
- 1医药领域知识图谱快速及医药问答项目(项目全过程)_基于知识图谱的心理咨询智能问答系统
- 2python数据预处理之将类别数据转换为数值的方法_将“数据预处理.xlsx”文件中的“类型转换”工作表中的数据类型统一调整为数值,使
- 3C++之正则表达式_c++ 正则表达式
- 4Linxu系统服务管理,systemd知识/进程优先级/平均负载/php进程CPU100%怎么解决系列知识!
- 5Android Studio解决BuildConfig同步问题_buildconfig无法导入
- 6uni-app开发小程序,笔记记录7 加入购物车_小程序加入购物车代码
- 7MySQL数据库(22):子查询 sub query
- 8在Vmware虚拟机上安装Ubuntu.iso镜像的完整指南_ubuntu iso
- 9Firefly-RK3288学习笔记4-移植Qt程序到开发板_rk3288移植qt
- 10小程序bindtap传参_小程序 bind:tap 带参数
因果,因果推断,因果关系是什么?_因果马尔科夫条件
赞
踩
因果关系是什么?
当我们在问「为什么」的时候,我们在问什么?
Shallow men believe in luck or in circumstance. Strong men believe in cause and effect. ― Ralph Waldo Emerson
目录
- 第一章——前言:用通俗的语言介绍「什么是因果关系?」这一问题的讨论背景,并概括若干个传统的哲学观点,以及和下文的统计因果模型相比,这些传统定义存在的缺陷。
- 第二章——事件性因果
- 2.1. 随机对照试验
- 2.2. 介入主义的因果观
- 2.3. 虚拟事实模型(RCM)
- 2.4. 贝叶斯网络
- 2.5. 结构方程(SEM)+ 结构因果模型(SCM)
- 2.6. SCM的反事实推理
- 第三章——过程性因果:因果环路图(CLD)与微分方程
- 第四章——后记
除前言外,本文其他部分默认读者已经理解基础概率论(概率、条件概率、贝叶斯定理、随机变量、期望值、相互独立事件)、基础图论(节点、边、有向无环图)、概率图模型初步(贝叶斯网络、d分隔)、统计学基础(随机对照试验)等知识。
另外,本文可以看作Judea Pearl的《Causality》的一篇导读。
参考系统:关河因果分析系统
禁止全文转载,大篇幅引用请标注出处并私信告知。
一、前言
因果关系在生活中无处不在。经济、法律、医学、物理、统计、哲学、宗教等众多学科,都与因果的分析密不可分。然而,和其他概念,例如统计的相关性相比,因果(causality)非常难以定义。
利用直觉,我们可以轻易判断日常生活中的因果关系;但是,用清晰、没有歧义的语言准确回答「因果关系是什么?」这个问题,往往超出了常人的能力范围。
(感兴趣的读者,不妨暂停阅读,然后试着给出一个「因果关系」的定义。)
不得不承认,回答这个问题是非常困难的,以至于部分哲学家认为,因果关系是不可还原的、最基础的认知公理,无法被用其他方式描述。不过,本文即将描述的众多统计因果模型,将会是针对这一观点的有力反驳。
在CSDN上,也有一些对于因果关系的探讨,令人遗憾的是,这个问题下的大多数答案,都把重心放在了认知论上,即「如何回应休谟的归纳问题?」以及「我们怎么知道,我们认知的因果关系是可靠的?」大家似乎都默认,「什么是因果关系」是一个琐碎得不需要讨论的前提(但显然并非如此),陷入怀疑论和先验论,从而无法给出一个实用的因果模型。事实上,因果关系是一个本体论的话题:我们需要找到一个符合直觉、足够广泛,但也足够具体的定义来描述因果关系;在此基础之上,我们还需要一套可靠的判定因果的方法。
常用的统计因果模型都采用了介入主义(interventionism)的诠释:因果关系的定义依赖于「介入」的概念;外在的介入是因,产生现象的变化是果。
在此之前,我们先了解一下其他传统的对于「因果关系」的定义,以及为什么它们不符合直觉。

大卫·休谟(David Hume)
休谟:因果就是「经常性联结」(constant conjunction)。如果我们观察到,A总是在B之前发生,事件A与事件B始终联结在一起,那么A就导致了B,或者说A是B的原因。
反驳:令A表示公鸡打鸣,令B表示日出。自然条件下,日出之前总有公鸡打鸣,但不会有人认为公鸡打鸣导致了日出。假如我们进行介入,监禁了所有的公鸡,使它们无法打鸣,太阳仍然会照常升起。
在这里,有必要注意一个细节:
大卫·休谟(David Hume,1711年-1776年)。
卡尔·皮尔逊(Karl Pearson,1857年-1936年)。
