
- 1git merge之后,如何进行撤销_git merge 撤回
- 2L1-080 乘法口诀数列 (20 分)_l1-080 乘法口诀数列 分数 20 作者 陈越 单位 浙江大学 本题要求你从任意给定的两
- 3python 数据分析概述
- 4laravel5.4+vue+element-ui配置及简单使用_laravel 使用 elementui
- 5Hugging Face Transformers 学习1_can't load the configuration of 'distilbert-base-u
- 6iptables防火墙详解_iptables:将链设置为策略接受:过滤iptables:刷新防火墙
- 7创建跟踪和查看执行计划需要的权限
- 8Pytorch总结三之 softmax回归用于分类问题_python 用softmax实现分类结果
- 9红队内网攻防渗透:内网渗透之内网和域信息收集
- 10表情识别-情感分析-人脸识别(代码+教程)_情感计算之人脸表情识别
一文弄懂索引数据结构 B+Tree_索引是几叉树b+树
赞
踩
索引在 MySQL 数据库中分三类:
- B+ 树索引
- Hash 索引
- 全文索引
我们今天要介绍的是工作开发中最常接触到的 InnoDB 存储引擎中的 B+ 树索引。
五、B+比B树更适合实际应用中操作系统的文件索引和数据库索引
一、什么是索引?
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
二、索引的优缺点
1、优点
索引大大减小了服务器需要扫描的数据量
索引可以帮助服务器避免排序和临时表
索引可以将随机I/O变成顺序I/O
2、缺点
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存索引文件。
建立索引会占用磁盘空间的索引文件。一般情况这个问题不算严重,但如果你在一个大表上创建了多种组合索引,且伴随大量数据量插入,索引文件大小也会快速膨胀。
如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
对于非常小的表,大部分情况下简单的全表扫描更高效;
数据库存在的意义之一就是是解决数据存储和快速查找的。数据库的数据存在磁盘,磁盘的缺点就是相比内存访问速度慢,因此减少IO次数才是重中之重。
三、B+树的演变过程
二叉查找树 → 平衡二叉树 → B-Tree(B树、平衡多路查找树) → B+Tree(B+树)
1、二叉查找树
二叉树的性质
左子树的键值小于根的键值,右子树的键值大于根的键值。如下图所示就是一棵二叉查找树,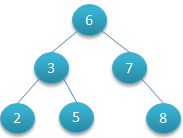
对该二叉树的节点进行查找发现深度为1的节点的查找次数为1,深度为2的查找次数为2,深度为n的节点的查找次数为n,因此其平均查找次数为 (1+2+2+3+3+3) / 6 = 2.3次
二叉查找树可以任意地构造,同样是2,3,5,6,7,8这六个数字,也可以按照下图的方式来构造: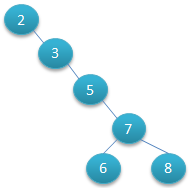
但是这棵二叉树的查询效率就低了。因此若想二叉树的查询效率尽可能高,应该尽量减少树高,降低IO次数,需要这棵二叉树是平衡的,从而引出新的定义——平衡二叉树。
2、平衡二叉树
平衡二叉树的性质
平衡二叉树(AVL树)是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树下面是平衡二叉树和非平衡二叉树的对比:
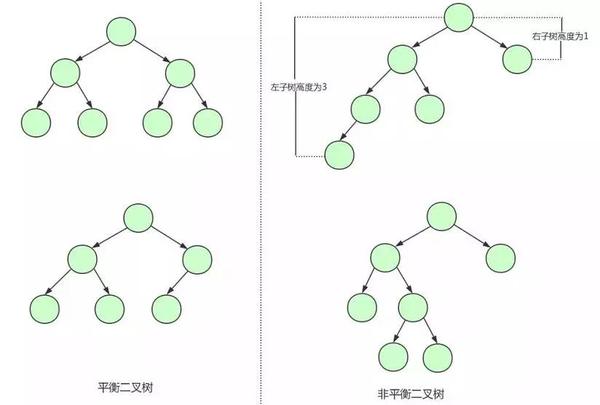
平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
更多相关知识点参考文章《平衡二叉树》
3、B-Tree(平衡多路查找树、B树)
B-Tree是为磁盘等外存储设备设计的一种平衡查找树。因此在讲B-Tree之前先了解下磁盘的相关知识。
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。
