
- 1指南:用 Python 打造你的《我的世界 Minecraft》_python mc
- 2基于Hadoop的高校图书馆阅读书目智慧推荐系统设计
- 3Oracle 数据库中 查询时如何使用日期(时间)作为查询条件_oracle 时间条件
- 4【PyTorch】成功解决ModuleNotFoundError: No module named ‘torch’_modulenotfounderror: no module named 'torch
- 5Python 使用can模块(记录稿)_pip install can
- 6python识别图标并点击_python找图点击
- 7https详解之 根证书、服务器证书、用户证书的区别 jg证书
- 8宝妈做什么兼职副业好?适合她们的有哪些?执行力才是关键_宝妈做什么赚钱
- 9SpringCloud的五大组件之一:Netflix Eureka
- 10Flutter中的Firebase:如何使用Flutter连接Firebase数据库_firebase flutter
Jina文章转载:多模态AI的范式变革&多模态AI总结(2022年COLING会议)_multimodal ai
赞
踩
Jina AI是领先的多模态人工智能(
multimodal AI)MLOps平台。我们的领域包括
multimodal AI及其在神经搜索(neural search)和人工智能创作(neural search)作方面的基础设施和应用。我们正处于人工智能新时代的风口浪尖,正从单模态大步迈向多模态 AI 时代。在 Jina AI,我们的 MLOps 平台帮助企业和开发者加速整个应用开发的过程,在这一范式变革中抢占先机,构建起着眼于未来的应用程序。
一、多模态AI的范式(Paradigm)变革
1.1 前言
1. 什么是多模态AI?
“模态”(modal)是指人类的感官:视觉、听觉、触觉、味觉、嗅觉。我们在这里使用它来表示数据模式,例如文本、图像、视频等。真实世界的数据是多模态的。
“多模态”(Multimodal)和“跨模态”(cross-modal)是另外两个经常相互混淆的术语,但意思不一样:
- 多模态深度学习(
Multimodal deep learning)是一个相对较新的领域,涉及从多种模态数据中学习的算法。例如,人类可以使用视觉和听觉来识别人或物体,而多模态深度学习关注的是开发计算机的类似能力。 - 跨模态深度学习(
Cross-modal deep learning)是一种多模态深度学习的方法,其中来自一种模态的信息用于提高另一种模态的性能。例如,如果您看到一只鸟的图片,当您听到它时,您也许可以通过它的歌声来识别它。
旨在与多种模式一起工作的人工智能系统被称为“多模态”。当狭义地指集成不同模式并将它们一起使用的人工智能系统时,术语“跨模态”更为准确。
2. 范式(Paradigm)是什么?
Paradigm (范式) 是一个领域中主流的行事套路,它包括 philosophy (理念) 和 methods (方法)两部分。Philosophy (理念) 这个概念很好理解。比如:
- 购物理念就是什么该买,什么不该买,怎么买。
- 环保理念就是什么还保护,什么不该保护,以及怎么保护。
- 时尚理念就是什么是时尚,什么不是,如何时尚。
所以,某事的 philosophy (理念) 就是,做某事,什么该做,什么不该做,以及方式。
Methods (方法)就是继方式之后的具体的操作。总结起来就是: paradigm (范式) = philosophy (理念) + methods (方法)。
1.2 AI行业已经向多模态AI时代
本节主要来自Jina 官网上Articles板块的一篇insights的文章:《The Paradigm Shift Towards Multimodal AI》,2022.11.30,Jina AI微信公众号将其译为中文《Jina AI创始人肖涵博士解读多模态AI的范式变革》

如果别人问到我们 Jina AI 是做什么的,我会有以下两种回答。
-
- 面对 AI 研究员时,我会说:Jina AI 是一个跨模态和多模态数据的 MLOps 平台;
-
- 面向从业者和合作伙伴时,我会说:Jina AI 是用于神经搜索和生成式 AI 应用的 MLOps 平台。
你可能听说过”非结构化数据“,但什么是“多模态数据”呢?你可能也听说过“语义搜索”,那“神经搜索”是什么新鲜玩意儿呢?可能更加令你困惑的是,Jina AI 为什么要将这四个概念混在一起,开发一个 MLOps 框架来囊括所有这些概念呢?
