
- 1《软件测试52讲》读书笔记 —— 你真的懂测试覆盖率吗?
- 2linux ubuntu 安装搜狗输入法后无法输入中文_搜狗输入法linux版本,输入时只出现英文
- 3使用QEMU搭建U-Boot+LinuxKernel+busybox+NFS嵌入式开发环境_qemu uboot 网络
- 4图像哈希:全局+局部提取特征_全局特征提取
- 5苹果电脑玩Windows游戏怎么实现 mac想玩windows游戏怎么办 parallels desktop激活密钥 虚拟机玩游戏_mac玩windows游戏
- 6Linux搜狗输入法不能打中文_搜狗输入法linux版无法输入中文
- 7display变量 Linux,linux DISPLAY变量
- 8使用LangChain构建问答聊天机器人案例实战(一)_langchain的实战案例
- 9谁是你项目服务开发最佳的web框架选择:Django or Flask or FastAPI?_fastapi和django
- 10Unity Shader丢失问题_unity shader 丢失
谷歌AI大模型一瞥:开源闭源齐头并进,多种模态精彩纷呈_google有哪些大模型
赞
踩
Google I/O 是 Google 最盛大的开发者大会,展示谷歌的最新产品和创新成果, 帮助开发者们了解和使用谷歌的技术。
谷歌在2024年5月15日召开的 Google I/O 大会上公布了旗下最新版的系列模型。今天我们梳理一下谷歌都有哪些生成式AI大模型,其市场定位以及主要能力。
1. Gemini系列模型
Gemini是由Google AI开发的多模态大模型,它代表了Google在人工智能领域的最先进技术。它可以处理多种类型的输入,包括文本、图像、音频和视频。
我们先来了解一下Gemini名字的由来。这个项目最初准备使用“Titan泰坦”这个名字,在早期的文章中,我们曾经介绍过希腊神话中的重要事件 —— 泰坦之战,大家有兴趣可以去阅读。Titan也是土星最大卫星的名字。泰坦神最终的命运是败于宙斯领导希腊新一代神邸,也许是因为这个原因,项目的联合技术负责人杰夫·迪恩并不喜欢这个名字。不过这也给了他一个太空主题的灵感。
“Gemini”在拉丁语中意为“双胞胎”。它是以希腊神话中的双子座兄弟卡斯托(Castor)和波鲁克斯(Pollux)命名的星座,这两颗恒星也是该星座中最亮的星。
在人工智能领域,谷歌的DeepMind和Brain团队正如两颗闪耀的恒星。2023年4月,这两个团队合并为新的谷歌DeepMind,集中了双方在AI领域的优势。因此,“Gemini”名称非常契合新团队的合作愿景,即共同推进人工智能的发展。
