
- 1【Docker】初学者 Docker 基础操作指南:从拉取镜像到运行、停止、删除容器_docker停止一个镜像的拉取
- 2NodeManager启动流程与服务
- 3Memcached开发(八):使用PHP进行操作
- 4Websocket携带参数或者携带自定义头的解决方案_websocket能添加请求头吗
- 5xshell的完美替代品:FinalShell及其操作介绍_finalshell默认字体是什么
- 6android 动态更换应用图标(一)_view.changeicon
- 7NoSQL数据库进阶实战 2,NoSQL数据存储模式_列族数据库
- 8大数据集群:hadoop3.3.6,spark,hbase,zookeeper_hbase-2.5.8-hadoop3-bin
- 9mac数字键盘错乱_苹果本键盘按键错位错乱是为什么?
- 10Andrej Karpathy | 详解神经网络和反向传播(基于micrograd)
达梦(DM) SQL数据及字符串操作_达梦字符串替换
赞
踩
这里继续讲解DM数据库的操作,主要涉及插入、更新、删除操作。
数据操作
插入数据,不指定具体列的话就需要插入除自增列外的其他列,当然自增列也可以直接指定插入
INSERT INTO SYS_USER VALUES(110,'test002','test002','00',null,'13522266688',0,null,'dfhgjhsfjg','12323',0,0,null,null,'test002','2023-10-23 10:11:11',null,null,null);
- 1
执行成功后查看数据

插入多行,比如创建测试表
CREATE TABLE test AS SELECT user_id, user_name, login_name, phonenumber, dept_id FROM sys_user WHERE 1 = 2;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
创建成功后查询可以看到表创建成功,带WHERE 1 = 2条件的话,实测是只创建指定字段表结构,不带WHERE条件的话会携带对应字段的数据
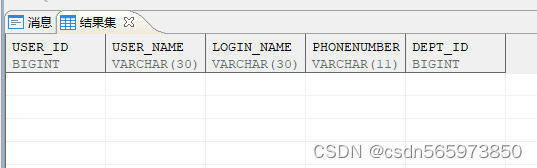
CREATE TABLE test1
AS
SELECT user_id,
user_name,
login_name,
phonenumber,
dept_id
FROM sys_user;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
执行结果
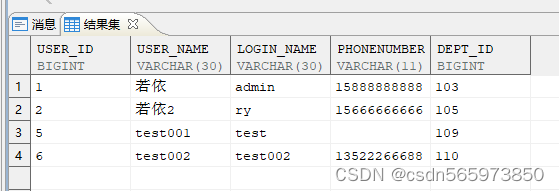
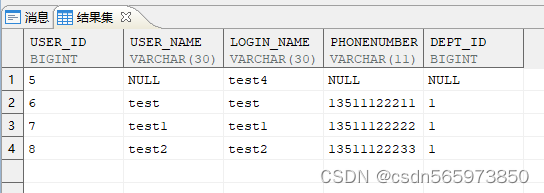
批量插入test表数据
insert into test VALUES (1,'test','test','13511122211',1),(2,'test1','test1','13511122222',1),(3,'test2','test2','13511122233',1);
- 1
执行成功后
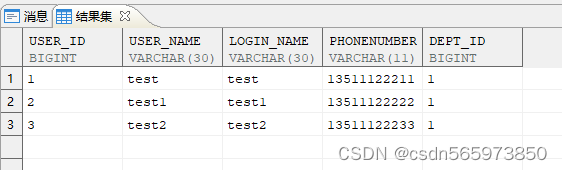
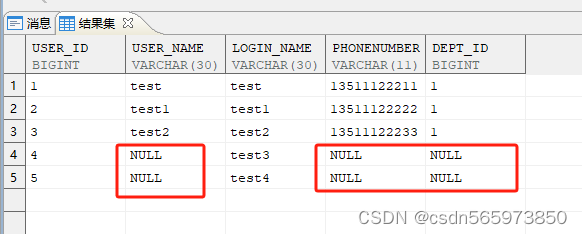
可以按指定列插入行,未指定值的列上若定义了默认值,则插入默认值。没有指定默认值,为 NULL,则插入 NULL 值
insert into test (user_id,login_name) VALUES (4,'test3'),(5,'test4');
- 1
执行结果如图
如需快速复制表结构且不需要数据,如需表机构和数据的话 WHERE 1 = 1; 或者不要WHERE条件
CREATE TABLE test2 AS SELECT * FROM test WHERE 1 = 0;
- 1