提出「统计相关性」概念的皮尔逊,比休谟晚出生了一百多年。
我们现在的思维方式,并非是自古以来就存在的:我们眼里理所应当的常识,在古人脑中可能从未出现。
在统计学成为一门严谨的学科、皮尔逊清晰地分离相关性和因果性之前,大多数人都把相关性和因果性混为一谈。即便到了现在,认为相关就代表因果的人也不在少数。
我们没有必要因为休谟的历史地位,就把他下的定义奉为金科玉律。所以,休谟用的经常性联结只能定义相关性,不能定义因果性。

相关性未必意味着因果性
- 相关性不代表因果性。
- 相关性是对称的,而因果性是不对称的。如果A是B的原因,那么B是A的结果,但我们绝不会同时说「事件A是事件B的原因,事件A也是事件B的结果」。至于相关性,随机变量X与Y之间的相关性定义为 corr(X,Y)=cov(X,Y)σXσY=E[(X−μX)(Y−μY)]σXσY ,所以必然有 corr(X,Y)=corr(Y,X) 。
因果关系的不对称性,曾被用于反驳亨佩尔用DN模型定义「科学解释」的做法,但这是属于科学哲学的题外话了。
以上两条直觉,可以反驳以下一系列不使用「介入」概念的因果定义。
- 充分因: A→B
- 必然因: A←B
- 朴素的反事实因果: (A→B)∧(¬A→¬B)
- 加入概率论,用相关性定义因果性。
一个典型的反例:用事件A表示「冰激凌销量增加」,用B表示「溺水死亡者数量增加」。A与B之间成正相关,但我们都知道,A与B之间不存在因果关系,它们都是由一个共同的因素「夏天」导致的。由此可见,仅仅使用概率统计的工具,并不足以让我们在现实中做出理性的因果推断。
- INUS条件:原因是Insufficient but Necessary parts of a condition which is itself Unnecessary but Sufficient。
是INUS条件,但不是原因的例子,并不难构造:闪电、干草堆、消防员玩忽职守、空气干燥都是一场火灾的INUS条件。但是,我们知道闪电和雷声永远符合「如果有闪电,那么必然有雷声」;因此,雷声也是火灾的INUS条件,却不是火灾的原因。
上述一系列模型/定义,都有一个共同的缺陷:给定一个因果关系,这些模型可以完美套用;然而,给定一个此类模型,我们却无法直接确定不同变量之间的因果关系,因为这样的单个模型可以同时描述多种不同的因果、甚至非因果的关系。
哲学家们看似没有对因果关系提出令人满意的诠释。但是,这至多只是一种流行于哲学爱好者之间的误解。普通哲学爱好者们在因果关系方面的了解,通常不会超过休谟与康德,能知道刘易斯、必然论、多元主义之类都极为难得。实际上,在统计、经济等领域,已经有大量成熟且投入使用的因果模型,它们准确反映了我们对因果的直觉认识,而且能被精确的数学语言描述。
二、事件性因果
当我们说「A是因,B是对应的果」的时候,A和B可以是什么「东西」?
一般而言,我们认为A和B是某种事件,而且A必须发生在B之前。因为「因」必须发生在「果」之前,所以如果A导致了B,那么不可能同时有B导致了A——两个事件无法互为因果。由此可见,因果关系存在一种不对称性。
针对「在时间上,因必须先于果」这一条件,哲学家们有过大量的讨论(Backward Causation),其中不少还涉及尖端的量子力学。不过,我们仍然没有理由放弃这一条件。因为,不同的模型有不同的适用范围,而因果模型的适用范围主要是宏观现象、经济、医疗、复杂动力/电路系统,不论微观物理的结论如何,它在已知领域的有效性都不受影响。
有人或许会质疑,为什么两个东西不能互为因果呢?例如,让A1表示草原上羊的数量,让B1表示草原上狼的数量;其他条件不变,狼的增加会导致羊的减少,羊的减少会导致狼的减少,狼的减少会反而导致羊的增加,羊的增加进而导致狼的增加;A1和B1互为因果。
值得注意,A1与B1表示了某种过程,而不是某些固定时间点上的事件,所以A1与B1之间完整的因果关系无法用事件性因果表示。所以,对于这种质疑,我有以下几条回应:
- 我们可以按照时间顺序,把每个时间点上的A和B拆分为单独的事件,即B1(狼增加)→A1(羊减少)→B2(狼减少)→A2(羊增加)。如此一来,事件性因果也能表达A与B之间的关系。
- 针对过程性的因果,我们有另一种模型——因果环路图(CLD),将在本文第三章介绍。
- 过程性因果比事件性因果复杂。在理解过程性因果模型之前,我们需要先理解更简单的事件性因果模型。
对于事件性因果,当前最成熟、最广泛的模型是结构因果模型(Structural Causal Model,以下简称SCM)。SCM结合了结构方程(SEM)、虚拟事实模型(RCM)、概率图模型(主要是贝叶斯网络),并将其应用于因果分析。各类常用因果模型,都可以看作SCM的子类。接下来,我将以RCM、贝叶斯网络、SEM的顺序,按照SCM的发展思路,对其进行详细的介绍。