名字的灵感还来源于美国宇航局的“双子星计划”,该计划作为水星计划与阿波罗计划之间的桥梁,成功实现了多项里程碑成就,包括美国首次太空行走和两个航天器的历史性对接。

Google没有公布Gemini模型的参数规模,但是据估计超过万亿参数,是迄今为止最大的模型之一。
传统的多模态模型训练方法通常采用分而治之的策略,即各个模态(如文本、图像、声音等)的模型分别训练。每个模型专注于其对应的数据形式,随后通过特定的技术将这些独立训练得到的模型及其输出进行整合,以实现多模态输入。
这种方法的优势在于可以针对不同模态进行专业化的优化,但不足之处在于模态间的整合通常较为简单,在处理需要跨模态理解与推理的复杂任务时往往差强人意。例如,模型能够识别图像中的对象,但在进行更深层次的推理分析时则可能力不从心。
与传统方法迥异,Gemini模型自设计之初就能同时处理多种模态数据,即采用的是原生多模态学习框架。在模型的预训练阶段,它就已经开始同时处理文本、图像、声音等多种类型的数据,从而在模型内部构建起不同模态之间的联系和相互理解。
预训练完成后,Gemini模型通过进一步的多模态微调,增强了其处理复合输入的能力。融合多模态数据的训练,使Gemini能够更好地理解多模态输入,尤其是在复杂和抽象推理的任务上。
Gemini系列包括几个不同的模型,每个模型针对特定用途:
-
Gemini Ultra (双子星至尊版) ——功能最强大、适用于高度复杂任务的超大型模型。
-
Gemini Pro (双子星专业版) —— 适用于处理各种类型任务的最佳模型。
-
Gemini Flash (双子星闪速版) —— 轻量级模型,它兼具速度、效率、高性价比。
-
Gemini Nano (双子星迷你版) —— 最高效的模型,适用于设备端任务。
Gemini 1.0 Ultra
Google 2023年12月推出了Gemini 1.0系列模型,其中Gemini 1.0 Ultra是最大的模型。
Gemini Ultra的主要特点和能力如下:
- 多模态推理 (Multimodal reasoning): Gemini 能够跨越音频、图像和文本等不同形式的序列,进行原生理解和推理。它可以同时处理多种信息来源,并从中提取关键要素,进行综合性的分析和判断。
- 复杂编码 (Complex coding): Gemini 在编码方面表现卓越,与 AlphaCode 2 集成使用,能够达到最先进的水平。AlphaCode 2 是一款基于 Gemini 模型的自动编程系统,在竞技编程比赛中超越 85% 的人类选手。
