- '''HYPER PARAMETER'''
- os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
-
- '''CREATE DIR'''
- experiment_dir = 'log/classification/' + args.log_dir
-
- '''LOG'''
- args = parse_args()
- logger = logging.getLogger("Model")
- logger.setLevel(logging.INFO)
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
- file_handler = logging.FileHandler('%s/eval.txt' % experiment_dir)
- file_handler.setLevel(logging.INFO)
- file_handler.setFormatter(formatter)
- logger.addHandler(file_handler)
- log_string('PARAMETER ...')
- log_string(args)
-
- '''DATA LOADING'''
- log_string('Load dataset ...')
- DATA_PATH = 'data/modelnet40_normal_resampled/'
- TEST_DATASET = ModelNetDataLoader(root=DATA_PATH, npoint=args.num_point, split='test', normal_channel=args.normal)
- testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=args.batch_size, shuffle=False, num_workers=4)
-
- '''MODEL LOADING'''
- num_class = 40
- model_name = os.listdir(experiment_dir+'/logs')[0].split('.')[0]
- MODEL = importlib.import_module(model_name)
-
- classifier = MODEL.get_model(num_class,normal_channel=args.normal).cuda()
-
- checkpoint = torch.load(str(experiment_dir) + '/checkpoints/best_model.pth')
- classifier.load_state_dict(checkpoint['model_state_dict'])
-
- with torch.no_grad():
- instance_acc, class_acc = test(classifier.eval(), testDataLoader, vote_num=args.num_votes)
- log_string('Test Instance Accuracy: %f, Class Accuracy: %f' % (instance_acc, class_acc))
-
-
-
- if __name__ == '__main__':
- args = parse_args()
- main(args)
(5)test_partseg.py
- """
- Author: Benny
- Date: Nov 2019
- """
- import argparse
- import os
- from data_utils.ShapeNetDataLoader import PartNormalDataset
- import torch
- import logging
- import sys
- import importlib
- from tqdm import tqdm
- import numpy as np
-
- BASE_DIR = os.path.dirname(os.path.abspath(__file__))
- ROOT_DIR = BASE_DIR
- sys.path.append(os.path.join(ROOT_DIR, 'models'))
-
- seg_classes = {'Earphone': [16, 17, 18], 'Motorbike': [30, 31, 32, 33, 34, 35], 'Rocket': [41, 42, 43], 'Car': [8, 9, 10, 11], 'Laptop': [28, 29], 'Cap': [6, 7], 'Skateboard': [44, 45, 46], 'Mug': [36, 37], 'Guitar': [19, 20, 21], 'Bag': [4, 5], 'Lamp': [24, 25, 26, 27], 'Table': [47, 48, 49], 'Airplane': [0, 1, 2, 3], 'Pistol': [38, 39, 40], 'Chair': [12, 13, 14, 15], 'Knife': [22, 23]}
- seg_label_to_cat = {} # {0:Airplane, 1:Airplane, ...49:Table}
- for cat in seg_classes.keys():
- for label in seg_classes[cat]:
- seg_label_to_cat[label] = cat
-
- def to_categorical(y, num_classes):
- """ 1-hot encodes a tensor """
- new_y = torch.eye(num_classes)[y.cpu().data.numpy(),]
- if (y.is_cuda):
- return new_y.cuda()
- return new_y
-
-
- def parse_args():
- '''PARAMETERS'''
- parser = argparse.ArgumentParser('PointNet')
- parser.add_argument('--batch_size', type=int, default=24, help='batch size in testing [default: 24]')
- parser.add_argument('--gpu', type=str, default='0', help='specify gpu device [default: 0]')
- # parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
- parser.add_argument('--num_point', type=int, default=2048, help='Point Number [default: 2048]')
- parser.add_argument('--log_dir', type=str, default='pointnet2_part_seg_ssg', help='Experiment root')
- # parser.add_argument('--log_dir', type=str, default='visual', help='Experiment root')
- parser.add_argument('--normal', action='store_true', default=False, help='Whether to use normal information [default: False]')
- parser.add_argument('--num_votes', type=int, default=3, help='Aggregate segmentation scores with voting [default: 3]')
- return parser.parse_args()
-
- def main(args):
- def log_string(str):
- logger.info(str)
- print(str)
-
- '''HYPER PARAMETER'''
- os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
- experiment_dir = 'log/part_seg/' + args.log_dir
-
- '''LOG'''
- args = parse_args()
- logger = logging.getLogger("Model")
- logger.setLevel(logging.INFO)
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
- file_handler = logging.FileHandler('%s/eval.txt' % experiment_dir)
- file_handler.setLevel(logging.INFO)
- file_handler.setFormatter(formatter)
- logger.addHandler(file_handler)
- log_string('PARAMETER ...')
- log_string(args)
-
- root = 'data/shapenetcore_partanno_segmentation_benchmark_v0_normal/'
-
- TEST_DATASET = PartNormalDataset(root = root, npoints=args.num_point, split='test', normal_channel=args.normal)
- testDataLoader = torch.utils.data.DataLoader(TEST_DATASET, batch_size=args.batch_size,shuffle=False, num_workers=4)
- log_string("The number of test data is: %d" % len(TEST_DATASET))
- num_classes = 16
- num_part = 50
-
- '''MODEL LOADING'''
- model_name = os.listdir(experiment_dir+'/logs')[0].split('.')[0]
- MODEL = importlib.import_module(model_name)
- classifier = MODEL.get_model(num_part, normal_channel=args.normal).cuda()
- checkpoint = torch.load(str(experiment_dir) + '/checkpoints/best_model.pth')
- classifier.load_state_dict(checkpoint['model_state_dict'])
-
-
- with torch.no_grad():
- test_metrics = {}
- total_correct = 0
- total_seen = 0
- total_seen_class = [0 for _ in range(num_part)]
- total_correct_class = [0 for _ in range(num_part)]
- shape_ious = {cat: [] for cat in seg_classes.keys()}
- seg_label_to_cat = {} # {0:Airplane, 1:Airplane, ...49:Table}
- for cat in seg_classes.keys():
- for label in seg_classes[cat]:
- seg_label_to_cat[label] = cat
-
- for batch_id, (points, label, target) in tqdm(enumerate(testDataLoader), total=len(testDataLoader), smoothing=0.9):
- batchsize, num_point, _ = points.size()
- cur_batch_size, NUM_POINT, _ = points.size()
- points, label, target = points.float().cuda(), label.long().cuda(), target.long().cuda()
- points = points.transpose(2, 1)
- classifier = classifier.eval()
- vote_pool = torch.zeros(target.size()[0], target.size()[1], num_part).cuda()
- for _ in range(args.num_votes):
- seg_pred, _ = classifier(points, to_categorical(label, num_classes))
- vote_pool += seg_pred
- seg_pred = vote_pool / args.num_votes
- cur_pred_val = seg_pred.cpu().data.numpy()
- cur_pred_val_logits = cur_pred_val
- cur_pred_val = np.zeros((cur_batch_size, NUM_POINT)).astype(np.int32)
- target = target.cpu().data.numpy()
- for i in range(cur_batch_size):
- cat = seg_label_to_cat[target[i, 0]]
- logits = cur_pred_val_logits[i, :, :]
- cur_pred_val[i, :] = np.argmax(logits[:, seg_classes[cat]], 1) + seg_classes[cat][0]
- correct = np.sum(cur_pred_val == target)
- total_correct += correct
- total_seen += (cur_batch_size * NUM_POINT)
-
- for l in range(num_part):
- total_seen_class[l] += np.sum(target == l)
- total_correct_class[l] += (np.sum((cur_pred_val == l) & (target == l)))
-
- for i in range(cur_batch_size):
- segp = cur_pred_val[i, :]
- segl = target[i, :]
- cat = seg_label_to_cat[segl[0]]
- part_ious = [0.0 for _ in range(len(seg_classes[cat]))]
- for l in seg_classes[cat]:
- if (np.sum(segl == l) == 0) and (
- np.sum(segp == l) == 0): # part is not present, no prediction as well
- part_ious[l - seg_classes[cat][0]] = 1.0
- else:
- part_ious[l - seg_classes[cat][0]] = np.sum((segl == l) & (segp == l)) / float(
- np.sum((segl == l) | (segp == l)))
- shape_ious[cat].append(np.mean(part_ious))
-
- all_shape_ious = []
- for cat in shape_ious.keys():
- for iou in shape_ious[cat]:
- all_shape_ious.append(iou)
- shape_ious[cat] = np.mean(shape_ious[cat])
- mean_shape_ious = np.mean(list(shape_ious.values()))
- test_metrics['accuracy'] = total_correct / float(total_seen)
- test_metrics['class_avg_accuracy'] = np.mean(
- np.array(total_correct_class) / np.array(total_seen_class, dtype=np.float))
- for cat in sorted(shape_ious.keys()):
- log_string('eval mIoU of %s %f' % (cat + ' ' * (14 - len(cat)), shape_ious[cat]))
- test_metrics['class_avg_iou'] = mean_shape_ious
- test_metrics['inctance_avg_iou'] = np.mean(all_shape_ious)
-
-
- log_string('Accuracy is: %.5f'%test_metrics['accuracy'])
- log_string('Class avg accuracy is: %.5f'%test_metrics['class_avg_accuracy'])
- log_string('Class avg mIOU is: %.5f'%test_metrics['class_avg_iou'])
- log_string('Inctance avg mIOU is: %.5f'%test_metrics['inctance_avg_iou'])
-
- if __name__ == '__main__':
- args = parse_args()
- main(args)
-
(6)test_semseg.py
- """
- Author: Benny
- Date: Nov 2019
- """
- import argparse
- import os
- from data_utils.S3DISDataLoader import ScannetDatasetWholeScene
- from data_utils.indoor3d_util import g_label2color
- import torch
- import logging
- from pathlib import Path
- import sys
- import importlib
- from tqdm import tqdm
- import provider
- import numpy as np
-
- BASE_DIR = os.path.dirname(os.path.abspath(__file__))
- ROOT_DIR = BASE_DIR
- sys.path.append(os.path.join(ROOT_DIR, 'models'))
-
- classes = ['ceiling','floor','wall','beam','column','window','door','table','chair','sofa','bookcase','board','clutter']
- class2label = {cls: i for i,cls in enumerate(classes)}
- seg_classes = class2label
- seg_label_to_cat = {}
- for i,cat in enumerate(seg_classes.keys()):
- seg_label_to_cat[i] = cat
-
- def parse_args():
- '''PARAMETERS'''
- parser = argparse.ArgumentParser('Model')
- parser.add_argument('--batch_size', type=int, default=32, help='batch size in testing [default: 32]')
- parser.add_argument('--gpu', type=str, default='0', help='specify gpu device')
- parser.add_argument('--num_point', type=int, default=4096, help='Point Number [default: 4096]')
- parser.add_argument('--log_dir', type=str, default='pointnet2_sem_seg', help='Experiment root')
- parser.add_argument('--visual', action='store_true', default=True, help='Whether visualize result [default: False]')
- parser.add_argument('--test_area', type=int, default=5, help='Which area to use for test, option: 1-6 [default: 5]')
- parser.add_argument('--num_votes', type=int, default=5, help='Aggregate segmentation scores with voting [default: 5]')
- return parser.parse_args()
-
- def add_vote(vote_label_pool, point_idx, pred_label, weight):
- B = pred_label.shape[0]
- N = pred_label.shape[1]
- for b in range(B):
- for n in range(N):
- if weight[b,n]:
- vote_label_pool[int(point_idx[b, n]), int(pred_label[b, n])] += 1
- return vote_label_pool
-
- def main(args):
- def log_string(str):
- logger.info(str)
- print(str)
-
- '''HYPER PARAMETER'''
- os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
- experiment_dir = 'log/sem_seg/' + args.log_dir
- visual_dir = experiment_dir + '/visual/'
- visual_dir = Path(visual_dir)
- visual_dir.mkdir(exist_ok=True)
-
- '''LOG'''
- args = parse_args()
- logger = logging.getLogger("Model")
- logger.setLevel(logging.INFO)
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
- file_handler = logging.FileHandler('%s/eval.txt' % experiment_dir)
- file_handler.setLevel(logging.INFO)
- file_handler.setFormatter(formatter)
- logger.addHandler(file_handler)
- log_string('PARAMETER ...')
