
热门标签
热门文章
- 1Python压缩、减压7z文件_py7zr
- 2docker 创建容器时报错:WARNING: IPv4 forwarding is disabled. Networking will not work.
- 3复制知乎文章_知乎f12
- 4外包员工和正式员工有什么区别?为什么外包员工总受鄙视_浪潮外包和正式员工区别
- 5魅族员工哀叹把青春献给了公司,当年如果选择小米,人生会不一样
- 6Pytorch学习笔记(3)—word2vec_pytorch word2vec.word2vec经验
- 7最近,大模型岗位爆了。。。
- 8【深度学习实验】循环神经网络(五):基于GRU的语言模型训练(包括自定义门控循环单元GRU)_gru代码实现及模型训练
- 9.NET、C# 和ASP.NET 三者的关系和区别_aspnet和c#什么关系
- 10OSPF被动接口配置(华为)_怎么开启被动端口设置
当前位置: article > 正文
分析Booking的150种机器学习模型,我总结了六条成功经验
作者:木道寻08 | 2024-07-05 10:07:09
赞
踩
booking数据分析

(图片付费下载自视觉中国)
作者 | Adrian Colyer
译者 | Monanfei
出品 | AI科技大本营(ID:rgznai100)
本文是一篇有趣的论文(150 successful machine learning models: 6 lessons learned at Booking.com Bernadi et al., KDD’19),通过分析 Booking.com 上 150 个成功的面向客户的机器学习应用程序的集成,该论文对其中的经验教训进行了精彩的总结,主要内容如下:
-
使用机器学习模型的项目将带来巨大的商业价值
-
模型表现并不代表商业绩效
-
明确你要解决的问题
-
预测服务的延迟很重要
-
尽早获得有关模型质量的反馈
-
使用随机对照试验测试模型对业务的影响
不仅如此,本文更是包含超过这 6 条之外的建议。
我们发现,推动真正的业务影响非常困难,而且很难隔离和理解建模工作与观察到的影响之间的联系……我们的主要结论是,构建机器学习支持的 150 种成功产品有一个基础,那就是一个与其他学科相结合的,迭代的,受假设驱动的过程。
请千万不把上面的话理解成投资机器学习是不值得的,恰恰相反,在面向用户的场景中,锻炼设计、构建和实施成功的机器学习模型的能力,这正是组织竞争力的基础。
场景
-
您可能听说过 “全球最大的在线旅行社” Booking.com 。为了使向用户提供出色的体验,目前有许多挑战摆在它的面前
-
推荐的风险很高:在错误的地方预定住宿比播放不喜欢的电影要糟糕得多!
-
用户在预订旅行时仅提供很少的信息,我们很难明白用户到底在寻找什么
-
住宿供应受到限制,不断变化的价格会影响客人的喜好
-
用户的喜好可能会在他们每次使用该平台时发生变化(例如,每年仅预订一次或两次)
-
住宿的信息过于丰富,这可能会让用户不知所措
不同类型的模型
机器学习模型的好坏会影响 Booking.com 许多方面的体验。一些模型非常具体,着眼于特定上下文中的特定用例(例如针对渠道中某个点量身定制的建议);另一些模型则充当语义层,对上下文中的一些概念进行建模(例如,根据旅行目的地,指示用户的灵活性的模型)。
