
- 1fastjson自定义序列化_fastjson序列化方法实现自定义key&value
- 2《手把手带你开始计算机视觉项目实战》专栏概述 | 实战教程,开放源码
- 3huggingface镜像站_huggingface镜像网站
- 4mysql 查看主从延迟_MySQL|主从延迟问题排查(一)
- 52024年Python最新【图像分类】实战——使用VGG16实现对植物幼苗的分类(pytroch,字节跳动面试怎么写代码_vgg图像分类代码
- 6深入理解Linux内核-进程-信号_不同类型的信号会挂起吗
- 7基于FPGA的CAN总线控制器的设计(上)_基于fpga通过can接口远程在线升级c程序
- 8yum安装指定版本docker服务
- 9艺术与科技的融合:探索AI绘画工具的领军者
- 10线上问题执行.sh文件,权限不足_解释器错误权限不足
阿里巴巴打破视频生成技术壁垒,EasyAnimate实现高质量长视频生成_easyanimate网站试用
赞
踩

引言:视频生成技术的演进与挑战
视频生成技术在过去几年中取得了显著的进展,特别是在人工智能和深度学习的推动下。从最初的简单动画到现在可以生成高质量、长时间的视频内容,这一领域已经经历了巨大的变革。然而,尽管取得了这些成就,视频生成技术仍面临许多挑战,包括视频质量、视频长度限制以及运动的自然性等问题。
近年来,随着稳定扩散模型(Stable Diffusion)和变分自编码器(VAE)的发展,视频生成技术开始向更高的质量和更复杂的动态场景发展。例如,OpenAI的Sora项目在2024年实现了高保真度的一分钟视频生成,显著提高了视频的真实感。此外,Transformer架构在视频生成中的应用也开始受到重视,它通过在视频帧之间建立更复杂的关联,有助于生成更流畅和连贯的视频内容。
尽管如此,当前的视频生成模型在处理长时间视频时仍然存在挑战,如内存限制、编解码效率等问题。因此,研究者们持续探索更高效的编码机制和架构改进,以期解决这些问题,并推动视频生成技术向更高的水平发展。
论文标题、机构、论文链接和项目地址
论文标题: EasyAnimate: A High-Performance Long Video Generation Method based on Transformer Architecture
机构: Platform of AI (PAI), Alibaba Group
论文链接: https://arxiv.org/pdf/2405.18991.pdf
项目地址: https://github.com/aigc-apps/EasyAnimate
EasyAnimate框架介绍
EasyAnimate是一个先进的视频生成方法,它利用变压器架构的强大功能来实现高性能的输出。该框架扩展了最初为2D图像合成设计的DiT框架,以适应3D视频生成的复杂性,通过整合一个运动模块块来捕捉时间动态,从而确保生成一致的帧和无缝的运动过渡。此外,EasyAnimate引入了切片VAE,这是一种新颖的方法,用于压缩时间轴,有助于生成长时间视频。目前,EasyAnimate能够生成高达144帧的视频。
EasyAnimate提供了一个全面的视频生产生态系统,基于DiT,涵盖数据预处理、VAE训练、DiT模型训练(基线模型和LoRA模型)以及端到端视频推理等方面。代码可在GitHub上获取:https://github.com/aigc-apps/EasyAnimate。
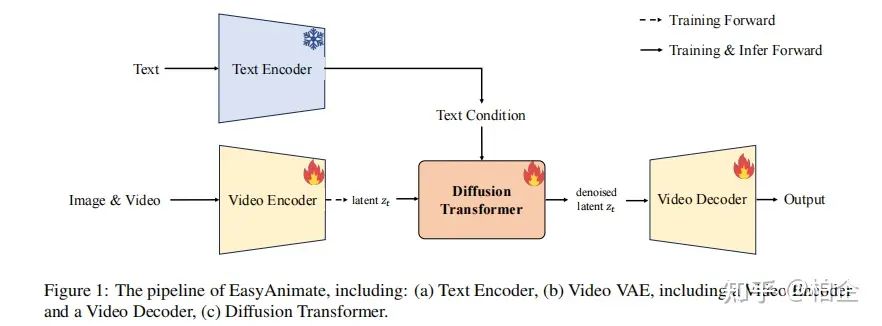
视频生成的关键技术
1. 切片VAE技术
在传统的基于图像的VAE中,每个视频帧被编码为一个单独的潜在特征,这大大减小了帧的空间尺寸。然而,这种编码技术忽略了时间动态,将视频降级为静态图像表示。为了有效压缩视频编码器和解码器中的时间维度,我们引入了切片机制到MagViT中,并提出了切片VAE。通过这种方法,一组视频帧被分成几个部分,每个部分分别进行编码和解码。
2. 视频扩散变压器
视频扩散变压器的架构增加了一个运动模块,使其从2D图像合成扩展到3D视频生成。此外,我们还整合了UViT的连接,以增强训练过程的稳定性。运动模块专门设计用来利用帧长度内嵌的时间信息。通过在时间维度上整合注意力机制,模型获得了吸收此类时间数据的能力,这对于生成视频运动至关重要。同时,我们采用网格重塑操作来增加输入令牌的池,从而提高图像中存在的空间细节的利用率,最终实现更优越的生成性能。