这篇文章就是为了帮助大家更好地理解 Jina AI 到底是做什么的,以及我们为什么要做这些。 首先,“人工智能已从单模态 AI 转向了多模态 AI”,这一点已成为行业共识,如下图所示:
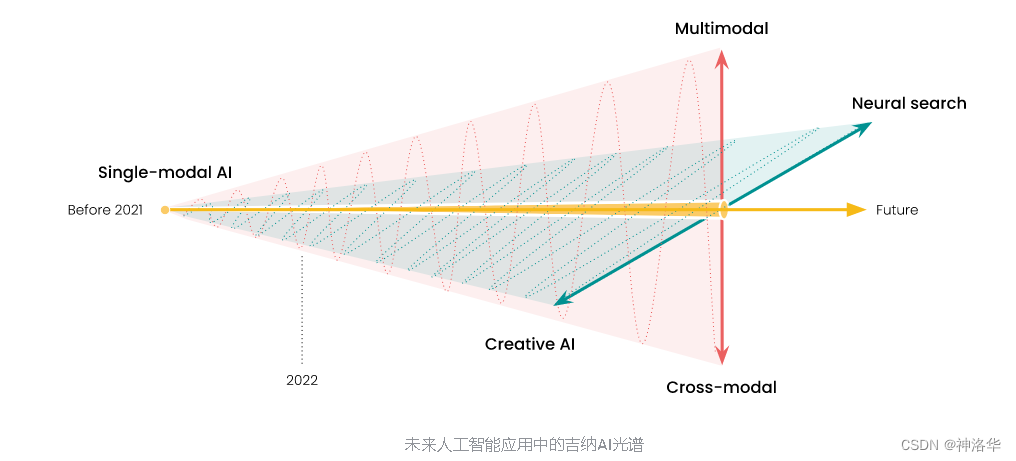
在 Jina AI,我们的产品囊括了跨模态(cross-modal)、多模态((cross-modal)、神经搜索(neural search)和生成式 AI(creative AI),涵盖了未来 AI 应用的很大一部分。我们的 MLOps 平台帮助企业和开发者加速整个应用开发的过程,在这一范式转变中抢占先机,构建起着眼于未来的应用程序。
在接下来的文章里,我们将回顾单模态 AI 的发展历程,看看这种范式转变是如何在我们眼下悄然发生的。
1.3 单模态人工智能
在计算机科学中,“模态”大致意思是“数据类型”。所谓的单模态 AI,就是将 AI 应用于一种特定类型的数据。这在早期的机器学习领域非常普遍。直至今日,你在看机器学习相关的论文时,单模态 AI 依然占据着半壁江山。
1.3.1 自然语言处理
早在2010年,我就发表了一篇关于 Latent Dirichlet Allocation(LDA)模型的改进 Gibbs sampling(吉布斯抽样)算法的论文:

一些资深的机器学习研究人员可能还记得 LDA,这是一种用于建模文本语料库的参数贝叶斯模型。它将单词“聚类”成主题,并将每个文档表示为主题的组合。因此有人称其为“主题模型”
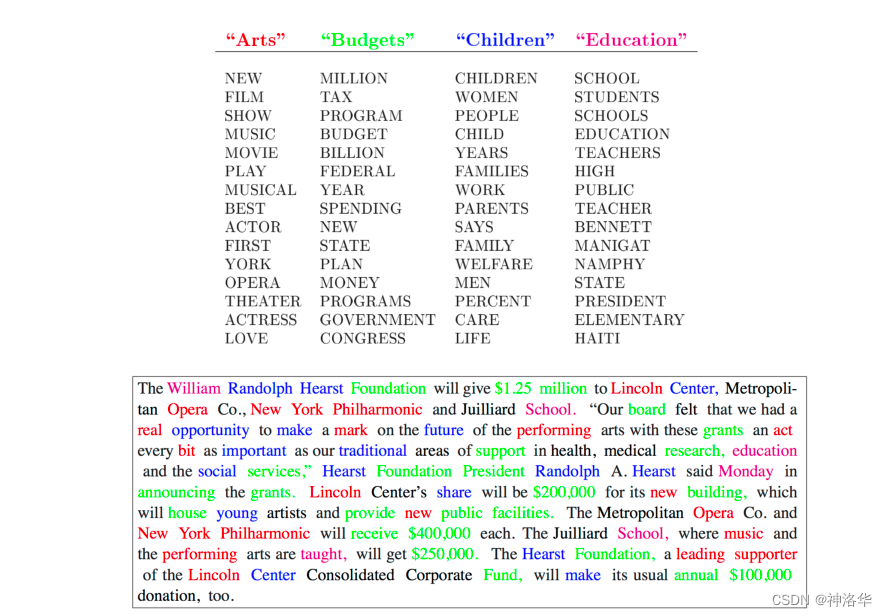
从 2008 年到 2012 年,主题模型一直是 NLP 社区中最有效和最受欢迎的模型之一——它的火热程度相当于当时的 BERT/Transformer。每年在顶级 ML/NLP 会议上,许多论文都会扩展或改进原始模型。但今天回过头来看,它是一个相当 "浅层学习"的模型,采用的是一次性的语言建模方法。它假定单词是由多项式分布的混合物生成的。这对某些特定的任务来说是有意义的,但对其他任务、领域或模式来说却不够通用。
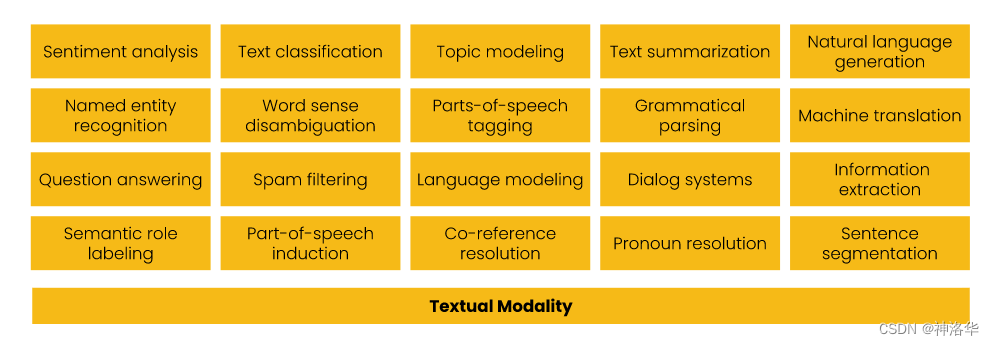