在 Booking.com 上部署的模型可以分为六大类:
-
旅行者偏好模型:在语义层中运行,并对用户偏好(例如灵活性程度)做出广泛的预测。
-
旅行者上下文模型:也是语义模型,用于预测旅行发生的上下文(例如,与家人,与朋友,商务……)。
-
项目空间导航模型:跟踪用户的浏览内容,可为用户的历史记录和整个目录提供建议。
-
用户界面优化模型:优化 UI 的元素,例如背景图像,字体大小,按钮等。有趣的是,“ 我们发现,几乎没有一个特定的值是一个整体最优的情况,因此我们的模型考虑了上下文和用户信息,从而决定最佳的用户界面。”
-
内容策划模型:策划人为生成的内容,例如评论,以决定显示哪些内容
-
内容增强模型:计算有关行程要素的其他信息,例如当前具有较高价值的选择、区域价格趋势等。
第 1 课:使用机器学习模型的项目将带来巨大的商业价值
上述的所有模型系列都在 Booking.com 上产生了商业价值。此外,与未使用机器学习的其他成功项目相比,基于机器学习的项目往往会带来更高的回报。
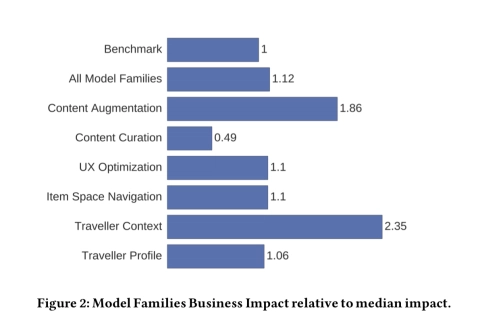
这些机器学习模型部署后,除了获得直接的业务收益外,它们经常成为进一步产品开发的基础。下图显示了一系列模型部署后的影响,每个新的部署都建立在原始部署之上,并进一步改善了业务成果。
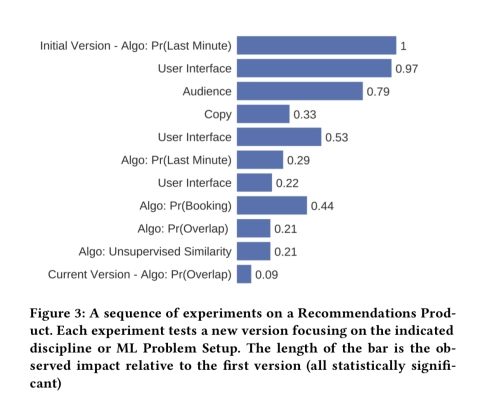
第 2 课:
模型表现并不代表商业绩效
通过衡量对业务指标影响的随机对照试验,Booking.com 能够估计模型提供的价值。
一个有趣的发现是,提高模型的性能并不一定会转化为业务价值的增长。
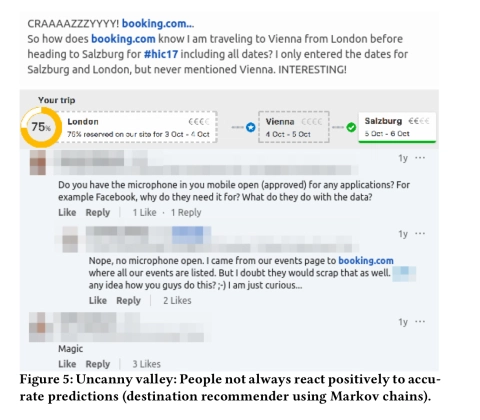
这种现象可能是多种因素导致的,包括业务价值饱和(无论做什么,都无法再提升);由于接受试验的人群较少而导致节段饱和(新旧模型在很大程度上吻合);对代理指标的过度优化(特别是那些无法将自身(例如点击)转换为所需业务指标的代理指标);以及怪异的山谷效应。下图可以很好地说明这些问题:
第 3 课:
明确你要解决的问题
在开始构建模型之前,值得花费时间仔细思考要解决的问题的定义。
问题构建过程将业务案例或概念作为输入,并输出定义明确的建模问题(通常是监督式机器学习问题),这样就能提出一个好的解决方案,从而有效地对给定业务案例或概念进行建模。
一些最强大的改进并非是在给定设置的上下文中改进模型,而是更改设置本身。例如,将基于 Clink 数据的用户偏好模型更改为基于来宾评论数据的自然语言处理问题。
总的来说,我们发现最好的问题往往不是立即想到的,改变设置是提高价值的卓越方法。
第 4 课:
预测服务的延迟很重要
在一项引入合成延迟的实验中,Booking.com 发现,延迟增加约 30% 会使转化率降低约 0.5%,“ 这是我们业务的相关成本 ”。
延迟对于机器学习模型尤其重要,因为它们在进行预测时需要大量的计算资源。即使是数学上简单的模型也可能会引入相关的延迟。
Booking.com 竭尽所能以最大程度地减少模型引入的延迟,包括水平缩放的模型分布式副本,内部开发的自定义线性预测引擎,偏好具有较少参数、批处理请求以及预计算 and/or 缓存的模型。
第 5 课:
尽早获得有关模型质量的反馈
当模型满足请求时,监视其输出质量至关重要,但这至少带来了两个挑战……