- log_string(args)
-
- NUM_CLASSES = 13
- BATCH_SIZE = args.batch_size
- NUM_POINT = args.num_point
-
- root = 'data/stanford_indoor3d/'
-
- TEST_DATASET_WHOLE_SCENE = ScannetDatasetWholeScene(root, split='test', test_area=args.test_area, block_points=NUM_POINT)
- log_string("The number of test data is: %d" % len(TEST_DATASET_WHOLE_SCENE))
-
- '''MODEL LOADING'''
- model_name = os.listdir(experiment_dir+'/logs')[0].split('.')[0]
- MODEL = importlib.import_module(model_name)
- classifier = MODEL.get_model(NUM_CLASSES).cuda()
- checkpoint = torch.load(str(experiment_dir) + '/checkpoints/best_model.pth')
- classifier.load_state_dict(checkpoint['model_state_dict'])
-
- with torch.no_grad():
- scene_id = TEST_DATASET_WHOLE_SCENE.file_list
- scene_id = [x[:-4] for x in scene_id]
- num_batches = len(TEST_DATASET_WHOLE_SCENE)
-
- total_seen_class = [0 for _ in range(NUM_CLASSES)]
- total_correct_class = [0 for _ in range(NUM_CLASSES)]
- total_iou_deno_class = [0 for _ in range(NUM_CLASSES)]
-
- log_string('---- EVALUATION WHOLE SCENE----')
-
- for batch_idx in range(num_batches):
- print("visualize [%d/%d] %s ..." % (batch_idx+1, num_batches, scene_id[batch_idx]))
- total_seen_class_tmp = [0 for _ in range(NUM_CLASSES)]
- total_correct_class_tmp = [0 for _ in range(NUM_CLASSES)]
- total_iou_deno_class_tmp = [0 for _ in range(NUM_CLASSES)]
- if args.visual:
- fout = open(os.path.join(visual_dir, scene_id[batch_idx] + '_pred.obj'), 'w')
- fout_gt = open(os.path.join(visual_dir, scene_id[batch_idx] + '_gt.obj'), 'w')
-
- whole_scene_data = TEST_DATASET_WHOLE_SCENE.scene_points_list[batch_idx]
- whole_scene_label = TEST_DATASET_WHOLE_SCENE.semantic_labels_list[batch_idx]
- vote_label_pool = np.zeros((whole_scene_label.shape[0], NUM_CLASSES))
- for _ in tqdm(range(args.num_votes), total=args.num_votes):
- scene_data, scene_label, scene_smpw, scene_point_index = TEST_DATASET_WHOLE_SCENE[batch_idx]
- num_blocks = scene_data.shape[0]
- s_batch_num = (num_blocks + BATCH_SIZE - 1) // BATCH_SIZE
- batch_data = np.zeros((BATCH_SIZE, NUM_POINT, 9))
-
- batch_label = np.zeros((BATCH_SIZE, NUM_POINT))
- batch_point_index = np.zeros((BATCH_SIZE, NUM_POINT))
- batch_smpw = np.zeros((BATCH_SIZE, NUM_POINT))
- for sbatch in range(s_batch_num):
- start_idx = sbatch * BATCH_SIZE
- end_idx = min((sbatch + 1) * BATCH_SIZE, num_blocks)
- real_batch_size = end_idx - start_idx
- batch_data[0:real_batch_size, ...] = scene_data[start_idx:end_idx, ...]
- batch_label[0:real_batch_size, ...] = scene_label[start_idx:end_idx, ...]
- batch_point_index[0:real_batch_size, ...] = scene_point_index[start_idx:end_idx, ...]
- batch_smpw[0:real_batch_size, ...] = scene_smpw[start_idx:end_idx, ...]
- batch_data[:, :, 3:6] /= 1.0
-
- torch_data = torch.Tensor(batch_data)
- torch_data= torch_data.float().cuda()
- torch_data = torch_data.transpose(2, 1)
- seg_pred, _ = classifier(torch_data)
- batch_pred_label = seg_pred.contiguous().cpu().data.max(2)[1].numpy()
-
- vote_label_pool = add_vote(vote_label_pool, batch_point_index[0:real_batch_size, ...],
- batch_pred_label[0:real_batch_size, ...],
- batch_smpw[0:real_batch_size, ...])
-
- pred_label = np.argmax(vote_label_pool, 1)
-
- for l in range(NUM_CLASSES):
- total_seen_class_tmp[l] += np.sum((whole_scene_label == l))
- total_correct_class_tmp[l] += np.sum((pred_label == l) & (whole_scene_label == l))
- total_iou_deno_class_tmp[l] += np.sum(((pred_label == l) | (whole_scene_label == l)))
- total_seen_class[l] += total_seen_class_tmp[l]
- total_correct_class[l] += total_correct_class_tmp[l]
- total_iou_deno_class[l] += total_iou_deno_class_tmp[l]
-
- iou_map = np.array(total_correct_class_tmp) / (np.array(total_iou_deno_class_tmp, dtype=np.float64) + 1e-6)
- print(iou_map)
- arr = np.array(total_seen_class_tmp)
- tmp_iou = np.mean(iou_map[arr != 0])
- log_string('Mean IoU of %s: %.4f' % (scene_id[batch_idx], tmp_iou))
- print('----------------------------')
-
- filename = os.path.join(visual_dir, scene_id[batch_idx] + '.txt')
- with open(filename, 'w') as pl_save:
- for i in pred_label:
- pl_save.write(str(int(i)) + '\n')
- pl_save.close()
- for i in range(whole_scene_label.shape[0]):
- color = g_label2color[pred_label[i]]
- color_gt = g_label2color[whole_scene_label[i]]
- if args.visual:
- fout.write('v %f %f %f %d %d %d\n' % (
- whole_scene_data[i, 0], whole_scene_data[i, 1], whole_scene_data[i, 2], color[0], color[1],
- color[2]))
- fout_gt.write(
- 'v %f %f %f %d %d %d\n' % (
- whole_scene_data[i, 0], whole_scene_data[i, 1], whole_scene_data[i, 2], color_gt[0],
- color_gt[1], color_gt[2]))
- if args.visual:
- fout.close()
- fout_gt.close()
-
- IoU = np.array(total_correct_class) / (np.array(total_iou_deno_class, dtype=np.float) + 1e-6)
- iou_per_class_str = '------- IoU --------\n'
- for l in range(NUM_CLASSES):
- iou_per_class_str += 'class %s, IoU: %.3f \n' % (
- seg_label_to_cat[l] + ' ' * (14 - len(seg_label_to_cat[l])),
- total_correct_class[l] / float(total_iou_deno_class[l]))
- log_string(iou_per_class_str)
- log_string('eval point avg class IoU: %f' % np.mean(IoU))
- log_string('eval whole scene point avg class acc: %f' % (
- np.mean(np.array(total_correct_class) / (np.array(total_seen_class, dtype=np.float) + 1e-6))))
- log_string('eval whole scene point accuracy: %f' % (
- np.sum(total_correct_class) / float(np.sum(total_seen_class) + 1e-6)))
-
- print("Done!")
