
- 1PostgreSQL物化视图相关操作,materialized view 不阻塞刷新_refresh materialized view
- 2【Spark编程基础】实验一Spark编程初级实践(附源代码)_spark实验一
- 3华为2288H V5 找不到本地启动项,进不了raid配置界面_2288hv5启动项
- 4MATLAB基于领航追随法的车辆编队控制,领航追随者与人工势场法的简单融合实现避障_领航跟随法车辆编队
- 5程序员感情生活大揭秘,想脱单的进......
- 6JSON parse error: Cannot deserialize value of type `java.lang.String` from Object value (token `Json
- 7【定位问题】chan算法、chan-Taylor算法移动基站(不同数量基站)无源定位【含Matlab源码 3148期】_chan定位算法
- 8c++图形界面开发中,Qt和MFC谁更胜一筹?_qt和mfc哪个界面开发更好
- 9深度解析 Spring 源码:三级缓存机制探究_spring 三级缓存源码解析
- 10将voc数据集划分为训练集测试集_voc 切分训练集
【Linux】项目自动化构建工具——make/Makefile及拓展_linux makefile编译并安装新app
赞
踩

一、Linux项目自动化构建工具-make/Makefile
1、背景知识
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率 .make是一个命令工具,是一个解释makefile中指令的命令工具
make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建
2、实现代码
我们先来看一下具体是怎么一回事:
创建文件mycode.c利用vim进入编写一个简单的程序,创建文件makefile(m可以大写)编写依赖关系和依赖方法,最后直接通过make完成编译。生成mycode
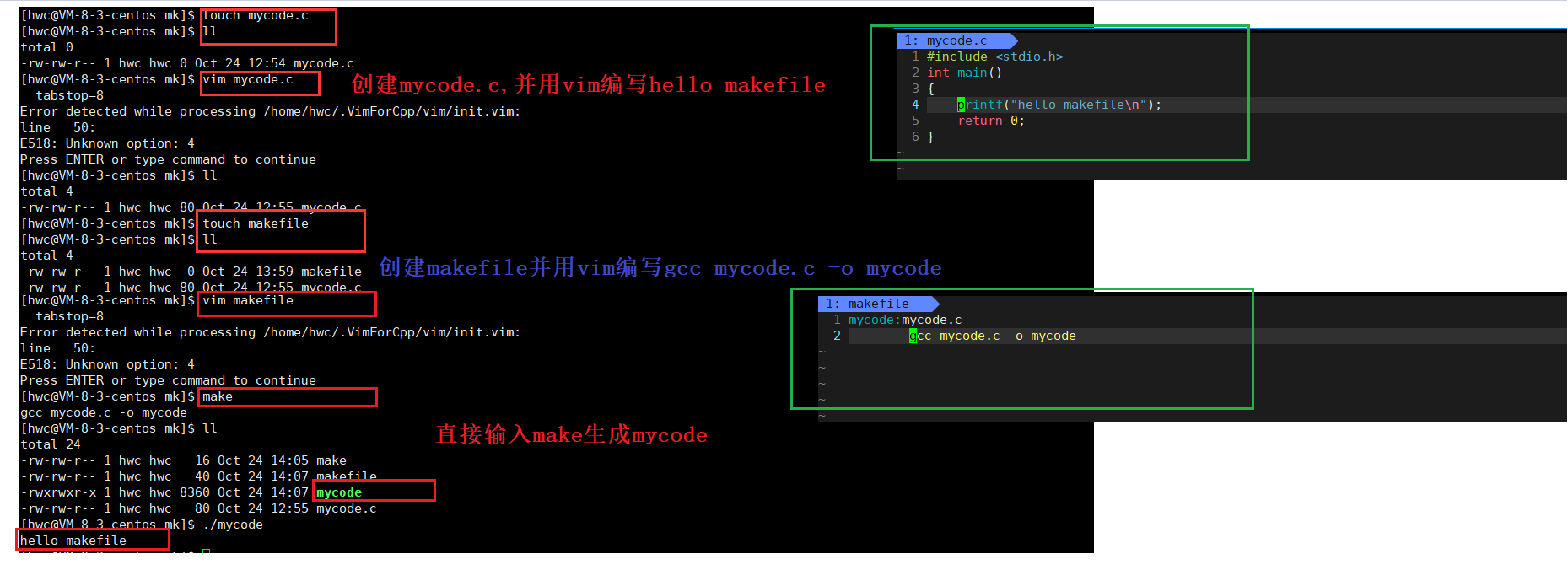
3、原理
makefile的具体原理:
必须包含依赖关系和依赖方法
makefile存在的意义,为了构建项目。对于上面的例子,mycode的形成依赖于mycode.c,所以需要把mycode.c进行编译线程mycode
初识makefile的语法
第一步,建立依赖关系,谁依赖:于谁(比如mycode依赖于mycode.c,因为mycode.c是我们自己创建出来的,mycode是通过其编译出来的)
第二步,新起一行,必须以tab键开头,gcc mycode.c -o mycode