查询表数据库看到
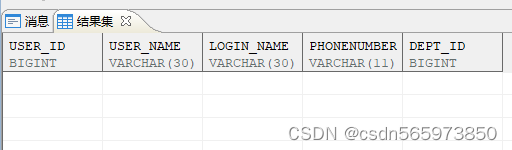
使用 SP_TABLEDEF 过程查看 test2 的结构,所有定义在 test 列上的约束均没有被新表继承。
为表语句添加约束条件
ALTER TABLE test ADD PRIMARY KEY (user_id);
ALTER TABLE test ALTER COLUMN user_name SET DEFAULT 'dm2020';
ALTER TABLE test ALTER COLUMN login_name SET NOT NULL;
ALTER TABLE test ALTER COLUMN phonenumber SET DEFAULT '13511122255';
- 1
- 2
- 3
- 4
使用 MERGE INTO 语法可合并 UPDATE 和 INSERT 语句,使用 MERGE 可以实现记录“存在则 update,不存在则 insert”的逻辑。
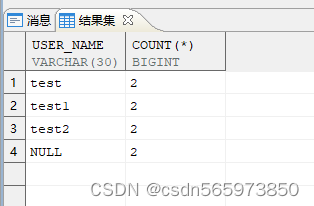
通过 group by + having 子句分组查询的方式,查找员工名称相同的记录
select user_name,count(*) FROM TEST group by USER_NAME HAVING count(*)>1;
- 1
查询结果如图
查询重复数据,通过 group by + rowid 的方式,查找员工名称重复的记录
select * from test where ROWID not in (select max(ROWID) from test group by user_name);
- 1
查找到重复记录后直接删除
delete from test where ROWID not in (select max(ROWID) from test group by user_name);
- 1
执行完再查询发现重复的1 2 3 4 已经删除了
字符串操作
使用函数 regexp_count、regexp_replace 或 translate 统计字符串个数
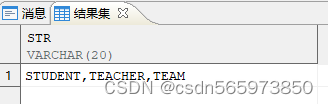
创建视图
CREATE OR REPLACE VIEW v AS SELECT 'STUDENT,TEACHER,TEAM' AS str FROM DUAL;
select * from V;
- 1
- 2
看到创建成功的视图
使用函数 regexp_count 统计子串个数
SELECT regexp_count(str,',')+1 as cnt FROM v;
- 1
执行结果如图
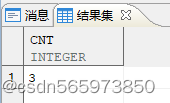
使用 regexp_replace 迂回求值统计子串个数
SELECT length(regexp_replace(str,'[^,]'))+1 as cnt FROM v;
- 1
使用 translate 统计子串个数
SELECT length(translate(str,',' || str,','))+1 AS cnt FROM v;
- 1
使用 translate 或者 regexp_replace 在某个字段中去掉不需要的字符,先创建视图
CREATE OR REPLACE VIEW v
AS
SELECT 'CLARK' ename FROM DUAL
UNION ALL
SELECT 'MILLER' FROM DUAL
UNION ALL
SELECT 'KING' FROM DUAL;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
创建成功如图
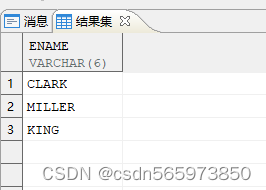
去掉ename中的元音字母
SELECT ename,translate(ename,'1AEIOU','1') stripped1 FROM v;