-
- if __name__ == '__main__':
- args = parse_args()
- main(args)
上面这些都是调整好的代码应该是可以直接跑通的,如果哪个程序有问题可以粘贴我的程序过去试一试,注意一些文件路径要修改成自己的。
三、复现过程中遇到的问题总结
(1)首先把下面这些文件夹依次打开,你会发现导入的包被标红,因为路径不对
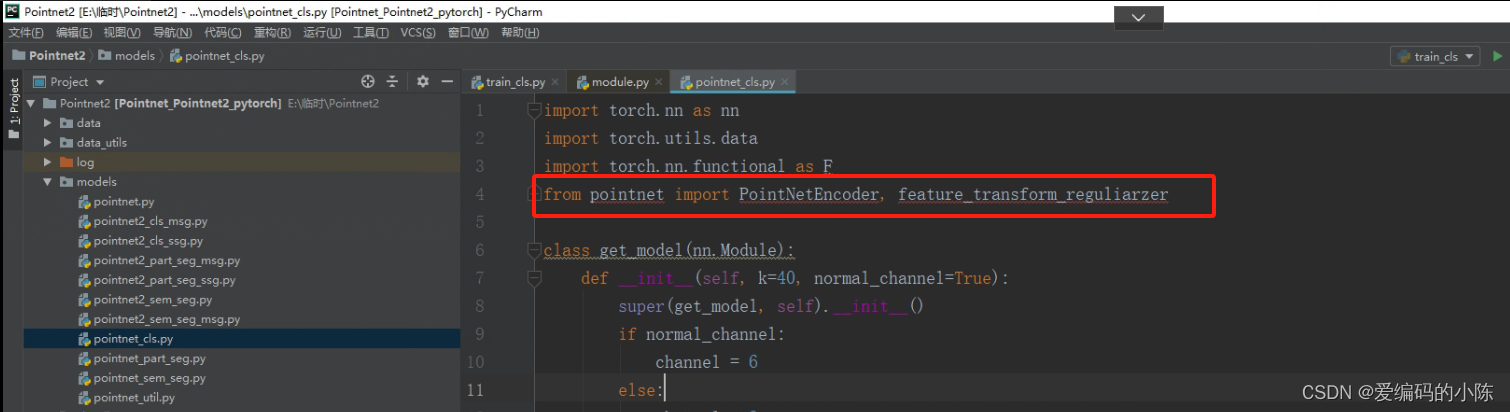
将下面
from pointnet import PointNetEncoder, feature_transform_reguliarzer修改为
from models.pointnet import PointNetEncoder, feature_transform_reguliarzermodels.是包含pointnet.py的文件夹,也就是说要精确到文件所在文件夹,系统才能正确找到,不报错,其他的脚本遇到这种情况类似处理
(2)报错:AttributeError: module ‘numpy‘ has no attribute ‘float‘
出现这个问题的原因是:从numpy1.24起删除了numpy.bool、numpy.int、numpy.float、numpy.complex、numpy.object、numpy.str、numpy.long、numpy.unicode类型的支持。解决上诉问题主要有两种方法:
方法一:修改numpy版本
安装numpy1.24之前的版本
- pip uninstall numpy
- pip install numpy==1.23.5
方法二:修改代码
可以用python内置类型或者np.ndarray类型替换:np.float替换为float或者np.float64/np.float32
参考链接:AttributeError: module ‘numpy‘ has no attribute ‘float‘
(3)报错:
choice = np.random.choice(len(point_set.shape[0]), npoints, replace=True) TypeError: object of type 'int' has no len()
将
choice = np.random.choice(len(point_set.shape[0]), npoints, replace=True)替换为
choice = np.random.choice(point_set.shape[0], npoints, replace=True)
(4)报错:
return F.conv1d(input, weight, bias, self.stride, RuntimeError: Given groups=1, weight of size [64, 6, 1], expected input[16, 9, 4096] to have 6 channels, but got 9 channels instead
上面是复现时运行train_semseg.py报错RuntimeError:
-
该个错误主要是因为S3DIS数据集的数据具有9个通道,涉及xyz、rgb和归一化XYZ。但是代码仅支持 3 或 6 个通道。要解决此问题,应进行一些小的修改。
1 pointnet_sem_seg.py;通过添加 if来考虑通道 =9 的情况。with_normalized_xyz params
- class get_model(nn.Module):