4、清理
4.1.清理文件/临时数据

不需要我们再去使用gcc命令了。同时,这里我们需要知道:

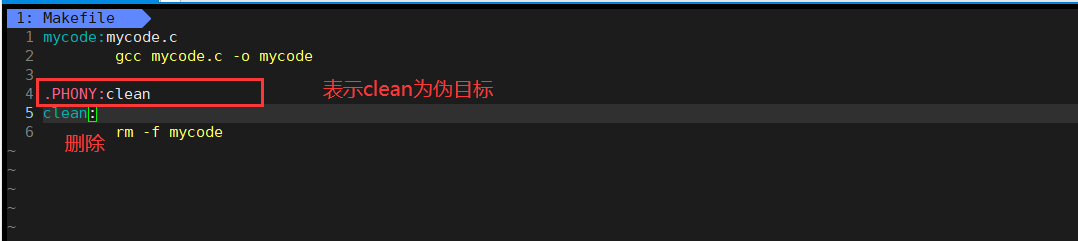
4.2.伪目标
这里的.PHONY:被该关键字修饰的对象是一个伪目标。但是如果我们一直make clean呢

伪目标表示该目标总是被执行的

4.3.三个时间
这里插入另一个问题,gcc是如何得知不需要编译了的(在没有加伪目标下,直接显示…is up to date.):(比较时间)

