
- 1[AI Omost] 革命性AI图像合成技术,让你的创意几乎一触即发!_omost如何安装
- 2【语音识别】WeNet——CPU开源中文语音识别模型选择、部署、封装与流式实现_最好的开源的流式语音识别
- 3SSM框架中,后台向前端传送数据的方法_前端请求ssm后端怎样返回连接数据库的数据
- 4面试必问的41道 SpringBoot 面试题,不看亏大了!_springboot管理系统导师会问什么
- 5毕业设计-基于 MATLAB 的图像边缘检测算法的研究和实现_1、公式实现的原理 图像中某点处的梯度值,正比于与该点周围相临近的像素点之间的
- 6本地部署多租户容器平台KubeSphere并实现远程访问管理Kubernetes集群_kubesphere 域名访问
- 7hive参数大全_hive 指定worker.threads
- 8nlp语义理解的一点儿看法_nlp 语义理解差
- 9Flink 数据类型和序列化_flink 序列化
- 10大模型关键技术与应用_大模型的关键技术
昇思25天学习打卡营第11天 | Vision Transformer图像分类
赞
踩
以下为官方活动的学习笔记兼打卡记录,大部分内容来自活动资料,稍有删改,以我自己能看懂为准。
一、Vision Transformer(ViT)简介
近些年,随着基于自注意(Self-Attention)结构的模型的发展,特别是Transformer模型的提出,极大地促进了自然语言处理模型的发展。由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。
ViT则是自然语言处理和计算机视觉两个领域的融合结晶。在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。
1.1 模型结构
ViT模型的主体结构是基于Transformer模型的Encoder部分(部分结构顺序有调整,如:Normalization的位置与标准Transformer不同),其结构图[1]如下:
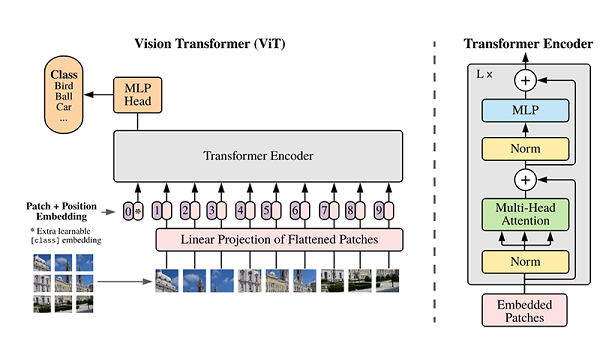
1.2 模型特点
ViT模型主要应用于图像分类领域。因此,其模型结构相较于传统的Transformer有以下几个特点:
- 数据集的原图像被划分为多个patch(图像块)后,将二维patch(不考虑channel)转换为一维向量,再加上类别向量与位置向量作为模型输入。
- 模型主体的Block结构是基于Transformer的Encoder结构,但是调整了Normalization的位置,其中,最主要的结构依然是Multi-head Attention结构。
- 模型在Blocks堆叠后接全连接层,接受类别向量的输出作为输入并用于分类。通常情况下,我们将最后的全连接层称为Head,Transformer Encoder部分为backbone。
二、数据集
本案例应用的数据集是从ImageNet中筛选出来的子集。经过数据增强处理,输出(224,224)的图像。
三、模型原理
3.1 Transformer原理
省略,以下是使用MindSpore构建的Multi-Head Attention模块。
from mindspore import nn, ops class Attention(nn.Cell): def __init__(self, dim: int, num_heads: int = 8, keep_prob: float = 1.0, attention_keep_prob: float = 1.0): super(Attention, self).__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = ms.Tensor(head_dim ** -0.5) self.qkv = nn.Dense(dim, dim * 3) self.attn_drop = nn.Dropout(p=1.0-attention_keep_prob) self.out = nn.Dense(dim, dim) self.out_drop = nn.Dropout(p=1.0-keep_prob) self.attn_matmul_v = ops.BatchMatMul() self.q_matmul_k = ops.BatchMatMul(transpose_b=True) self.softmax = nn.Softmax(axis=-1) def construct(self, x): """Attention construct.""" b, n, c = x.shape qkv = self.qkv(x) qkv = ops.reshape(qkv, (b, n, 3, self.num_heads, c // self.num_heads)) qkv = ops.transpose(qkv, (2, 0, 3, 1, 4)) q, k, v = ops.unstack(qkv, axis=0) attn = self.q_matmul_k(q, k) attn = ops.mul(attn, self.scale) attn = self.softmax(attn) attn = self.attn_drop(attn) out = self.attn_matmul_v(attn, v) out = ops.transpose(out, (0, 2, 1, 3)) out = ops.reshape(out, (b, n, c)) out = self.out(out) out = self.out_drop(out) return out

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
接下来就利用Self-Attention来构建ViT模型中的TransformerEncoder部分,类似于构建了一个Transformer的编码器部分,如下图所示:
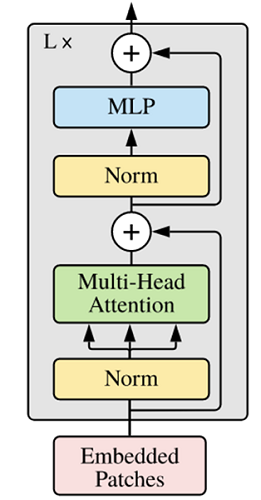
-
ViT模型中的基础结构与标准Transformer有所不同,主要在于Normalization的位置是放在Self-Attention和Feed Forward之前,其他结构如Residual Connection,Feed Forward,Normalization都如Transformer中所设计。
附:Transformer结构图
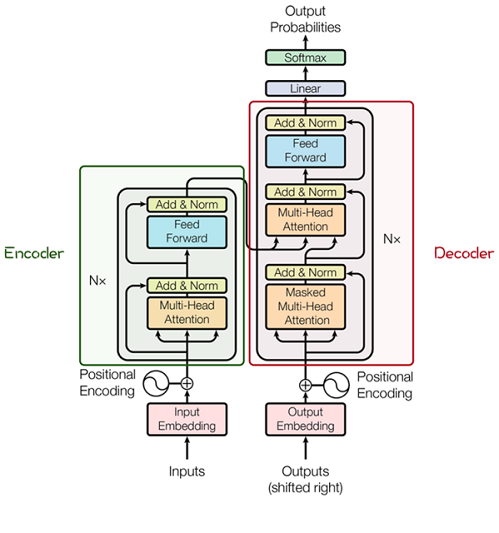
-
从Transformer结构的图片可以发现,多个子encoder的堆叠就完成了模型编码器的构建,在ViT模型中,依然沿用这个思路,通过配置超参数num_layers,就可以确定堆叠层数。
-
Residual Connection,Normalization的结构可以保证模型有很强的扩展性(保证信息经过深层处理不会出现退化的现象,这是Residual Connection的作用),Normalization和dropout的应用可以增强模型泛化能力。
从以下源码中就可以清晰看到Transformer的结构。将TransformerEncoder结构和一个多层感知器(MLP)结合,就构成了ViT模型的backbone部分。
from typing import Optional, Dict class FeedForward(nn.Cell): def __init__(self, in_features: int, hidden_features: Optional[int] = None, out_features: Optional[int] = None, activation: nn.Cell = nn.GELU, keep_prob: float = 1.0): super(FeedForward, self).__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.dense1 = nn.Dense(in_features, hidden_features) self.activation = activation() self.dense2 = nn.Dense(hidden_features, out_features) self.dropout = nn.Dropout(p=1.0-keep_prob) def construct(self, x): """Feed Forward construct.""" x = self.dense1(x) x = self.activation(x) x = self.dropout(x) x = self.dense2(x) x = self.dropout(x) return x class ResidualCell(nn.Cell): def __init__(self, cell): super(ResidualCell, self).__init__() self.cell = cell def construct(self, x): """ResidualCell construct.""" return self.cell(x) + x class TransformerEncoder(nn.Cell): def __init__(self, dim: int, num_layers: int, num_heads: int, mlp_dim: int, keep_prob: float = 1., attention_keep_prob: float = 1.0, drop_path_keep_prob: float = 1.0, activation: nn.Cell = nn.GELU, norm: nn.Cell = nn.LayerNorm): super(TransformerEncoder, self).__init__() layers = [] for _ in range(num_layers): normalization1 = norm((dim,)) normalization2 = norm((dim,)) attention = Attention(dim=dim, num_heads=num_heads, keep_prob=keep_prob, attention_keep_prob=attention_keep_prob) feedforward = FeedForward(in_features=dim, hidden_features=mlp_dim, activation=activation, keep_prob=keep_prob) layers.append( nn.SequentialCell([ ResidualCell(nn.SequentialCell([normalization1, attention])), ResidualCell(nn.SequentialCell([normalization2, feedforward])) ]) ) self.layers = nn.SequentialCell(layers) def construct(self, x): """Transformer construct.""" return self.layers(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
3.2 ViT模型的输入
传统的Transformer结构主要用于处理自然语言领域的词向量(Word Embedding or Word Vector),词向量与传统图像数据的主要区别在于,词向量通常是一维向量进行堆叠,而图片则是二维矩阵的堆叠,多头注意力机制在处理一维词向量的堆叠时会提取词向量之间的联系也就是上下文语义,这使得Transformer在自然语言处理领域非常好用,而二维图片矩阵如何与一维词向量进行转化就成为了Transformer进军图像处理领域的一个小门槛。
