- 1Failed to connect to gitee.com 或者是remote: Incorrect username or password ( access token )_failed to authenticate to git remote
- 2mysql数据库_登录mysql
- 3微信小程序添加用户隐私保护指引_微信小程序隐私保护指引弹框实现
- 4[flink 实时流基础] 输出算子(Sink)_flink addsink
- 5香橙派5 RK3588 yolov5模型转换rknn及部署踩坑全记录 orangepi 5_rk3588 pt转onnx转rknn
- 6redis集群模式工作原理_**redis 集群模式的工作原理能说一下么?
- 7跨链技术深入_跨链标准模型
- 8Altera DDR3调试记录
- 9使用 Python 在 NLP 中进行文本预处理_短文本预处理
- 10无人棋牌室茶室台球室自习室共享棋牌室系统开发小程序开发
CDH6.3.2之各个组件服务的安装_cdh6.3.2各组件版本
赞
踩
CDH
概述
CDH是指Cloudera’s Distribution Including Apache Hadoop(包含Apache Hadoop的Cloudera发行版),是一套由Cloudera提供的大数据解决方案。
CDH是基于Apache Hadoop生态系统构建的,其中包括了Hadoop核心组件(如HDFS、YARN和MapReduce)以及其他相关的开源技术(如Hive、HBase、Spark、Impala等)。Cloudera通过将这些组件整合在一起,为企业提供了一个稳定、可靠、可扩展的数据处理平台。
在CDH中,Cloudera Manager是用于管理和监控整个集群的关键组件。它提供了一个易于使用的Web界面,用于集群配置、软件安装、性能监控和故障排除。
架构
Hadoop核心组件:
Hadoop Distributed File System (HDFS):用于存储和管理大规模数据集的分布式文件系统。
Yet Another Resource Negotiator (YARN):用于分配和管理集群资源以运行各种应用程序。
MapReduce:一种分布式数据处理框架,用于在集群上执行大规模数据处理任务。
- 1
- 2
- 3
- 4
- 5
数据存储和处理组件:
Hive:一个基于Hadoop的数据仓库基础架构,提供了类似于SQL的查询语言,方便进行数据分析和处理。
HBase:一个分布式的、面向列的NoSQL数据库,适用于高度可扩展的实时读写。
Spark:一个快速的、通用的大数据处理引擎,支持批处理、交互式查询和流式处理。
Impala:一个高性能的SQL查询引擎,可在Hadoop上实时查询存储在HDFS和HBase中的数据。
Solr:一个开源的、高性能的搜索平台,用于构建实时搜索和大规模分析应用。
Sqoop:用于在Hadoop和关系型数据库之间进行数据传输的工具。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
数据集成和流处理组件:
Kafka:一个高吞吐量的、分布式的流处理平台,用于处理实时数据流。
Flume:一个用于高效、可靠地从多个数据源采集、聚合和移动数据的分布式系统。
- 1
- 2
- 3
安全与管理组件:
Cloudera Manager:用于集群的配置、部署、监控和管理的全面管理平台。
Apache Sentry:提供细粒度的访问控制和权限管理,以保护敏感数据。
Apache Knox:提供了一个单一的访问点和API网关,用于安全地访问和管理Hadoop集群。
- 1
- 2
- 3
- 4
- 5
创建数据库
创建各组件需要的数据库
CREATE DATABASE hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
CREATE DATABASE oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
CREATE DATABASE hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
CREATE DATABASE sentry DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
安装Kafka服务
在CDH中,各个组件服务的安装、配置方式大同小异,这里以安装Kafka组件服务为例说明
添加服务
在首页,点击添加服务

进入服务列表,选择Kafka服务

Kafka的Broker选择三台机器
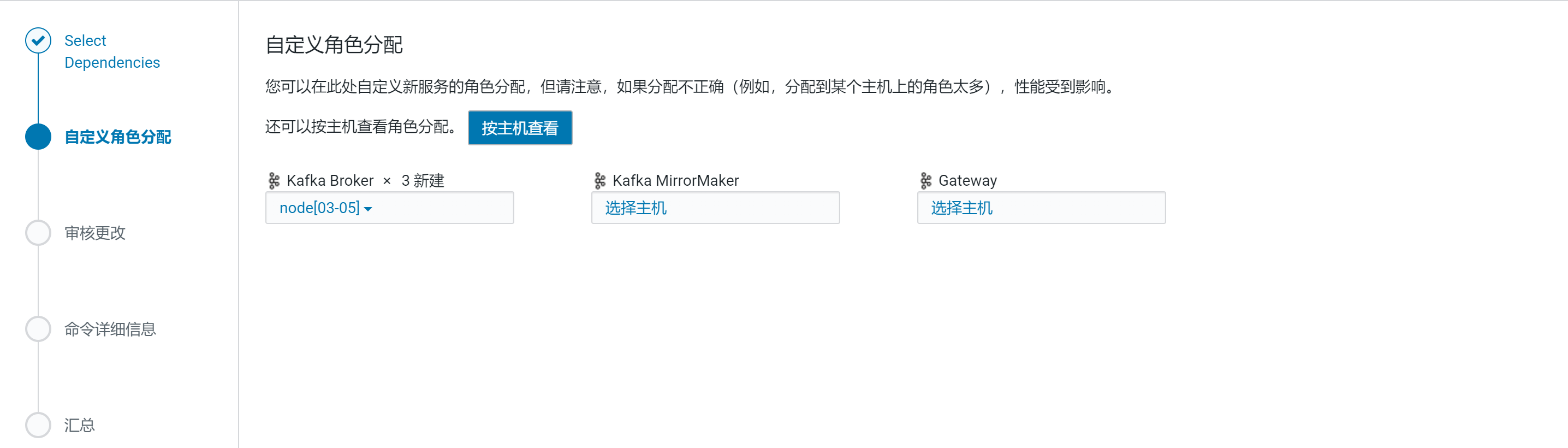
配置
在审核更改中调整堆内存大小,其他配置默认即可