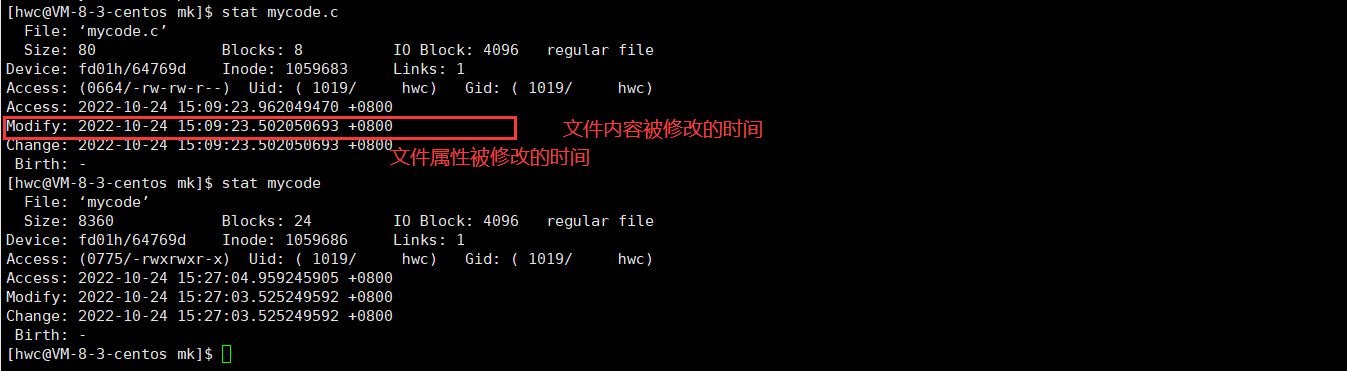
modify和chance的时间改变容易理解,但是对于Access时间的改变:
由于access访问的频率太高,一直被修改,导致负担过大。新内核对其进行了修正,根据一段时间内访问频率再去更新。
在第一次编译的时候一定先有源文件,再有可执行程序,所以第一次的mycode.c的modify时间要比mycode的modify时间要更早
如果后来mycode没修改,而把mycode.c修改了。所以识别就看mycode.c时间是不是比mycode的时间更新,如果更新,就重新编译。
简单验证一下把:
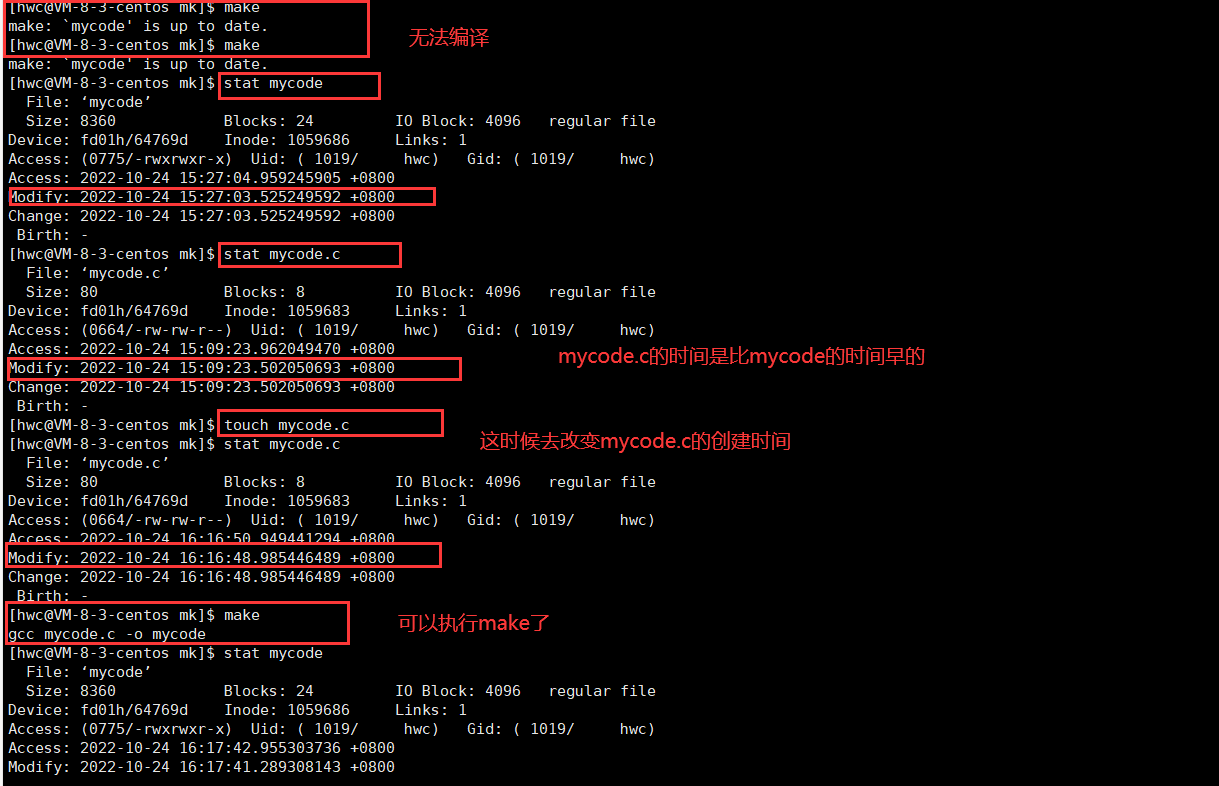
所以用.PHNOY不需要根据时间来做对比。每次都需要编译。
make默认从上到下执行,第一个被找到的直接用make执行,总是调用第一个,后面不在执行。而调用其他的需要手动指明
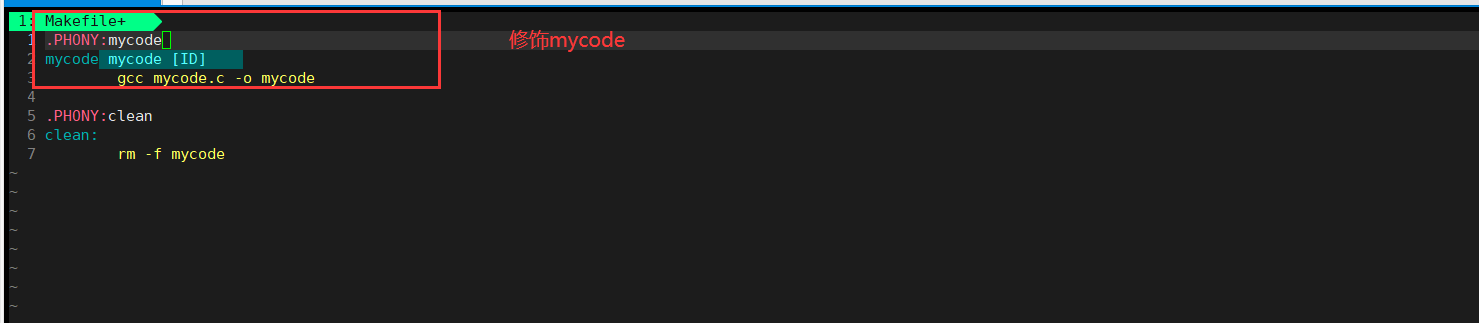
5、推导规则
理解makefile的推导规则:还是mycode.c到mycode的过程,不过我们需要把过程细化出来,把推导关系完善:
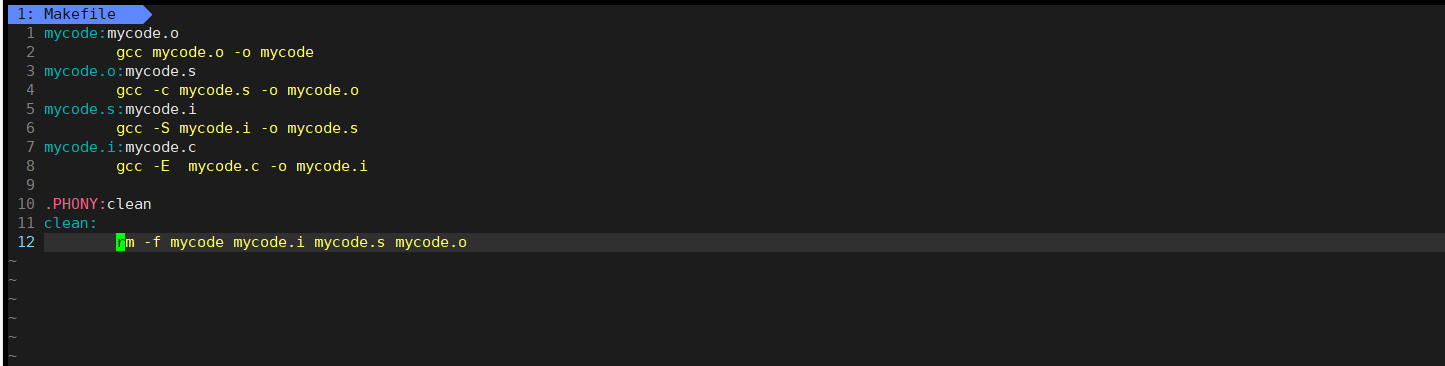