在ViT模型中:
-
通过将输入图像在每个channel上划分为16*16个patch,这一步是通过卷积操作来完成的,当然也可以人工进行划分,但卷积操作也可以达到目的同时还可以进行一次而外的数据处理;例如一幅输入224 x 224的图像,首先经过卷积处理得到16 x 16个patch,那么每一个patch的大小就是14 x 14。
-
再将每一个patch的矩阵拉伸成为一个一维向量,从而获得了近似词向量堆叠的效果。上一步得到的14 x 14的patch就转换为长度为196的向量。
这是图像输入网络经过的第一步处理。具体Patch Embedding的代码如下所示:
class PatchEmbedding(nn.Cell): MIN_NUM_PATCHES = 4 def __init__(self, image_size: int = 224, patch_size: int = 16, embed_dim: int = 768, input_channels: int = 3): super(PatchEmbedding, self).__init__() self.image_size = image_size self.patch_size = patch_size self.num_patches = (image_size // patch_size) ** 2 self.conv = nn.Conv2d(input_channels, embed_dim, kernel_size=patch_size, stride=patch_size, has_bias=True) def construct(self, x): """Path Embedding construct.""" x = self.conv(x) b, c, h, w = x.shape x = ops.reshape(x, (b, c, h * w)) x = ops.transpose(x, (0, 2, 1)) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
输入图像在划分为patch之后,会经过pos_embedding 和 class_embedding两个过程。
-
class_embedding主要借鉴了BERT模型的用于文本分类时的思想,在每一个word vector之前增加一个类别值,通常是加在向量的第一位,上一步得到的196维的向量加上class_embedding后变为197维。
-
增加的class_embedding是一个可以学习的参数,经过网络的不断训练,最终以输出向量的第一个维度的输出来决定最后的输出类别;由于输入是16 x 16个patch,所以输出进行分类时是取 16 x 16个class_embedding进行分类。
-
pos_embedding也是一组可以学习的参数,会被加入到经过处理的patch矩阵中。
-
由于pos_embedding也是可以学习的参数,所以它的加入类似于全链接网络和卷积的bias。这一步就是创造一个长度维197的可训练向量加入到经过class_embedding的向量中。
实际上,pos_embedding总共有4种方案。但是经过作者的论证,只有加上pos_embedding和不加pos_embedding有明显影响,至于pos_embedding是一维还是二维对分类结果影响不大,所以,在我们的代码中,也是采用了一维的pos_embedding,由于class_embedding是加在pos_embedding之前,所以pos_embedding的维度会比patch拉伸后的维度加1。
总的而言,ViT模型还是利用了Transformer模型在处理上下文语义时的优势,将图像转换为一种“变种词向量”然后进行处理,而这样转换的意义在于,多个patch之间本身具有空间联系,这类似于一种“空间语义”,从而获得了比较好的处理效果。
3.3 整体构建ViT
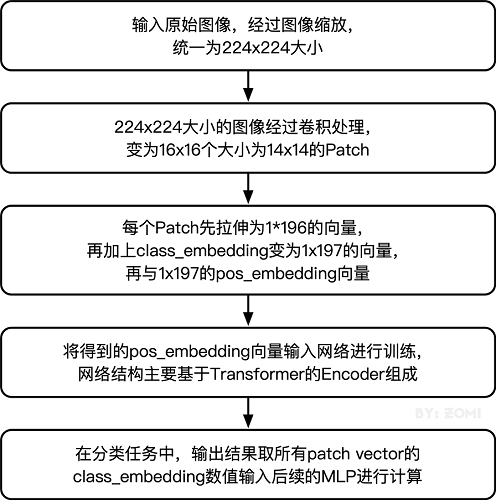
以下代码构建了一个完整的ViT模型。
from mindspore.common.initializer import Normal from mindspore.common.initializer import initializer from mindspore import Parameter def init(init_type, shape, dtype, name, requires_grad): """Init.""" initial = initializer(init_type, shape, dtype).init_data() return Parameter(initial, name=name, requires_grad=requires_grad) class ViT(nn.Cell): def __init__(self, image_size: int = 224, input_channels: int = 3, patch_size: int = 16, embed_dim: int = 768, num_layers: int = 12, num_heads: int = 12, mlp_dim: int = 3072, keep_prob: float = 1.0, attention_keep_prob: float = 1.0, drop_path_keep_prob: float = 1.0, activation: nn.Cell = nn.GELU, norm: Optional[nn.Cell] = nn.LayerNorm, pool: str = 'cls') -> None: super(ViT, self).