
- 1SpringBoot整合Spring Security【超详细教程】_spring boot security 教程
- 2Git多人协作开发_git协同问题
- 3机械学习—零基础学习日志(高数14——函数极限概念)
- 4图解自注意力机制(Self-Attention)_注意力机制结构图
- 5STM32FFT_stm32 fft程序
- 6霍格沃兹遗产Hogwarts Legacy Mac高清壁纸_霍格沃茨之遗壁纸
- 7【新手入门】NLP机器翻译(3)——基于Transformer的翻译模型_基于transformer的机器翻译模型
- 8秋元康系偶像·NHK紅白歌合戦(AKB48、SKE48、NMB48、HKT48、NGT48、STU48、乃木坂46、櫸坂46、日向坂46、櫻坂46、宫脇咲良、LE SSERAFIM、生田絵梨花)
- 9如何编写软件测试简历?_软件测试可以写进简历的电商项目
- 102024年最全[ 环境搭建篇 ] 安装python环境并配置环境变量(附python3,头条社招面试流程_python安装环境变量设置
基于 FPGA 的 YOLOv5s 网络高效卷积加速器设计【上】_卷积网络fpga
赞
踩
摘 要:为提升在资源受限情况下的嵌入式平台上卷积神经网络( Convolutional Neural Network, CNN)目标识别的资源利用率和能效,提出了一种适用于 YOLOv5s 目标识别网络的现场可编程门阵 列(Field Programmable Gate Array,FPGA)共享计算单元的并行卷积加速结构,该结构通过共享 3×3 卷积和 1× 1 卷积的计算单元提高了加速器硬件资源利用率。 此外,还利用卷积层 BN( Batch Normalization)层融合、模型量化、循环分块以及双缓冲等策略,提高系统计算效率并减少硬件资源开 销。 实验结果表明,加速器在 200 MHz 的工作频率下,实现的卷积计算峰值性能可达 97. 7 GOPS (Giga Operations per Second),其 YOLOv5s 网络的平均计算性可达 78. 34 GOPS,与其他 FPGA 加速 器方案相比在 DSP 效率、能耗比以及整体性能等方面具有一定的提升。