- 数学推理 (Mathematical reasoning): Gemini 拥有强大的分析能力,能够出色地解决竞赛级别的数学问题集。
关于Gemini的复杂推理能力,我们可以看两个示例。
先看一个Gemini帮助科学家搜索和使用科学文献的例子。一位遗传学研究者需要审查数万篇论文才能找到数百篇相关的论文,然后手动提取数据并整理成表格。
Gemini如何提供帮助研究者提高效率呢?首先,Gemini可以筛选科学论文的相关性,区分相关和不相关的论文。对于相关的论文,Gemini可以提取关键数据,并添加注释,标记信息在论文中的确切位置。
此外,Gemini还可以辅导数学和物理的学习。用户上传一张带有答案的手写物理练习表的照片,Gemini可以识别答案中的错误,并解释需要澄清的概念,使学习过程更加高效和个性化。
Gemini 1.5 Pro
Gemini 1.5 Pro 于 2024 年 2 月发布,与庞然大物Ultra相比,它是一个中型规模的模型,采用了Mixture-of-Experts (MoE) 架构。
传统的Transformer模型是一个统一的大规模神经网络。与之相对,MoE(专家模型)包含多个小型的“专家”神经网络。
在传统模型中,不同类型的输入都需通过这一个大网络处理,类似于所有患者都需由同一个全科医生诊治。而MoE模型能根据输入的具体情况,激活最相关的专家网络,类似于患者根据病情被分配到相应的专科医生,这大幅提高了处理效率和精准度。在综合医院中,根据患者病情的不同,会指派给心脏病、神经科或肿瘤科等相关领域的专家,MoE模型正是采用了这种高效的“专家分配”机制。
模型的上下文窗口越大,其一次性处理和理解的信息量也越多。模型在生成回答时也就能够考虑更多的前后文信息,提高输出的相关性和一致性。更大的上下文窗口还有助于模型更好地理解复杂问题,提高回答的准确性和实用性。例如,在处理长篇文本或连续对话时,较大的上下文窗口可以使模型能更全面地理解用户的意图和需求,从而提供更加贴切和连贯的回答。
Gemini 1.5 Pro 的最大上下文窗口为100万个token,这是目前基础模型中的最大值,在Google I/O大会上,Google宣布近期将将支持至200万token。
这个窗口一次性处理的信息量大约等同于1小时的视频、11小时的音频、超过3万行的代码或超过70万字的文本。Google内部已成功测试了1000万token的数据处理。
例如,在分析NASA阿波罗11号任务的402页记录时,Gemini 1.5 Pro能够识别出关键和细微的信息,为科学研究提供深入的分析。
