
- 1去哪里找抖音短视频素材?告诉大家几个抖音短视频素材下载资源_抖音资源哪里找
- 2Linux权限有哪些?500代表什么意思?_权限500啥意思
- 3软件测试面试题及答案_软件测试上机考试面试
- 4【机器学习入门】拥抱人工智能,从机器学习开始
- 5微信小程序使用ColorUI组件库_微信小程序只引用部分colorui组件
- 6使用Typecho搭建个人博客网站,并内网穿透实现公网访问
- 7算法沉淀——BFS 解决拓扑排序(leetcode真题剖析)_bfs拓扑排序
- 8pytorch实现word embedding :torch.nn.Embedding_pytorch embedding python 实现
- 9JVM笔记_java 虚拟机的类型
- 10【OpenVINO】基于 OpenVINO Python API 部署 RT-DETR 模型_openvino 的github链接
双塔模型及其优化方法总结
赞
踩

作者:星翰
链接:https://zhuanlan.zhihu.com/p/576286147
后台留言『交流』,加入 NewBee讨论组
双塔模型结构凭借其出色的预测效率广泛应用于推荐系统、文本匹配等领域的召回阶段。经典工作如微软的DSSM[1],谷歌的YoutubeDNN[2],Airbnb的个性化用户embedding[3]等方法均在许多工业场景落地,并取得了显著的效果提升。
随着双塔模型自身优化逐渐进入深水区,边际收益越来越低,最近一些研究工作从双塔模型与交互模型客观存在的效果差距入手,通过给双塔模型增加交互信息,交互模型蒸馏双塔等方式取得了不错的效果,为双塔模型优化拓展出新空间。