InnoDB存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为16KB,可通过参数innodb_page_size将页的大小设置为4K、8K、16K,在MySQL中可通过如下命令查看页的大小:
mysql> show variables like 'innodb_page_size';
而系统一个磁盘块的存储空间往往没有这么大,因此InnoDB每次申请磁盘空间时都会是若干地址连续磁盘块来达到页的大小16KB。InnoDB在把磁盘数据读入到磁盘时会以页为基本单位,在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘I/O次数,提高查询效率。
B-Tree结构的数据可以让系统高效的找到数据所在的磁盘块。为了描述B-Tree,首先定义一条记录为一个二元组[key, data] ,key为记录的键值,对应表中的主键值,data为一行记录中除主键外的数据。对于不同的记录,key值互不相同。
一棵m阶的B-Tree有如下特性:
- 每个节点最多有m个孩子。
- 除了根节点和叶子节点外,其它每个节点至少有Ceil(m/2)个孩子。
- 若根节点不是叶子节点,则至少有2个孩子
- 所有叶子节点都在同一层,且不包含其它关键字信息
- 每个非终端节点包含n个关键字信息(P0,P1,…Pn, k1,…kn)
- 关键字的个数n满足:ceil(m/2)-1 <= n <= m-1
- ki(i=1,…n)为关键字,且关键字升序排序。
- Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1)
B-Tree中的每个节点根据实际情况可以包含大量的关键字信息和分支,如下图所示为一个3阶的B-Tree: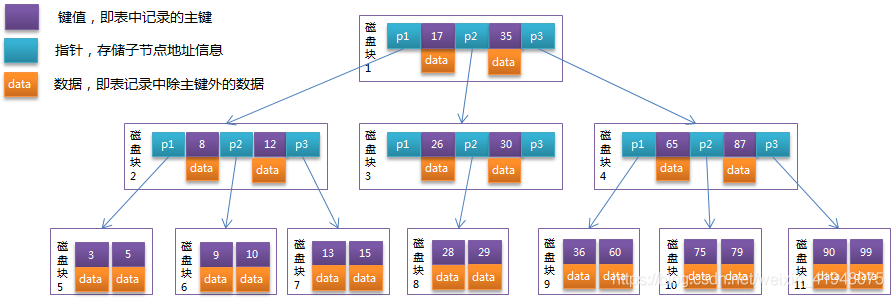
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
比较关键字29在区间(17,35),找到磁盘块1的指针P2。
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
比较关键字29在区间(26,30),找到磁盘块3的指针P2。
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。B-Tree相对于AVLTree缩减了节点个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
4、B+Tree
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
从上一节中的B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
B-Tree
- 每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null,叶子结点不包含任何关键字信息
B+Tree
- 所有的叶子结点中包含了全部关键字的信息,非叶子节点只存储键值信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接,所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B树的非终节点也包含需要查找的有效信息)
- 所有叶子节点之间都有一个链指针,意味着所有的值都是按顺序存储的,并且每一个叶子页到根的距离相同,很适合查找范围数据。说明支持范围查询和天然排序。
- 数据记录都存放在叶子节点中。
由于B+Tree的非叶子节点只存储键值信息,假设每个磁盘块能存储4个键值及指针信息,则变成B+Tree后其结构如下图所示: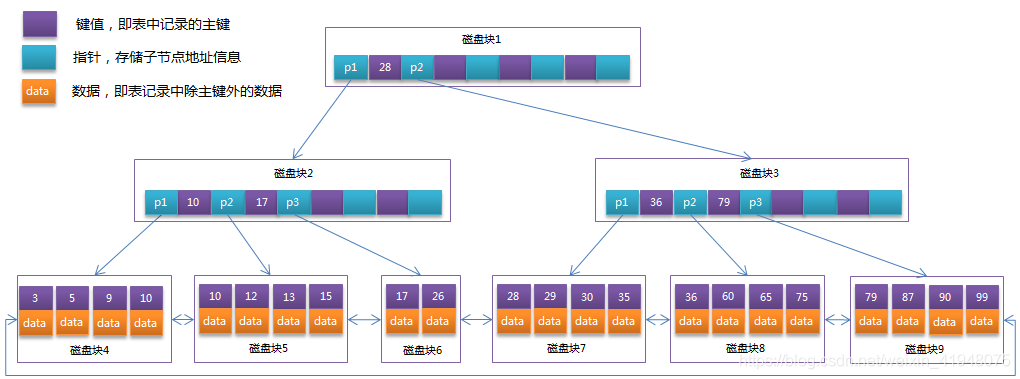
通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
可能上面例子中只有22条数据记录,看不出B+Tree的优点,下面做一个推算:
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为103。也就是说一个深度为3的B+Tree索引可以维护103 * 103 * 103 = 10亿条记录。