早在 2010-2020 年,像这样的一次性方法是 NLP 研究的常态。研究人员和工程师开发了专门的算法,每种算法虽然都擅长解决一项任务,但是也仅仅只能解决一项任务:
1.3.2 计算机视觉
相较于 NLP 领域,我进入计算机视觉 (CV) 领域要晚一些。2017 年在 Zalando 时,我发表了一篇关于 Fashion-MNIST 数据集 的论文。该数据集是 Yann LeCun 1990 年原始 MNIST 数据集(一组简单的手写数字,用于对计算机视觉算法进行基准测试)的直接替代品。原始 MNIST 数据集对于许多算法来说过于简单 —— 逻辑回归、决策树等浅层学习算法树和支持向量机可以轻松达到 90% 的准确率,留给深度学习算法发挥的空间很小。
Fashion-MNIST 提供了一个更具挑战性的数据集,使研究人员能够探索、测试和衡量其算法。时至今日,超过 5,000 篇学术论文在分类、回归、去噪、生成等方面的研究中都还引用了 Fashion-MNIST,可见其价值所在。
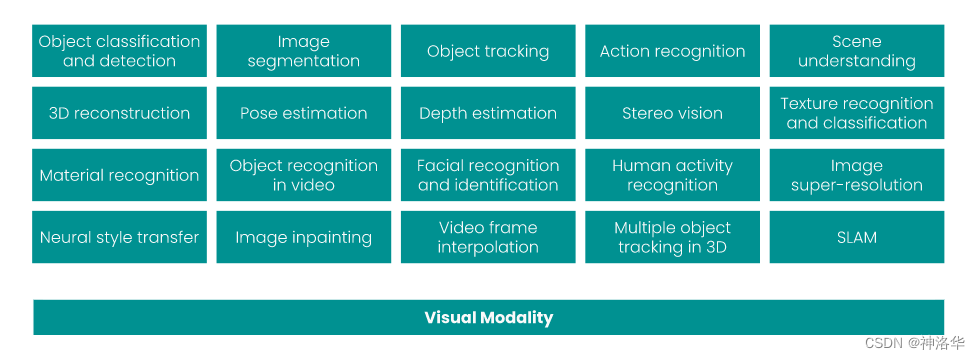
但正如主题模型只适用于 NLP,Fashion-MNIST 也只适用于计算机视觉。它的缺陷在于,数据集中几乎没有任何信息可以用来研究其他模式。如果梳理2010-2020年间最常见的20个CV任务,你会发现,几乎所有任务都是单一模式的。同样的,它们每一个都涵盖了一个特定的任务,但也仅仅涉及一项任务:
1.3.3 语音和音频(Speech & Audio)
针对语音和音频机器学习遵循相同的模式:算法是为围绕音频模态的临时任务而设计的。他们各自执行一项任务,而且只执行一项任务,但现在都在一起执行:
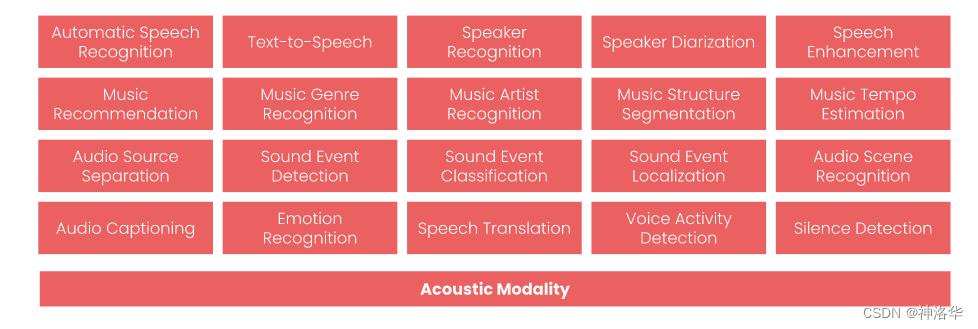
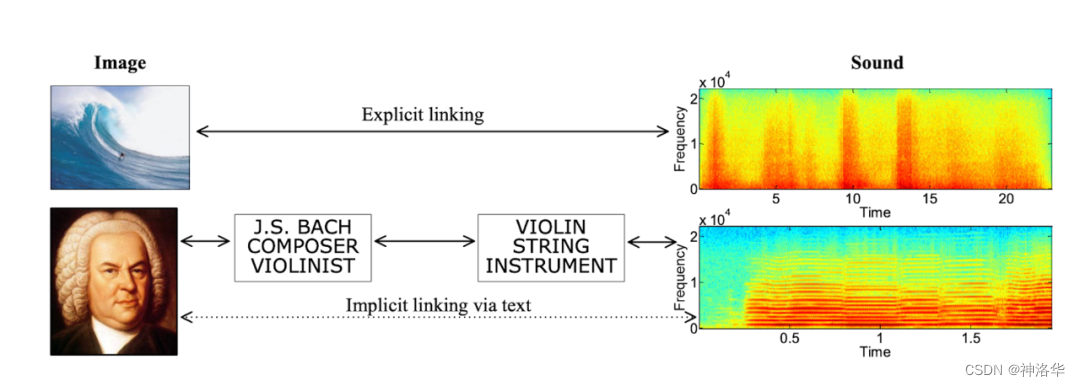
我对多模态 AI 方面最早的尝试之一是我在 2010 年发表的一篇论文,当时我建立了一个贝叶斯模型,对视觉、文本和声音 3 种模态进行联合建模。经过训练后,它就能完成两项跨模式的检索任务:从声音片段中找到最匹配的图像,反之亦然。我给这两个任务起了一个很赛博朋克的名字:“Artificial Synesthesia,人机联觉”。