2.1. 随机对照试验
任何一本初级统计学课本都会提到,基于观测的统计模型无法可靠地识别因果关系。要确定因果关系,必须通过随机对照试验(Randomized Controlled Trial)。
在一个简单随机对照试验中,试验对象(通常是参加研究的志愿者,下文每一个对象用u表示)会被随机分入两组:实验组(treatment group,下文用t表示)和对照组(control group,下文用c表示)。
我们有多种不同的随机分组方式,例如简单随机分组、随机区组设计、配对设计。使用随机区组设计时,研究者会先根据个体的特征(年龄、性别等)将其分入不同的区组,再在每个区组内实施简单随机分组。使用配对设计时,研究者会把在各方面都非常相似的个体(例如双胞胎、不同时间节点的同一个人)配成对,在每一对个体中随机选一个作为实验组,另一个作为对照组。
实验组的对象会接受干预,但对照组的对象不会受到任何干预/介入。在医学实验中,实验组的对象会接受真正的治疗,而对照组的对象只会收到安慰剂。实验结束后,研究者会比较实验组和对照组的结果。
如果我们用Y表示我们感兴趣的结果变量,那么我们可以用以下符号表示随机对照试验的结果:
- Yc(u) 是在对照组条件下,对象u展现出的结果变量Y。
- Yt(u) 是在实验组条件下,对象u展现出的结果变量Y。
在研究中,我们通常会探究 Yt(u) 是否统计显著地不同于 Yc(u) 。这一过程涉及较为具体的统计假设检验,与本文的主要内容无关。但是,我们至少可以意识到,t与c的区别是因果关系中的「因」, Yt(u) 与 Yc(u) 的区别是因果关系中的「果」。
2.2. 介入主义的因果观
在随机对照实验的基础框架上,我们可以建立起一个介入主义(interventionism)因果观。
一个介入主义的因果模型包括三部分:
- 所有的系统 U :一个包含所有系统 u 的集合。一个系统 u 我们讨论的对象,可以是人体、机械、星球、化学反应系统、经济实体等。
- 所有的介入方式 T :一个包含所有可能的介入方式 t 的集合。例如,假设我们讨论的系统 U 是一个有两个按钮的黑箱,一个按钮是红色的,另一个按钮是绿色的,那么所有可能的介入方式为 {按红按钮,按绿按钮,两个按钮都按,两个按钮都不按} 。(在这个具体的例子里,根据黑箱的结构不同,可能的介入方式或许不止四种,所以这只是一个经过简化,以便直观理解的模型。)
- 状态函数 Y :输入一个系统 u 和一种介入方式 t ,输出系统的某个状态 y ,写作 y=Yt(u) 。例如,在一个医疗实验中, Y 可以反映「u(病人甲)在受到干预t(服用降压药)之后的y(血压)」。注意,y不一定要完整描述u的状态的所有部分,只反映几个变量也是可以的。我们当然可以让y表示某个病人全身所有分子的运动状态,但这类过于复杂的状态函数,往往没有太大的实用价值。可是,在简单电路这样的系统中,完整表达电路每个节点的状态不仅可行,而且有利。因此,在建立因果模型时,我们需要具体问题具体分析,选择一个合适的状态函数。
值得注意的是,因为「果」的定义涉及到 Yt(u) 与 Yc(u) 的区别,而单次介入只说明了t却没有说明c,所以 T 必须包含一种表示「不介入」的介入方式 c 。也就是说,在一个因果模型中,任何一个系统都必须有一种不受干预的「自然状态」。如果现实情况过于复杂,很难找到不受干预的自然状态,我们可以把某种介入方式 c 默认为「不介入」。
因此:
- 任意一个介入主义的因果模型,都必须明确指出一种代表「不介入」的介入方式。
- 当我们在问「为什么发生了现象 y1」的时候,我们其实在问:「在我对世界建立的因果模型中,自然状态的现象是 y0=Yc(u) ,但是我观察到了现象 y1≠y0 。于是,我认为实际发生的情况是 y1=Yt(u) ,其中 t≠c 。 t 与 c 之间的区别是什么?」
- 或者,更简单地说,当我们问「为什么A」的时候,我们往往省略了后半句:「为什么A,而不是B?」
以知乎搜索「为什么」前几个结果为例,我们可以发现,「默认状态」的思维方式的确无处不在。
例1: 现在的男生为什么不追女生?
默认状态:男生应当追女生。
例2: 为什么有人会点两百多块一杯的猫屎咖啡?
默认状态:一般人不会花两百多块买一杯咖啡。
另一些情形中,两个对话者可能选择了不同的默认状态,便带来了以下的对话:
甲:「你为什么做了A这件事?」(默认「不做A」是自然状态,要求乙为「做A」提供理由)
