
热门标签
热门文章
- 1滚动轴承变转速故障数据集:6种故障状态和正常状态的振动信号,详细记录了加速减速过程中的故障特征_轴承振动信号测试与故障分析实验数据
- 2“打造智能售货机系统,基于ruoyi微服务版本开源项目“_自动售卖机 开源项目
- 32024 年第十四届 APMCM 亚太地区大学生数学建模A题 飞行器外形的优化问题--完整思路代码分享(仅供学习)_2024 年第十四届 apmcm 亚太地区大学生数学建模竞赛a题
- 4bn层学习笔记 卷积层和BN层融合
- 5四款高性价比海外服务器推荐,亚马逊云科技的优势有哪些_性价比高的海外服务器
- 6记录Hbase出现HMaster一直初始化,日志打印hbase:meta,,1.1588230740 is NOT online问题的解决_master.hmaster: hbase:meta,,1.1588230740 is not on
- 7SparkSQL | 表生成函数_python sparksql lateral view explode split
- 8Docker--在linux安装软件
- 9互联网架构【服务化】
- 10【Sql】安装sql server 提示Polybase要求安装Oracle JRE 7更新51(64位)或更高版本_polybase要求安装oracle jre7更新51
当前位置: article > 正文
深度学习(28)——YOLO系列(7)_model.fuse()
作者:爱喝兽奶帝天荒 | 2024-07-10 16:05:41
赞
踩
model.fuse()
深度学习(28)——YOLO系列(7)
咱就是说,需要源码请造访:Jane的GitHub:在这里
上午没写完的,下午继续,是一个小尾巴。其实上午把训练的关键部分和数据的关键部分都写完了,现在就是写一下推理部分
在推理过程为了提高效率,速度更快:
detect 全过程
1.1 attempt_load(weights)
- weights是加载的yolov7之前训练好的权重
- 刚开始load以后还有BN,没有合并的
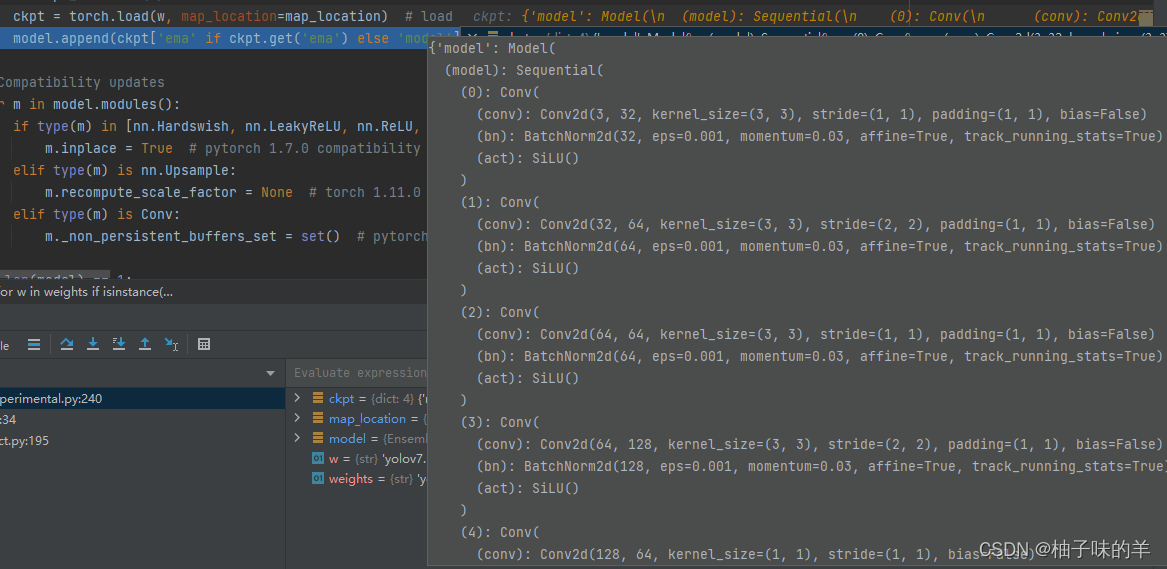
- 关键在下面的fuse()
1.2 model.fuse()

# 很隐蔽,刚开始我没想到接口是在这里的 def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers print('Fusing layers... ') for m in self.model.modules(): if isinstance(m, RepConv): #print(f" fuse_repvgg_block") m.fuse_repvgg_block() elif isinstance(m, RepConv_OREPA): #print(f" switch_to_deploy") m.switch_to_deploy() elif type(m) is Conv and hasattr(m, 'bn'): m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv delattr(m, 'bn') # remove batchnorm m.forward = m.fuseforward # update forward elif isinstance(m, (IDetect, IAuxDetect)): m.fuse() m.forward = m.fuseforward self.info() return self