可以看出,这是逆着来的。在make推导的时候会根据依赖关系而推导,从上到下,当依赖文件列表不存在会继续根据依赖文件列表所对应的项而继续。
不过平时直接一步到位即可
二、小程序进度条
- 缓冲区问题
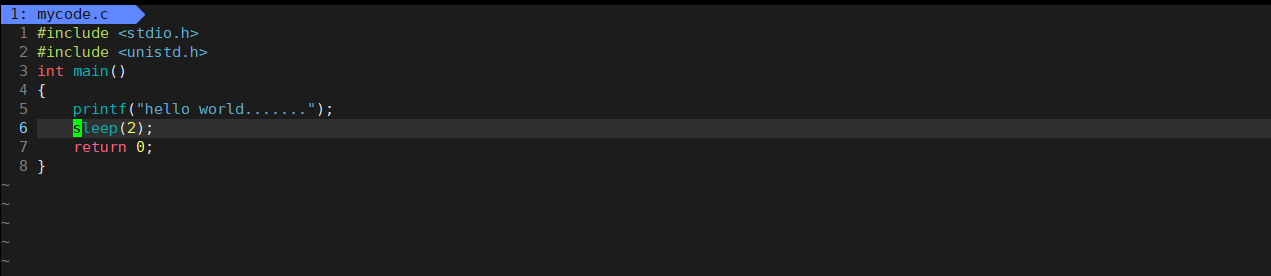