等待安装
Kafka命令使用
创建Kafka Topic
/opt/cloudera/parcels/CDH/bin/kafka-topics --bootstrap-server node03:9092,node04:9092,node05:9092 --create --replication-factor 1 --partitions 1 --topic test
kafka-topics --bootstrap-server node03:9092,node04:9092,node05:9092 --create --replication-factor 1 --partitions 1 --topic test
- 1
- 2
- 3
查看Kafka Topic
/opt/cloudera/parcels/CDH/bin/kafka-topics --zookeeper node03:2181 --list
kafka-topics --zookeeper node03:2181 --list
- 1
- 2
- 3
删除Kafka Topic
/opt/cloudera/parcels/CDH/bin/kafka-topics --delete --bootstrap-server node03:9092,node04:9092,node05:9092 --topic test
kafka-topics --delete --bootstrap-server node03:9092,node04:9092,node05:9092 --topic test
- 1
- 2
- 3
其他组件安装
在CDH中,各个组件服务的安装大同小异,参考上述Kafka安装,进行下列常用组件的安装
安装Flume服务
选择添加Flume服务

选择Flume依赖哪些服务
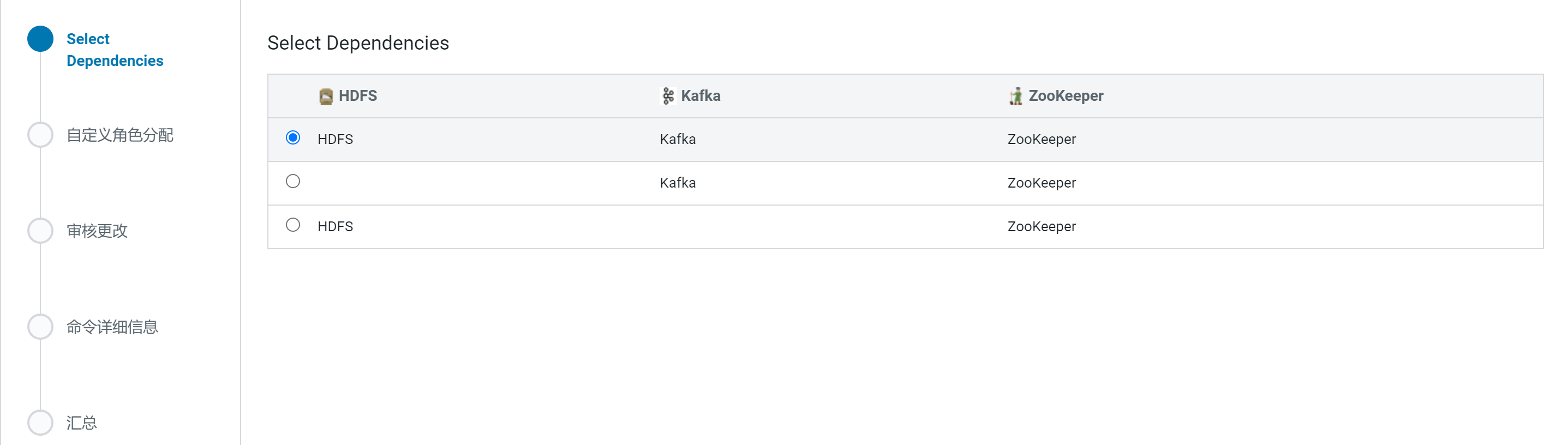
分配Flume Agent所处节点

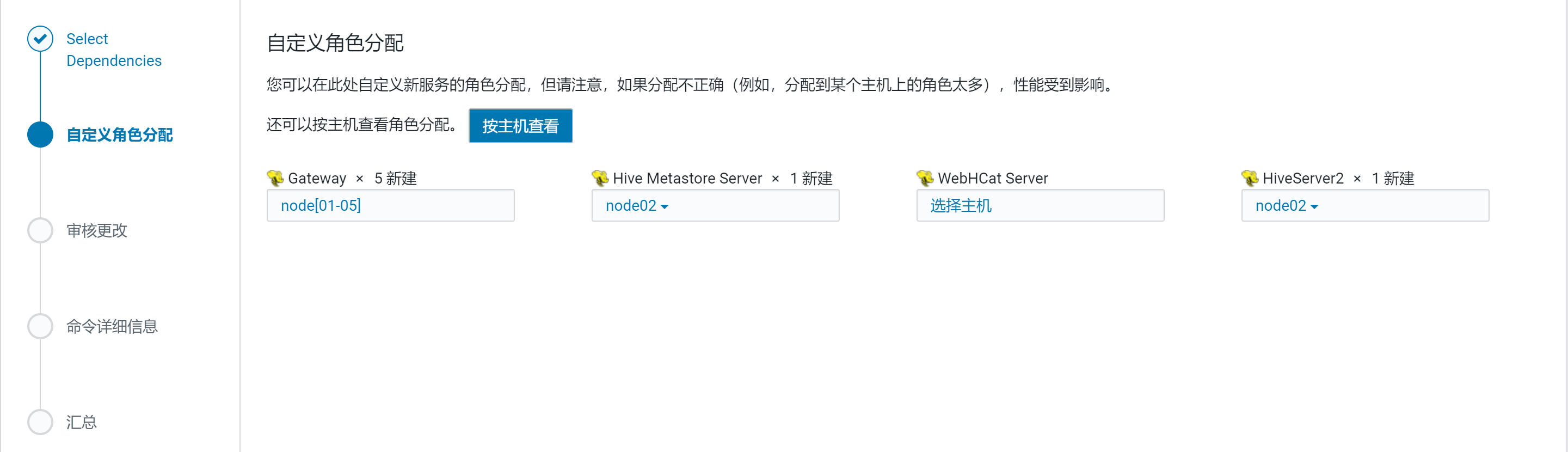