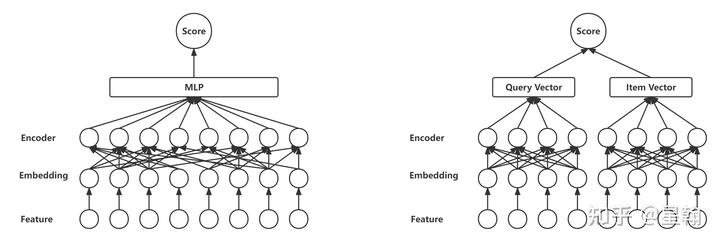
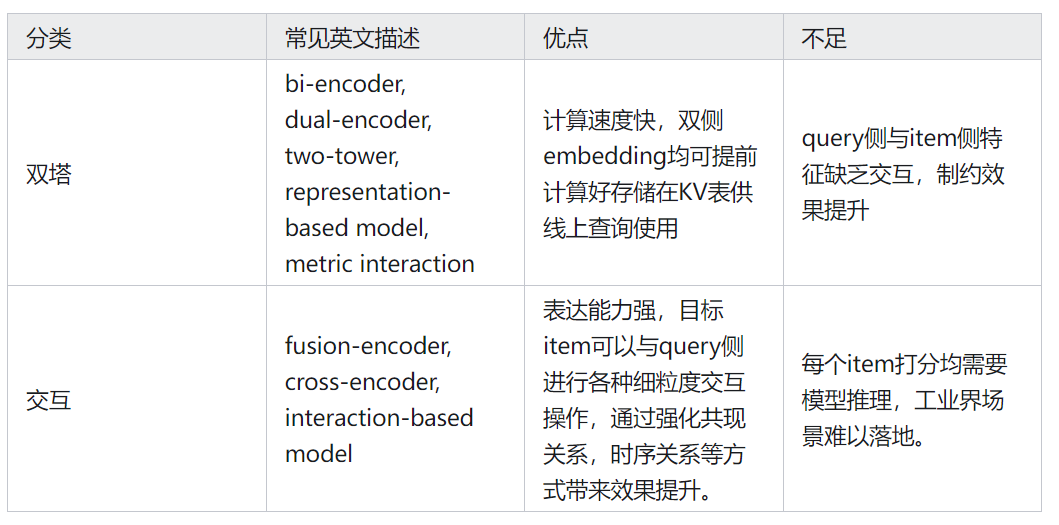
一 优化方法概述
本文所述优化方法基于传统双塔结构展开,一些依赖强大工程能力配合的方法(COLD,TDM系列,DR等)不在此范畴。
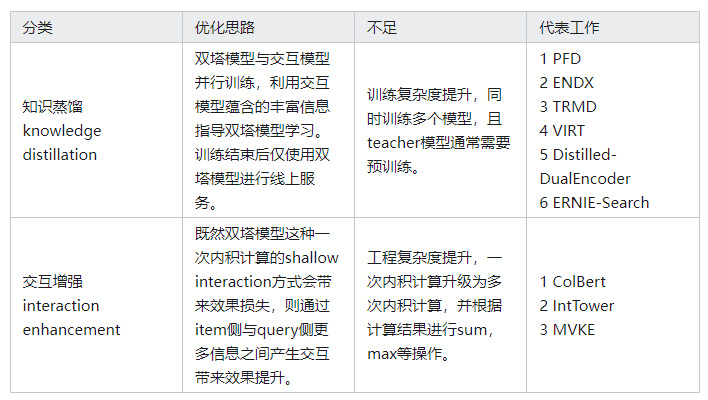
二 知识蒸馏 knowledge distillation
1. PFD[4]
离线训练时teacher模型添加了一批优势特征,优势特征主要包括以下两类:交互特征(双塔结构无法获取),如用户过去24小时候选item同类目点击。点击后信息(在线服务无法获取),如点击后页面停留时长,与店家交流状态等。teacher模型无需提前预训练,与student模型同步更新,初始阶段两个模型各自独立更新,待teacher模型稳定后开始蒸馏。
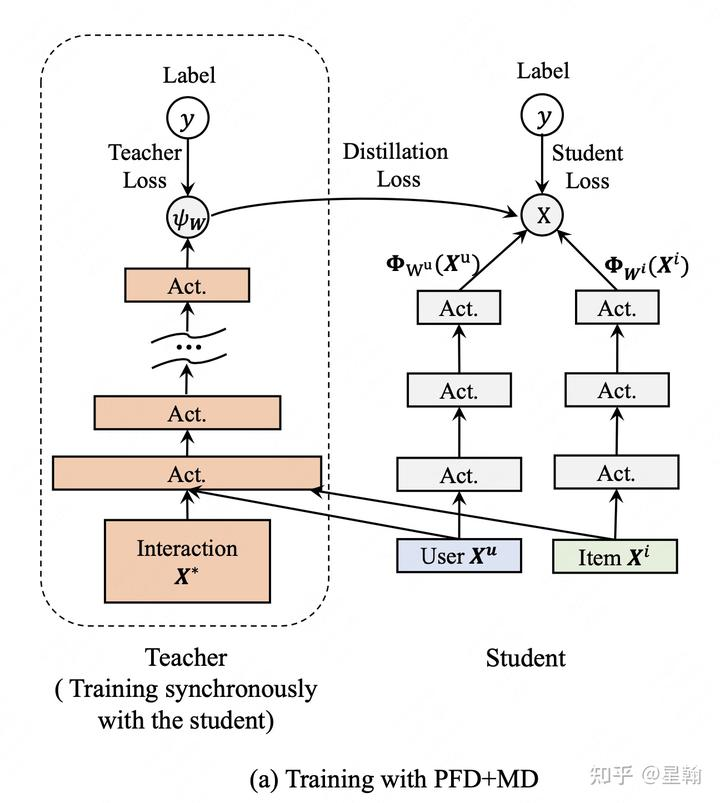
蒸馏方式:共享特征表征,对于teacher与student的公共特征,互相share特征对应的embedding;增加辅助loss,student模型预测值拟合真实label的同时也要拟合teacher模型的预测值。
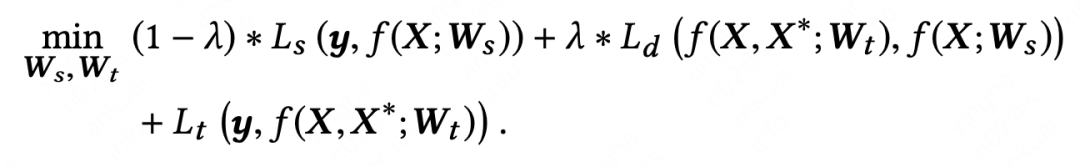
2. ENDX[5]
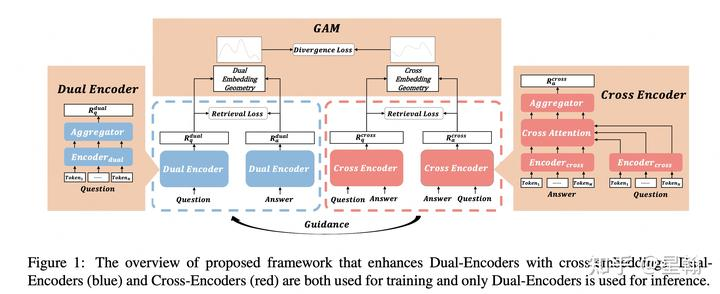