- def __init__(self, num_class, with_rgb=True, with_normalized_xyz=True):
- super(get_model, self).__init__()
- if with_rgb:
- channel = 6
- if with_normalized_xyz:
- channel= 9
- else:
- ...
2 pointnet.py;更改 PointNetEncoder 的前向方法,稍微修改拆分方法
- def forward(self, x):
- B, D, N = x.size() # batchsize,3(xyz坐标)或6(xyz坐标+法向量),1024(一个物体所取的点的数目)
- trans = self.stn(x) # STN3d T-Net
- x = x.transpose(2, 1) # 交换一个tensor的两个维度
- if D >3 :
- # x, feature = x.split(3,dim=2)
- x, feature = x.split([3,D-3],dim=2)
3 这样就可以解决S3DIS数据集在pointnet++训练时的场景分割报错了。
参考自:pointnet++复现时运行train_semseg.py报错RuntimeError:
(5)报错
return open(self.baseFilename, self.mode, encoding=self.encoding)
PermissionError: [Errno 13] Permission denied: 'D:\\cs\\Pointnet2\\log\\part_seg\\pointnet2_part_seg_ssg\\eval.txt'
或
model_name = os.listdir(experiment_dir+'/logs')[0].split('.')[0]
IndexError: list index out of range
这是因为该路径下没有这个名称的文件夹或者文件夹名称不对,我一开始就是文件夹名字写错了,应该是ssg我写成了msg所以一直报错
要有这个文件夹
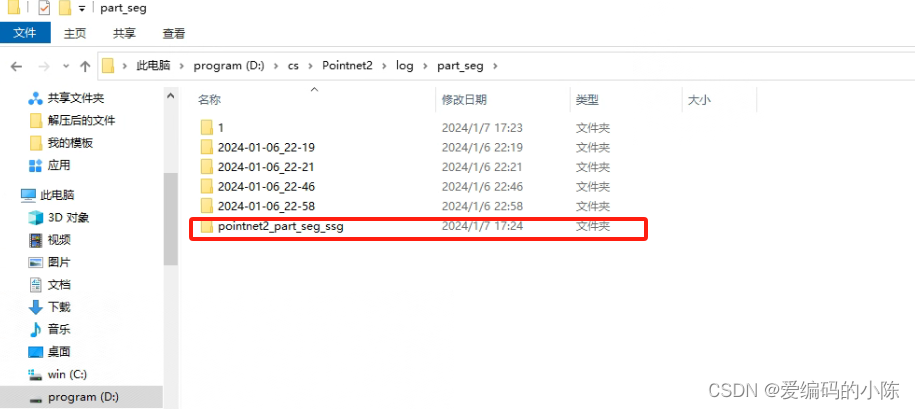
文件夹里要有这些文件
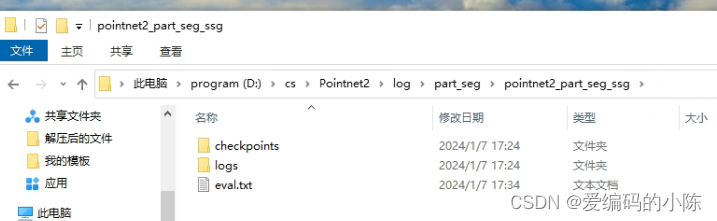
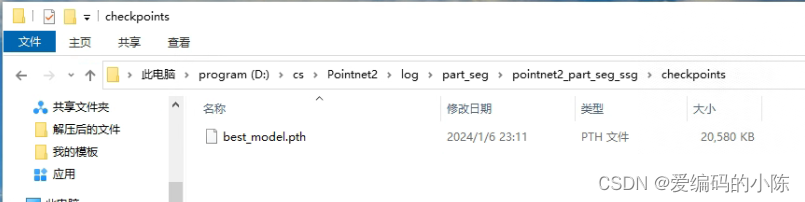
如果没有的话可以从以往的2024-01-06_22-21记录中复制过来,实在不行建立内容为空的文件,但是一定要让系统在搜索路径的时候能找到
(6)FileNotFoundError: [WinError 3] 系统找不到指定的路径的解决方法
判断文件的父子目录设置是否正确
可参考:FileNotFoundError: [WinError 3] 系统找不到指定的路径。的解决方法
(7)self = reduction.pickle.load(from_parent) EOFError: Ran out of input的解决方法
这是在运行train_semseg.py程序时遇到的错误
将num_workers改为0即可
修改前
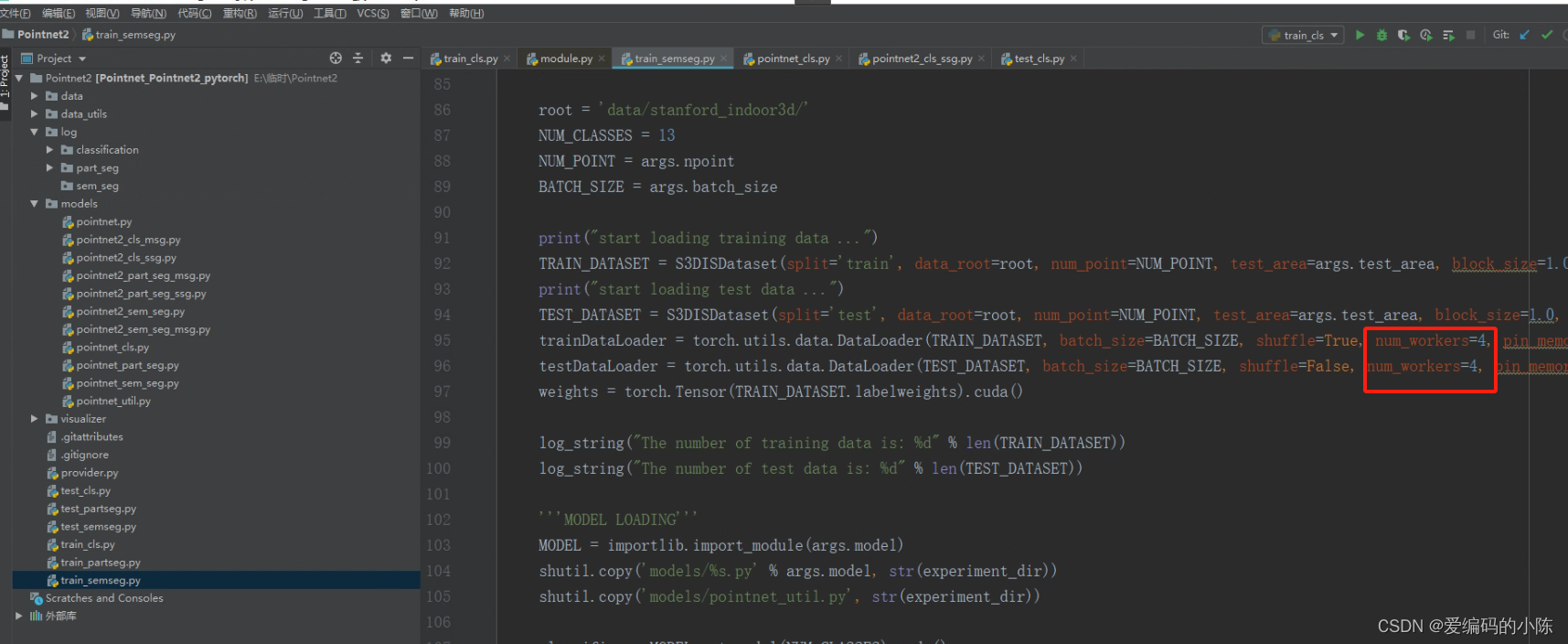
修改后
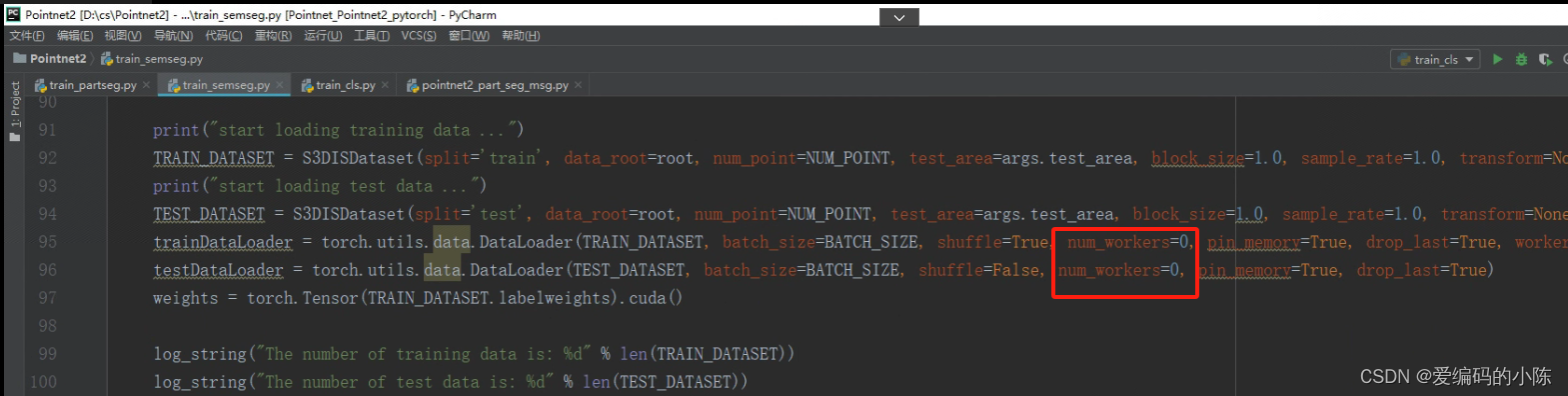
参考:self = reduction.pickle.load(from_parent) EOFError: Ran out of input的解决方法
(8)报错
rooms = sorted(os.listdir(data_root))