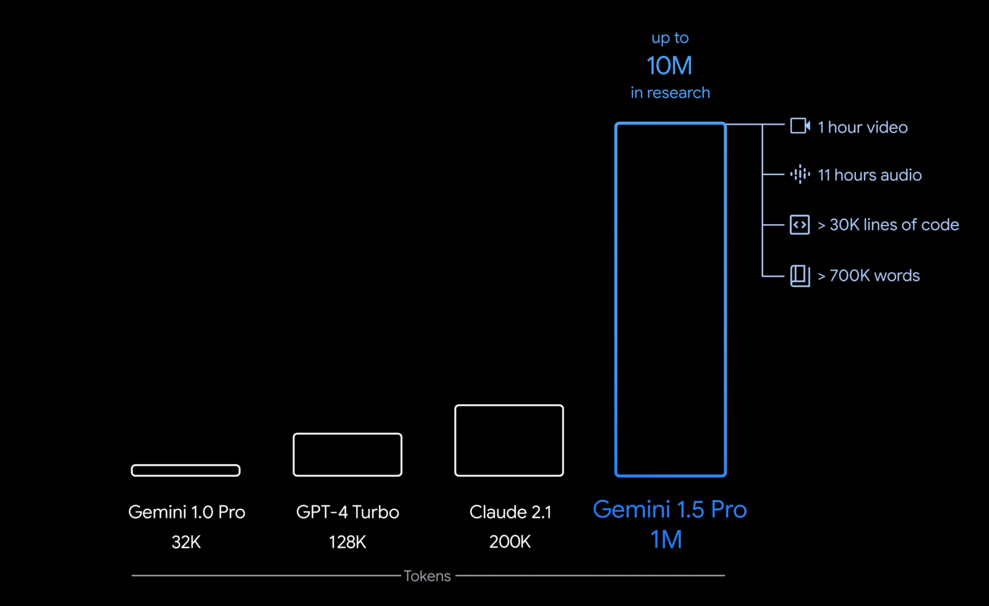
在综合评估测试中,Gemini 1.5 Pro 在 87% 的文本、代码、图像、音频和视频基准测试中 超越 了 Gemini 1.0 Pro。
与 Gemini 1.0 Ultra 相比,Gemini 1.5 Pro 的 整体性能大致相当。
因此尽管 Gemini 1.5 Pro 属于中型模型,但在性能表现上丝毫不逊色于高端的 Gemini 1.0 Ultra。
Gemini 1.5 Flash
在2024年5月I/O大会上,Google宣布了Gemini Flash 1.5模型。Gemini Flash 是一款基于 Gemini 技术的轻量级多模态模型。它兼具速度、效率、高性价比和强大的多模态推理能力,能够处理长达百万token的上下文信息,适用于需要快速处理海量数据的各种场景。
主要特点
- 轻巧、快速、高性价比:Gemini Flash 采用了先进的模型压缩技术,模型体积小,运行速度快,且成本低廉,是预算有限用户的理想选择。
- 突破性的百万级超长上下文窗口:Gemini Flash 拥有突破性的百万级超长上下文窗口,能够理解更长、更复杂的输入,例如一小时的视频、11 小时的音频、超过 30,000 行代码的代码库或超过 700,000 个单词的文本。能够更好地理解上下文语义,并执行更复杂的任务。
- 出色的多模态推理能力:Gemini Flash 能够理解和推理跨越文本、图像、音频和视频等多种模态的数据,使其能够用于各种多模态任务,例如图像描述、视频问答、跨模态检索等。
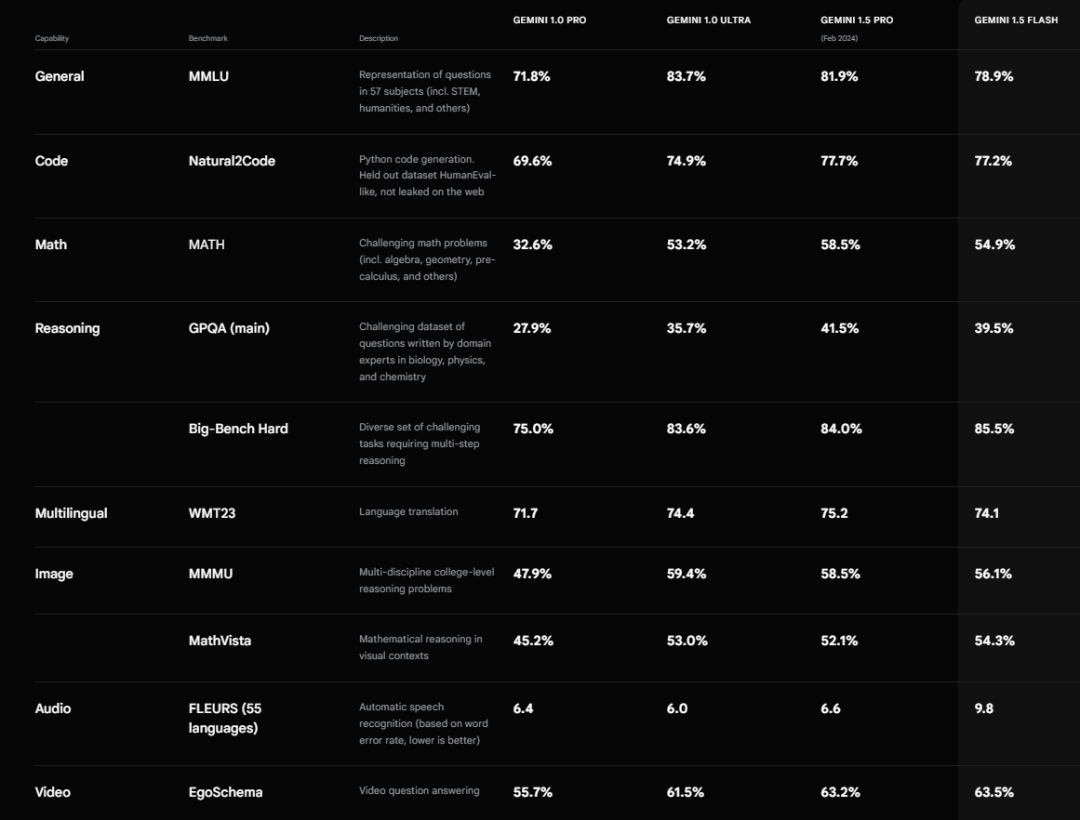
下面是几种Gemini模型的基准测试性能比较。基准测试是用于评估模型能力的数据集或评估方法。一般来说,更高的分数表示在特定任务上具有更好的性能。
基准测试包括:
- MMLU: 一个包含57个科目的问题表示数据集,包括STEM、人文科学等。
- Natural2Code: 一个Python代码生成基准测试,使用非公开数据集。
- MATH: 一个包含具有挑战性的数学问题数据集,包括代数、几何、微积分等。
- GPQA (main): 一个包含由生物学、物理学和化学领域的专家撰写的具有挑战性的问题数据集。
- Big-Bench Hard: 一个包含需要多步骤推理的各种具有挑战性的任务数据集。
- WMT23: 一个机器翻译基准测试。
- MMMU: 一个包含多学科大学水平推理问题数据集。
- MathVista: 一个包含视觉环境中数学推理问题数据集。