1.4 迈向多模态人工智能
从上面的例子中,我们可以看到所有的单模态 AI 算法都有两个共同的弊端:
- 任务只针对一种模态(例如文本、图像、音频等)。
- 知识只能从一种模态中学习,并应用在这一模式中(即视觉算法只能从图像中学习,并应用于图像)。
在上文中,我已经讨论了文本、图像、音频。还有其他模式,例如 3D、视频、时间序列,也应该被考虑在内。如果我们把来自不同模态的所有任务可视化,我们会得到一个下面立方体,其中各模态正交排列:

另一方面,多模态人工智能就像将这个立方体重新粘合成一个球体,重要的不同点在于它抹去了不同模态之间的界限,其中:
- 任务在多种模态之间共享和传输(因此一种算法可以处理图像和发短信和音频)。
- 知识是从多种模式中学习并应用于多种模式的(因此算法可以从中学习文本数据并将其应用于视觉数据)。

多模态AI的兴起可归因于两种机器学习技术的进步:表征学习(Representation learning)和迁移学习(transfer learning)。
- 表征学习:让模型为所有模态创建通用的表征。
- 迁移学习:让模型首先学习基础知识,然后在特定领域进行微调。
如果没有表征学习和迁移学习的进步,想在通用数据类型(generic data types)上实行多模态是非常难以落地的,就像我 2010 年的那篇关于声音-图像的论文一样,一切都是纸上谈兵。
2021 年 CLIP发表了,这是一种将图片和文本配对训练的模型,将配对图片-文本对设为正样本,不配对的设为负样本,通过对比学习能够让图片和其对应的语义信息(文字信息)紧密的联系在一起。2022年,DALL·E2 和 Stable Diffusion发布了,两者都是根据 prompts 文本生成对应高质量的图像。
由此可见,范式的转变已然开启:未来我们必将看到越来越多的AI应用将超越单个模态,发展为多模态,并巧妙利用不同模态之间的关系。随着模态之间的界限变得模糊,一次性的方法也不再适用了。

1.5 搜索和生成的二元性(The Duality of Search & Creation)