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'data/stanford_indoor3d/'

这是因为我们的data文件夹里还没有stanford_indoor3d这个文件夹,这是个数据集,需要我们先运行个脚本生成
下载 3D indoor parsing dataset ( S3DIS ) 数据集 Stanford3dDataset_v1.2_Aligned_Version.zip 并解压 到 data/s3dis/Stanford3dDataset_v1.2_Aligned_Version/ ,首先需要进行的是预处理工作:
- cd data_utils
- python collect_indoor3d_data.py
或者在Pycharm中运行
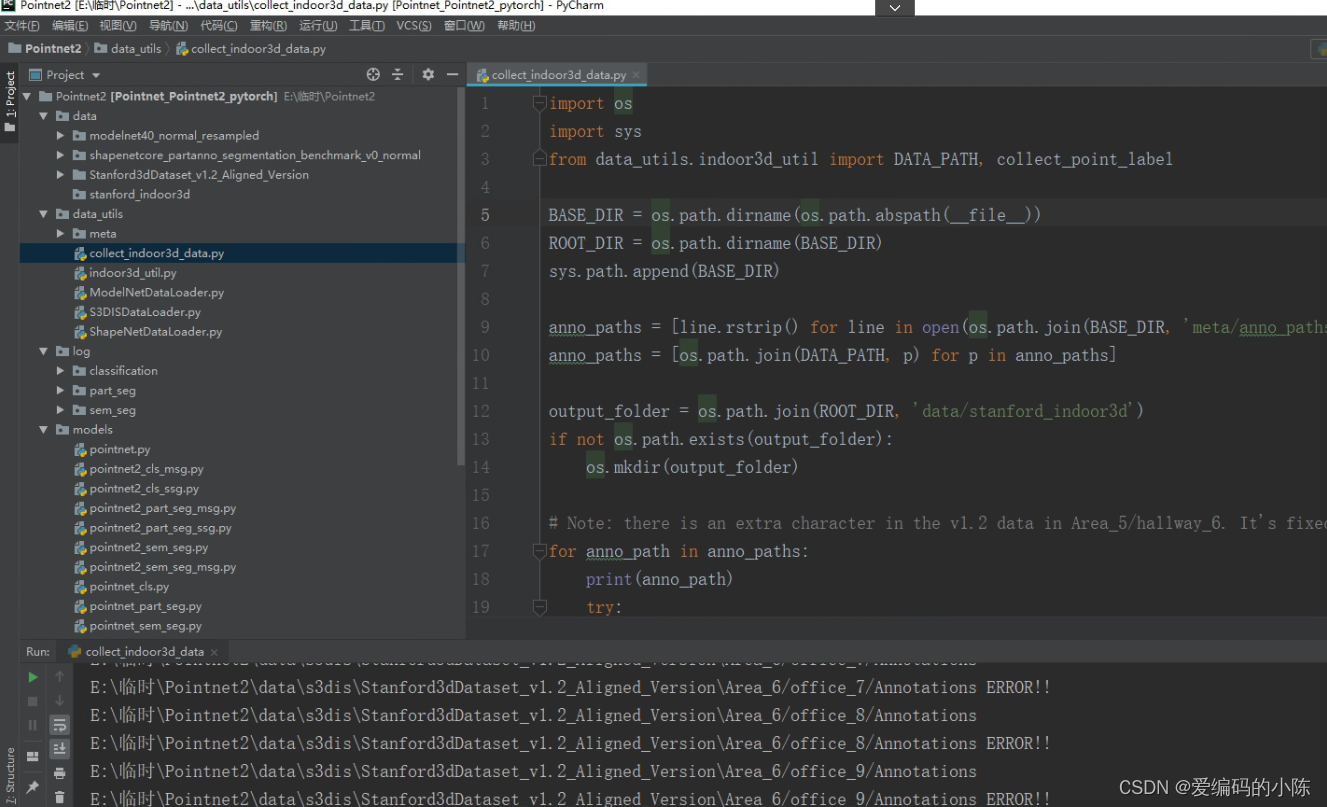
报错原因是我们没有建立s3dis文件夹,并将Stanford3dDataset_v1.2_Aligned_Version放入其中所以脚本运行时找不到路径,文件夹像下面这样处理


然后再运行collect_indoor3d_data.py就成功了,如下图所示
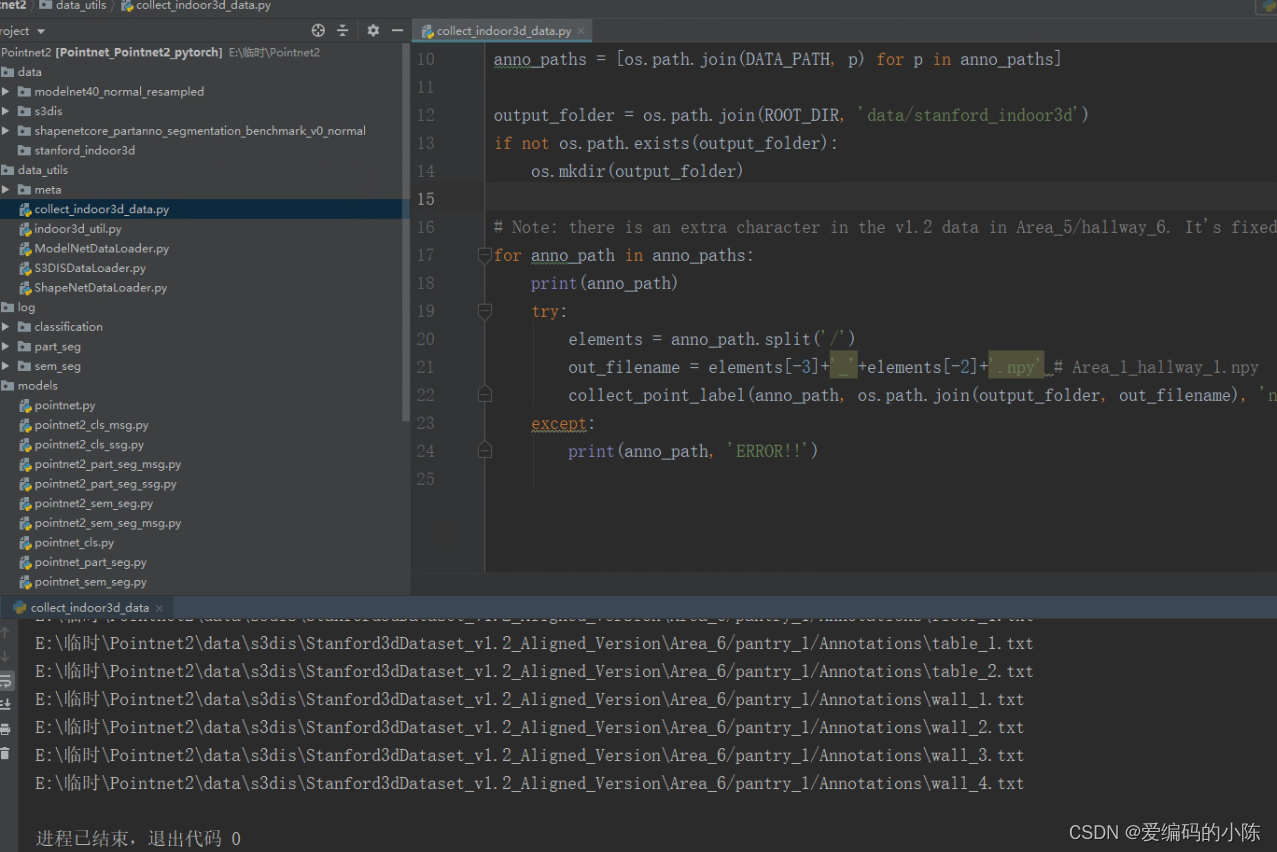
此时我们在回到 data/s3dis/Stanford3dDataset_v1.2_Aligned_Version/文件夹会发现多了好多npy文件
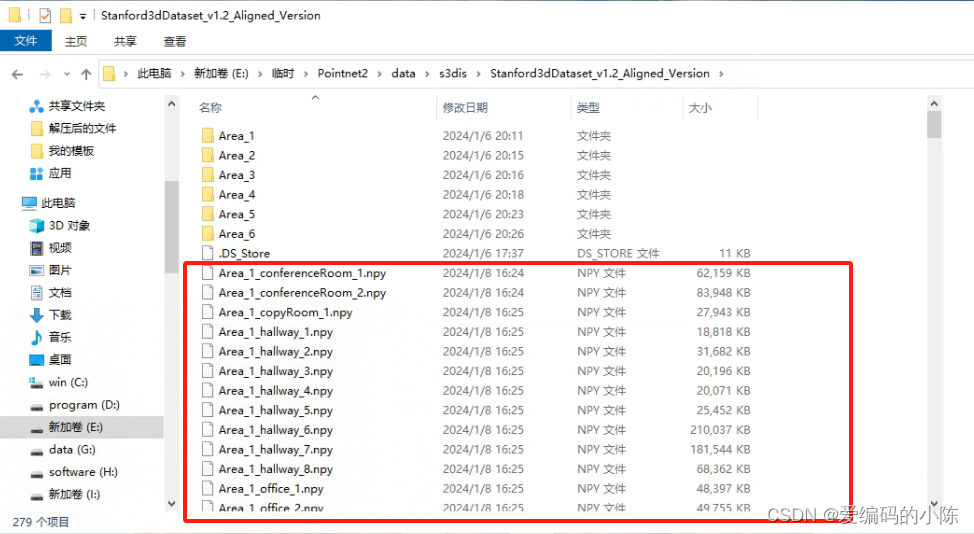
而我们的stanford_indoor3d文件夹里是空的,但是后续模型数据集的加载又是来自这个文件夹,因此将所有的npy文件复制到stanford_indoor3d文件夹中
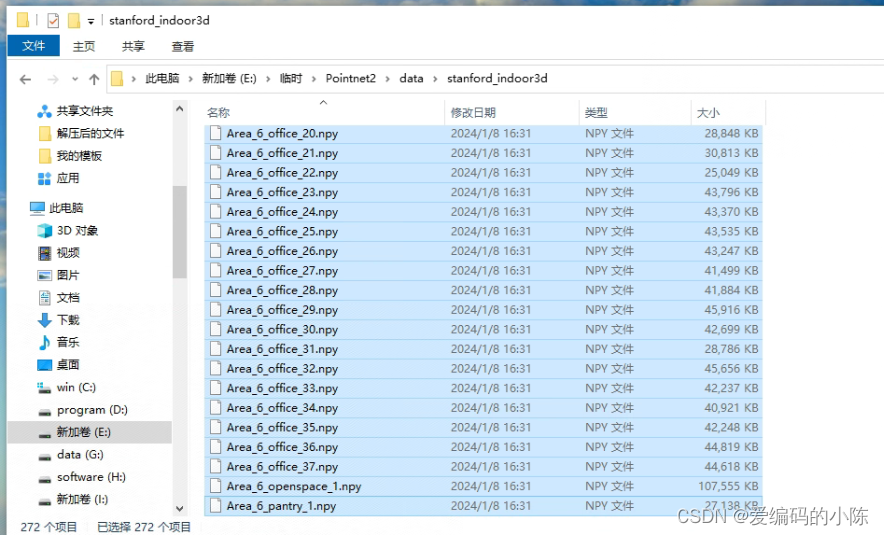
现在此时data文件夹里的目录结构是下面这样的
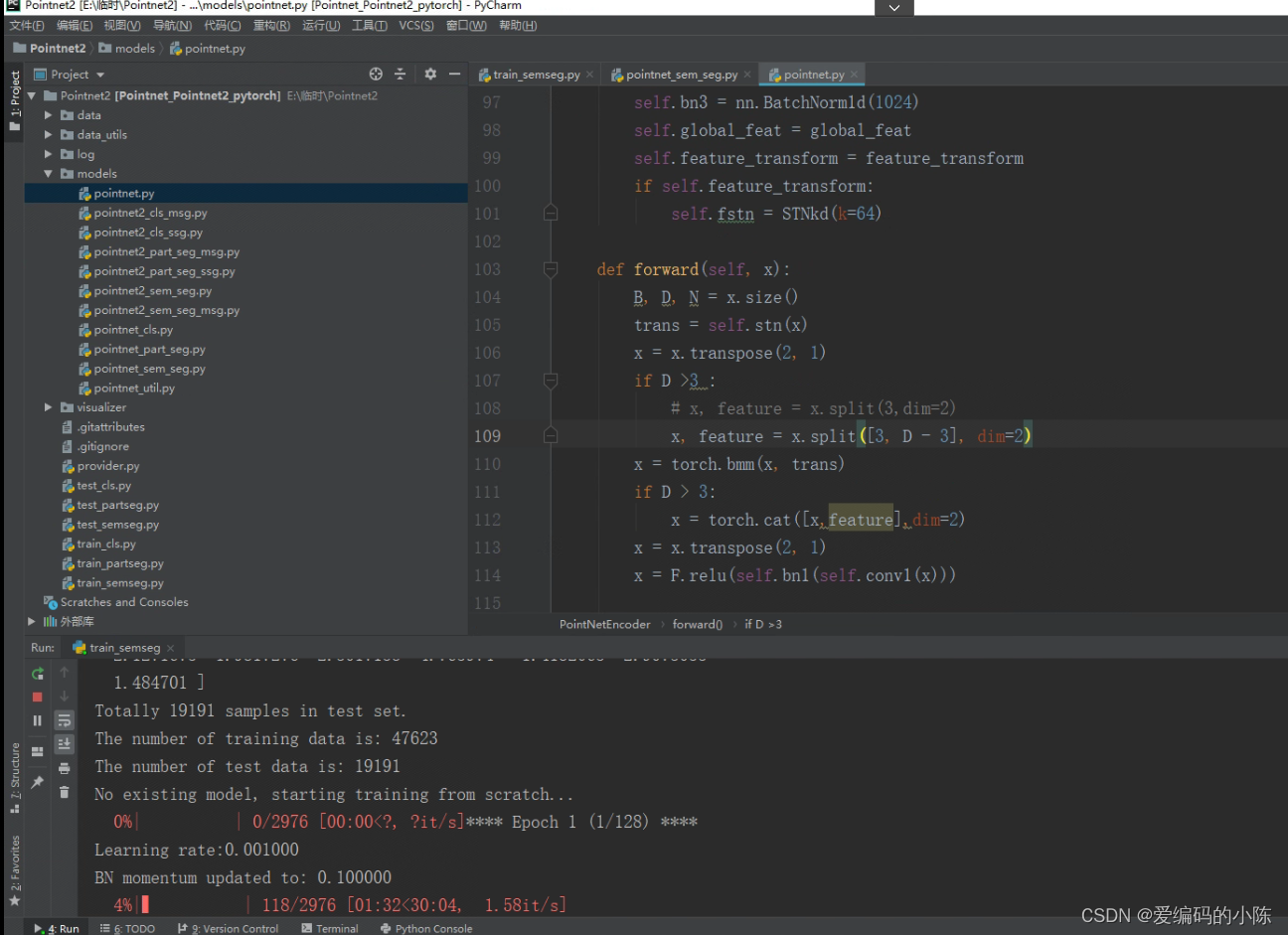
再回来运行train_semseg.py程序就可以了,可能会遇到上面提到的(4)和(7)的报错,对应上面方法就可以解决,成功截图如下:
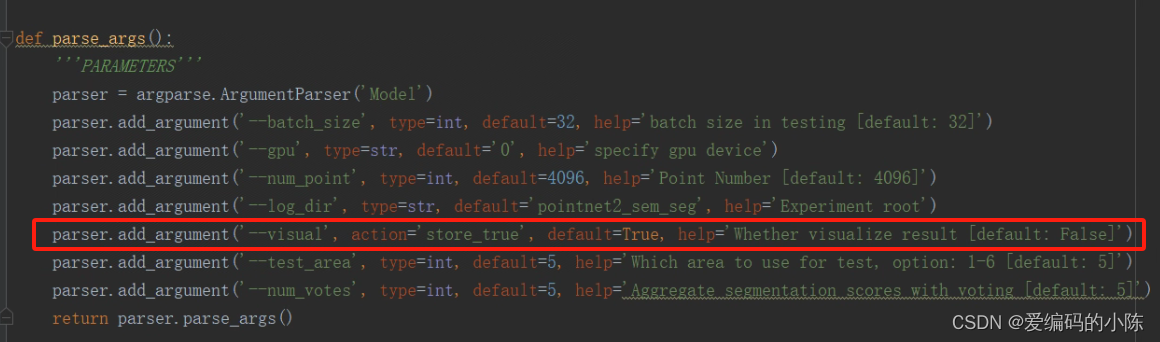
先训练,训练完才能用test_semseg.py进行测试,测试结果是可以进行可视化的,只需要把test_semseg.py中,visual的default的参数值改为True就可以生成obj文件,然后可以用CloudCompare软件进行可视化
注意,我们网盘下载下来的文件里没有visual,我们要自己建立,否则会因找不到文件路径而报错,目录结构如下,如果缺少eval.txt或其他文件夹,仿着classification建好

运行其他的也是,如果找不到路径就缺啥见啥或检查路径和文件名对不对
(9)visualizer文件中有个show3d_balls.py文件,适用于可视化的,官方链接里的README有提到,但是用到的一些so文件,是ubuntu里的命令文件,如果想在windows下能运行,需要重新改写。
1、win10系统下build.sh文件运行问题
安装git–>安装g++
安装git:https://so.csdn.net/so/search?q=%E5%AE%89%E8%A3%85git&t=&u=
安装g++: MinGW下载和安装教程
可通过linux系统或者已安装的git中bash环境运行build.sh脚本
安装完毕g++之后可通过sh build.sh运行,见上图