- FLEURS (55 languages): 一个自动语音识别基准测试,使用词错误率衡量性能(较低表示更好)。
- EgoSchema: 一个视频问答基准测试。
总体而言,Gemini 1.5 Pro在多项基准测试中表现最佳,在多模态推理、复杂编码和数学推理方面取得了显著进步。
Gemini Nano 1.0
Gemini Nano 是专为设备端任务而设计的人工智能模型。Nano 拥有小巧的模型体积,同时无需网络连接,可以直接在设备上提供快速响应,满足即时需求。
Nano模型将来在终端侧提供的能力如:
- 图像理解: 强大的图像理解能力,可以识别图像内容并生成描述。
- 语音转文本: 识别语音,实现语音输入。
- 文本摘要: 将冗长的信息浓缩为简洁易读的摘要,快速获取关键信息。
下面是Google示例的一些具体应用:
- Pixel 录音机: Pixel 录音机利用 Nano 和 AICore 功能,可以直接在设备上生成录音摘要。
- Gboard 智能回复: 得益于 Nano 和 AICore 的支持,Gboard 可以在设备上提供精准的智能回复功能。
- TalkBack 无障碍功能: 从今年晚些时候开始,TalkBack 无障碍功能将利用 Nano 的多模态能力,为安卓手机用户提供清晰的图像描述。
TalkBack 是安卓系统中的一项辅助功能,旨在帮助视障人士使用手机。它可以通过语音提示和触觉反馈来描述屏幕上的内容,允许用户通过手势或语音指令进行操作。
Nano 2024年底将率先用于 Pixel 手机和安卓操作系统。
总的来说,Gemini是谷歌开发的最先进的多模态大模型,具备先进的理解和推理能力,能够处理复杂的书面、视觉和音频信息。Gemini共有四种模型,分别针对不同的应用场景:
- Ultra:用于处理复杂且高计算需求的任务。
- Pro:适用于大多数商业应用,提供高效和可靠的性能。
- Flash:优化了速度,适合需要快速响应的场景。
- Nano:轻量级模型,适用于资源受限的环境,如移动设备。
2. Gemma 系列开源模型
2024年2月Google 宣布推出开源文本模型Gemma。其实,Google在AI领域早就有不少开源的典范,例如Transformers、TensorFlow、BERT、T5、JAX、AlphaFold和AlphaCode。
- Transformers:作为自然语言处理领域的革命性技术,Transformers推动了整个行业的前进,是多种现代NLP系统和大语言模型的核心。
- TensorFlow:是一种广泛使用的机器学习框架,用于部署复杂的机器学习模型,广泛用于商业和研究领域。