安装Hive服务
选择添加Hive服务

将 Hive 服务添加到 Cluster
配置hive元数据
出现异常:
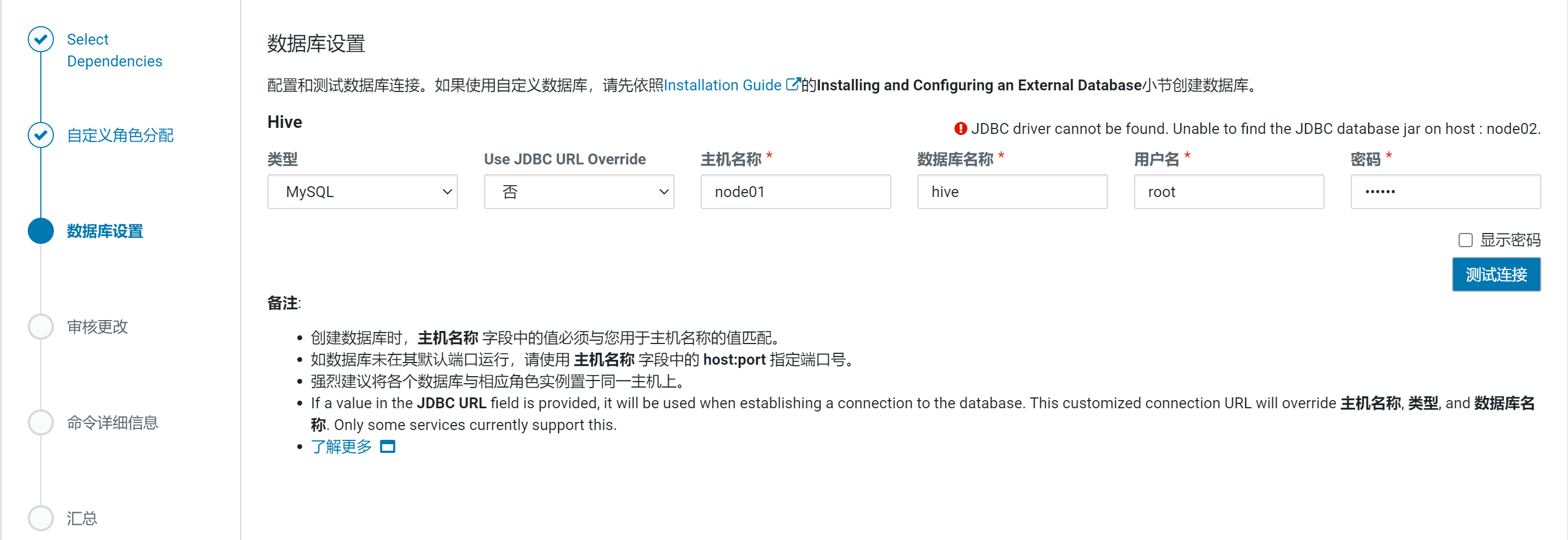
解决方案:拷贝mysql-connector-java.jar,分发到各个节点的/usr/share/java/目录
[root@node01 ~]# ./sync.sh /usr/share/java/mysql-connector-java.jar
- 1
重新测试
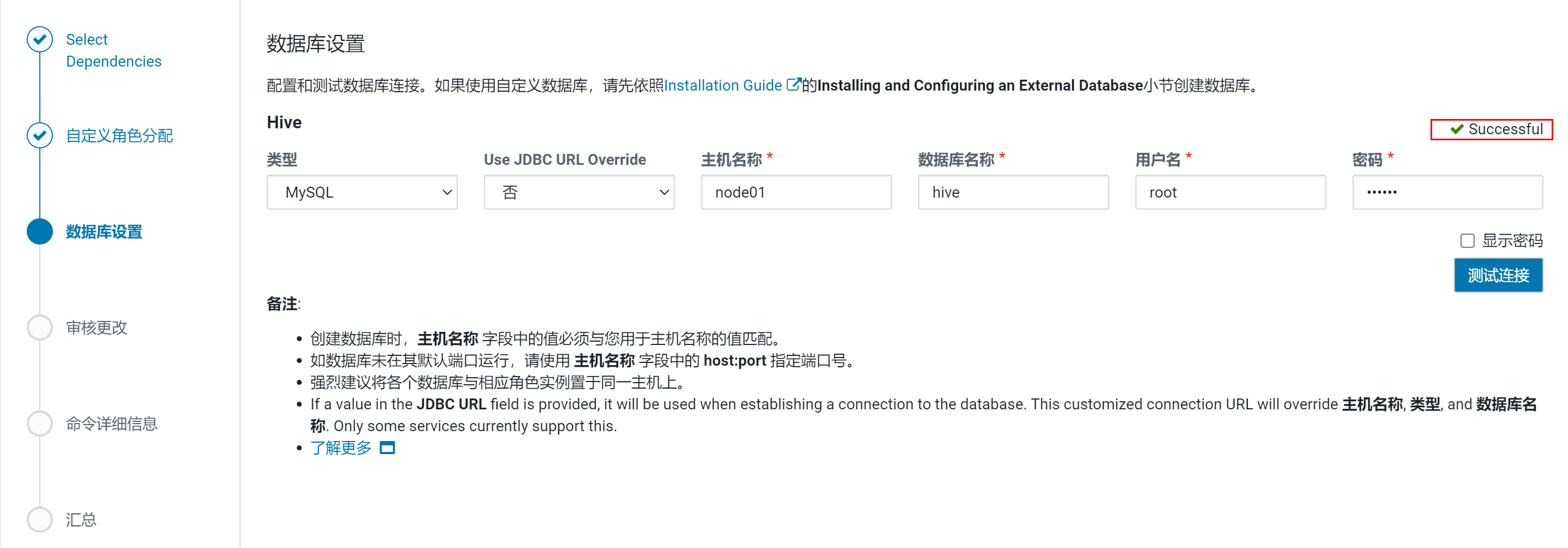
使用默认配置
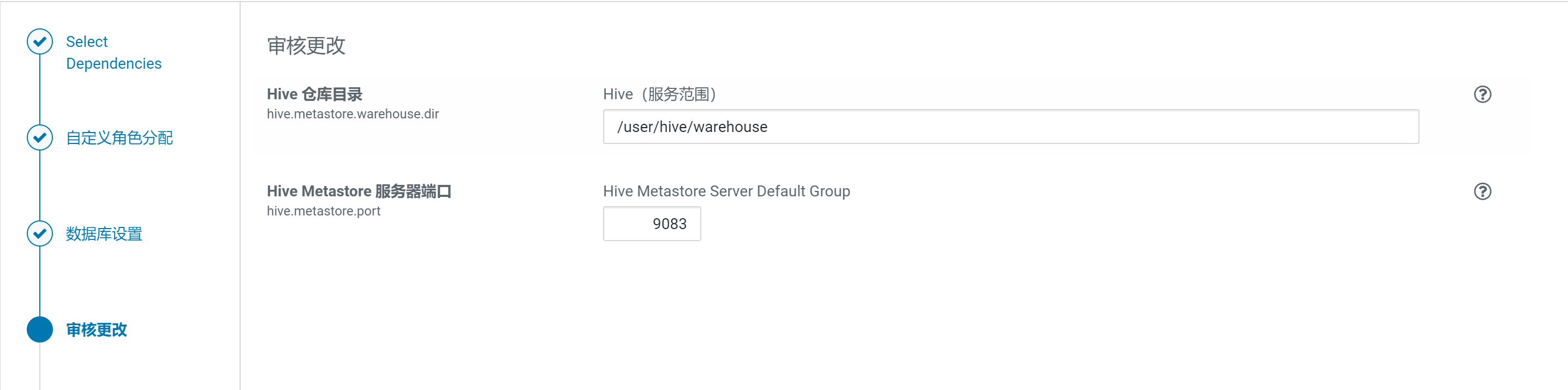
安装后自动启动Hive进程
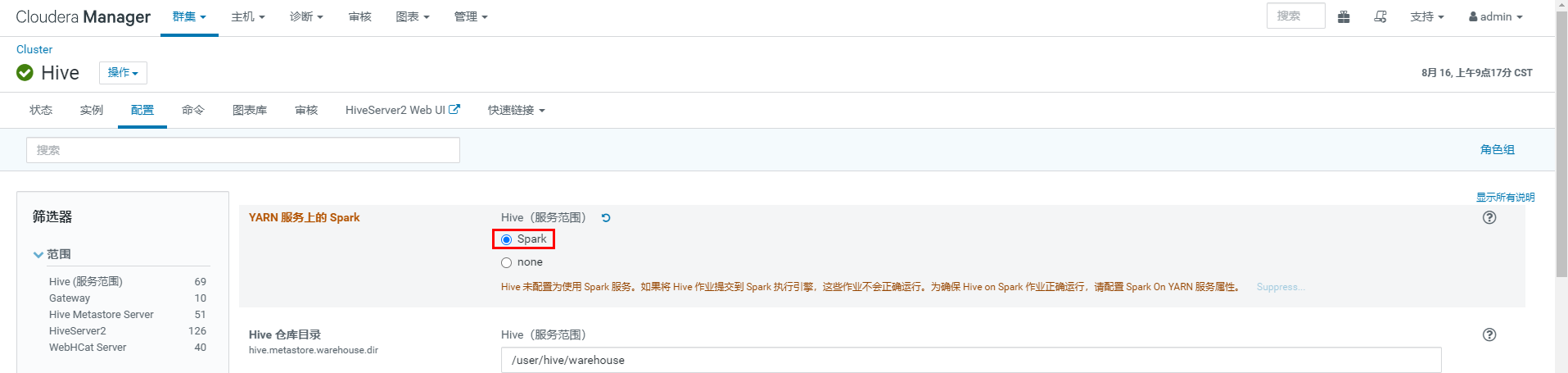
注意:在安装Spark后,配置Hive On Spark,然后重启Hive
安装Spark服务
添加Spark服务