关键词:卷积神经网络(CNN);目标识别;YOLOv5s;并行卷积加速结构
0 引 言
近年来,卷积神经网络目标识别算法在人脸识 别、自动驾驶以及物体识别等民用领域获得了巨大的 成功。 目前国内航天技术也逐渐向智能化转变,在航 天设备上应用智能化的目标检测系统受到越来越多 的关注。 然而星载硬件计算资源十分匮乏,如何将基 于卷积神经网络的目标检测算法部署到资源有限的 宇航级芯片上是亟需解决的一项技术难题[1] 。 现场可编程门阵列 ( Field Programmable Gate Array,FPGA)作为航天常用主控器件,具有功耗低、 可重构以及并行计算能力强等优点,利用其高度的 并行计算能力能够以较低的功耗实现高效的卷积计 算,在卷积加速方面能够表现出独特的优势[2] 。 因 此,本文提出采用 FPGA 作为硬件加速单元实现基 于卷积神经网络的目标检测加速系统。 目前基于 FPGA 的卷积加速器研究主要集中在 3×3 标准卷积加速的优化上,对于目标检测常用的 YOLO 网络的网络加速优化研究还较少。 由于目标 检测网络较卷积计算有着更加复杂的结构,因此研 究如何实现高效的网络加速更具有意义。 在 YOLO 目标检测网络中卷积一般为两种,分别是 1×1 卷积 和 3×3 卷积。 对于 YOLO 目标检测网络的加速,文 献[3-4]中提出的加速结构分别对 1×1 卷积和 3×3 卷积进行了硬件设计,两种卷积计算单元相互独立, 计算资源互不共享。 由于卷积神经网络目标检测算 法每次只对一种卷积进行计算,因此此类结构中总 有一部分计算单元会空闲,从而使硬件利用率较低。 而文献[5]中提出卷积复用的方法,将 1×1 卷积权 重放置在 3×3 卷积核权重第 5 位,剩余 8 位权重置 零。 该方法用 3×3 卷积直接代替 1×1 卷积,虽然大 幅提高了硬件利用率,但是 1×1 卷积计算时每计算 1 次会产生 8 次无效计算和无效数据传输,因此造 成了 1×1 卷积计算效率低下。 文献[6]中提出了一 种策略,将 3×3 卷积转换成 1×1 卷积进行计算,并 对 YOLOv5s 网络实现了加速计算,但是该方法却牺 牲了部分并行性,计算性能较差。 