2、win10系统下download_data.sh文件运行问题
该文件位于链接https://github.com/KuangenZhang/ldgcnn的part_seg的文件夹下
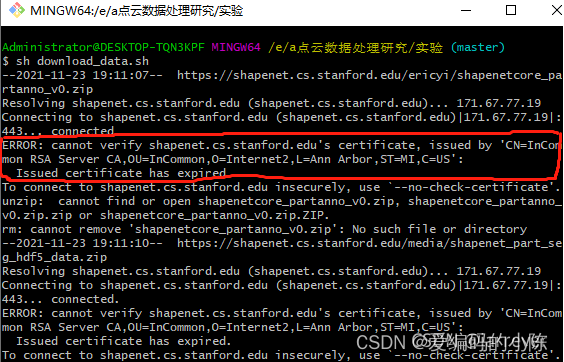
对于sh download_data运行问题的错误,主要原因为Issued certificate has expired,win10系统下解决方案为:通过记事本打开sh文件,wget指令后添加–no-check-certificate
若显示无–no-check-certificate参数,参考https://blog.csdn.net/topsogn/article/details/121217646?spm=1001.2014.3001.5501
- def download():
- BASE_DIR = os.path.dirname(os.path.abspath(__file__))
- DATA_DIR = os.path.join(BASE_DIR, 'data')
- if not os.path.exists(DATA_DIR):
- os.mkdir(DATA_DIR)
- if not os.path.exists(os.path.join(DATA_DIR, 'modelnet40_ply_hdf5_2048')):
- www = 'https://shapenet.cs.stanford.edu/media/modelnet40_ply_hdf5_2048.zip'
- zipfile = os.path.basename(www)
- os.system('wget --no-check-certificate %s' % (www))
- os.system('unzip %s' % (zipfile))
- os.system('mv %s %s' % (zipfile[:-4], DATA_DIR))
- os.system('rm %s' % (zipfile))
若显示unzip不是内部或外部命令,也不是可运行的程序或批处理文件。则可通过在系统环境变量中添加windows下的zip.exe和unzip.exe的路径
3、 raise OSError(“no file with expected extension”)问题
在运行PointNet的可视化程序时,作者只提供了linux平台下的动态链接库程序源码,自己的windows平台下无法调用。发现是动态链接库的文件格式不对,遂学习如何将.so文件转换成.dll文件
3.1 安装viusal studio
3.2 新建C++动态链接库项目
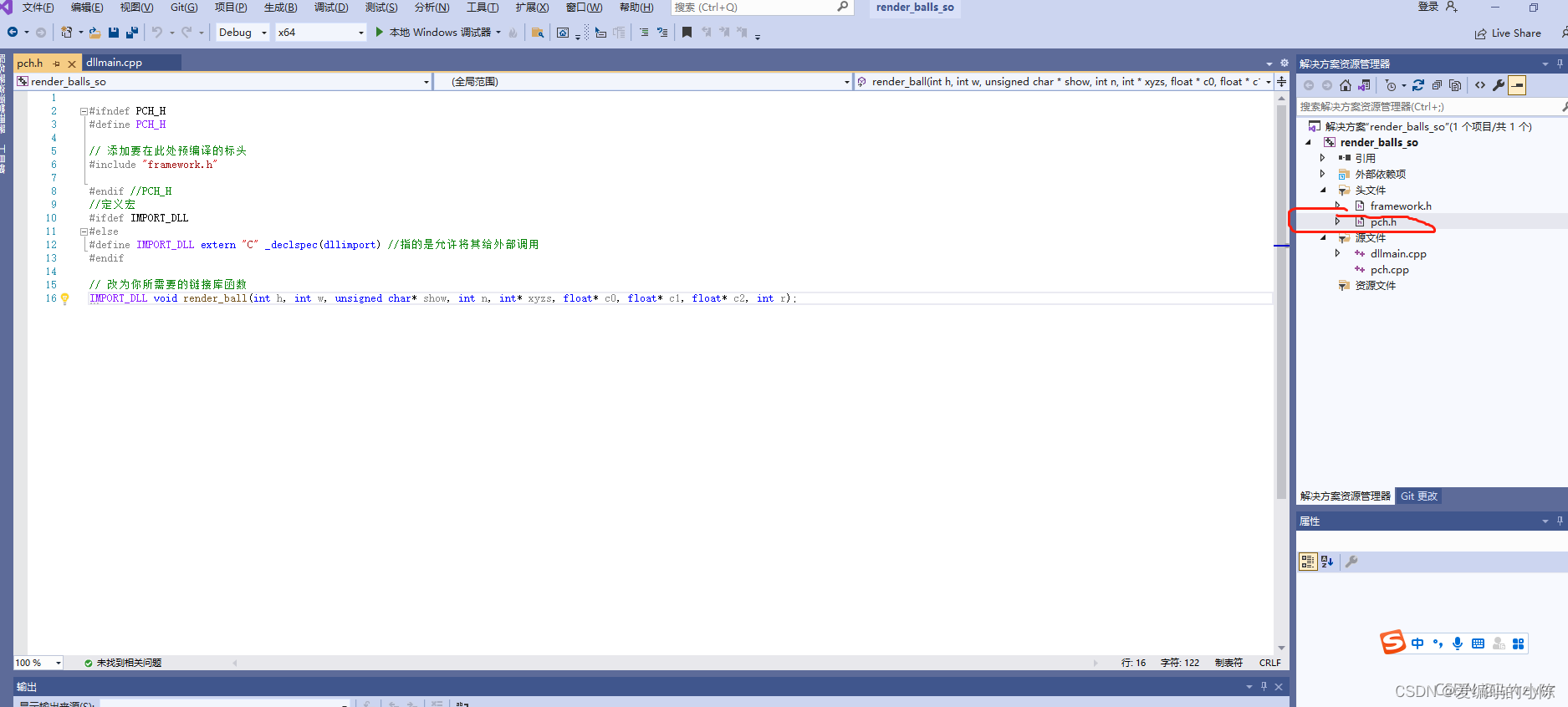
3.3 修改头文件pch.h
- #ifndef PCH_H
- #define PCH_H
-
- // 添加要在此处预编译的标头
- #include "framework.h"
-
- #endif //PCH_H
- //定义宏
- #ifdef IMPORT_DLL
- #else
- #define IMPORT_DLL extern "C" _declspec(dllimport) //指的是允许将其给外部调用
- #endif
-
- // 改为你所需要的链接库函数
- IMPORT_DLL void render_ball(int h, int w, unsigned char* show, int n, int* xyzs, float* c0, float* c1, float* c2, int r);