在Jina官网《Search is Overfitted Create; Create is Underfitted Search》一文中曾提到:神经搜索(neural search)的最大竞争力来自于,这是一种不需要embeddings作为中间表示的技术,一种直接返回所需结果的端到端技术。关于神经搜索更多内容可参考《Neural Search: The Definitive Guide to Building a Neural Search Engine with Jina》
1.5.1 多模态两大支柱:搜索和创作
多模态深度学习具有广泛的潜在用途,例如:
- 自动生成图片描述
- 根据文本提示搜索图片
- 艺术创作,比如文生图
所有这些应用都依赖于两大支柱技术:搜索和创作(search and creation),这里搜索指的是神经搜索。
Neural search(神经搜索):即使用深度神经网络进行搜索。神经搜索擅长处理多模态数据,因为它可以学习将多种模态(例如文本和图像)映射到相同的嵌入空间。这使神经搜索引擎能够使用文本查询搜索图像,并使用图像查询搜索文本文档。

Creative AI(创造AI):使用神经网络模型生成新内容,例如图像、视频或文本。例如,OpenAI的GPT-3可以从提示中创作新的文本,OpenAI的DALL·E 根据文本提示创建新颖的图像。代码示例如下:
server_url = 'grpc://dalle-flow.jina.ai:51005'
prompt = 'an oil painting of a humanoid robot playing chess in the style of Matisse'
from docarray import Document
doc = Document(text=prompt).post(server_url, parameters={'num_images': 8})
da = doc.matches
da.plot_image_sprites(fig_size=(10, 10), show_index=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