- 1
可以看到元音字母已经去掉了
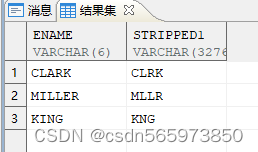
使用正则函数 regexp_replace [] 内列举的字符替换为空
SELECT ename,regexp_replace(ename,'[AEIOU]') AS stripped FROM v;
- 1
使用 regexp_replace 正则表达式实现字符串中字符与数字分离,创建测试视图
CREATE OR REPLACE VIEW v
AS
SELECT 'CLARK10' data FROM DUAL
UNION ALL
SELECT 'MILLER20' FROM DUAL
UNION ALL
SELECT 'KING30' FROM DUAL;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
查询结果如图
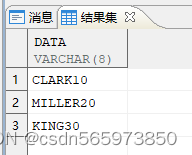
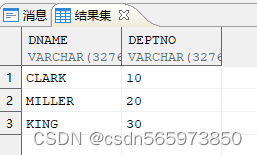
使用 regexp_replace 正则表达式
SELECT REGEXP_REPLACE (data, '[0-9]', '') dname,
REGEXP_REPLACE (data, '[^0-9]', '') deptno
FROM v;
- 1
- 2
- 3
- 4
- 5
执行结果如图
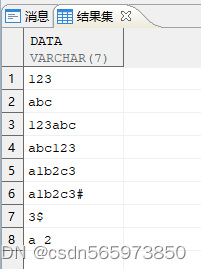
使用 regexp_like 实现查询只包含字母或者数字型的数据,创建测试视图
CREATE OR REPLACE VIEW v AS SELECT '123' AS data FROM DUAL UNION ALL SELECT 'abc' FROM DUAL UNION ALL SELECT '123abc' FROM DUAL UNION ALL SELECT 'abc123' FROM DUAL UNION ALL SELECT 'a1b2c3' FROM DUAL UNION ALL SELECT 'a1b2c3#' FROM DUAL UNION ALL SELECT '3$' FROM DUAL UNION ALL SELECT 'a 2' FROM DUAL;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
查询执行结果如图
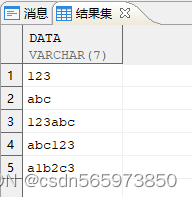
在上面的语句中,有些数据包含了空格、逗号、$ 等字符。现在要求只返回其中只有字母及数字的行,使用 regexp_like 语句
SELECT data FROM v WHERE REGEXP_LIKE (data, '^[0-9a-zA-Z]+$');
- 1
查询结果如图
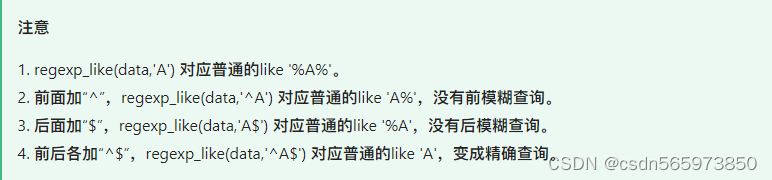
注意下方内容
通过正则表达式或者 translate 函数实现按字符串中的数值排序,创建视图
CREATE OR REPLACE VIEW v AS SELECT 'ACCOUNTING 10 NEW YORK' data FROM DUAL UNION ALL SELECT 'OPEARTINGS 40 BOSTON' FROM DUAL UNION ALL SELECT 'RESEARCH 20 DALLAS' FROM DUAL UNION ALL SELECT 'SALES 30 CHICAGO' FROM DUAL;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
执行后查询结果如图
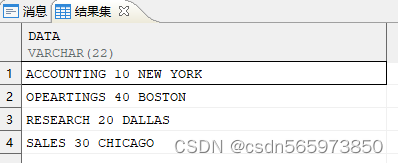
用正则表达式替换非数字字符