文献[7] 采用了 基于 Winograd 算法的硬件加速结构完成了对 3×3、 5×5 以及 11×11 尺寸的卷积加速,并取得了较好的 加速效果,但该方法并不支持 1×1 卷积的计算。 由 于 YOLOv5 目标检测网络中具有大量的 1×1 卷积计 算,因此该方法并不适合用于加速 YOLOv5 目标检测网络。 为解决以上文献中所提结构的缺点,本文提出 了一种将 1×1 卷积和 3×3 卷积计算单元复用共享 的结构。 在大幅提高硬件利用率的同时,既可以计 算 1×1 卷积也可以计算 3×3 卷积,同时 1×1 卷积计 算时也不会产生无效计算和无效数据传输,解决了 文献[3-7]中加速器结构硬件利用率低、计算效率 低以及不支持 1×1 卷积计算等问题。 此外,该硬件 加速器还利用了层融合、多维度并行卷积加速、模型 量化降低资源消耗等方法以较低的 FPGA 资源消耗 获得了较高的计算能力,实现了卷积神经网络目标 检测的高效计算。 最后本文以通用目标检测算法 YOLOv5s 算法为基础,并以天体表面陨石坑的识别 为主,验证了所提出的加速器结构的有效性。
1 YOLOv5s 目标检测算法
YOLOv5 目标检测算法由 Ultralytics LLC 公司 于 2020 年 5 月提出,是目前优秀的目标检测算法之 一。 通过 YOLOv5 算法能够实现多目标高精度的目 标检测,可以解决传统目标检测算法要求检测背景 简单以及需要被检测目标特征明显类型单一等问 题。 YOLOv5 目标检测网络结构共有 5 个主流版 本,分别是 YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l 和 YOLOv5x。 本文综 合 速 度、 精 度 等 方 面 的 因 素 采 用 了 YOLOv5s,并对 YOLOv5s 算法结构进行了微调: 一是将原算法模型的激活层由 SiLU 替换为 Leaky ReLU。 由于 SiLU 激活函数中包括指数、乘 法、除法和加法计算, 其计算复杂度高, 而 Leaky ReLU 激活函数中仅包含一个乘法计算计算复杂度 低,因此采用 Leaky ReLU 激活函数能够在一定程度 上降低计算量。 二是保留了 YOLOv5s-5. 0 中的 FOCUS 结构和 YOLOv5s-6. 