__init__() self.patch_embedding = PatchEmbedding(image_size=image_size, patch_size=patch_size, embed_dim=embed_dim, input_channels=input_channels) num_patches = self.patch_embedding.num_patches self.cls_token = init(init_type=Normal(sigma=1.0), shape=(1, 1, embed_dim), dtype=ms.float32, name='cls', requires_grad=True) self.pos_embedding = init(init_type=Normal(sigma=1.0), shape=(1, num_patches + 1, embed_dim), dtype=ms.float32, name='pos_embedding', requires_grad=True) self.pool = pool self.pos_dropout = nn.Dropout(p=1.0-keep_prob) self.norm = norm((embed_dim,)) self.transformer = TransformerEncoder(dim=embed_dim, num_layers=num_layers, num_heads=num_heads, mlp_dim=mlp_dim, keep_prob=keep_prob, attention_keep_prob=attention_keep_prob, drop_path_keep_prob=drop_path_keep_prob, activation=activation, norm=norm) self.dropout = nn.Dropout(p=1.0-keep_prob) self.dense = nn.Dense(embed_dim, num_classes) def construct(self, x): """ViT construct.""" x = self.patch_embedding(x) cls_tokens = ops.tile(self.cls_token.astype(x.dtype), (x.shape[0], 1, 1)) x = ops.concat((cls_tokens, x), axis=1) x += self.pos_embedding x = self.pos_dropout(x) x = self.transformer(x) x = self.norm(x) x = x[:, 0] if self.training: x = self.dropout(x) x = self.dense(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
四、模型训练与评估
4.1 模型训练
from mindspore.nn import LossBase from mindspore.train import LossMonitor, TimeMonitor, CheckpointConfig, ModelCheckpoint from mindspore import train # define super parameter epoch_size = 10 momentum = 0.9 num_classes = 1000 resize = 224 step_size = dataset_train.get_dataset_size() # construct model network = ViT() # load ckpt vit_url = "https://download.mindspore.cn/vision/classification/vit_b_16_224.ckpt" path = "./ckpt/vit_b_16_224.ckpt" vit_path = download(vit_url, path, replace=True) param_dict = ms.load_checkpoint(vit_path) ms.load_param_into_net(network, param_dict) # define learning rate lr = nn.cosine_decay_lr(min_lr=float(0), max_lr=0.00005, total_step=epoch_size * step_size, step_per_epoch=step_size, decay_epoch=10) # define optimizer network_opt = nn.Adam(network.trainable_params(), lr, momentum) # define loss function class CrossEntropySmooth(LossBase): """CrossEntropy.""" def __init__(self, sparse=True, reduction='mean', smooth_factor=0., num_classes=1000): super(CrossEntropySmooth, self).