乙:「为什么不呢?」(默认「做A」是自然状态,把论证的责任转移到甲身上)
在下一部分(2.3),我们将把这一系列直觉发展为正式的虚拟事实模型。
不过,我希望先对格兰杰因果(Granger causality)做出一些澄清。格兰杰因果的定义:如果得知事件A的发生有助于预测之后的事件B,那么我们说A是B的格兰杰因。然而,格兰杰因果只包含了观测,却没有包含介入,直接操纵A并不一定能影响B,这与我们日常对因果的直觉不符。所以,格兰杰因果虽然名叫「因果」,却只是一个统计相关性的概念,而非真正的因果概念。在下文中,我不会对格兰杰因果做更多讨论。
2.3. 虚拟事实模型
2.3.1 虚拟事实模型(Rubin Causal Model,简称RCM)由Donald Rubin提出。在RCM中,因果关系「果」的定义是 δ(u)=Yt(u)−Yc(u) 。
在实际生活中,我们考虑的系统往往不止一个——对于某个正在研发的药品,我们最感兴趣的无疑是它在所有目标人群上的效果,而不仅仅是某个病人甲。继续采用RCM对于因果的定义,那么一个介入「因」对群体内所有个体的「果」是 E[δ(u)]=E[Yt(u)−Yc(u)]=E[Yt(u)]−E[Yc(u)] 。(由期望值的线性可得)
在上帝视角下,上述定义并不复杂。即使变量 y=Yt(u) 不是一个数值变量,我们也可以通过其他方式定义 δ(u) 。从更广泛的角度考虑,RCM定义中的减法未必是实数域的减法;针对更复杂的变量y(例如张量、概率分布),我们可以采用其他的减法,只要符合数学规范和具体研究需要即可。
可是在实际生活中,我们无法获得完美的信息:
- 无法同时知晓 Yc(u) 与 Yt(u) 。由于每个人都是独一无二的,每个时间节点也是独一无二的,所以在受到了一种介入,并表现出新状态之后,这个系统不可能完美恢复到原来的状态,重新接受另一种介入。这种情况被称为「因果推断的根本问题」(the Fundamental Problem of Causal Inference,以下简称FPCI)。
- 无法同时知晓每个个体的情况。正如在检测手机在极端条件下的质量时,我们不可能去砸坏每一个手机一样,我们只能随机从群体中抽取样本,再利用样本的统计数据推断群体参数。
「无法同时知晓每个个体」的问题,已经有常规的统计学手段解决。但为了避免FPCI,我们必须对群体参数的分布做出额外的假设,包括但不限于以下的一种或多种:
- 个体处理效应稳定假设(Stable unit treatment value assumption,简称SUTVA):对于任意个体 u1 的干预不会影响到另一个任意个体 u2 的状态。SUTVA使我们可以把样本中每个个体的反应看作独立事件,从而降低了我们需要的样本体积、模型体积和建模时间。
- 同效果假设(assumption of constant effect):对于所有的个体,某种介入方式造成的效果是相同的。例如,某个降压药对所有人的效果都是降低血压,不会产生增高血压的情况——即使有,也只不过是统计的噪声,可以用大样本、大数定理和中心极限定理消解。于是,我们可以得到 δ^(u)=Yt¯(u)−Yc¯(u) ,用样本内的平均效果估算这一介入方法对所有个体的因果效果。
- 同质性假设(assumption of homogeneity):对于任意个体 u1 和 u2 ,以及任意介入方式 t∗ ,始终有 Yt∗(u1)=Yt∗(u2) 。同质性假设强于同效果假设。例如,一个简单的FizzBuzz电脑程序在不同时间点上的性质理应完全相同。虽然在同一时间点上,我们无法同时测试它在不同输入下的输出,但是它在不同时间点上的表现必然相同。如果我们把「不同时间点上的FizzBuzz程序」看作一个群体,那么其中个体「每个时间点上的FizzBuzz程序」均符合同质性假设。
2.3.2 虚拟事实模型的不足
虽然RCM提供了一个可以用数学、统计定义的因果模型,但是它的缺点也很明显:在介入时,我们通常一次只能改变一个变量,观测的状态也只有一个变量。如果我们增加变量,模型的体积、需要的训练数据、训练时间都将以指数级增长。在下一部分,我们可以看到,贝叶斯网络先验的条件独立信息可以缓解这一困难。
此外,RCM从自变量的「因」到应变量的「果」的结构几乎完全是个黑箱,缺乏更清晰的可解释性。因此,单个RCM所能解决的问题也较为有限。相比之下,结构因果模型能为因果律、多变量之间的因果关系提供更详细的解释。
2.4. 贝叶斯网络
贝叶斯网络是一种基于有向无环图(directed acyclic graph,简称DAG)的概率图模型。虽然贝叶斯网络并不能直接表示因果,只能表示相关,但是它的图结构是SCM的基础。