效果是先睡眠在打印,我们可以知道先printf,但是执行完printf后数据没被显示出来,在sleep期间,printf已经执行打印了,但是数据在缓冲区中,这就是为什么会先睡眠后才把数据显示出来。要把数据立即显示出来,我们直接刷新缓冲区,fflush(stdout)
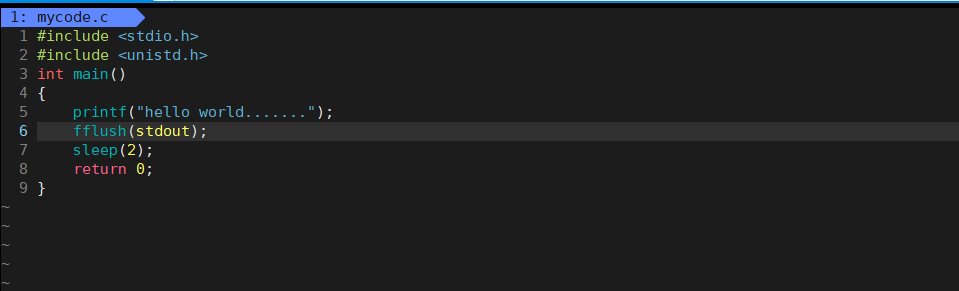

但是直接在printf中加上\n也可以直接显示出来,\n是行缓冲
同时,\r称为回车,\n称为换行,所以\r\n就是回车换行,但是在语言层面,\n就是回车换行
到这里,我们可以利用上面的写10个倒计时:
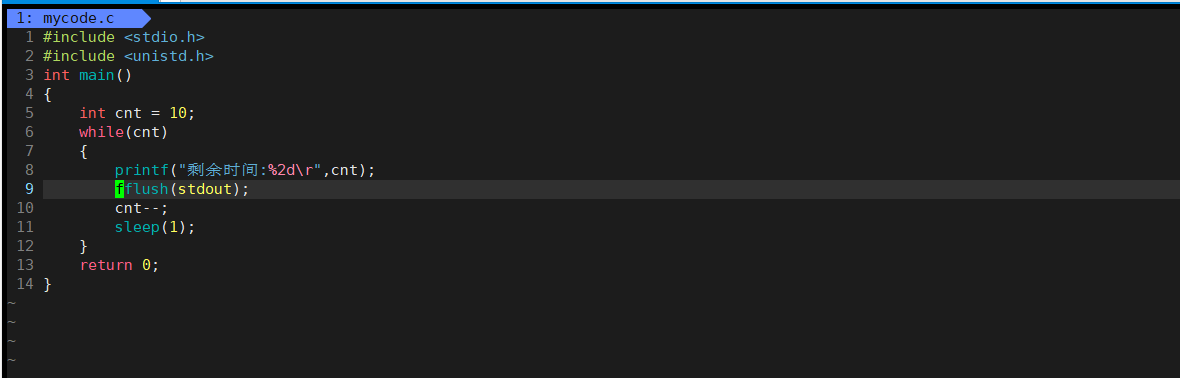