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
当遇到conv后面一定是有BN的,所以

1.3 fuse_conv_and_bn(conv,bn)
- 先定义一个新的conv【和原来传入的是一样的inputsize,outputsize和kernel】
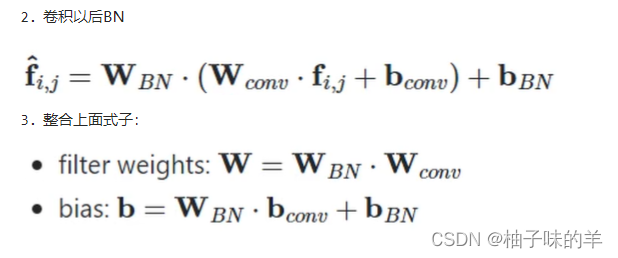
- 先得到w_conv:
w_conv = conv.weight.clone().view(conv.out_channels, -1) - 得到w_bn:
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))【bn.weight 就是以下公式中的gamma,sigma平方是方差bn.running_var】
- 得到w_fuse:
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape)) - 得到b_conv,因为在学习过程中bias我们都设置为0,所以:
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias - 得到b_bn :
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))【bn.bias是上面公式中的β,μ为均值bn.running_mean】 - 计算b_fuse
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
def fuse_conv_and_bn(conv, bn): # Fuse convolution and batchnorm layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/ fusedconv = nn.Conv2d(conv.in_channels, conv.out_channels, kernel_size=conv.kernel_size, stride=conv.stride, padding=conv.padding, groups=conv.groups, bias=True).requires_grad_(False).to(conv.weight.device) # prepare filters bn.weight 对应论文中的gamma bn.bias对应论文中的beta bn.running_mean则是对于当前batch size的数据所统计出来的平均值 bn.running_var是对于当前batch size的数据所统计出来的方差 w_conv = conv.weight.clone().view(conv.out_channels, -1) w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var))) fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape)) # prepare spatial bias b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps)) fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn) return fusedconv
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
1.4 Repvgg_block
把Repvgg中的卷积和BN合在一起
- 原来的block↓
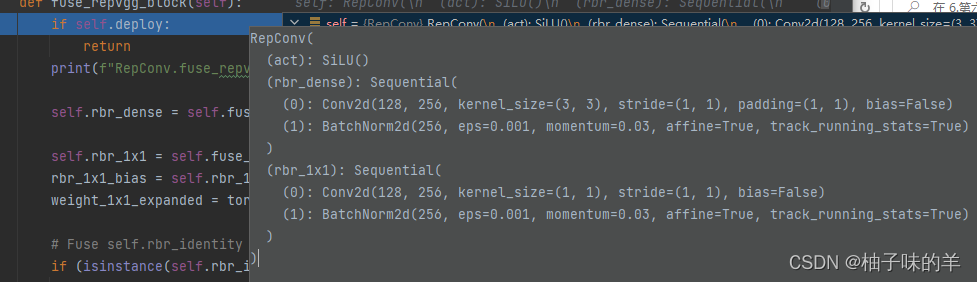
- 融合rbr_dense后:

- 融合rbr_1*1后:

1.5 将1* 1卷积padding成3* 3

padding后

所有的都改变以后:model长这样——>
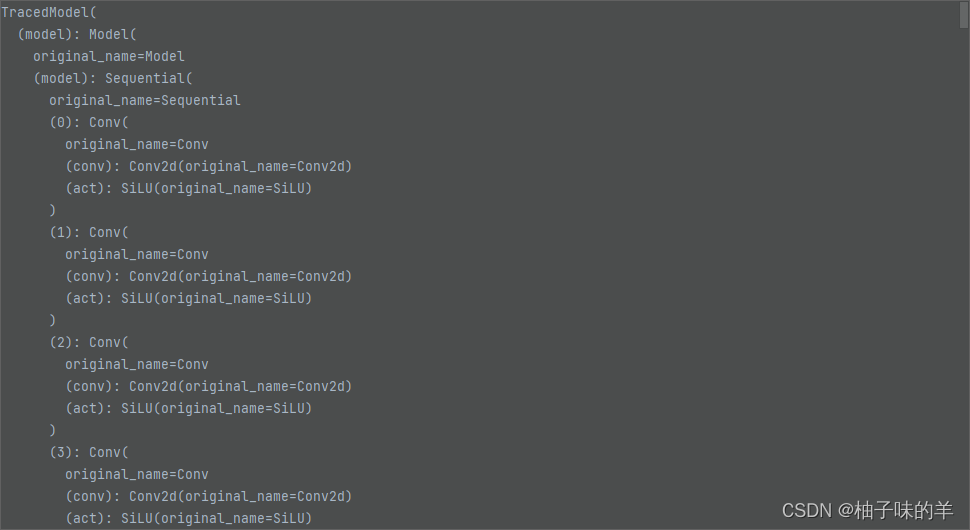

OK,这次真没啦,886~~~~
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/爱喝兽奶帝天荒/article/detail/806832
推荐阅读
相关标签