__init__() self.onehot = ops.OneHot() self.sparse = sparse self.on_value = ms.Tensor(1.0 - smooth_factor, ms.float32) self.off_value = ms.Tensor(1.0 * smooth_factor / (num_classes - 1), ms.float32) self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction) def construct(self, logit, label): if self.sparse: label = self.onehot(label, ops.shape(logit)[1], self.on_value, self.off_value) loss = self.ce(logit, label) return loss network_loss = CrossEntropySmooth(sparse=True, reduction="mean", smooth_factor=0.1, num_classes=num_classes) # set checkpoint ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size, keep_checkpoint_max=100) ckpt_callback = ModelCheckpoint(prefix='vit_b_16', directory='./ViT', config=ckpt_config) # initialize model # "Ascend + mixed precision" can improve performance ascend_target = (ms.get_context("device_target") == "Ascend") if ascend_target: model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O2") else: model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O0") # train model model.train(epoch_size, dataset_train, callbacks=[ckpt_callback, LossMonitor(125), TimeMonitor(125)], dataset_sink_mode=False,)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74

4.2 模型评估
模型验证过程主要应用了ImageFolderDataset,CrossEntropySmooth和Model等接口。
ImageFolderDataset主要用于读取数据集。
CrossEntropySmooth是损失函数实例化接口。
Model主要用于编译模型。
与训练过程相似,首先进行数据增强,然后定义ViT网络结构,加载预训练模型参数。随后设置损失函数,评价指标等,编译模型后进行验证。本案例采用了业界通用的评价标准Top_1_Accuracy和Top_5_Accuracy评价指标来评价模型表现。
在本案例中,这两个指标代表了在输出的1000维向量中,以最大值或前5的输出值所代表的类别为预测结果时,模型预测的准确率。这两个指标的值越大,代表模型准确率越高。
dataset_val = ImageFolderDataset(os.path.join(data_path, "val"), shuffle=True) trans_val = [ transforms.Decode(), transforms.Resize(224 + 32), transforms.CenterCrop(224), transforms.Normalize(mean=mean, std=std), transforms.HWC2CHW() ] dataset_val = dataset_val.map(operations=trans_val, input_columns=["image"]) dataset_val = dataset_val.batch(batch_size=16, drop_remainder=True) # construct model network = ViT() # load ckpt param_dict = ms.load_checkpoint(vit_path) ms.load_param_into_net(network, param_dict) network_loss = CrossEntropySmooth(sparse=True, reduction="mean", smooth_factor=0.1, num_classes=num_classes) # define metric eval_metrics = {'Top_1_Accuracy': train.Top1CategoricalAccuracy(), 'Top_5_Accuracy': train.Top5CategoricalAccuracy()} if ascend_target: model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics=eval_metrics, amp_level="O2") else: model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics=eval_metrics, amp_level="O0") # evaluate model result = model.eval(dataset_val) print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
> {‘Top_1_Accuracy’: 0.7495, ‘Top_5_Accuracy’: 0.928}
4.3 模型推理
调用模型的predict方法进行模型推理。
在推理过程中,通过index2label就可以获取对应标签,再通过自定义的show_result接口将结果写在对应图片上。

学习打卡记录