创意人工智能具有巨大的潜力。它可以通过创建以下内容来彻底改变我们与机器的交互方式:
- 在计算机与人类交互期间提供更个性化的体验。
- 人物和物体的逼真 3D 图像和视频,可用于电影、视频游戏和其他视觉媒体。
- 视频游戏或其他互动媒体的自然对话。
- 产品的新设计,可用于制造业和其他行业。
- 更具新颖性和创造性的营销材料。
1.5.2 搜索与创作的二元性
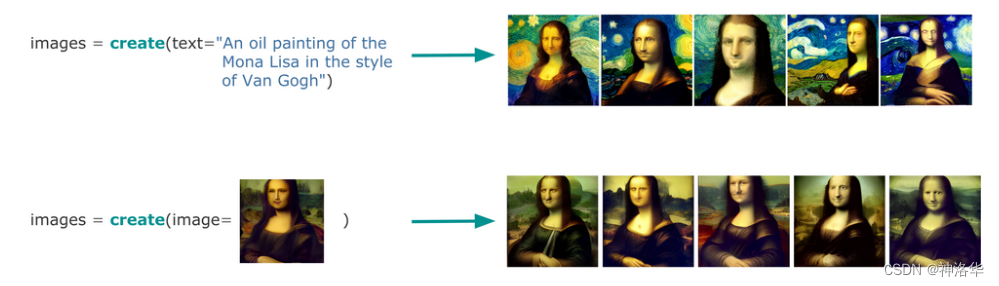
Search和creation是多模态 AI 中的两项基本任务。对于大多数人来说,这两项任务是完全孤立的,并且已经独立研究了很多年。但其实, 搜索和生成是紧密相连的,并且具有共同的二元性 。下面是一些例子:
-
搜索:多模态AI使用文本或图像来搜索图像数据集(文搜图和以图搜图)。
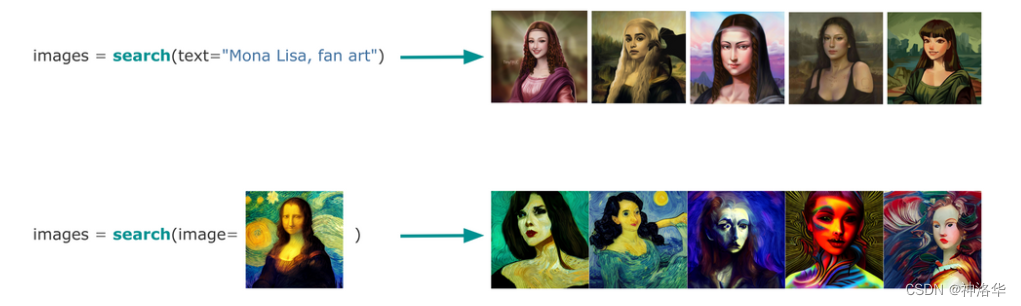
Search : find what you need -
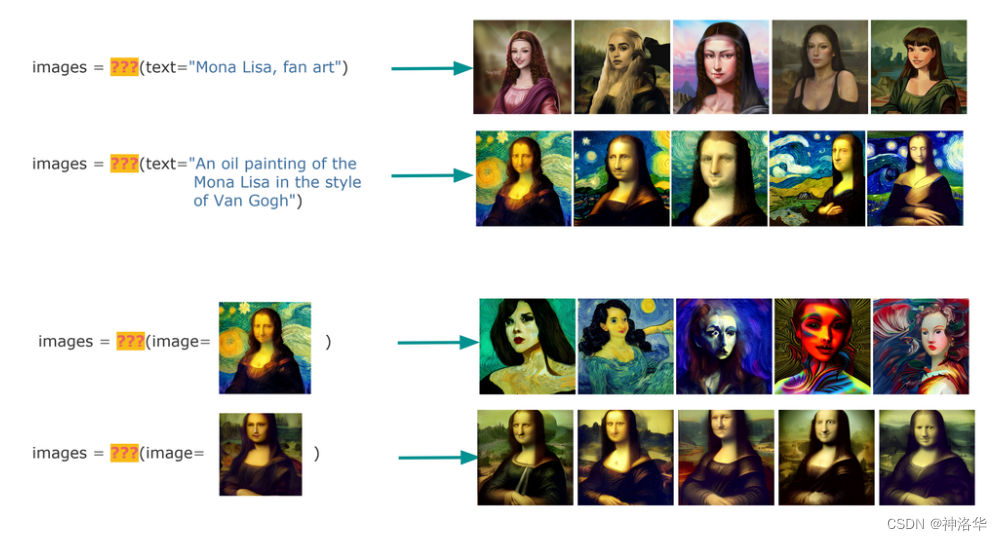
创作:文生图或者丰富/修复指定的图片
Create : make what you need
当把这两个任务组合在一起并屏蔽掉它们的函数名时,你可以看到这两个任务没有区别。两者都接收和输出相同的数据类型。唯一的区别是,搜索是找到你需要的东西,而生成是制造你需要的东西。
当把这两个任务组合在一起并屏蔽掉它们的函数名时,你可以看到这两个任务没有区别。两者都接收和输出相同的数据类型。唯一的区别是,搜索是找到你需要的东西,而生成是制造你需要的东西。
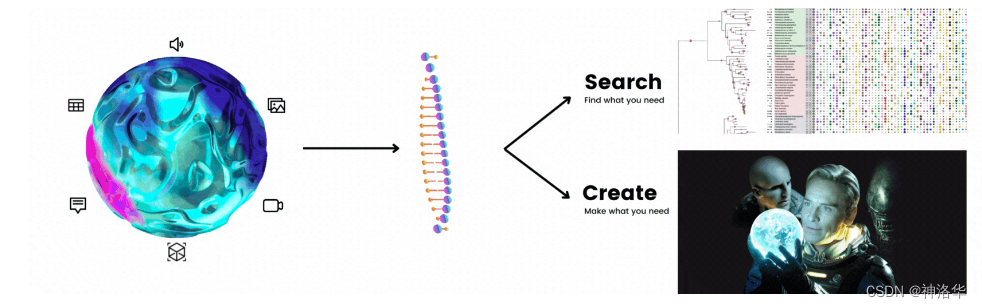
类似于哆啦A梦和瑞克,他们都拥有令人羡慕的超能力。但他们的不同在于哆啦A梦在他的口袋里寻找现有的物品,而瑞克则从他的车间创造了新东西。

Search和creation的二元性也提出了一个有趣的思想实验。想象一下,当生活在一个所有图像都由人工智能生成,而不是由人类构建的世界里。我们还需要(神经)搜索吗?或者说,我们还需要将图像嵌入到向量中,再使用向量数据库对其进行索引和排序吗?
