
- 1【Linux】文件打包解压_tar_zip
- 2一个 3 年 Java 程序员 5 家大厂的面试总结(已拿 Offer)_3年后端大厂真实面经
- 3java8-Stream流_stream流复杂caoz
- 4【KTips】在Kotlin中实现一个十分简单的自循环状态机
- 5git Bash 生成SSH密钥步骤_gitbash密钥
- 6基于SpringBoot的美食分享平台_美食分享系统数据设计
- 7豆瓣读书top250数据爬取与可视化_书籍出版时间爬虫可视化怎么写
- 8微信公众号图片防盗链机制的应对办法^-^_mmbiz.qpic.cn
- 9Java配置方式使用Spring MVC_java spring mvc
- 10kkFileView部署
keras添加L1正则化,L2正则化和Dropout正则化及其原理_keras 正则化
赞
踩
一、什么是正则化,用来干嘛的?
正则化(regularization),是指在线性代数理论中,不适定问题通常是由一组线性代数方程定义的,而且这组方程组通常来源于有着很大的条件数的不适定反问题。大条件数意味着舍入误差或其它误差会严重地影响问题的结果。
因为机器学习的理论来源于数学,正则化的概念被很好的引用到机器学习模型中,主要作用是防止模型过拟合。
我们的模型训练时,比如常见的深度学习模型,可能往往会因为神经元的数目和网络的层数过于庞大,模型具有非常强大的学习能力,但是能力过强不是一件好事,因为过分学习了训练集的数据特点,能在训练集上取得一个非常好的结果,但是在测试集可能会随着训练误差反而不断变大,这就是常说的过拟合问题。
通常出现过拟合要么是数据集本身的质量问题,比如数据集内容分布不均匀,导致划分的训练集和测试集数据内容差别过大,特别是数据集本身数据量很少的时候,往往容易导致分布不均,所以后面又提出了很多数据增强的方法。再者是模型的问题,之前提到,如果模型过于复杂,拥有太过强大的学习能力,在训练集上表现很好但是测试集却越来越差,就是模型结构过于复杂导致的过拟合问题了,这个时候的解决方法就是减弱模型的复杂度,要么我们直接修改神经网络模型的层数或者每层神经元的个数,当然这样的方法很多时候不一定能带来好的效果,因为就是当我们的模型不能在训练集取得很好的拟合效果才考虑增大模型的复杂度,结果又导致过拟合问题,随着模型神经网络层数的增加,模型往往能够更好的学习到某些潜在的数据特征,所以最好是保证在原始的模型的结构基础不变的情况下做一定的修改,于是正则化被提出来使用。
正则化最直白的理解就是通过添加一些系数削弱深度学习模型中某些神经元输出的数据权重,因为神经网络就是靠这些神经元不断的拟合数据集,从而使得模型不会过分拟合训练集,而同时保证在验证集和训练集都有较好的效果。
二、L1正则化,L2正则化和Dropout正则化
2.1 L1正则化,L2正则化
L1正则化和L2正则化差别不大,先抛出公式如下:
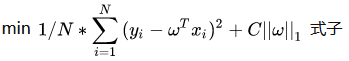
(L1正则化公式)
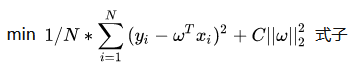
(L2正则化公式)
模型的目标是优化损失函数,上面的正则化公式就是在损失函数后面加上了所谓的正则项,可以看到L2仅仅是L1的正则项取平方,所以两者在结构上差别不大。C为一个常数系数,需要人为设置,w为和损失函数中的wT一样都是神经网络的权重参数。
直观理解为:因为模型的目标是优化损失函数,使得损失函数尽可能降低趋近于0,因为后面添加了这么一个正则项,于是损失函数被干扰,可以理解为,如果模型的学习能力过于强大(也就是容易出现过拟合问题),那么||w||也会增大,就会间接导致现在的损失函数变大(现在的损失函数是原来的损失函数的基础上加了正则项),那么模型又需要反复调节,使得不断训练达到一个w不会过分大和损失函数也尽可能小的平衡点,此时的话就有效的使得模型不会轻易过拟合。