3.4 重写dllmain.cpp文件
- // dllmain.cpp : 定义 DLL 应用程序的入口点。
- #include "pch.h"
- #include <cstdio>
- #include <vector>
- #include <algorithm>
- #include <math.h>
- using namespace std;
-
- struct PointInfo {
- int x, y, z;
- float r, g, b;
- };
- void render_ball(int h, int w, unsigned char* show, int n, int* xyzs, float* c0, float* c1, float* c2, int r) {
- r = max(r, 1);
- vector<int> depth(h * w, -2100000000);
- vector<PointInfo> pattern;
- for (int dx = -r; dx <= r; dx++)
- for (int dy = -r; dy <= r; dy++)
- if (dx * dx + dy * dy < r * r) {
- double dz = sqrt(double(r * r - dx * dx - dy * dy));
- PointInfo pinfo;
- pinfo.x = dx;
- pinfo.y = dy;
- pinfo.z = dz;
- pinfo.r = dz / r;
- pinfo.g = dz / r;
- pinfo.b = dz / r;
- pattern.push_back(pinfo);
- }
- double zmin = 0, zmax = 0;
- for (int i = 0; i < n; i++) {
- if (i == 0) {
- zmin = xyzs[i * 3 + 2] - r;
- zmax = xyzs[i * 3 + 2] + r;
- }
- else {
- zmin = min(zmin, double(xyzs[i * 3 + 2] - r));
- zmax = max(zmax, double(xyzs[i * 3 + 2] + r));
- }
- }
- for (int i = 0; i < n; i++) {
- int x = xyzs[i * 3 + 0], y = xyzs[i * 3 + 1], z = xyzs[i * 3 + 2];
- for (int j = 0; j<int(pattern.size()); j++) {
- int x2 = x + pattern[j].x;
- int y2 = y + pattern[j].y;
- int z2 = z + pattern[j].z;
- if (!(x2 < 0 || x2 >= h || y2 < 0 || y2 >= w) && depth[x2 * w + y2] < z2) {
- depth[x2 * w + y2] = z2;
- double intensity = min(1.0, (z2 - zmin) / (zmax - zmin) * 0.7 + 0.3);
- show[(x2 * w + y2) * 3 + 0] = pattern[j].b * c2[i] * intensity;
- show[(x2 * w + y2) * 3 + 1] = pattern[j].g * c0[i] * intensity;