teacher模型使用交互信息生成与student模型相同size的query和answer(推荐系统中的item)表征,以便蒸馏时为student模型提供更多学习信号。PFD中由于teacher模型与student模型网络结构差异大,只能使用预测值logit进行蒸馏,导致teacher模型可提供的监督信息较少。
蒸馏方式:通过Geometry Alignment Mechanism (GAM)机制对齐student与teacher各自对应的query和answer表征,具体包含以下几步:
通过条件概率刻画两个向量相似程度,两个向量越相似,条件概率取值越大
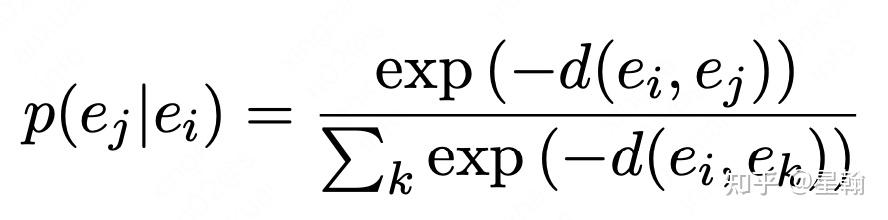
一个Batch中所有同类型向量pair在student网络中计算出相似度对应的概率分布,同时在teacher网络中也计算出相似度对应的概率分布。通过KL-divergence刻画两个概率分布的接近程度
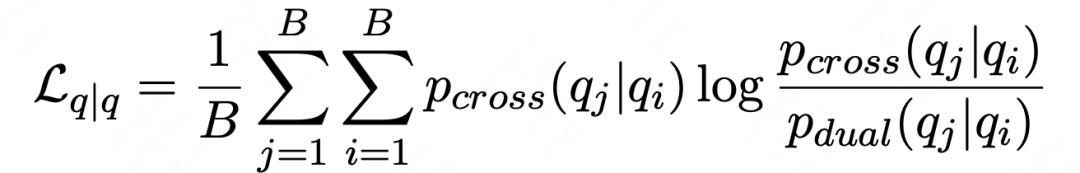
四种类型向量pair(P(answer|query), P(answer|answer), P(query|answer), P(query|query))共同构成迁移辅助loss
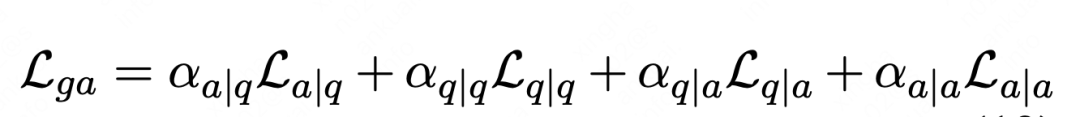
3. TRMD[6]
有两个teacher,cross-encoder teacher 和 bi-encoder teacher,两个teacher均需要提前预训练,蒸馏时参数固定不变。遗憾的是作者没有论证两个teacher相比一个teacher的效果提升幅度。
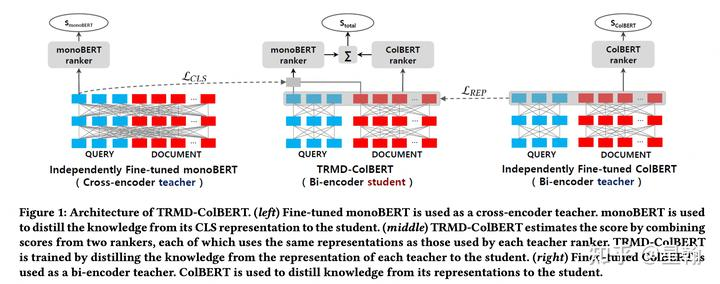
蒸馏方式:
cross-encoder teacher指导student学习CLS表征(CLS为Bert输出的CLS表征,一般表示doc的起始字符)
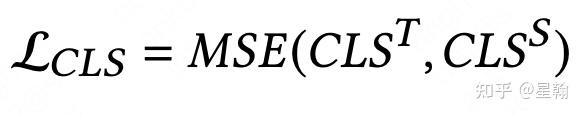
bi-encoder teacher(ColBert) 指导student学习REP表征(REP为Bert输出的所有表征,包含CLS,query,doc。特别需要注意bi-encoder teacher也是双塔,所以它和student一样有两个CLS,若想通过cross-encoder teacher学习REP表征,需要对两个CLS进行max或者sum等操作)
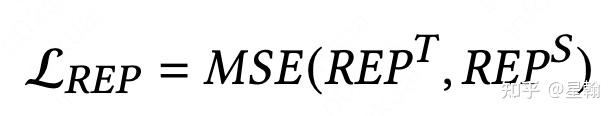
student模仿两个teacher分别计算score,两个score相加作为模型预测值。
bi-encoder如何得到cross-encoder的分数?将bi-encoder的两个CLS表征聚合为一个,后续流程不变。
4. VIRT[7]
teacher 模型中query和doc各自序列的所有word在transformer encoder层计算得到的Q,K均包含interaction信息。每个word都有对应通过transformer计算得到的q,k,v参数,因此可以使用teacher模型蕴含interaction信息的q,k参数蒸馏student模型。teacher模型需要预训练,蒸馏过程中参数固定。
下图中X代表query,Y代表doc。

蒸馏方式:
teacher模型所有word通过transformer计算得到的参数自身做矩阵乘法后可以分解为四部分,仅和query相关,query和doc交叉,doc和query交叉,仅和doc相关。对于交叉部分,使用teacher模型的计算结果来蒸馏student模型对应缺失的部分,如图b所示,蒸馏过程通过辅助loss实现。
为了弥补单纯向量内积计算无交互信息的缺点,作者设计了一个attention机制使用上一步蒸馏学到的交互信息分别对query和doc侧最后一层表征进行加权。具体计算方式如下:
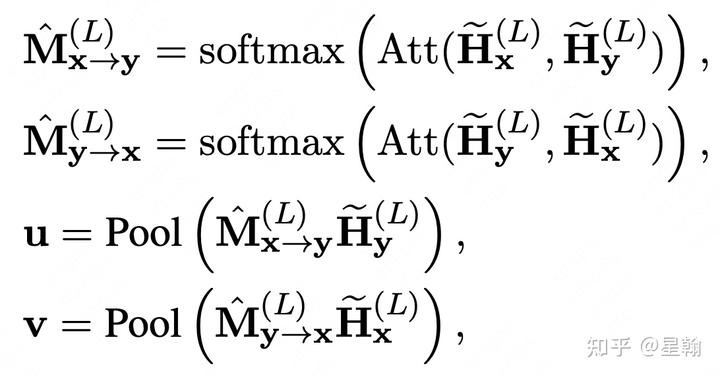
5. Distilled-DualEncoder[8]
核心思路与上一篇VIRT类似,额外添加了两个模型预测值之间的soft-label蒸馏
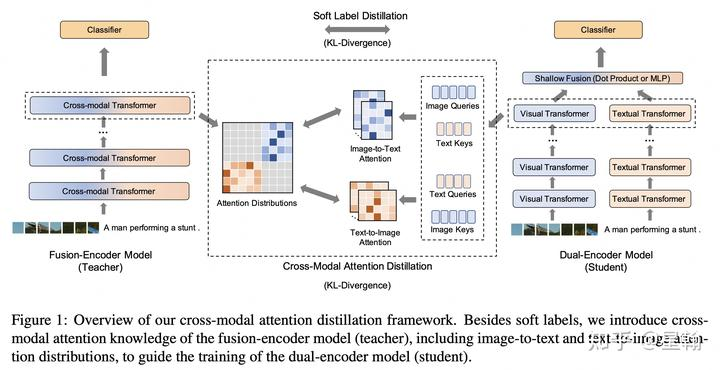
蒸馏方式:
与VIRT类似采用transformer对每个word进行encoder,然后通过矩阵乘法获得teacher的交叉信息来蒸馏student缺失的部分。唯一的区别是辅助loss的选择,VIRT中使用L2距离,本文使用KL-divergence。
teacher预测值蒸馏student预测值
6. ERNIE-Search[9]
提出cascade蒸馏范式,鉴于bi-encoder直接学习cross-encoder难度比较大,引入Colbert这种增加交互信息的bi-encoder作为信息传递的桥梁。训练完毕后student模型依然是bi-encoder结构,只需要一次内积计算。
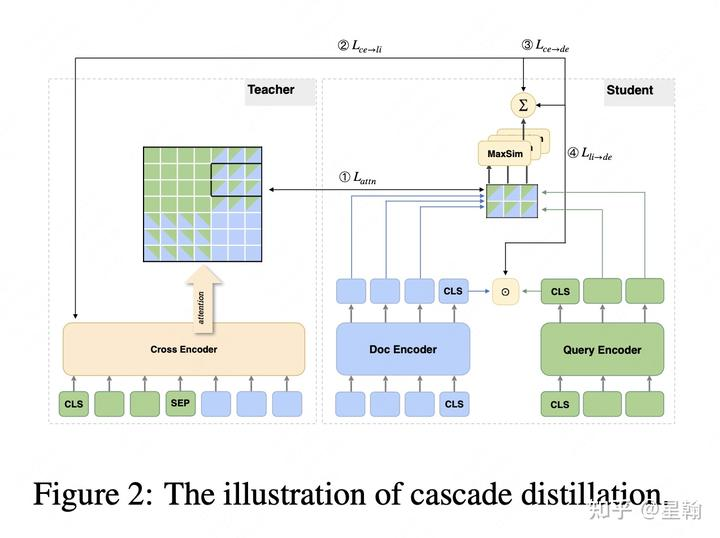
蒸馏方式:两层蒸馏
ColBert 蒸馏 student.