贝叶斯网络示例
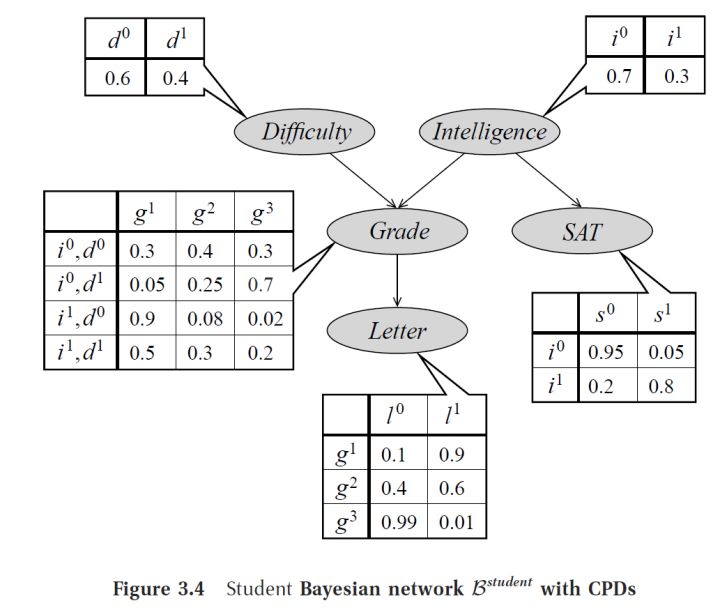
在一个贝叶斯网络中,每个节点是一个随机变量,代表一个事件。通常,这个随机变量服从某个离散或连续的分布。一个节点 X 中,储存了给定它的所有父节点 pa(X) 时 X 的分布,即 P(X=x|pa(x)) 。pa(X)表示节点X的所有父节点,即所有「拥有直接指向X的有向边」的节点。以上图为例, pa(Grade)={Difficulty,Intelligence} 。
贝叶斯网络(以及其他所有的概率图模型)相比于原始的联合分布模型,最大的优势在于增加了变量之间条件独立的先验信息,从而减小了模型的体积,与模型进行推断、学习的时间。例如,上图共有5个变量,如果用朴素的联合分布模型建模,条件概率表格的体积将会是 2×3×2×2×2=48 ,而采用贝叶斯网络后,条件概率表格的总体积为 2+2+4×2+2×1+3×1=17 。在小型的网络中,这种简化的效果尚不明显,但在大型网络中,假设每个变量有a种取值,那么联合分布模型的体积将为 O(an) ,而一个合适的贝叶斯网络或许能把体积复杂度降低到多项式级别。最极端的情况是朴素贝叶斯,即所有的随机变量均独立,此时模型的体积复杂度为 O(an) 。
条件独立的信息是先验的,它们往往由任务相关的专家提供,而非从数据中学习得到。这种做法能保证网络结构的可靠。(此处讨论的是parameter learning而非structure learning,网络结构已知而参数未知;对于后者,我们有Chow-Liu算法,但此处不讨论。)之后,我们也会发现,类似的先验因果假设在SCM中有重要地位。
2.4.1. d分隔
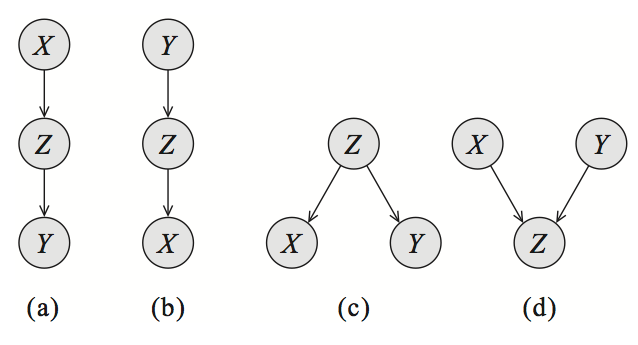
如图所示,对于一个贝叶斯网络中的三个节点/变量而言,一共有三种基本的结构。两种不同的条件独立假设。用 X⊥Y表示X与Y之间独立:
- cascade: A→B→C ,则必有 (A⊥C)|B 以及 A⊥̸C 。
- common parent: A←B→C,同样有 (A⊥C)|B 以及 A⊥̸C 。
- V-structure: A→B←C ,必有 A⊥C 与 (A⊥̸C)|B ,与前两种基本结构的条件独立情况不同。
为了回答「给定一个随机变量的集合Z,随机变量A与B之间是否条件独立」这个问题,我们需要引入d分隔的概念。d分隔(d-separation)的全名是「有向分隔」(directed separation)。
某个节点集合O能d分隔节点A与节点B,当且仅当:给定O时,A与B之间不存在有效路径(active path)。
对于A与B之间的无向无环路径P,如果P上的每三个连续节点,都符合以下四种情况中的一种,那么P就是一条有效路径:
- X←Y←Z且Y∉O
- X→Y→Z且Y∉O
- X←Y→Z且Y∉O
- X→Y←Z且Y∈O。这种情况被称为伯克森悖论(Berkson's Paradox):当两个独立事件的共同结果被观察到时,这两个独立事件就不再相互独立了。例如,扔两个硬币,硬币A朝上的面和硬币B朝上的面之间,应该是相互独立的;然而,如果我们已知「有一个硬币正面朝上」,那么A与B朝上的面之间就不再相互独立了。
相应地,如果给定O之后,一条路径P不是一条有效路径,那么我们称O节点集合 d分隔 了路径P。d分隔的概念适用于两个节点,也适用于两个节点之间的路径,后者在「后门准则」的定义中非常有用。
如果两个变量没有被d分隔,那么它们之间的状态被称为d联结(d-connection)。
d分隔能极大简化贝叶斯网络中 (X⊥Y)|Z 等条件独立情况的判定。Pearl将其进一步泛化,提出了拟图(graphoid)的概念。一个graphoid是一组形如「已知变量Z,则变量X与变量Y相互独立」的陈述,服从以下五条拟图公理:
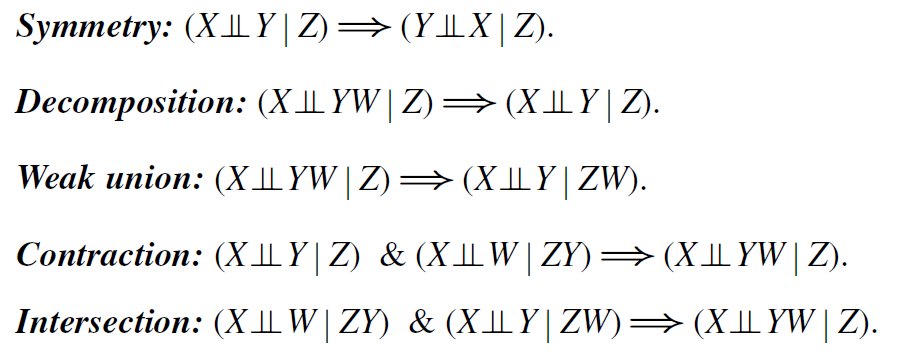
关于graphoid中文翻译的备注:graphoid尚无权威的中文翻译,而且在互联网上几乎没有任何相关的中文材料。我在选择译名时,参考了matroid的翻译。既然matrix是矩阵,而matroid是拟阵,那么graph是图,所以graphoid应该被称为拟图。
拟图的概念只出现在Pearl的著作中。不过,如果我们采用概率论对于「独立事件」的定义,那么我们可以把它们当做定理推导得出,可见概率论的「独立」符合拟图公理体系。当然,intersection的成立需要一个额外条件:针对所有的事件A,如果 A≠∅ ,那么 P(A)>0 。
2.4.2. 为什么贝叶斯网络不适合做因果模型?