有了上面的铺垫之后,下面,我们直接来写一个进度条:
所创建的文件:

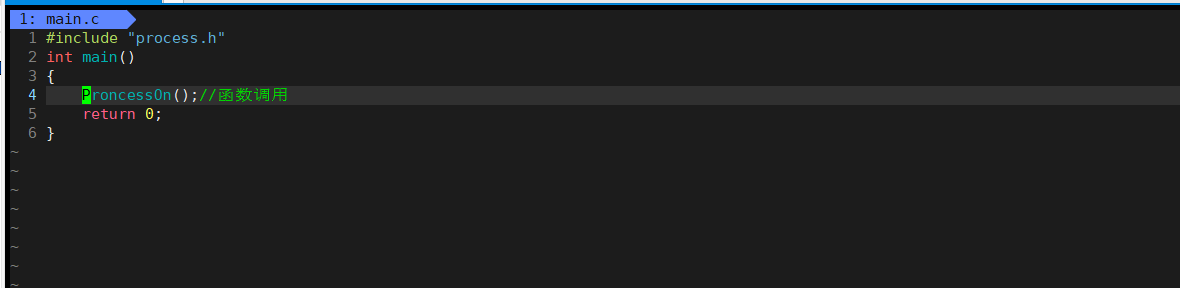
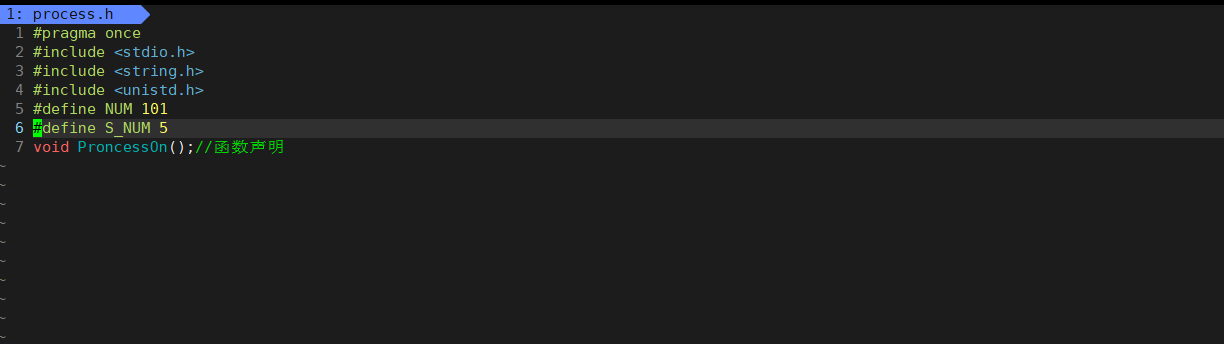
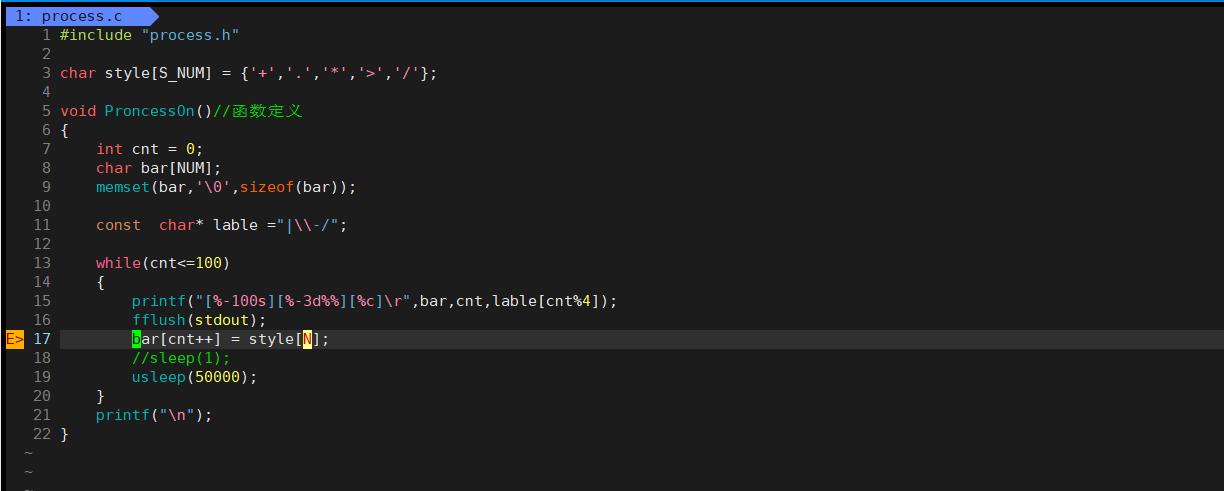
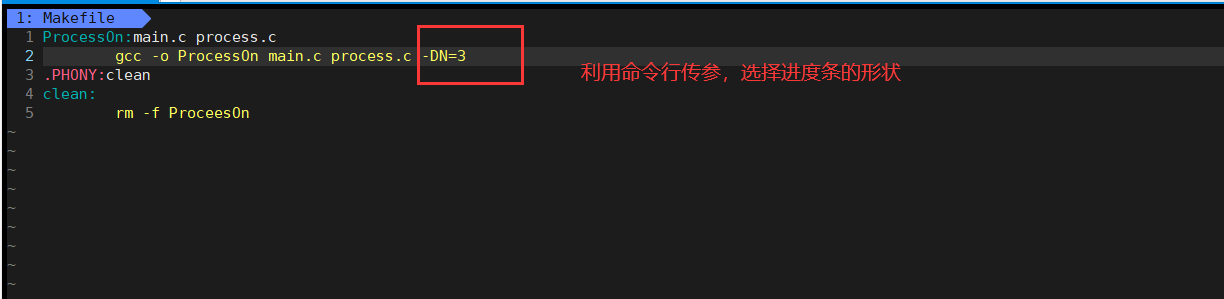