分别计算query对所有候选doc的打分概率分布
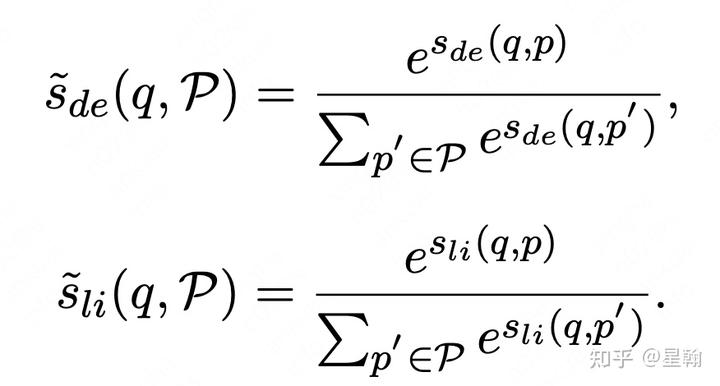
通过KL-divergence刻画两个概率分布的接近程度
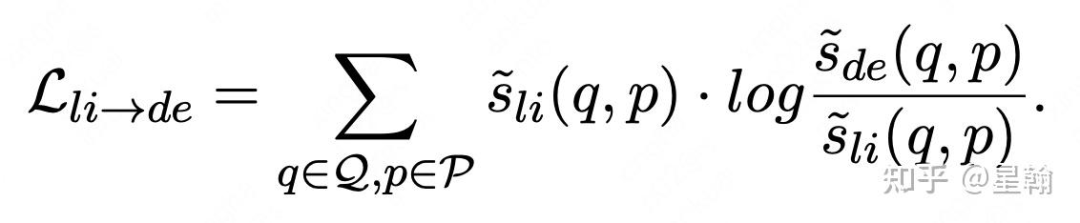
ross-encoder teacher蒸馏ColBert
与上一步类似计算teacher对所有候选doc打分的概率分布,然后通过KL-divergence刻画接近程度。额外引入辅助loss蒸馏word-level的attention信息,具体思路与VIRT和Distilled-DualEncoder类似,teacher模型蕴含的交叉信息指导student缺失部分学习。
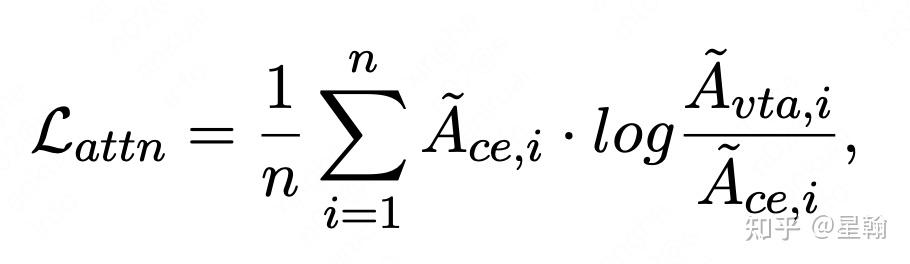
作者还额外添加了teacher对student的辅助loss,最终loss包含三个模型自身的训练loss以及四个辅助loss
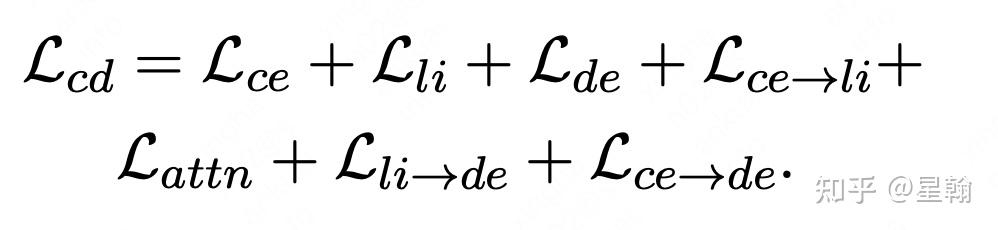
三 交互增强 interaction enhancement
1 ColBert[10]
ColBert是这个方向的开创性工作,后续多篇论文均在此基础上进行深入研究。论文中将这种交互描述为late interaction,对应cross-encoder一开始就交互的early interaction。query和doc的相似性刻画由单一向量内积升级为累加query下每个word与doc的相似性。
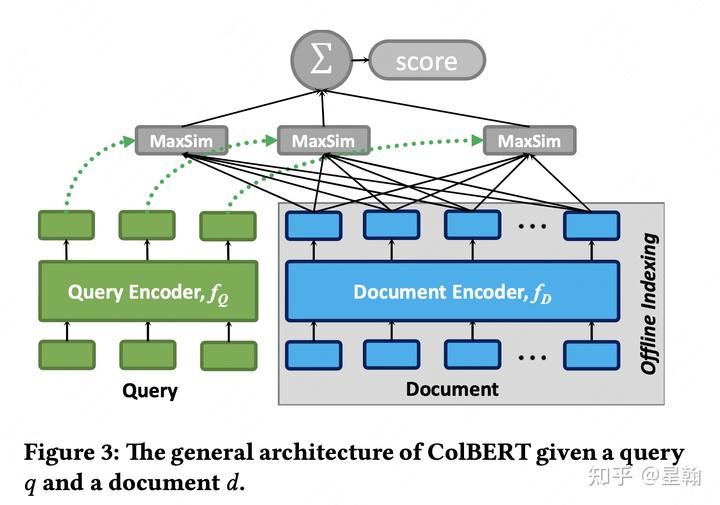
interaction方式:给定query中的每个word,遍历doc中的word计算匹配度得分,汇总query下所有word的匹配度得分作为最终得分
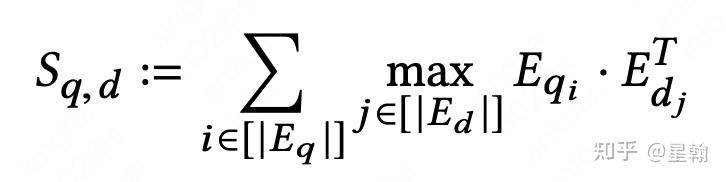
积计算次数:query_word_num * doc_word_num
2 IntTower[11]
item侧最后一层隐向量与user侧多层隐向量产生交互来刻画相似性。此外还通过正负样本对构造辅助loss(L_cir)指导模型通过自监督学习的方式增强相似性刻画。
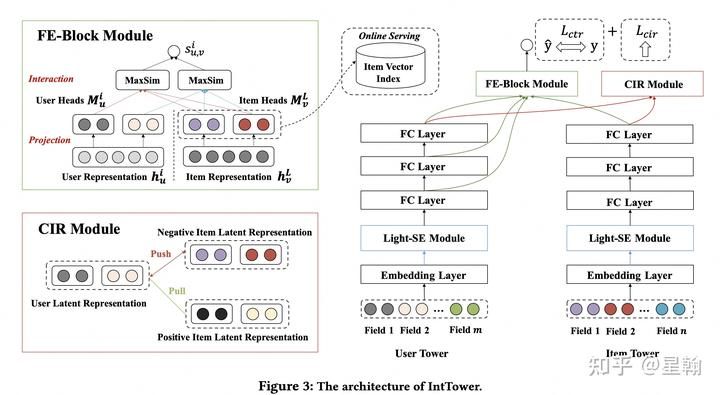
interaction 方式: 论文中将两种交互方式进行融合