0 中的 SPPF 结构,SPPF 结构中只采用 了一种尺寸 5×5 的 Maxpool,相较于 SPP 结构中 3 种不同尺寸(5×5、9×9、13×13)的 Maxpool 在 FPGA 上仅需要设计一种尺寸 Maxpool,能够简化 FPGA 对 Maxpool 的设计。 以上算法修改均能够有效减少 FPGA 资源使 用,且对算法本身影响不大。 调整后的 YOLOv5s 网 络结构如图 1 所示。
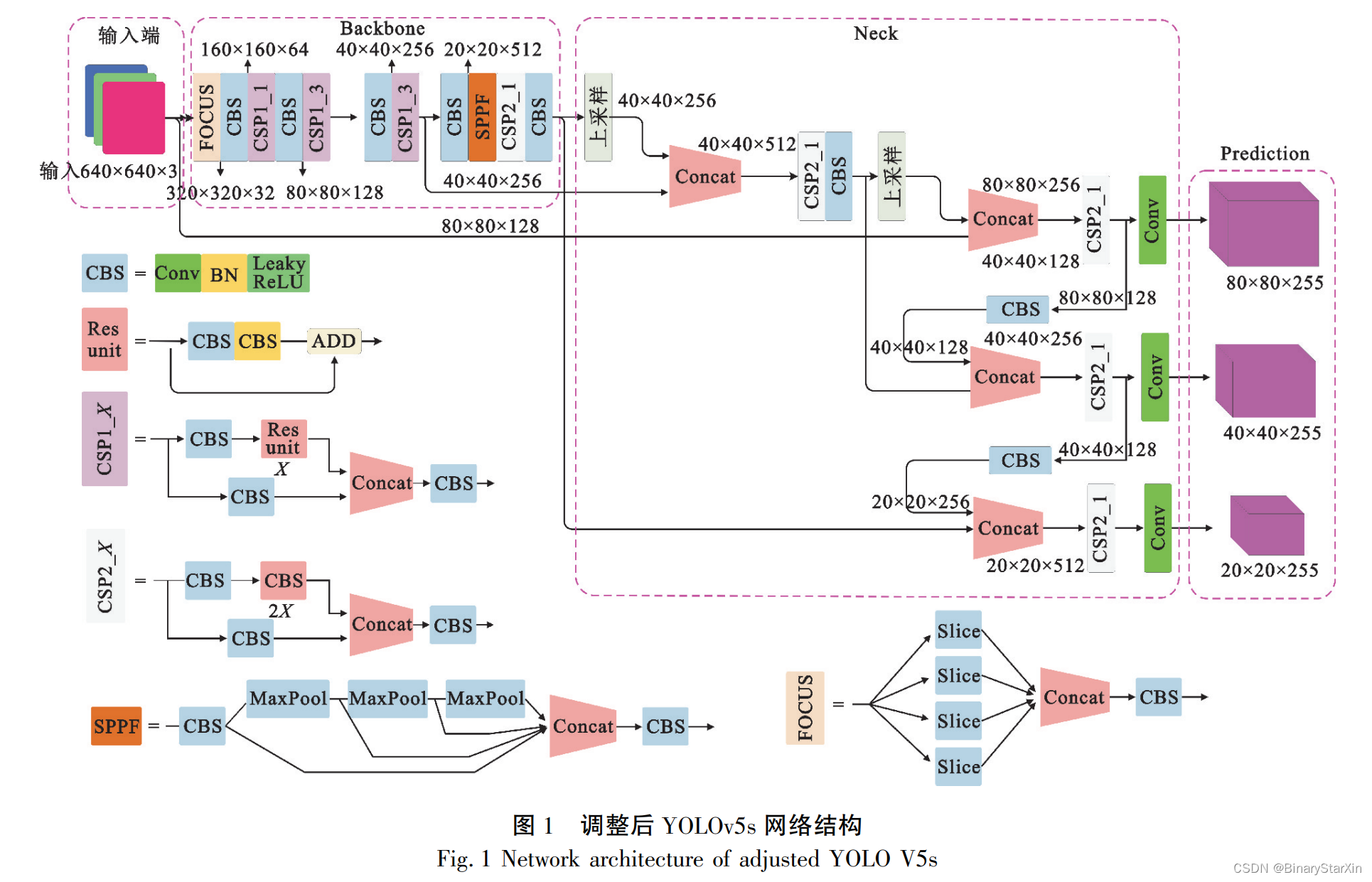
2 网络模型层融合与量化
2. 1 网络模型层融合
YOLOv5s 算法中 CBS 计算过程包括卷积、BN (Batch Normalization)和 Leaky ReLU 三部分。 在模 型训练过程中 BN 层能够解决梯度消失和梯度爆炸 的问题,并可以加快网络的收敛提高训练效率,同时 也可以提高网络稳定性。 而在前向推理过程中 BN 层却降低了模型的性能,所以在推理过程中可以通 过层融合的方式将 BN 层融合到卷积层中,从而达 到降低计算量、提高模型性能的效果[8] 。 卷积层 BN 层融合过程如下: 在 BN 层中 μ 表示输入的均值如式(1)所示,式 中 x 表示输入特征图中的元素,m 表示输入特征图 中元素的个数。 δ 2 为输入的方差,如式(2)所示。
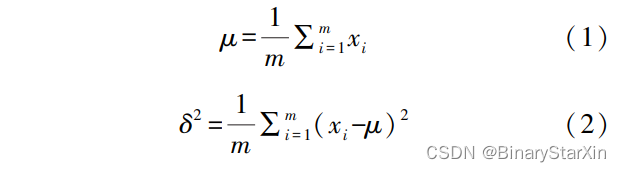
BN 计算公式如式(3) 所示,式中 γ 为尺度因 子,β 为偏移因子。 尺度因子优化了特征数据分布 的宽窄,偏移因子则优化了数据的偏移量,在模型训练过程中这两个参数自动学习,训练结束后数值固 定。 ε 为一个大于 0 且极小的数值,用于防止方差 δ 2 为 0 的异常情况出现。 式(4)为卷积计算公式, 其中 W 表示卷积核,X 表示输入特征图,B 表示偏 置,Y 表示输出特征图。 将式(4)代入到 BN 计算中 得到卷积和 BN 计算的总公式(5),式中 Y′表示卷积 和 BN 计算后的输出特征图。
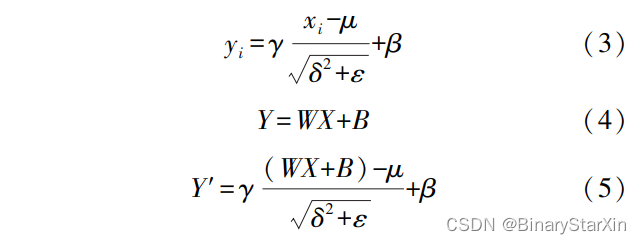
将式(5)展开可得出新的卷积核 W′如式(6)所 示,新的偏置 B′如式(7)所示。