CDH6.x自带spark2.4无需升级
分配节点

集群设置全部选择默认即可
等待安装
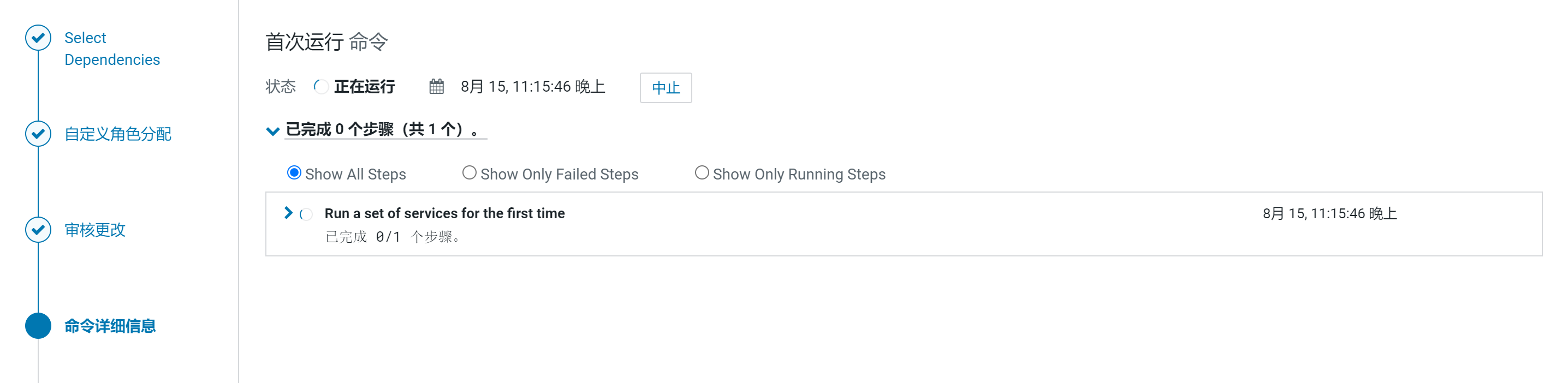
点击进行重启

在安装Spark后,配置Hive On Spark,然后重启Hive
安装OOZIE服务
选择添加OOZIE服务

分配节点


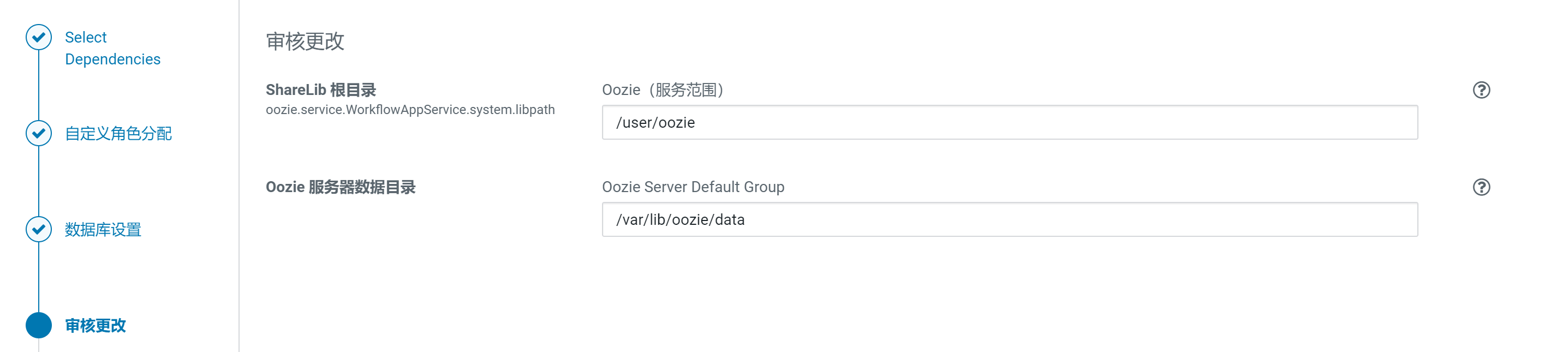
配置Oozie元数据

使用默认配置
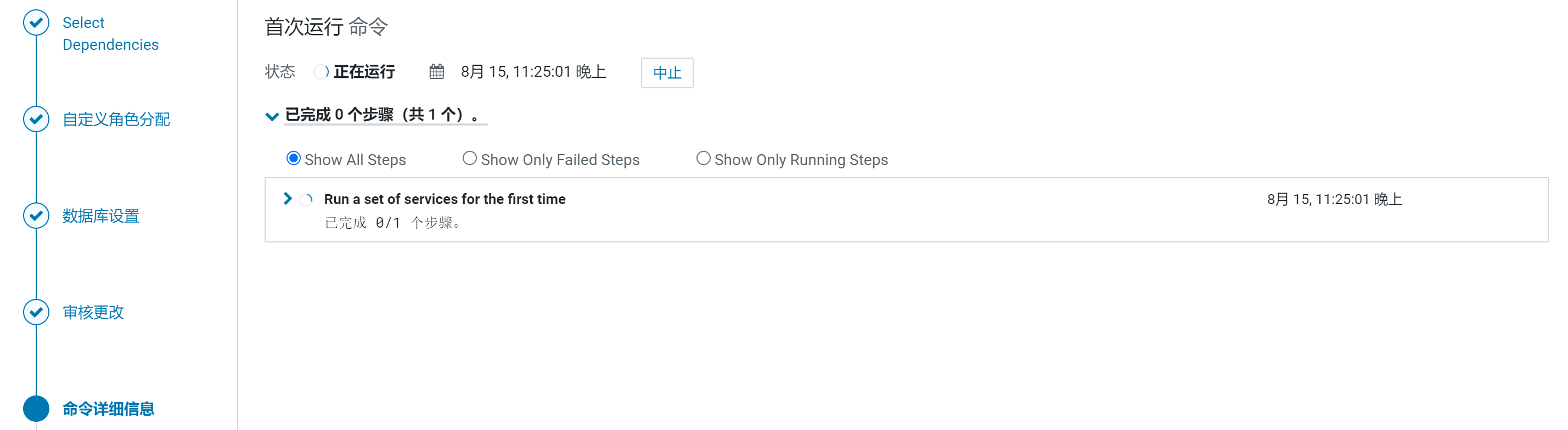
等待安装并启动oozie

安装HUE服务
选择添加Hue服务

分配节点


配置hue元数据

等待安装并自动启动hue进程
安装Flink服务
Flink服务也是大数据领域中一个常见服务,然而CDH6.3.2版本没有包含Flink服务,因此需要手动编译Flink
下载相关配置包
查看CDH各个组件版本信息,与Hive2.1.1匹配的Flink版本是flink-1.13.6