- BERT(Bidirectional Encoder Representations from Transformers):作为一种预训练模型,BERT极大提升了机器对语言的理解能力,被广泛应用于搜索引擎、语言翻译等领域。
- T5:将各种NLP任务统一为文本到文本的格式,增强了模型的泛化能力,广泛用于自然语言理解和生成任务。
- JAX:是一个高性能的数值计算库,用于高效地执行机器学习算法,特别支持自动微分和GPU/TPU加速。在科学研究和AI应用开发中扮演重要角色,特别是在需要大规模并行计算的任务中。
- AlphaFold:是一个使用深度学习预测蛋白质结构的模型,它在生物医学研究领域中具有革命性的意义。通过预测蛋白质结构,可以帮助科学家更快地理解疾病和开发新药。
- AlphaCode:是一个编程竞赛中用于自动生成代码的AI模型,能够理解复杂的编程问题并生成相应的代码解决方案。
好,我们回到开源模型Gemma。Gemma 是一个系列轻量级的开源模型,与 Gemini 师出同门,使用了相同的技术。其名字“gemma”来自拉丁语,意为“珍贵宝石”。
Gemma 在推出时包括两个版本:Gemma 2B 和 Gemma 7B。 两种规模的模型都包含预训练版本和指令微调版本,满足不同的应用需求。
Gemma 模型设计精巧,适合在笔记本电脑或工作站上运行。其开源许可协议允许各种组织将其用于商业用途。
在Google I/O 大会上,Google宣布了下一代开源模型 Gemma 2。
下一代开源文本模型 Gemma 2
Gemma 2 采用了全新架构设计,实现了性能和效率的显著提升。除了之前发布的两个小规模版本 Gemma 2B 和 Gemma 7B,Gemma 2 现在还推出了 27B 参数的大型模型,其性能可与 70B 参数的 Llama 3 相媲美,但模型大小却不到后者的一半。
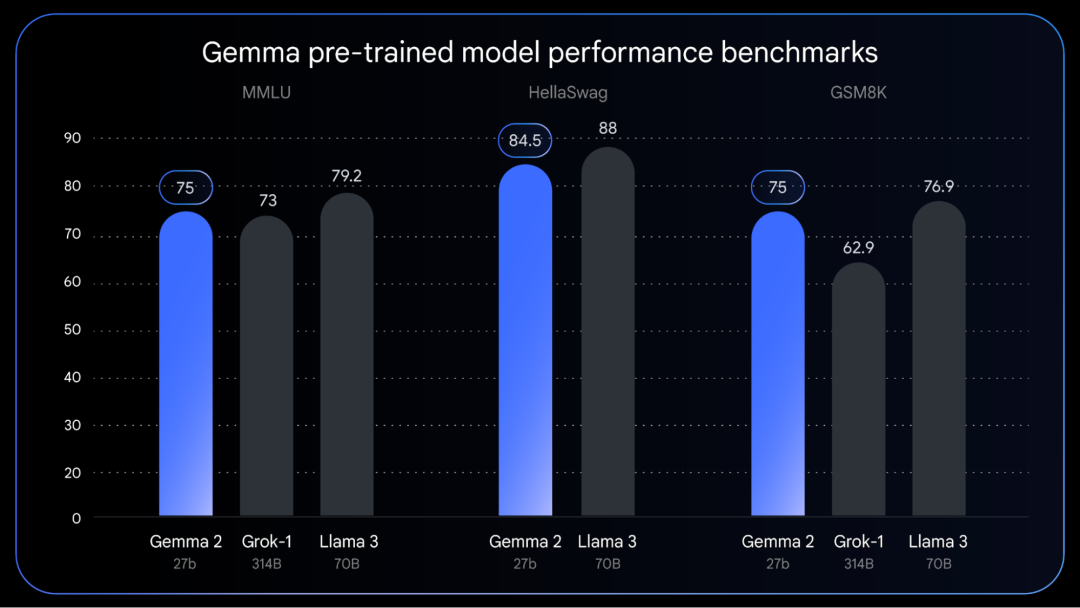
Gemma 2 模型仍处于预训练阶段。此图表显示了最新 Gemma 2 检查点以及基准预训练指标的性能。来源:Hugging Face 开放大型语言模型排行榜(2024 年 4 月 22 日)和 Grok 发布博客
PaliGemma:开源视觉 - 语言模型
PaliGemma 是Google 开发的创新视觉语言模型 (VLM)。该模型结合了两个先进的开源组件:SigLIP 视觉模型和 Gemma 语言模型,使其在处理视觉与语言结合的任务上表现出色。