有了一个学习完毕的贝叶斯网络后,我们可以用它进行各类推断,主要是概率推断P(Xi|Xj1,Xj2,Xj3,...,Xjk) :已知 Xj1,Xj2,Xj3,...,Xjk 等随机变量的值,求另一随机变量 Xi 的条件概率。贝叶斯网络的优越性体现于,即使有大量的缺失、未知变量值,它也能利用边缘化操作,毫无障碍地进行概率推断。在SCM中,这一功能仍然有相当重要的地位。
如果我们把箭头看作从因指向果,把A→B看作A导致了B,那么贝叶斯网络看起来似乎能表达因果关系。然而,贝叶斯网络本身无法区分出因果的方向。例如,A←B←C与A→B→C的因果方向完全相反,但在贝叶斯网络的模型描述下,它们表达的概率分布和条件独立假设完全相同。
此外,概率论「给定/已知随机变量Z」里的「给定/已知」只能用于表达观察,而非介入。例如,P(下雨|地面是湿的)与P(地面是湿的|下雨)的概率值都很高,其中「给定“地面是湿的”」与「给定“下雨”」都是观察而非介入的结果。用do(X)表示「介入,使得事件X发生」,现在考虑另一种情况:P(下雨|do(地面是湿的))。根据直觉,显然P(下雨|do(地面是湿的)) < P(下雨|地面是湿的),因为把地面弄湿并不能导致下雨。
综上所述,贝叶斯网络虽然十分强大,但无法准确描述因果关系。下文的SEM将主要解决这个问题。在学习贝叶斯网络的过程中,我们也应该尽量避免使用「因果」相关的词语——贝叶斯网络中,A→B未必等同于A导致B。
2.5. 结构方程+结构因果模型
为了表示因果关系,我们需要对贝叶斯网络进行改进。结构方程模型(Structural Equation Model,简称SEM)在经济与工程领域十分常用。在贝叶斯网络的基础上加入SEM的成分之后,我们就离完善的SCM(结构因果模型)更近了一步。
2.5.1. 打破对称性
在贝叶斯网络中,节点 X 的概率分布 P(X=x|pa(X)) 由它的父节点 pa(x) 决定,记录在一个条件概率表格中。然而,条件概率表格和一些简单的连续概率分布都是可逆的。例如,对于随机变量 X 和 Y ,如果 Y=αX+β ,那么我们可以操纵代数表达式,得到 X=Y−βα 。然而,这种对称性在因果关系里是不符合直觉的。对称的代数表达式表明,如果我们改变Y,X就会发生相应的改变;可是,修改温度计的读数并不会改变环境温度,调整闹钟的时针并不会改变真正时间的流动。
因此,在SEM中,我们用函数式的方程表示某个变量 X : X=fX(pa(X),u(X)) 。其中, pa(X) 表示X的父节点中的内生变量(endogenous variable); u(X) 表示X的父节点中的外生变量(exogenous variable),只有一个。内生变量依赖于其他变量,在SCM中表示为「存在父节点的节点」,即至少有一条边指向该节点;外生变量独立于其他变量,在SCM中表示为「不存在父节点的节点」,即没有边指向该节点。
传统的路径分析研究中, fX 通常是一个线性函数,因果律的定义也局限与 Y=αX+β 中的 α 。但是,在数据越发复杂的现在,我们完全可以采用非线性函数、非参数模型。相对地,「因果」的定义也从路径参数 α 变成了更广义的「变化传递」,参见前文RCM的部分。作为一个广泛的模型框架,SCM可以产生各式各样的复杂模型。
在最广泛的条件下,函数 fX 是不可逆的。我们需要把 X=fX(pa(X),u(X)) 理解为「(大自然/模型本身)对X的赋值」,而不仅仅是一个普通的代数等式。SCM要求所有的箭头 A→B 必须表示「A直接导致B」。所以,在因果推断的过程中,我们必须按照因果箭头的方向进行推理,不能颠倒顺序。
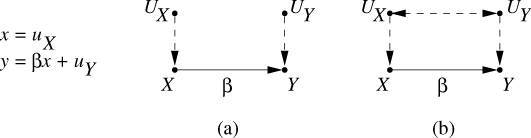
图1:结构因果模型示意图
如上图所示, UX 与 UY 是外生变量, X与Y是内生变量,X可以导致Y。在图(a)中, UX 与 UY 之间没有边相连,而在图(b)中, UX 与 UY 之间有一条用虚线表示的双向箭头。在SCM里,我们用单向箭头表达直接的因果关系,用双向箭头表明两个外生变量之间可能存在未知的混杂因素(confounding variable)。
UX 与 UY 等外生变量可以表示「模型没有考虑到的环境噪音」,从而为看似非随机的结构方程模型加入随机的成分。因此,SEM并非完全确定,它也可以拥有概率、不确定性等特征;SCM比普通的贝叶斯网络更广泛。此外,一个SCM描述了数据的生成原理,而不仅是表面观测到的概率分布,所以SCM比贝叶斯网络更稳定。
2.5.2. 介入
如上文所言,SCM是对于贝叶斯网络的一种泛化。一般的贝叶斯网络可以解答两类问题:
- 条件概率: P(Y|E=e) ,其中Y是我们感兴趣的一组未知变量,E是一组我们观察到的已知变量,e是我们观察到的E的值。E可以是空集,代表「我们没有观察到任何变量」。
- 最大后验概率(MAP): argmaxyP(Y=y|E=e) ,我们想要找到的是一组最有可能的Y值。
如果不考虑算法复杂度,一个能估计条件概率的模型必然能估计MAP,所以下文将只讨论条件概率的情况。
在「观察」的基础上,SCM还能做到「介入」: P(Y|E=e,do(X=x)) 。其中,我们对系统进行介入,迫使一组变量X拥有值x。在X是一个空集的情况下,SCM与普通的贝叶斯网络差别不大。
以下图为例,我将展示SCM实现介入的方法。