层融合的方法通过提前计算获得新的卷积核 W′和偏置 B′,从而将 BN 层融合到卷积层中,有效降 低了模型推理阶段 FPGA 上的计算量,减少 FPGA片上 DSP48E、LUT 等资源的消耗。 同时由于计算 步骤减少,所以也能够在一定程度上减小推理延时, 提高系统整体性能。
2. 2 网络模型量化
在深度学习领域量化是一种常用的能够有效降 低存储空间和计算成本的方法[9] ,可以有效压缩模 型大小。 在 FPGA 上采用量化方法用低位宽的定点 乘法器、加法器代替高位宽的浮点乘法器、加法器可 以大幅降低 FPGA 逻辑资源的使用,提高资源紧缺 情况下 FPGA 上的计算能力。 本文对模型进行了量 化,将 32 位单精度浮点转换为 16 位定点数, 在 FPGA 中设计 16 位定点乘法器、加法器来完成卷积 层的计算。
3 FPGA 硬件加速器设计
3. 1 加速器体系架构
根据图 1 中 YOLOv5s 网络结构框图可以看出 其内部由基础模块构成,包括卷积 Conv 模块、ADD模 块、 Maxpool 模 块、 Silce 模 块、 上 采 样 模 块 和 Concat 模块。 其中卷积分为两类,分别为 1×1 卷积 和 3×3 标准卷积,在 YOLOv5s 算法中一共了包含 43 层 1 × 1 卷积和 19 层 3 × 3 标准卷积,该部分是 YOLOv5s 算法中计算最复杂的部分,需要在 FPGA 设计并行计算单元以达到计算加速效果。 本文对 YOLOv5s 算法中计算量较大的模块在 FPGA 上进行 了硬件加速设计,包括 Conv1× 1 卷积、Conv3 × 3 卷 积、ADD、Maxpool 和上采样模块。
加速器整体架构如图 2 所示,该架构中包括 CPU 和 FPGA 两个部分。 其中 CPU 部分为双核 ARM Cortex-A9 MPCore,该部分外挂 DDR3 内存,用 于缓存特征图和权重数据以及运算过程中产生的中 间数据,外挂 NAND FLASH 用于存储输入的图像文 件和权重文件以及存储计算后的输出文件。 UART 接口用于监控加速器各个阶段的计算耗时,输出所 识别到的陨石坑在图像中的坐标信息。 CPU 部分 主要进行图像和权重等文件的读取、将图像和权重 文件转存到 DDR3、配置 FPGA 端加速器以及处理 YOLOv5s 中简单的计算如 Silce 和 Concat。