基于 SigLIP 视觉模型,PaliGemma 能够深度理解图像内容并提取关键特征,为后续的语言处理奠定基础。依托 Gemma 语言模型,PaliGemma 在文本生成、理解和推理方面表现出色,能够将视觉信息转化为清晰易懂的语言表达。
PaliGemma 可用于图像和短视频的自动标注、视觉问答、图中文本理解、对象检测和对象分割等任务,具有广泛的应用潜力。
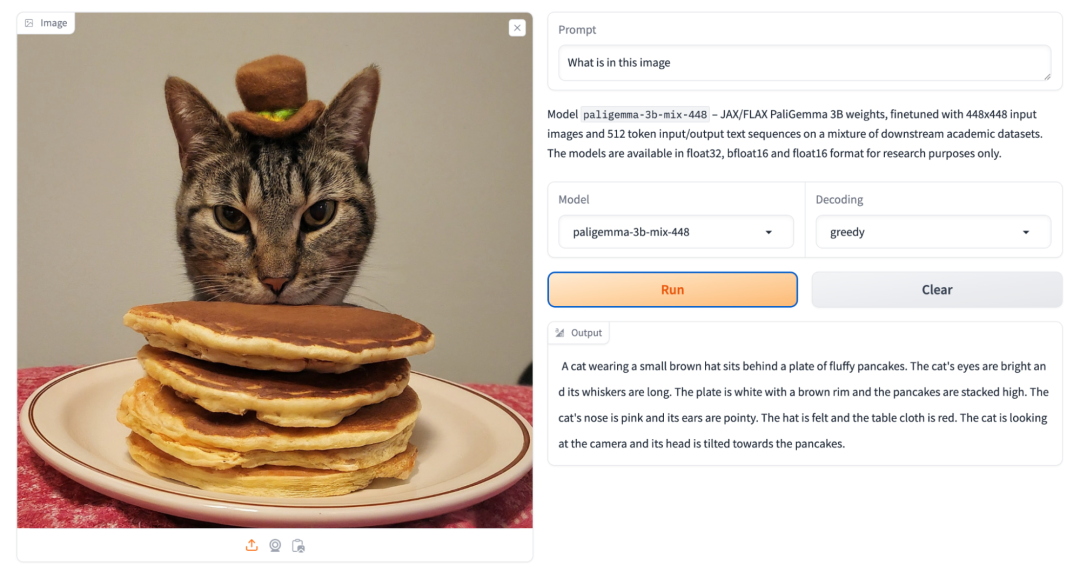
例如,下图中模型根据提示词:“图像中有什么”,提供出详细的图像描述信息。
3. Imagen 3:文生图模型
在2004 Google I/O大会上,Google发布了最新的 Imagen 3 文本转图像模型。
Imagen 3 在理解复杂文本描述方面取得了显著的技术突破,能够生成丰富多样的视觉风格,并能精确捕捉更长描述中的细节。为了提高实用性,Imagen 3 将推出多个版本,每个版本都专门针对不同的视觉任务进行优化,从生成草图到创作高清图像,满足各种创意需求。
创作者可以在 ImageFX 平台上体验 Imagen,并可以申请加入Imagen 3等候名单。ImageFX 是由 Google 开发的文本转图像平台,它基于强大的 Imagen 模型,可以将文字描述转化图像。
以下是Google提供的几个生成示例。
使用“单反相机拍摄,使用偏振滤镜”的描述,生成土耳其卡帕多奇亚上空色彩缤纷的热气球漂浮在奇特岩石地貌之上的照片,热气球的色彩和图案与下方泥土色调的景观形成鲜明对比,展现了乘坐热气球带来的冒险精神。


一台生满苔藓的木制机器人站在野花田中,将手伸向一只停在它手上的蓝色小鸟。背景中瀑布从悬崖上倾泻而下

Imagen 3 作为 Google AI 推出的最新文本转图像模型,采用了严格的过滤和数据标注手段,降低了生成有害图像的可能性。针对公平、偏见和内容安全等方面,Imagen 3 进行了严格的红队测试和评估,确保其输出符合道德标准,避免歧视性或偏见性的结果。
Imagen 3 采用了水印工具 SynthID。SynthID 可以将数字水印直接嵌入图像的像素中,但肉眼不可见,以有效保护用户隐私和版权安全。
未来几个月内,Imagen 3 将引入 Imagen 2 受欢迎的编辑功能,例如内容填充和外延填充,为用户提供更加丰富的创作工具。此外,Imagen 3 的应用范围也将逐步扩展到更多 Google 产品,例如 Gemini 应用及其网页端、Workspace、广告等等。
4. Veo:文生视频模型
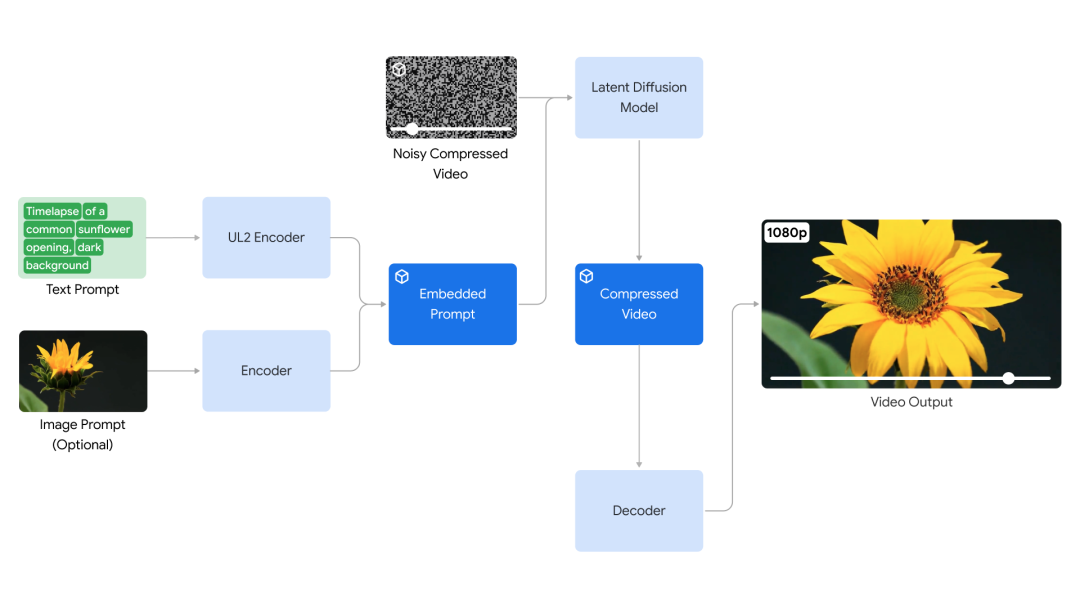
在2024年5月 Google I/O大会上,Google发布了最新的 Veo 文本转视频模型。