但是在后来的发展中,L1和L2正则化不仅仅是对目标损失函数作用,也被利用作用在神经网络中每个神经元的权重参数w和b,或者激活函数中,其实现也是对这些参数添加一个正则项用来影响对数据集的拟合能力,这样一来L1和L2正则化方式和Dropout正则化方式有点相似了。
如果要想具体实现比较麻烦,不过keras里面已经封装好了具体的使用,后面会具体说明。
2.2 Dropout正则化
Dropout正则化相比L1和L2正则化方式比较简单粗暴,我们上面提到模型过于复杂(层数太多或者每层神经元太多),那么最直接的方式就是直接减少某些神经元的存在不就行了吗。Dropout的方式就是在模型训练中在某些神经元的输出部分随机产生一个很小权重系数并乘上这个输出,其作用是削弱这个神经元对整个模型拟合能力的作用,如果这个权重系数很小甚至趋近于0,那么就相当于这个神经元在神经网络中没有出现过,效果如下图所示。
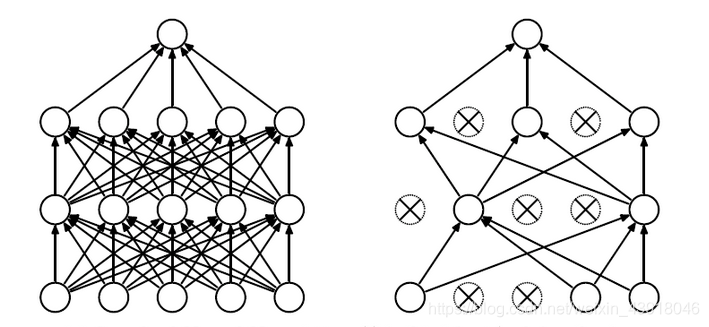
同样的Dropout在keras框架中也被进行了封装,甚至说,Dropout在神经网络中的使用频率比L1和L2正则化常见,可能是使用比较简单,效果也较好。
三、keras框架使用L1、L2和Dropout正则化
3.1 L1和L2正则化的添加使用
之前提高L1和L2后来被作用于神经元的权重w和偏置向量b或者激活函数部分,于是keras中也分别进行了封装如下:
kernel_regularizer:施加在神经元权重w上的正则项,为keras.regularizer.Regularizer对象。
bias_regularizer:施加在神经元偏置向量b上的正则项,为keras.regularizer.Regularizer对象。
activity_regularizer:施加在输出(激活函数)上的正则项,为keras.regularizer.Regularizer对象。
- 1
- 2
- 3
- 4
- 5
上面3个分别表示正则化的作用对象,keras中封装的可使用的正则项如下:
#其中0.01为上面2.1小节提到的常数系数C,自己设置
keras.regularizers.l1(0.01)#L1正则项
keras.regularizers.l2(0.01)#L2正则项
keras.regularizers.l1_l2(0.01)#结合了L1和L2的正则项
- 1
- 2
- 3
- 4
使用例子
from keras import regularizers
model.add(Dense(2, input_dim=10,#输入数据唯独10,输出唯独为2
kernel_regularizer=regularizers.l1(0.01),#在权重参数w添加L1正则化
bias_regularizer=regularizers.l2(0.01),#在偏置向量b添加L2正则化
activity_regularizer=regularizers.l1_l2(0.01),#在输出部分添加L1和L2结合的正则化
activation='relu'#激活函数采用ReLU
))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.2 Dropout正则化的添加使用
这个就很简单了,相比L1和L2比较简洁。
from keras.layers import Dropout
model.add(Dense(2, input_dim=10,#输入数据唯独10,输出唯独为2
activation='relu'#激活函数采用ReLU
))
model.add(Dropout(0.5))#直接在每层神经元后面添加,一般数值取0.5,也有取0.3,这个为Dropout率,可以理解为每个神经元被处理的概率。
- 1
- 2
- 3
- 4
- 5
希望我的分享对你的学习有所帮助,如果有问题请及时指出,谢谢~