答案是 NO。因为在观察图像之前,唯一代表图像的 seed 和 prompts 是已知的,后果现在变成了前因。与经典的表示法相比,学习图像是原因,表示法是结果。为了搜索图像,我们可以简单地存储 seed(一个整数)和 prompts(一个字符串),这不过是一个好的老式 BM25 或二分搜索。当然,我们作为人类还是更偏爱由人类自己创造的艺术品,所以平行宇宙暂时还不是真正的现实。至于为什么我们更应该关注生成式 AI 的进展 —— 因为处理多模态数据的老方法可能已经过时了。
1.6 总结
我们正处于人工智能新时代的前沿,多模态学习将很快占据主导地位。多模态学习结合了多种数据类型和模式,有可能彻底改变我们与机器交互的方式。到目前为止,多模态人工智能在计算机视觉和自然语言处理等领域取得了巨大的成功。未来,毋庸置疑的是,多模式人工智能将产生更大的影响。例如,开发能够理解人类交流的细微差别的系统,或创造更逼真的虚拟助手。总而言之,未来拥有万种可能,而我们才只接触到冰山一角!
想要从事多模态 AI、神经搜索和创意 AI 方面的工作吗?加入Jina,引领多模态 AI 范式变革!
二、 COLING2022 多模态AI总结
2022年10月21日,韩晓在Jina官网发表文章《COLING2022 Summary on Multimodal AI》,总结了一周前在韩国庆州参加COLING2022会议时,多模态 AI 的相关工作。本节译从此文。
2.1 前言
COLING是每两年举行一次的计算语言学的重要会议,可以学到很多关于计算语言学和NLP的最新研究,例如自动写作评估和多跳问答( automated writing evaluation and multi-hop question answering)。尽管主要是NLP会议,但仍有26场演讲专注于多模态AI,涵盖文本图像,文本视频和文本语音领域。下面重点列举其中三个特别有趣的发言。

2.2 视觉语言模型是基于常识性知识吗(Commonsense Knowledge)?
2.2.1 什么是常识?常识知识的维度有哪些?