三、拓展
使用 git 命令行
这里以gitee为例子。
- git clone
克隆远程仓库
git clone
- 1
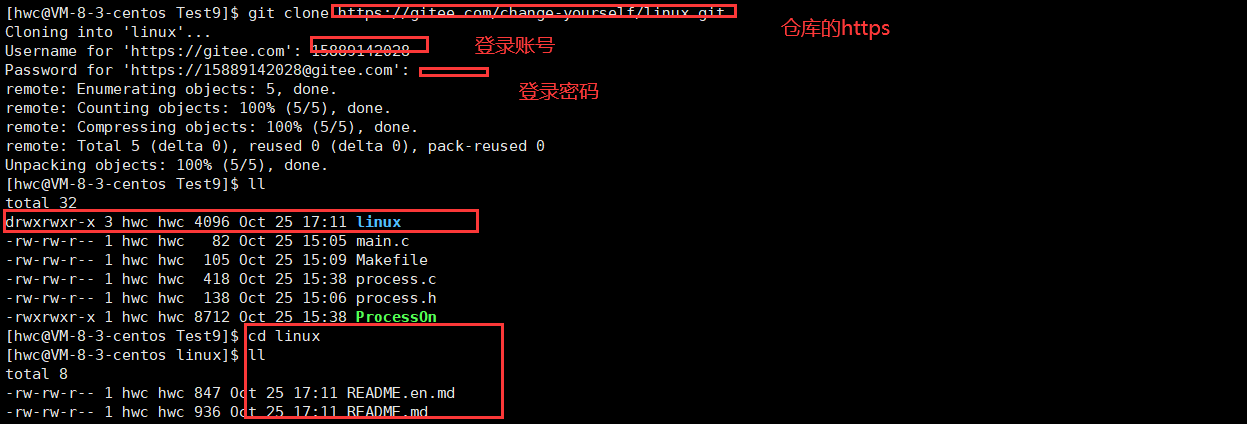