下载Flink安装包
wget https://archive.apache.org/dist/flink/flink-1.13.6/flink-1.13.6-bin-scala_2.11.tgz
- 1
下载Flink源码包
wget https://archive.apache.org/dist/flink/flink-1.13.6/flink-1.13.6-src.tgz
- 1
安装Maven
下载Maven
wget https://archive.apache.org/dist/maven/maven-3/3.8.8/binaries/apache-maven-3.8.8-bin.tar.gz
- 1
参考:Maven安装与配置
Flink的CDH版本编译配置
解压Flink源码包
tar -axvf flink-1.13.6-bin-scala_2.11.tgz
tar -axvf flink-1.13.6-src.tgz
mv flink-1.13.6 flink-src
- 1
- 2
- 3
- 4
flink的pom.xml文件
<flink.hadoop.version>3.0.0-cdh6.3.2</flink.hadoop.version>
<hive.version>2.1.1-cdh6.3.2</hive.version>
- 1
- 2
- 3
在<repositories> 标签中添加如下内容
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>confluent-repo</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
修改vim /root/flink-src/flink-connectors/flink-sql-connector-hive-2.3.9/pom.xml文件
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1-cdh6.3.2</version>
- 1
- 2
- 3
编译Flink
mvn clean install -DskipTests -Dfast -Drat.skip=true -Dhaoop.version=3.0.0-cdh6.3.2 -Dinclude-hadoop -Dscala-2.11 -T10C
- 1
拷贝编译成功的flink-sql-connector-hive到flink的lib目录下
[root@node01 ~]#cp flink-src/flink-connectors/flink-sql-connector-hive-2.2.0/target/flink-sql-connector-hive-2.2.0_2.11-1.13.6.jar /usr/local/flink/lib/
# 拷贝hive-exec-2.1.1-cdh6.3.2.jar、libfb303-0.9.3.jar
[root@node01 ~]#cp /opt/cloudera/parcels/CDH/jars/hive-exec-2.1.1-cdh6.3.2.jar /usr/local/flink/lib/
[root@node01 ~]#cp /opt/cloudera/parcels/CDH/jars/libfb303-0.9.3.jar /usr/local/flink/lib/
- 1
- 2
- 3
- 4
- 5
拷贝相关hadoop包
[root@node01 ~]#cp /opt/cloudera/parcels/CDH/jars/hadoop-common-3.0.0-cdh6.3.2.jar /usr/local/flink/lib/
[root@node01 ~]#cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-common-3.0.0-cdh6.3.2.jar /usr/local/flink/lib/
[root@node01 ~]#cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar /usr/local/flink/lib/
[root@node01 ~]#cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-hs-3.0.0-cdh6.3.2.jar /usr/local/flink/lib/
[root@node01 ~]#cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.3.2.jar /usr/local/flink/lib/
- 1
- 2
- 3
- 4
- 5
制作Flink的parcel包和csd文件
1.将lib包含了复制进去的jar的Flink完整包进行压缩
[root@node01 ~]# cd /usr/local
[root@node01 local]#tar -zcvf flink-1.13.6-cdh6.3.2.tgz flink
- 1
- 2
2.下载制作脚本
[root@node01 local]# yum install git
[root@node01 local]# git clone https://github.com/YUjichang/flink-parcel.git
加速地址: git clone https://gitclone.com/github.com/YUjichang/flink-parcel.git