参考论文《Dimensions of Commonsense Knowledge》,此论文的介绍性博文《天天说常识推理,究竟常识是什么?》
1. 什么是常识
常识的例子:
- 睁开眼睛打喷嚏是不可能的。(还真没留意。)
- 北极熊是左撇子。
- 长颈鹿没办法咳嗽
2. 常识研究
关于常识的研究近年来是比较火热的话题,在NLP领域,研究的方向主要有两条线:
- 各种benchmark数据集的构建,各种刷榜以测试我们的模型是否具备某些类型的常识
- 构建常识知识图谱,关注点主要在于如何挖掘常识知识、构建结构化常识知识。比如有正式命名为常识KG(知识图谱)的,比如ATOMIC、WebChild;也有包含常识知识但非正式命名为常识KG的知识源,如WordNet、VerbNet等等。
两条线的交叉点在于如何利用常识知识辅助各类下游任务。
流行的常识KG:ConceptNet。

所以常识知识领域的研究看起来像是遍地开花,但每个知识源的格式、创建的方法、知识类型的覆盖率都各不相同。对于现存的常识KGs到底包含了哪些类型的常识知识,每个KG对每种类型的覆盖程度是怎样的,以及哪些类型对于下游常识推理任务是有用的,缺乏一个统一的定论,直到《Dimensions of Commonsense Knowledge》。这篇文章主要想探究两个问题:
- 如何研究现有常识KGs中包含了哪些维度的常识知识?
- 对于常识推理任务,常识知识图谱有多重要?
此文既可以看成是对常识知识的维度的正式划分,也可以看成是对常识知识融合[1]是有意义的一个证明。
3. 常识维度(commonsense dimensions)有哪些?
作者首先对现有的20个包含常识的知识源进行了调研,从中挑选了7个进行研究。对现有常识KGs中包含的常识知识的关系类型进行整理、重新聚类后,定义了13个常识维度:

每个维度包含若干个具体的关系。比如维度distinctness包含ConcpetNet中的{Antonym,DistinctFrom}两个具体关系。统一了维度后,就可以从维度的视角统一研究各个常识KGs中存在的常识知识,也可以融合各个KGs的知识进行知识的增强。
ps:每个知识源的关系标签不一样,所以每个维度包含的具体关系的名字也不相同,详情参加论文中的Table2。
在统一所有常识KGs的维度的基础上,此文首先对各个常识KGs中包含常识维度进行了统计分析,对比了它们的维度知识的数量、覆盖度、冗余度。
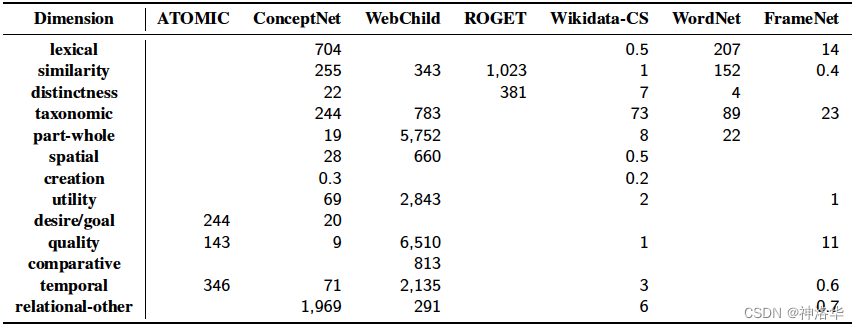
可以看出,13个关系维度在知识源中的分布是不平衡的。
- 较好捕捉的关系维度,更多涉及词汇关系和分类关系,比如lexical, similarity, distinctictness, taxonomic。
- 部分维度则非常罕见,比如comparative维度只出现在WebChild,creation维度只出现在了两个知识源中,并且只有500条三元组。
另外还探究了哪些维度的常识有助于提升对下游常识推理任务的性能,具体的提升有多大,具体可查看原文。
2.2.2 视觉语言模型是基于常识性知识吗
来自2022年第29届计算语言学国际会议 论文集论文:《Are Visual-Linguistic Models Commonsense Knowledge Bases?》,下同。
在过去的几年里,我们都看到了预训练语言模型(PTLM)的巨大潜力。Transformer和GPT等模型因其作为常识性知识库的潜力(commonsense knowledge base)而广泛用于许多下游任务。但是,用于训练 PTLM 的文本语料库可能会使它们非常有偏见,会使它们可能一致性和鲁棒性不够(inconsistent and not very robust)。
在本文中,Yang和Silberer认为,单独的文本语料库可能不足以获取知识,并针对UNITER、VILBERT和CLIP等视觉语言模型提出了重要问题:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/木道寻08/article/detail/760287
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