- show[(x2 * w + y2) * 3 + 2] = pattern[j].r * c1[i] * intensity;
- }
- }
- }
- }
- // 具体内容改为你的文件内容
-
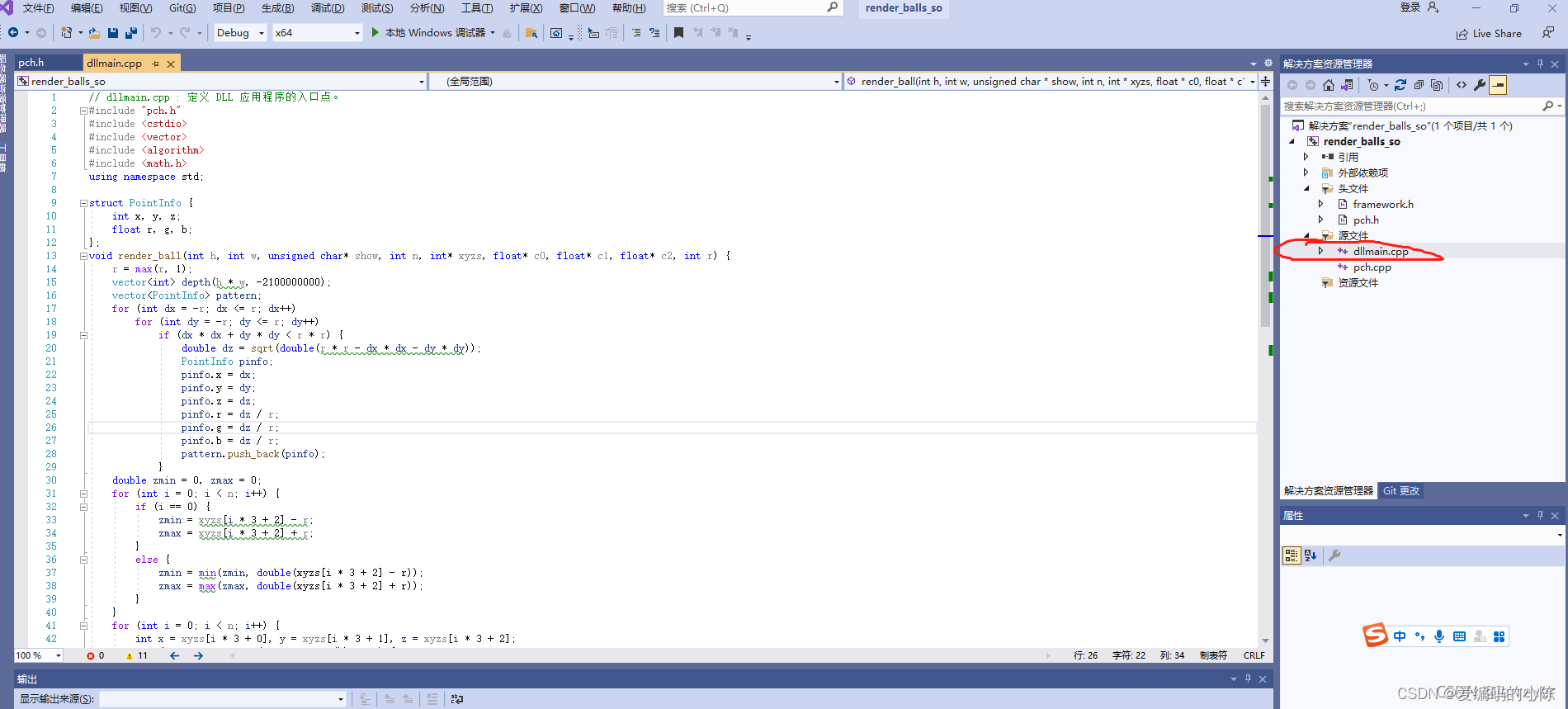
转载链接:https://blog.csdn.net/Moringstarluc/article/details/105702543
注: 若pycharm调试时出现OSError: [WinError 193] %1 不是有效的 Win32 应用程序 的问题
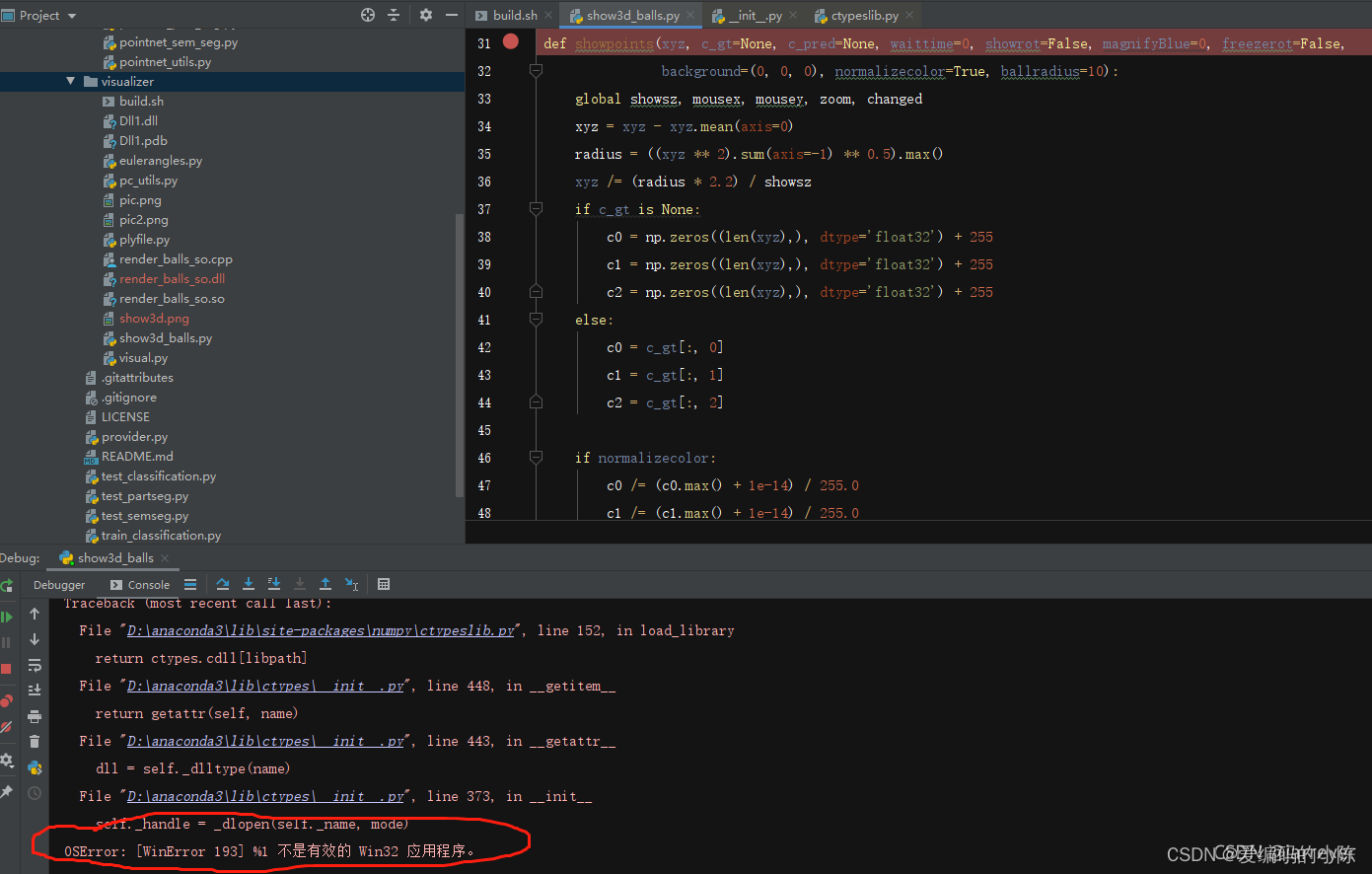
原因为visual调试时的 配置: Debug Win32,需修改为Win64,解决方案见下图,修改为x64即可

(10)报错
FileNotFoundError: [Errno 2] No such file or directory: 'E:\\临时
\\Pointnet2\\log\\part_seg\\pointnet2_part_seg_ssg\\eval.txt'
这个就是运行test_partseg.py报的错,原因是原文件家里有一个pointnet2_part_seg_msg的文件夹而我们这里找的是pointnet2_part_seg_ssg文件夹,因此我们要自己建立,结构如下
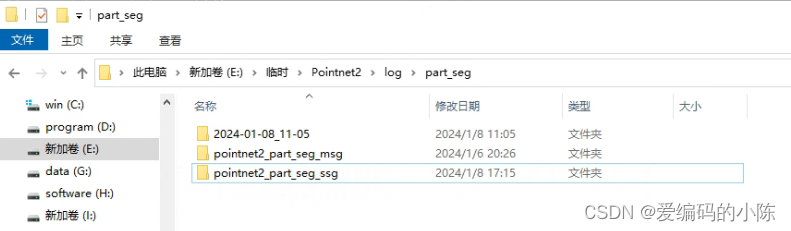

然后再运行就可以了
(11)报错
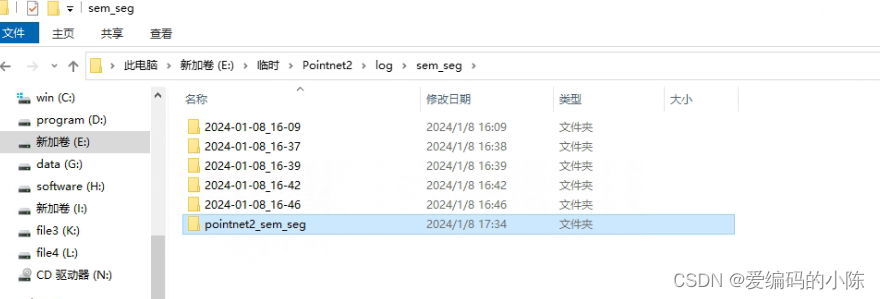
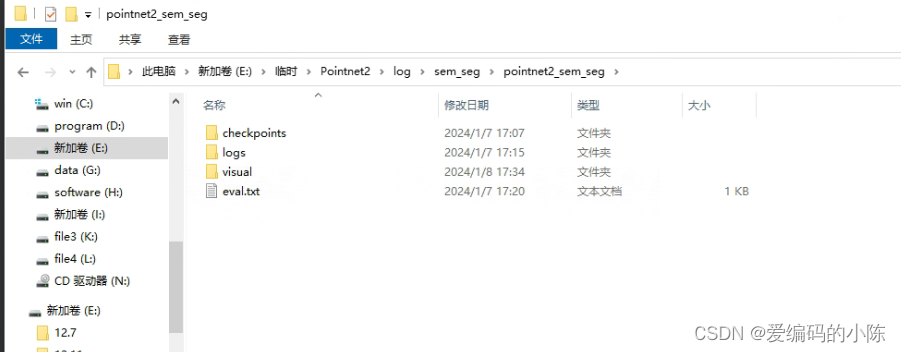
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'log\\sem_seg\\pointnet2_sem_seg\\visual'
这是运行test_semseg,py找不到文件,做法类似于上面建立文件夹,后续如何用test_semseg,py前面已经介绍
(12)最先开始遇到的错误是,运行train_cls.py遇到的报错
(1)
return forward_call(*input, **kwargs)
TypeError: forward() missing 1 required positional argument: 'cls_label'

一开始查这个问题,一直没有解决掉,后面按照(4)进行修改后,报错变成下面这样了
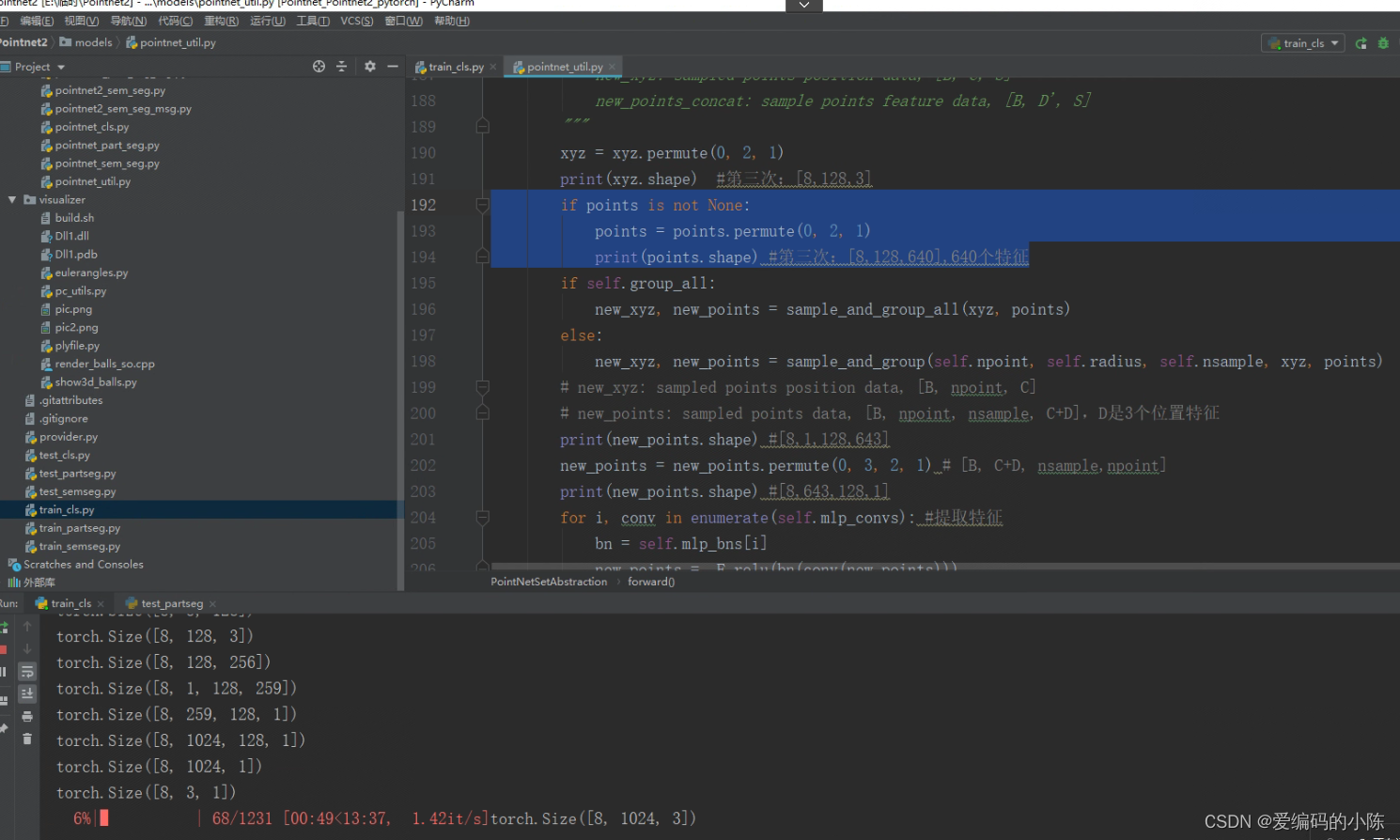
print(points.shape) #第三次:[8,128,640],640个特征
AttributeError: 'NoneType' object has no attribute 'shape'
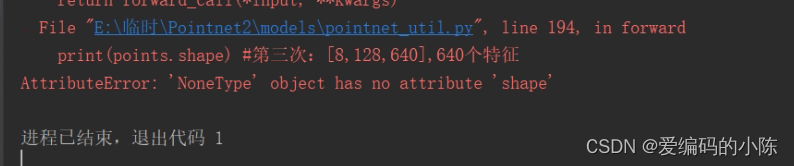
问题在pointnet_util.py这里

将
- if points is not None:
- points = points.permute(0, 2, 1)
- print(points.shape) #第三次:[8,128,640],640个特征
改为
- if points is not None:
- points = points.permute(0, 2, 1)
- print(points.shape) #第三次:[8,128,640],640个特征
即把print朝里面缩进一下,然后就可以正常跑了
至此,所有程序就都可以正常跑了,复现完成!