这些关键技术的应用使EasyAnimate成为未来视频合成研究的一个强大且高效的基线,推动创新、进步和探索。
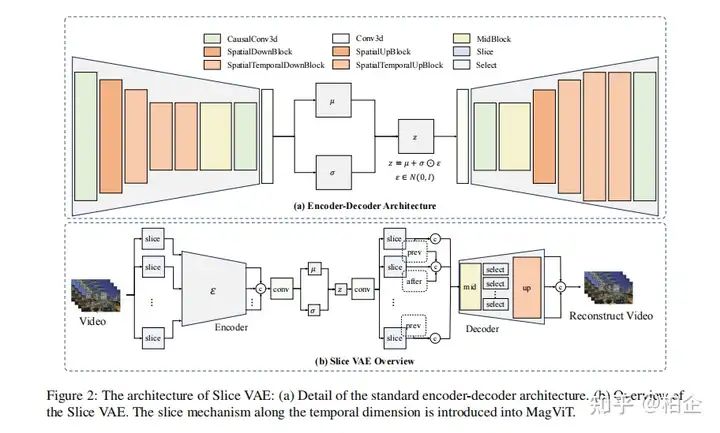
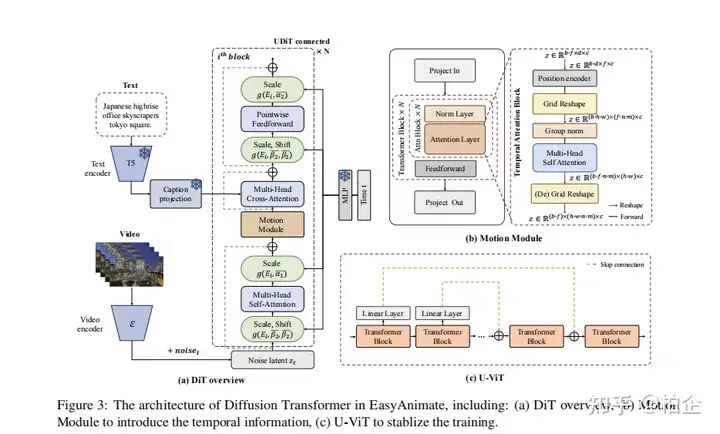
训练过程与策略
1. 训练策略概述
EasyAnimate采用了三阶段的训练策略,以逐步提升视频生成的质量和效率。首先,通过对图像数据的训练,使DiT模型适应新的视频VAE。接着,利用大规模的视频数据集和图像数据预训练运动模块,引入视频生成能力。最后,使用高质量的视频数据对整个DiT模型进行精细调整,以优化生成性能。
2. 运动模块的训练
运动模块的训练是在大规模数据集上进行的,这一步骤至关重要,因为它帮助模型捕捉视频中的时间动态信息,从而生成连贯的帧和平滑的运动过渡。此模块通过在时间维度上集成注意力机制,使模型能够整合这些时间数据,这对于视频动作的生成至关重要。
3. 分辨率的逐步扩展
在训练的最后阶段,DiT模型通过从较低分辨率到较高分辨率的逐步扩展来训练,这种方法有效地提高了模型处理高分辨率视频的能力,同时保持了生成质量。
数据预处理与视频质量控制
1. 视频分割
为了保证视频内容的主题一致性,使用PySceneDetect工具识别视频中的场景变化,并根据这些过渡进行场景切割。只保留时长在3到10秒之间的视频段用于模型训练,这有助于模型更好地学习和生成短视频。
2. 视频过滤
视频数据通过三个方面进行过滤:运动评分、文本区域评分和美学评分。运动过滤确保视频显示出运动感,同时保持运动的一致性;文本过滤通过OCR技术检测视频帧中的文本区域,过滤掉文本区域超过1%的视频段;美学过滤则计算视频的美学评分,只保留高分的视频用于训练。
3. 视频字幕处理
视频字幕的质量直接影响视频生成的结果。通过比较多个大型多模态模型的性能和操作效率,选择了性能优异的VideoChat2和VILA进行视频数据的字幕处理,这些模型在视频字幕的详细性和时间信息方面表现出色,有助于提高生成视频的质量。
实验结果与分析
1. 视频生成性能
EasyAnimate在视频生成方面表现出色,能够生成高达144帧的视频。通过使用创新的Slice VAE和动态模块,EasyAnimate不仅提高了视频的时间压缩效率,还保持了视频帧之间的连贯性和流畅的动态过渡。实验结果显示,通过在时间维度上进行切片处理,能够有效地管理视频帧的编码和解码,解决了传统VAE在处理长视频时遇到的内存限制问题。
2. 模型训练与优化
在模型训练方面,EasyAnimate采用了三阶段训练策略,首先是图像数据的训练,然后是动态模块的大规模数据集训练,最后是高分辨率视频和图像的整体网络训练。这种分阶段的训练方法有效地提升了模型的稳定性和生成质量。特别是引入UViT的长跳跃连接,有助于在反向传播过程中防止梯度消失,从而保证了训练的稳定性。
3. 视频质量与创新性
通过对比其他视频生成模型,EasyAnimate在视频质量和创新性方面均表现优异。它不仅能够处理不同帧率和分辨率的视频生成,还能够适应不同的DiT基线模型,生成多样化的视频风格。此外,其视频VAE的切片机制创新地解决了视频长时间维度的压缩问题,显著提升了生成视频的长度和质量。
结论与未来展望
EasyAnimate作为一个基于变换器架构的高性能视频生成方法,成功地扩展了DiT框架,将其从2D图像合成拓展到3D视频生成。通过引入动态模块和Slice VAE,EasyAnimate不仅优化了视频帧的一致性和动态过渡,还提高了模型的训练效率和视频的生成质量。
未来展望
- 模型优化:未来的研究可以进一步探索如何优化Slice VAE的架构,以更高效地处理更长时间的视频,同时减少信息损失。
- 应用拓展:EasyAnimate的应用可以扩展到更多领域,如虚拟现实、游戏开发和电影制作,其中对高质量和长时视频的需求日益增长。
- 技术迭代:随着人工智能技术的不断进步,未来可以探索将更多先进的AI技术,如深度学习和神经网络,整合到EasyAnimate中,以进一步提升视频生成的自然性和真实感。