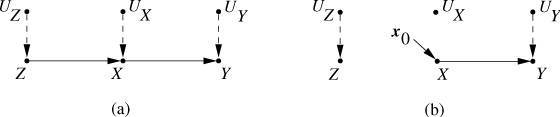
图2:一个SCM
在这个SCM中,变量X、Y、Z之间的关系可以用以下的结构方程表示:
- Z=fZ(UZ)
- X=fX(Z,UX)
- Y=fY(X,UY)
在此模型中,我们假设 UX 与 UY 与 UZ 这三个外生变量独立。所以,图(a)与图(b)中的 UX 与 UY 与 UZ 之间均没有边相连。
如图(b)所示,当我们进行介入 do(X=x0) 时,我们切断了所有指向X的边,并将X赋值为 x0 。于是,新的SCM包括了一套新的结构方程:
- Z=fZ(UZ)
- X=x0
- Y=fY(X,UY)
综上所述,一个SCM(写作 M1 )估计 PM1(Y|E=e,do(X=x)) 的方式为:完成对原有模型 M1 的介入 do(X=x) 之后,得到一个新的模型 M2 。随后,在 M2 上估计 PM2(Y|E=e) 。
有人可能会产生疑问:「观察和介入,有什么本质区别吗?」
一个日常例子式的回答如下:
用A代表「环境温度」,用B代表「温度计读数」,A与B之间的因果关系为 A→B 。在默认状态下,温度计不会受到外在干预。因此,观察到温度计读数升高,我们可以推断出环境温度升高。但是,当我们直接干预温度计时(例如用手握住温度计),我们进行了介入 do(B=b1) ,使温度计的读数变成了 b1 ;同时,因为是介入而非观察,从A到B的因果箭头被切断了,我们有 A↛B 或 A B 。
假设 b1 是一个较高的温度,那么 P(A=b1|B=b1) 代表「在自然状态下,观察到温度计的读数是 b1 时,实际的环境温度为 b1 的概率」; P(A=b1|do(B=b1)) 代表「在外在干预使温度计读数成为 b1 时,实际的环境温度为 b1 的概率」。显然, P(A=b1|B=b1)>P(A=b1|do(B=b1)) ,可见观察与介入是两种完全不同的行为。观察不会影响模型的自然状态,但介入会。
2.5.3. 因果推断的数学原理
在这一部分,我将介绍SCM进行因果推断的数学基础。
我们说一个SCM具有马尔可夫性质,当且仅当这个SCM不包含任何的有向环,且所有外生变量均相互独立。因为外生变量通常被理解为某种「误差项」或「噪音项」,所以如果某些外生变量之间存在相关性,那么它们之间可能存在混淆变量。在一个马尔可夫式SCM中,我们可以得到以下的基本定理:
因果马尔可夫条件: P(v1,v2,...,vn)=∏i=1nP(vi|pa(vi))
其中, vi 代表我们感兴趣的变量, pa(vi) 代表它的父节点中的所有内生变量。利用因果马尔可夫条件,我们可以把一个联合概率分布分解为多个条件概率分布的积。
一个符合因果马尔可夫条件的SCM经过介入之后,仍然符合因果马尔可夫条件,条件概率计算如下:
P(v1,v2,...,vn|do(X=x))=∏i=1,vi∉XnP(vi|pa(vi))|X=x
其中,X是一系列受到干预的变量,x是X中变量受干预之后的数值。 P(vi|pa(vi))|X=x 表示, pa(vi) 里同时也在X里(即在 pa(vi)∪X 中)的变量将被赋值为 x 的对应值。
图2
以图2为例,在干预之前, P(Z,Y,X)=P(Z)P(X|Z)P(Y|X) ,而在干预 do(X=x1) 之后, P(Z,Y|do(X=x1))=P(Z)P(Y|X=x1) 。注意,由于从Z到X的因果箭头已经被切断, P(Z)=P(Z|do(X=x1)) ,因为直接改变X无法影响Z。
在《Causality》中,Pearl证明了一个更广泛的结论:
P(Y=y|do(X=x))=∑tP(Y=y|T=t,X=x)P(T=t)
其中,每一个t都代表X所有父节点的一种可能取值。由于所有直接指向X的箭头已经被切断,所以自然有 P(T=t|X=x)=P(T=t) 。
2.5.4. 后门准则(back-door criterion)
考虑如下图3所示的SCM:
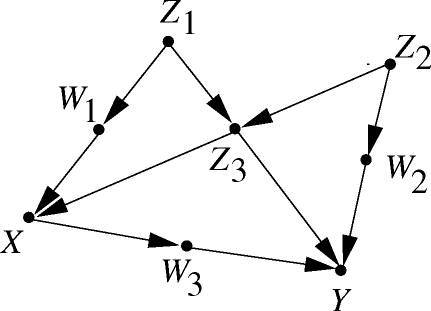
图3
在SCM中,如果一条无向连接X与Y的路径有一条指向X的箭头,那么我们把这条路径称为从X到Y的后门路径。按照正常的因果链,「X导致Y」的结构应该是 X→V1→V2→...→Vk−1→Vk→Y ;然而,如果X与Y之间后门路径存在,那么实际结果中很可能出现虚假的统计相关性。
因此,当一个变量集合S符合以下两个条件时,我们称S符合后门准则:
- S中不包括X的后代。
- S能d分隔所有从X到Y的后门路径。
例如,在图3里, {Z1,Z2,Z3},{Z1,Z3},{W1,Z3},{W2,Z3} 等集合都满足后门准则,但 {Z3} 不满足后门准则。
后门准则的重要性在于,它进一步泛化了2.5.3.结尾的公式。如果S满足从X到Y的后门准则,那么,我们可以推导得到:
P(Y=y|do(X=x),S=s)=P(Y=y|X=x,S=s)
P(Y=y|do(X=x))=∑sP(Y=y|X=x,S=s)P(S=s)=∑sP(Y=y,X=x,S=s)P(X=x,S=s)
这极大简化了SCM推导时的运算。
2.6. SCM的反事实推理
反事实推理(counterfactual inference)的核心在于:虽然现实情况下 X=x1 ,但是假如X=x2 的话,Y会怎么样呢?