Veo能够以多种风格制作高质量的1080p视频。这款模型拥有强大的理解电影概念的能力,例如“延时摄影”和“航拍”,可以忠实地实现电影制作者的创意愿景。
Veo不仅能够准确地捕捉创作者的指令,还能保持视频序列之间的真实性和连贯。Veo的发布,也标志着谷歌与OpenAI在视频生成领域的竞争日趋激烈。 近期,OpenAI推出文本到视频生成器Sora,引起了业界的广泛关注。两家公司都在不断突破技术壁垒,推动视频生成技术的进步。像 Sora 一样,Veo 对物理有一定的理解——比如流体动力学和重力等,这些有助于它生成更具真实感的视频。
为了展示Veo的实力,谷歌与著名电影制作人唐纳德·格洛弗及其创意工作室Gilga联手合作。他们的联合项目展现了Veo在专业电影制作中的潜力,也预示着AI将在未来创意过程中扮演越来越重要的角色。
目前,谷歌已邀请部分创作者参与Veo的体验,并在VideoFX中探索其功能。
Veo 集Google 多年视频生成研究之大成,包括生成式查询网络 (Generative Query Network, GQN)、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet、Lumiere,以及强大的 Transformer 架构和 Gemini 模型。
为了帮助 Veo 更准确地理解和遵循文本描述,Google 在训练数据中每个视频的标题中添加了更多细节信息。此外,为了进一步提升性能,该模型采用了高质量的压缩视频表示(也称为潜在向量),从而提高了效率。这些举措不仅改善了视频生成质量,还缩短了生成时间。
5. AlphaFold 3:分子模型
2024年5月,Google还发布了AlphaFold 3,一款由谷歌 DeepMind 和同态(Isomorphic Lab)实验室联合开发的全新 分子模型,用于预测蛋白质、DNA、RNA、配体等生命分子的结构及其相互作用方式。
这类模型可以帮助科学家更深入地了解细胞系统中的结构、相互作用,揭示生命过程的奥秘。以及帮助科学家设计更有效、更安全的药物,并缩短药物研发周期。其他应用还包括生物可再生材料、农作物育种、基因组学研究等领域。
结语
今天借Google I/O大会之际,我们总结了Google的一系列人工智能模型,如Gemini、Gemma、Imagen、Veo和AlphaFold,相信大家对于Google在大模型领域的布局有了一个清晰的了解。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