- 1
- 2
- 3
- 4
3.修改脚本配置
[root@node01 local]# cd flink-parcel/
[root@node01 flink-parcel]# vim flink-parcel.properties
- 1
- 2
#FLINk存放目录地址
FLINK_URL= /usr/local/flink-1.13.6-cdh6.3.2.tgz
#flink版本号
FLINK_VERSION=1.13.6
#扩展版本号
EXTENS_VERSION=CDH6.3.2
#操作系统版本,以centos为例
OS_VERSION=7
#CDH 小版本
CDH_MIN_FULL=6.0
#CDH大版本
CDH_MAX_FULL=6.4
CDH_MIN=5
CDH_MAX=6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4.运行 build.sh脚本,开始构建parcel和csd
[root@node01 flink-parcel]# ./build.sh parcel
[root@node01 flink-parcel]# ./build.sh csd
- 1
- 2
5.编译完成后,生成的Flink的parcel和csd文件
FLINK_ON_YARN-1.13.6.jar
FLINK-1.13.6-CDH6.3.2-el7.parcel
FLINK-1.13.6-CDH6.3.2-el7.parcel.sha
manifest.json
- 1
- 2
- 3
- 4
- 5
6.向CM中添加Flink服务
cp FLINK-1.13.6-CDH6.3.2-el7.parcel /opt/cloudera/parcel-repo/
cp FLINK-1.13.6-CDH6.3.2-el7.parcel.sha /opt/cloudera/parcel-repo/
- 1
- 2
- 3
直接向CM中添加Flink服务
1.拷贝镜像包到cloudera的parcel-repo中
root@node01 local]# tar -zxvf flink-1.13.6-cdh6.3.2_parcel.tar.gz
[root@node01 local]# cd flink-1.13.6-cdh6.3.2/
[root@node01 flink-1.13.6-cdh6.3.2]# ll
total 377276
-rwxrwxrwx 1 root root 386296010 Aug 30 11:51 FLINK-1.13.6-CDH6.3.2-el7.parcel
-rwxrwxrwx 1 root root 40 Aug 30 11:51 FLINK-1.13.6-CDH6.3.2-el7.parcel.sha
-rwxrwxrwx 1 root root 21123 Aug 30 11:51 FLINK_ON_YARN-1.13.6.jar
-rwxrwxrwx 1 root root 841 Aug 30 11:52 manifest.json
[root@node01 flink-1.13.6-cdh6.3.2]# cp FLINK-1.13.6-CDH6.3.2-el7.parcel /opt/cloudera/parcel-repo/
[root@node01 flink-1.13.6-cdh6.3.2]# cp FLINK-1.13.6-CDH6.3.2-el7.parcel.sha /opt/cloudera/parcel-repo/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在cloudera的parcel-repo中得manifest.json文件添加Flink.parcel相关得加载依赖配置
vim /opt/cloudera/parcel-repo/manifest.json
- 1
[ { "Components": [ { "Pkg_version": "", "Version": "6", "Name": "", "Pkg_release": "" } ], "Hash": "", "Parcelname": "", "Replaces": "" }, { "Components": [ { "Pkg_version": "flink1.13.6", "Version": "flink1.13.6", "Name": "flink", "Pkg_release": "cdh6.3.2" } ], "Hash": "4e1a65e353d2e36c7e9d12a912eb8516a7f486f5", "Parcelname": "flink-1.13.6-cdh6.3.2-el7.Parcel", "Replaces": "flink" } ]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
3.拷贝FLINK_ON_YARN到cloudera的csd中
[root@node01 software]# cd flink-1.13.6-cdh6.3.2/
[root@node01 flink-1.13.6-cdh6.3.2]# cp FLINK_ON_YARN-1.13.6.jar /opt/cloudera/csd/
[root@node01 flink-1.13.6-cdh6.3.2]# systemctl restart cloudera-scm-server
- 1
- 2
- 3
4.重启后在CM页面进行分配和激活