item最后一层表征与user侧多层(L)表征交互作为模型预测值,共分三步
user/item 侧隐层分别映射至M个子空间(M个向量)
user侧每一层的M个向量与item侧M个向量计算内积然后取max作为该层表征得分
user侧多层表征得分累加作为模型预测值
正负样本对进行交互作为辅助loss:L_cir
除正样本外的所有样本均作为负样本,使用召回中常用的InfoNCE方法达到user与positive接近,与negative远离的效果。
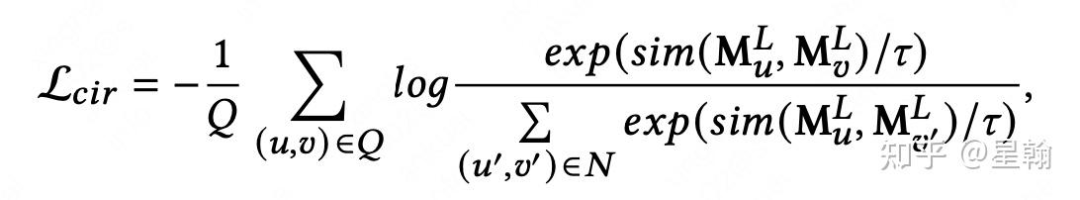
内积计算次数:user侧隐层个数L * 子空间个数M * 子空间个数M
3 MVKE[12]
User侧先产出多个公共兴趣表征,Item侧(下图中的Tag)表征作为query通过attention聚合方式获得每个User的item-related兴趣表征。
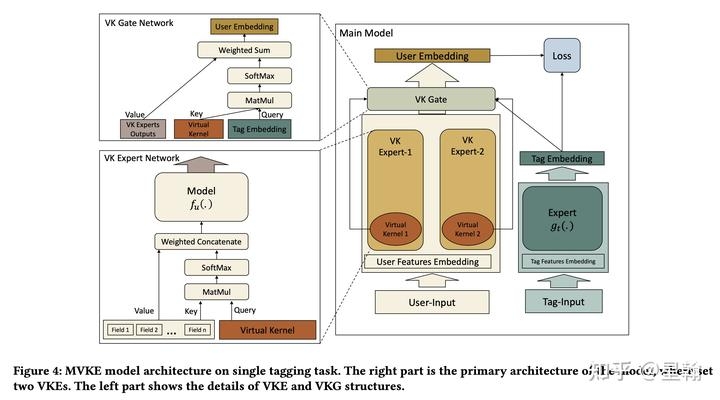
interaction 方式:
VK-Expert 用来表征用户某方面的兴趣,Virual Kernel是对应的可学习参数,它作为query对用户侧所有特征(Field)进行加权聚合(attention aggregation)作为VK-Expert输出。
Item侧表征与用户侧的多个VK-Expert表征进行加权聚合作为用户item-related兴趣表征
用户item-related兴趣表征与item表征内积作为模型预测值
内积计算次数:number of VK Experts + 1
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

参考
^(DSSM) Huang et al. Learning deep structured semantic models for web search using clickthrough data. CIKM. 2013.
^(YoutubeDNN) Covington et al. Deep neural networks for youtube recommendations. Recsys. 2016.
^Grbovic et al. Real-time personalization using embeddings for search ranking at airbnb. KDD. 2018.
^(PFD) Xu C, Li Q, Ge J, et al. Privileged features distillation at Taobao recommendationsKDD. 2020.
^ (ENDX) Wang et al. Enhancing Dual-Encoders with Question and Answer Cross-Embeddings for Answer Retrieval. arXiv, 2022.
^(TRMD) Choi et al. Improving Bi-encoder Document Ranking Models with Two Rankers and Multi-teacher Distillation. SIGIR. 2021.
^(VIRT) Li et al. VIRT: Improving Representation-based Models for Text Matching through Virtual Interaction. arXiv , 2021.
^(Distilled-DualEncoder) Wang et al. Distilled Dual-Encoder Model for Vision-Language Understanding. arXiv, 2021.
^(ERNIE-Search) Lu et al. ERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation for Dense Passage Retrieval. arXiv, 2022.
^(ColBert) Khattab et al. Colbert: Efficient and effective passage search via contextualized late interaction over bert.SIGIR.2020.
^ IntTower: the Next Generation of Two-Tower Model for Pre-Ranking System
^(MVKE) Xu et al. Mixture of virtual-kernel experts for multi-objective user profile modeling. KDD. 2022.