FPGA 端设计有主计算单元和辅计算单元两个 部分。 其中主计算单元包括 3×3 卷积缓存模块、1× 1 卷积缓存模块、通用并行计算模块和 ADD 计算模 块。 在主计算单元中由于涉及的数据量较大且数据 传输延时较长,所以在主计算单元中采用双缓存乒 乓机制用于掩盖数据传输所消耗的时间。 辅计算单 元包括 Maxpool 计算模块和上采样计算模块。
CPU 和 FPGA 之 间 通 过 AXI ( Advanced eXtensible Interface) 总 线 交 互 数 据, 采 用 了 1 个 AXI-GP 接口和 4 个 AXI-HP 接口。 其中 AXI-GP 接 口用于 FPGA 和 CPU 之间的控制信号传输,实现加 速器的偏移地址配置以及其他参数配置。 而 AXI-HP 接口负责计算过程中 DDR3 内存与 FPGA 的高 速数据交换,AXI-HP 接口和 DDR 之间具有专有控制器可以直接实现 FPGA 与内存的高速数据交换, 由于不需要经过 CPU 从而大大提高了数据传输效 率,适合大数据吞吐量的应用场景。
3. 2 存储设计
3. 2. 1 循环分块策略
由于 FPGA 的片上存储 BRAM(Block Random Access Memory)资源十分有限,而卷积计算过程中 的权重、偏置以及特征图会占用大量的存储资源,所 以无法直接将整个特征图存储到 FPGA 的片上存储 中。 因此本文采用对特征图进行循环分块的设计策 略,将片外 DDR3 中存储的完整特征图分为数个小 块,分批次存储到 FPGA 片上存储 BRAM 中进行后 续的卷积计算,解决了 FPGA 片上存储资源不足的 问题。 循环分块过程如图 3 所示,分块后的小特征 图存储在双缓存结构中。

3. 2. 2 双缓存与缓存分割
为进一步提高整个系统的吞吐量,掩盖 AXI 总 线和内存之间的传输延时,本文设计了一种双缓存 机制,使加速器可以在 AXI 总线传输特征图的过程 中同时进行卷积计算。 双缓存结构如图 4 所示,当 计算单元读取缓存 1 中的数据进行卷积计算的过程 中,缓存 2 可以同时用于接收 AXI 总线中的数据, 而缓存 2 用于计算时,缓存 1 则可以用于接收数据, 以此往复。 该结构可以使计算单元一直处于工作状 态,从而在一定程度上提高整个系统的工作效率。