5.添加Flink服务配置和集群规划



重启
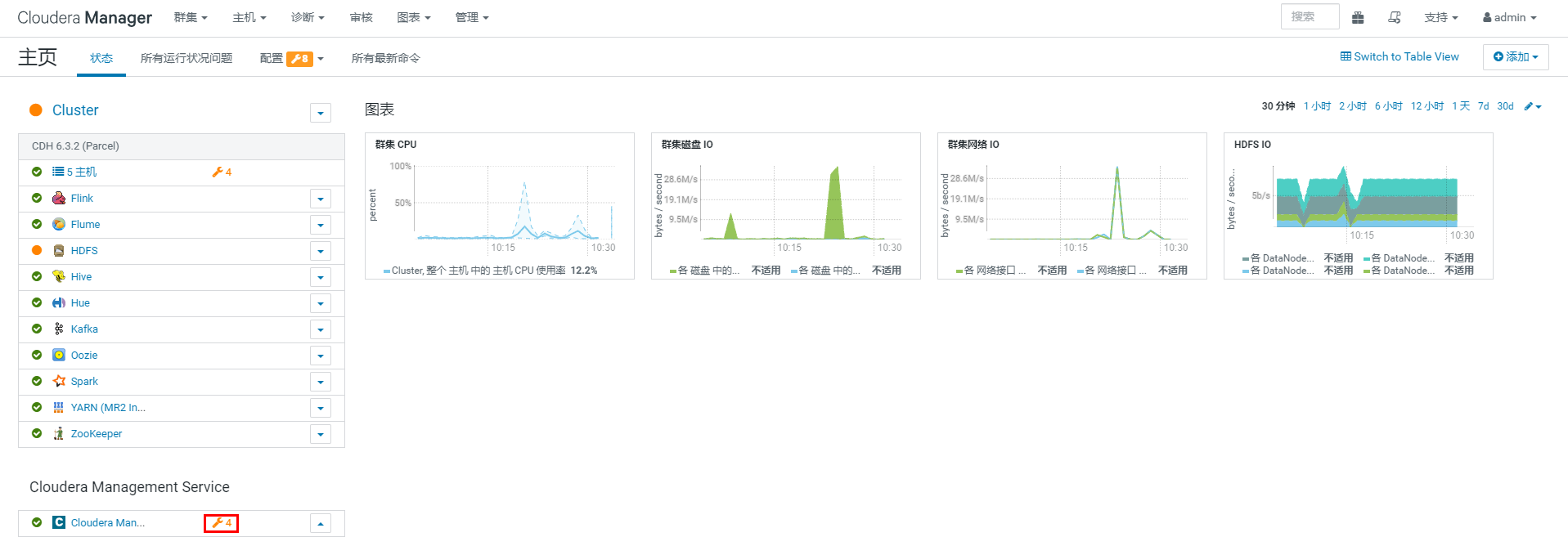
验证Flink服务
1.使用yarn-per-job模式跑wordcount测试flink_on_yarn
[root@node01 ~]# chmod 777 /opt/cloudera/parcels/FLINK/bin/flink
[root@node01 ~]# sudo -u hdfs /opt/cloudera/parcels/FLINK/bin/flink run -t yarn-per-job /opt/cloudera/parcels/FLINK/lib/flink/examples/batch/WordCount.jar
- 1
- 2
Printing result to stdout. Use --output to specify output path. 2023-08-16 10:37:33,318 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/etc/flink/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file. 2023-08-16 10:37:33,589 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2023-08-16 10:37:33,747 INFO org.apache.hadoop.conf.Configuration [] - resource-types.xml not found 2023-08-16 10:37:33,747 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils [] - Unable to find 'resource-types.xml'. 2023-08-16 10:37:33,801 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=2048, taskManagerMemoryMB=2048, slotsPerTaskManager=1} 2023-08-16 10:37:36,652 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1692149627327_0002 2023-08-16 10:37:36,893 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1692149627327_0002 2023-08-16 10:37:36,894 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated 2023-08-16 10:37:36,895 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED 2023-08-16 10:37:43,446 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully. 2023-08-16 10:37:43,447 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node05:8080 of application 'application_1692149627327_0002'. Job has been submitted with JobID c0b4b89406f6fee0a4c3f6b95bb0ee67 Program execution finished Job with JobID c0b4b89406f6fee0a4c3f6b95bb0ee67 has finished. Job Runtime: 12175 ms Accumulator Results: - 7611dc575cfdcecc9d3528d9326c6aba (java.util.ArrayList) [170 elements] (a,5) (action,1) (after,1) (against,1) (all,2) (and,12) (arms,1) (arrows,1) (awry,1) (ay,1) (bare,1) (be,4) (bear,3) (bodkin,1) (bourn,1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
2.浏览器访问:http://IP:8088/cluster查看执行

3.验证Hive_FlinkSQL
[root@node01 ~]# /opt/cloudera/parcels/FLINK/bin/flink-sql-client
- 1