SELECT data, TO_NUMBER (REGEXP_REPLACE (data, '[^0-9]', '')) AS deptno FROM V ORDER BY 2;
- 1
执行结果如图
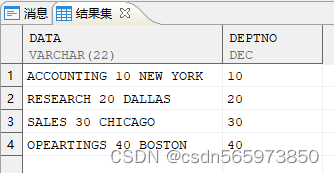
使用 translate 函数,直接替换掉非数字字符
SELECT data,TO_NUMBER (TRANSLATE (data, '0123456789' || data, '0123456789'))AS deptno FROM V ORDER BY 2;
- 1
通过 listagg 分析函数实现多行字段的合并显示,创建视图
CREATE OR REPLACE VIEW v AS SELECT '10' deptno, 'CLARK' name, '800' sal FROM DUAL UNION ALL SELECT '10', 'KING', '900' FROM DUAL UNION ALL SELECT '20', 'JAMES', '1000' FROM DUAL UNION ALL SELECT '20', 'KATE', '2000' FROM DUAL UNION ALL SELECT '30', 'JONES', '1150' FROM DUAL;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
执行结果如图
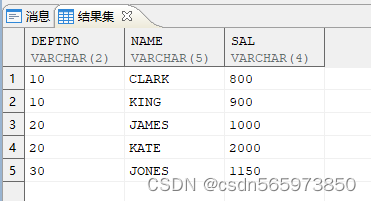
使用 listagg 分析函数实现合并显示
SELECT deptno,SUM (sal) AS total_sal,LISTAGG (name, ',') WITHIN GROUP (ORDER BY name) AS total_name FROM v GROUP BY deptno;
- 1
执行结果如图
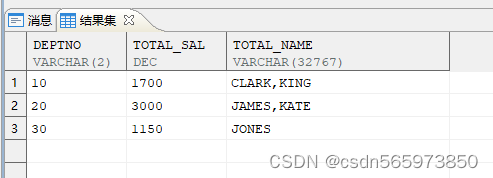
同 sum 一样,listagg 函数也起到汇总结果作用。sum 将数值结果累计求和,而 listagg 是把字符串的结果连在一起。
通过 regexp_substr 实现第 n 个子串的分割,创建测试视图
CREATE OR REPLACE VIEW v AS SELECT 'CLARK,KATE,JAMES''CLARK,KATE,JAMES' AS name;
- 1
执行结果如图
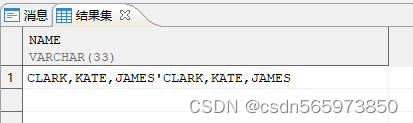
使用 regexp_substr 分割子串
SELECT REGEXP_SUBSTR (v.name,'[^,]+',1,2) AS 子串 FROM v;
- 1
执行结果如图
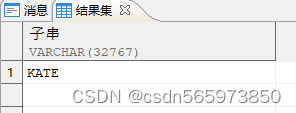
说明:
参数 1:“^”在方括号里表示否的意思,+ 表示匹配 1 次以上。第二个参数表示匹配不包含逗号的多个字符。
参数 2:“1”表示从第一个字符开始。
参数 3:“2”表示第二个能匹配目标的字符串,也就是 KATE。
使用 regexp_substr 实现字符串拆分。比如将 IP 地址“192.168.1.111”中的各段取出来
SELECT REGEXP_SUBSTR (v.ip,'[^.]+',1,1)a,
REGEXP_SUBSTR (v.ip,'[^.]+',1,2)b,
REGEXP_SUBSTR (v.ip,'[^.]+',1,3)c,
REGEXP_SUBSTR (v.ip,'[^.]+',1,4)d
FROM (SELECT '192.168.1.111' AS ip FROM DUAL) v;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
执行结果如图
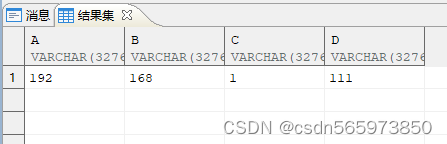
到这里数据新增,修改,删除的操作以及字符串的相关操作就介绍完了。