有些人后悔,「如果我当年……,那么我现在就能……。」这一思维方式就是反事实推理。
反事实推理与FPCI(因果推断的根本问题)息息相关。对于一个已经接受了实验组介入的样本u,我们只能观察到u的 Yt(u) ,却永远无法观察到 Yc(u) ,反之亦然。RCM(虚拟事实模型)对反事实推理有一定的描述,但RCM整体不如SCM清晰、明确、易解释。
下面,我将用SCM重新表达2.2部分中提到的介入主义因果观。
- RCM考虑的对象是一个种群 U 内的所有个体 u 。在很多情形下,同质性假设不成立,每个个体都不尽相同。在SCM中,个体的差异会被误差项 UV 表示(外生变量 UV 会相对应地影响内生变量 V )。除了 UV 之外,模型 M 本身所代表的「自然法则」保持不变。
- RCM的表达式 Yt(u) 可以表示为 M.query(P(Y|do(T=t),U=u)) 。即:我们对模型M进行干预,使得变量T赋值为t;同时,我们观察到所有外生变量U的值为u;在此情况下,我们向模型M查询我们感兴趣变量Y的条件概率。
- RCM要求模型拥有一个「不受介入」的默认状态。显然,SCM符合要求:Yc(u)=M.query(P(Y|U=u))
因此,SCM可以回答类似「假如 X=x1 而非现实中的 X=x0 ,Y的值是什么?」的反事实问题。但是,在现实生活中,由于个体信息 U=u 通常未知,而复杂的非线性结构方程可能会随着U的分布变化而变化,所以反事实推理普遍比较困难。
总而言之,所有RCM均可以用SCM表达,而且SCM的白箱比RCM的黑箱更清晰、更稳定。
三、过程性因果
在第二章,我们使用的SCM(结构因果模型)建立在三条基本直觉上:
- 因和果都是单独时间点上的单独事件
- 因在前,果在后
- (由1和2可得)两个事件无法互为因果
不过,在其他一些情境中,例如掠食者的数量与猎物的数量,两个变量似乎「互为因果」。SCM与贝叶斯网络不允许环路的存在,故无法表示此类直觉上的因果关系。所以,我们需要一个更复杂的因果模型——因果环路图(Causal Loop Diagram,简称CLD)。
CLD中的变量基于以下的直觉:
- 因和果是某种过程,有一段持续的时间
- 因和果的持续时间段可以相互重叠
- 两个过程可以互为因果,甚至一个过程自身也可以形成因果环路
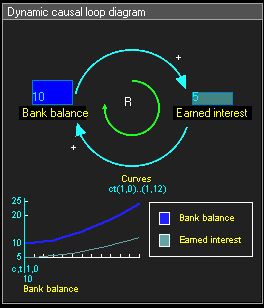
因果环路图:银行存款与利息
和SCM相比,CLD尚未有那么严谨、广泛的理论框架。我们可以把CLD理解为一个「从时间标量(实数)到一个SCM集」的函数映射。为了方便建模,所有的变量都是数值变量,而且多个过程变量之间的相互影响往往都是线性的,形如 Y=αX+β 。如果 α=dYdX>0 ,那么我们说从X到Y的链接是正链接;如果 α=dYdX<0 ,那么我们说从X到Y的链接是负链接。
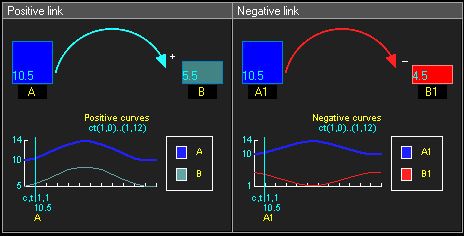
正链接(左)与负链接(右)
对于因果环路 A→B→A :
- 如果A起初的一点增加(或减少)会通过因果环路,导致A进一步增加(或减少),那么我们称之为强化反馈回路。
- 如果A起初的一点增加(或减少)会通过因果环路,反而导致A减少(或增加),从而中和最初的增加(减少),那么我们称之为平衡反馈回路。
假设A>0且B>0,那么:
- 如果 A→B 与 B→A 的链接正负相同,那么我们通常可以得到一个强化反馈回路。
- 如果 A→B 与 B→A 的链接正负相反,那么我们通常可以得到一个平衡反馈回路。
更一般地,在一个因果环路图中:
- 如果有偶数个负链接,那么它是一个强化反馈回路。
- 如果有奇数个负链接,那么它是一个平衡反馈回路。
反馈回路的实际意义通常如下:
- 强化反馈回路通常意味着指数增加、指数衰减,例如「利滚利」的银行存款与利息、不受限制的人口增长。
- 平衡反馈回路通常意味着达到某个平衡状态,例如洛特卡-沃尔泰拉方程的解。
在未来,一个可能的研究方向是把SCM中较为成熟、广泛的因果推断框架推广到CLD上。研究的重点在于引入非线性、非参数的复杂因果链接。此类研究必然十分困难,但随着电脑计算能力的增强,我们将逐渐有能力构建更复杂的CLD。
参考资料、拓展阅读:
https://yinguo.grandhoo.com/home
An Introduction to Causal Inference
Probabilistic Graphical Models: Principles and Techniques
The Art and Science of Cause and Effect - Judea Pearl
后记
经过此次文献阅读,我意识到,很多看似困难的哲学问题,或许在其他领域(经济学、人工智能、社会学、统计学、心理学、流行病学等)已经有了足够好的解答。因此,不论我们在学习什么学科,我们都不能被脚下的一亩三分地限制了视野。恰恰相反,我们应该多从不同的学科汲取灵感,切莫给自己打上「只研究xxxx领域」、故步自封。
同时,我们也应当意识到,学习形而上学等较为抽象、高级的学科时,很容易产生一种虚假的优越感,认为自己比那些「只知道实际应用的人」高一等,从而忽视了实践的重要性。这种做法是不可取的——例如,我不能因为研究因果关系而忽视数据挖掘调参技巧……总之,仰望星空,脚踏实地。
如果喜欢的话,不妨点个赞,让更多的人看到;欢迎关注我。