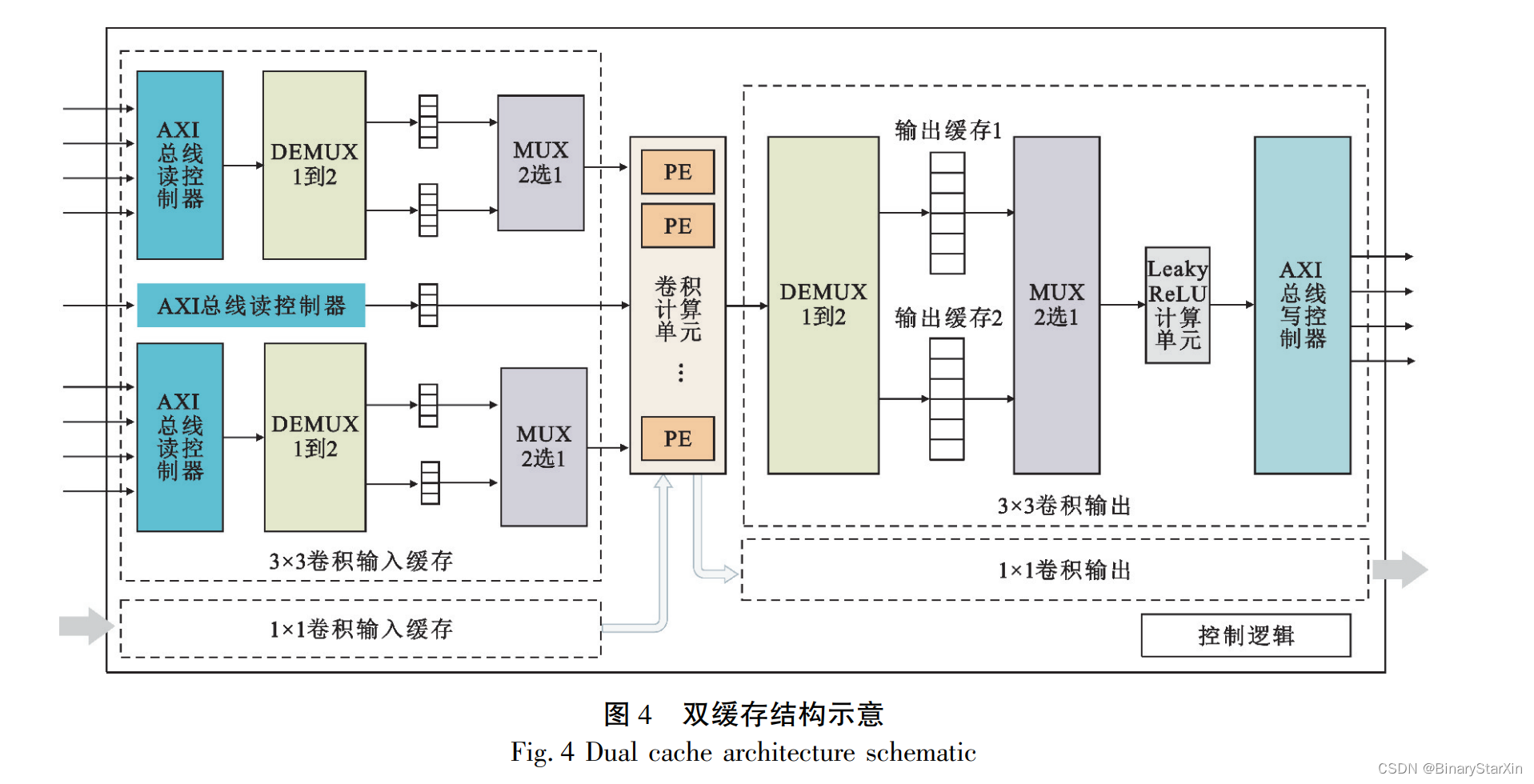
此外,由于 FPGA 中的 BRAM 仅能配置为双端 口进行读写,读写速率受端口数量的限制。 为解决 此类问题,本文采用数组分割的方式,将分割后的数 组存储在不同的 BRAM 中,用数个小容量缓存代替 一个大容量缓存,从而可以实现多个端口同时读写 数据提高数据吞吐量,为后续并行计算结构提供充 足的数据量。
3. 3 卷积计算结构设计
本文中 1×1 卷积和 3×3 卷积采用了复用的计 算单元,需要计算单元尽可能兼容两种卷积计算,此本文设计了输入-输出通道并行的加速结构,该 结构中计算单元的硬件结构与卷积核尺寸无关。 其计算单元中包含 64 个数据处理单元( Processing Element,PE) ,PE 由 8 个输入并行数据选择器、4 个乘法器、1 个加法树以及 1 个累加结构构成。 每 个 PE 单元具有 8 个输入通道其中 1×1 卷积和 3× 3 卷积各 4 个通道,通过数据选择器选择其中 4 个 通道至后续的运算结构,因此实现了 1×1 卷积和 3×3 卷积的计算资源共享。 PE 计算单元结构如图 5 所示。
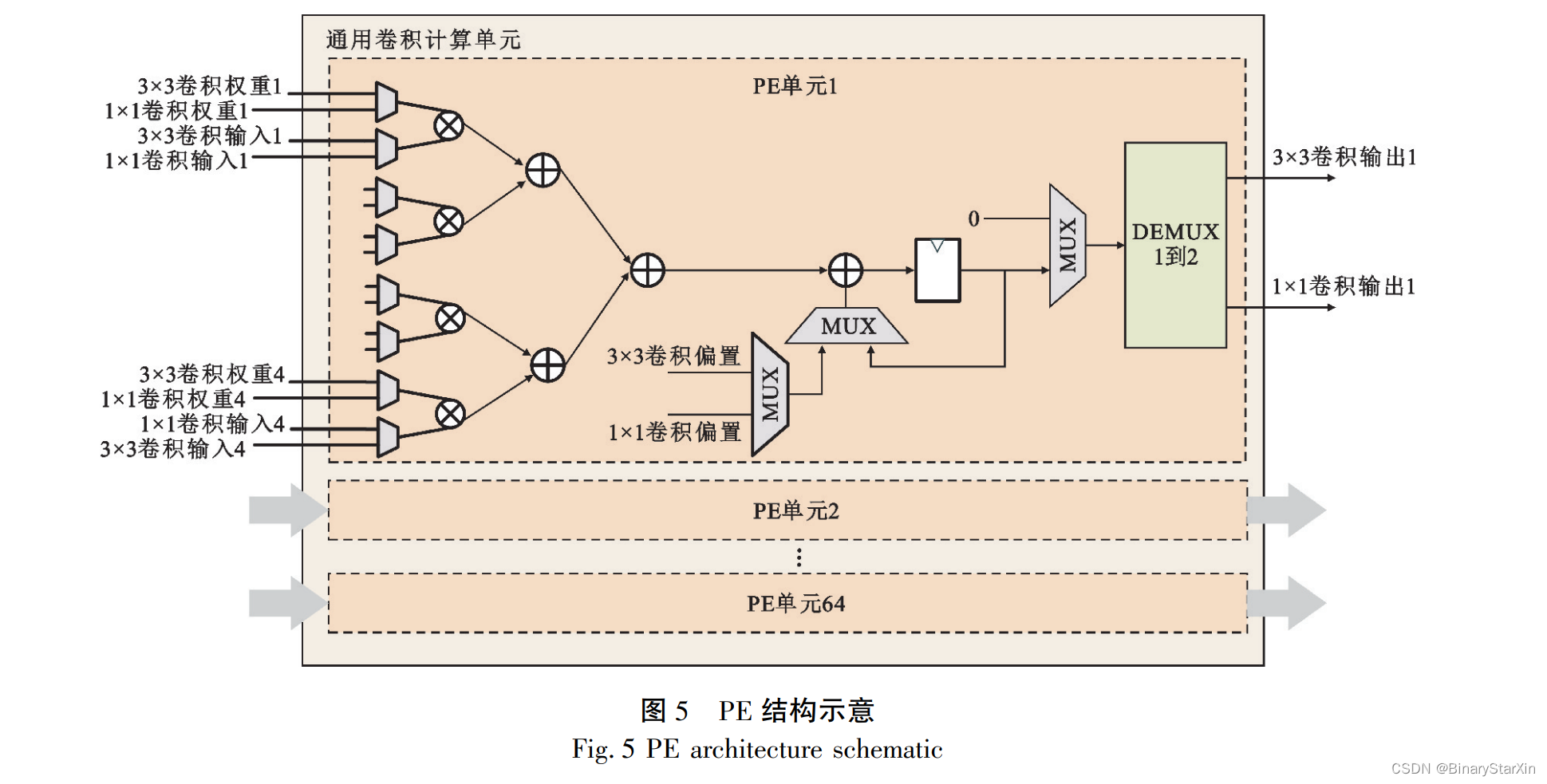
在 YOLOv5s 算 法 中 的 通 道 数 最 大 达 到 了 1 024,受限于 FPGA 资源无法将 1 024 个通道全部 在 FPGA 上实现并行,所以实际输入的特征图通道 数远大于 PE 单元的设计输入通道,因此,输入的特 征图只能分批进入 PE 单元中进行计算。 此外,对 于 3×3 卷积每一个通道的每一个输出数据也都会 进行 9 次卷积核内计算,且输出通道的计算结果是 分批输入特征图卷积累加的结果,因此在 PE 单元 中增加了累加结构用于将不同批次进入 PE 单元的 输出数据以及 3×3 卷积核内计算数据进行累加,实 现完整的多通道卷积计算。 为提高 PE 结构的运行 频率和吞吐量,本文在 PE 单元的硬件结构中插入 了中间寄存器进行了 6 级流水设计,使加速器可以 在高时钟频率下稳定工作。