-
由于难以观察真实标签,反馈不完整
-
反馈会有延迟,例如在预订时做出的关于用户是否会留下评论的预测,直到旅行完成后才能进行评估。
Booking.com 提出了一种策略:查看模型生成的响应的分布。该策略已经成功地在这些情况下针对二进制分类器进行了部署。“ 具有一个清晰稳定点的平滑双峰分布,这是模型成功区分两类数据的标志”。其他形状(参见下图)则表明该模型正在陷入困境。
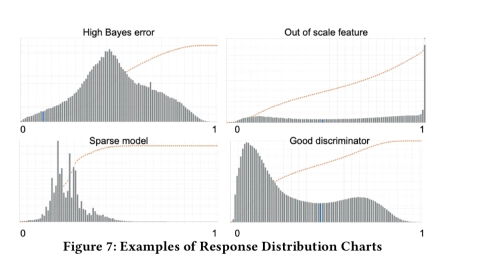
…响应分布分析已被证明是非常有用的工具,可让我们尽早发现模型中的缺陷。
第 6 课:
使用随机对照试验测试模型对业务的影响
在这项工作中,绝大多数成功的机器学习成功案例都是通过复杂的实验设计实现的,这些实验设计既可以指导开发过程,也可以检测其影响。
本文提供了有关如何在不同情况下进行实验的建议。
-
如果并非所有受试者都有资格接受更改(例如,他们没有模型所要求的特征),则从合格子集中创建实验组和对照组。
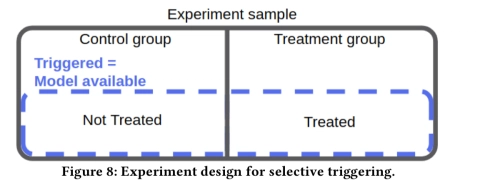
-
如果模型仅产生影响用户体验的一个小方面的输出,则进一步将实验组和对照组进行限制,即模型仅产生用户可观察到的输出的情况(当然在对照组)。为了评估性能的影响,需要添加第三个控制组,在控制组中不会调用该模型。
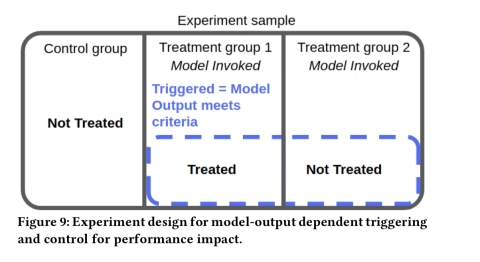
-
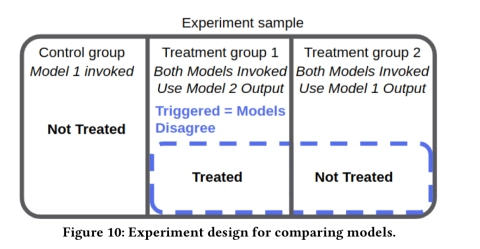
在比较模型时,我们对两种模型不一致的情况很感兴趣。我们将使用一个调用当前模型的对照组作为基准(假设针对改进后模型,我们对当前模型进行测试)。实验设计如下:
总结
假设驱动的迭代和跨学科的集成,这些是我们利用机器学习实现价值的方法的核心,我们希望这项工作可以为其他机器学习从业人员提供指导,并引发对该主题的进一步研究。
原文链接:
https://blog.acolyer.org/2019/10/07/150-successful-machine-learning-models/
(*本文为AI科技大本营编译文章,
转
载请微
信联系 1092722531
)
◆
精彩推荐
◆
早鸟票倒计时最后
2天
,扫码购票立减
2600元
!
2019 中国大数据技术大会(BDTC)再度来袭!
豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。

推荐阅读
诺贝尔物理学奖出炉,三大天体物理学家获奖
美政府再将8家中国企业列入“黑名单”,海康、科大讯飞、旷视等做出回应
Python入门你要懂哪些?
百度回应李彦宏卸任百度云执行董事;甲骨文拟增聘 2000 员工拓展云服务;PostgreSQL 12 正式发布 | 极客头条
真·上天!NASA招聘区块链"多功能复合型"人才, 欲保护飞行数据安全……
10 月全国程序员工资统计,一半以上的职位 5 个月没招到人!
【光说不练假把式】今天说一说Kubernetes 在有赞的实践

你点的每个“在看”,我都认真当成了喜欢
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/木道寻08/article/detail/789872
推荐阅读
相关标签