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2-4层。mysql的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作。
数据库中的B+Tree索引可以分为聚集索引(clustered index)和辅助索引(secondary index)。上面的B+Tree示例图在数据库中的实现即为聚集索引,聚集索引的B+Tree中的叶子节点存放的是整张表的行记录数据。辅助索引与聚集索引的区别在于辅助索引的叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键,即主键。当通过辅助索引来查询数据时,InnoDB存储引擎会遍历辅助索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据。
四、聚集索引和非聚集索引区别
聚集索引(clustered index):
聚集索引表记录的排列顺序和索引的排列顺序一致,所以查询效率快,只要找到第一个索引值记录,其余就连续性的记录在物理也一样连续存放。聚集索引对应的缺点就是修改慢,因为为了保证表中记录的物理和索引顺序一致,在记录插入的时候,会对数据页重新排序。
聚集索引类似于新华字典中用拼音去查找汉字,拼音检索表于书记顺序都是按照a~z排列的,就像相同的逻辑顺序于物理顺序一样,当你需要查找a,ai两个读音的字,或是想一次寻找多个傻(sha)的同音字时,也许向后翻几页,或紧接着下一行就得到结果了。
非聚合索引(nonclustered index):
非聚集索引指定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致,两种索引都采用B+树结构,非聚集索引的叶子层并不和实际数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针方式。非聚集索引层次多,不会造成数据重排。
非聚集索引类似在新华字典上通过偏旁部首来查询汉字,检索表也许是按照横、竖、撇来排列的,但是由于正文中是a~z的拼音顺序,所以就类似于逻辑地址于物理地址的不对应。同时适用的情况就在于分组,大数目的不同值,频繁更新的列中,这些情况即不适合聚集索引。
根本区别:
聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致。
五、B+比B树更适合实际应用中操作系统的文件索引和数据库索引
1.B+的磁盘读写代价更低
B+的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2.B+tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3.区间查找效率更高
mysql是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以B+树对索引列上的区间范围查询很友好。而B树每个节点的key和data在一起,无法进行区间查找。
六、索引相关知识点
1、回表查询
比如你创建了name, age索引 name_age_index,查询数据时使用了
select * from table where name ='森思底恩' and age = 12由于附加索引中只有name 和 age,因此命中索引后,数据库还必须回去聚集索引中查找其他数据,这就是回表,这也是你背的那条:少用select * 的原因。
2、索引覆盖
结合回表会更好理解,比如上述name_age_index索引,有查询
select name, age from table where name ='森思底恩' and age = 26此时select的字段name,age在索引name_age_index中都能获取到,所以不需要回表,满足索引覆盖,直接返回索引中的数据,效率高。是DBA同学优化时的首选优化方式。
3、最左前缀原则
顾名思义,就是最左优先,上例中我们创建了a_b_c多列索引,相当于创建了(a)单列索引,(a,b)组合索引以及(a,b,c)组合索引。
参考文章