.gitignore凡事这个文件内部的后缀,都不会被上传到gitee上的。
所谓的git仓库,本质就是一个目录,以及里面的内容。而push到远端就是将.git的内容同步到gitee上
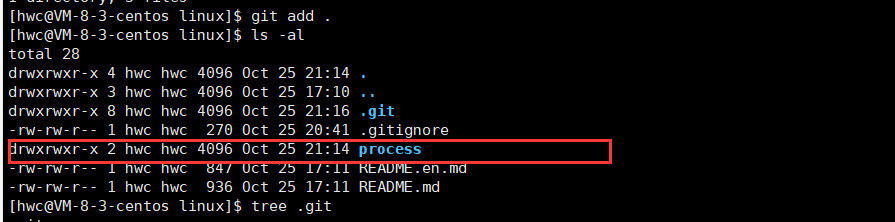
- git.add
将新增的文件添加到本地仓库
- git commit
提交。-m 后面加上提交的日志

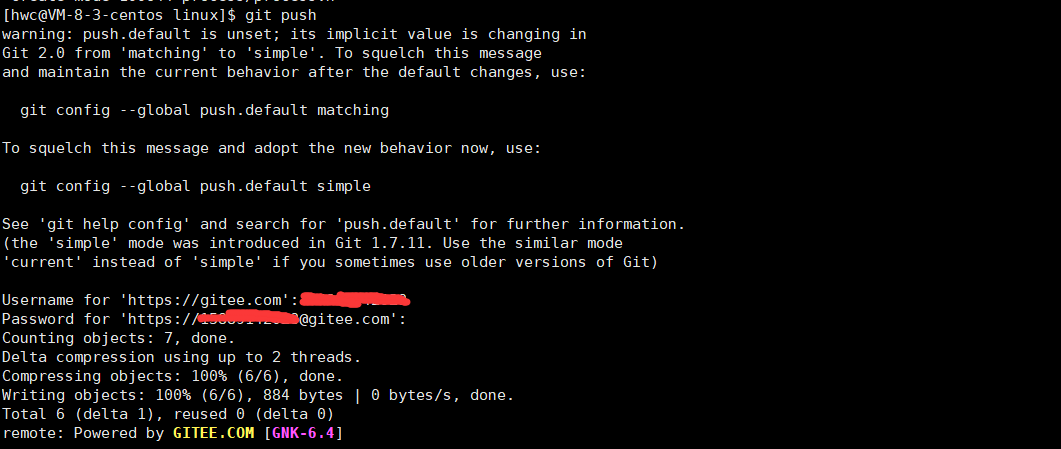
- git push
将本地内容推送到远端

- git log
查看提交日志
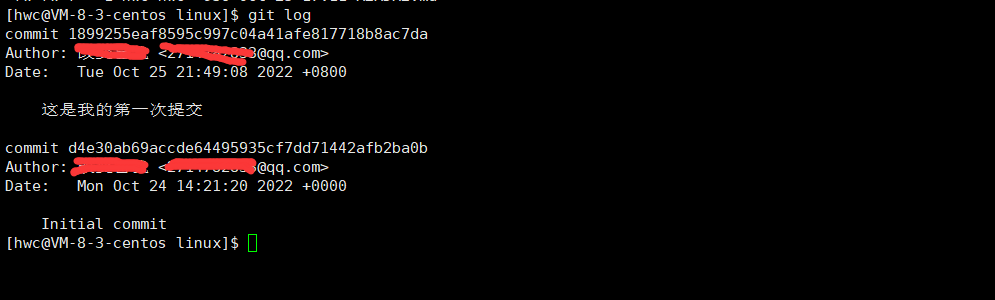
- git status
查看当前状态

当文件发生变化时:
- git pull
把远端拉到本地同步。(如果远端和本地都同步进行修改了,起冲突了,直接先pull一下)
此外,对于git push的时候要输入用户名和密码可以配置成免密码的。


