
- 1大模型训练语料质量差文档解析不精准,看CCIG上的专家怎么说
- 2MATLAB中的矩阵的重构和重新排列_重构矩阵
- 3Android 生成so库 然后给别人调用_android 构建so库文件给别人使用
- 4Bad credentials问题解决_[auth] extension activation failed: "bad credentia
- 5brew常见命令 自用 实践笔记_慎用 brew upgrade
- 6数据结构之——堆_堆的数组形式表现
- 7Unity3D 游戏数据本地化存储与管理详解
- 8【探索AI】四:AI(人工智能)自然语言处理(NLP)_人工智能nlp
- 9动态规划在程序算法中的运用
- 10动手学CV-Pytorch计算机视觉 使用transformer实现OCR字符识别_pytorch ocr
西瓜书习题 - 4.决策树_决策树经典例题及答案
赞
踩
1.决策树基本流程
1、下列选项哪个是决策树的预测过程?
- 将测试示例从一个中间节点开始,沿着划分属性所构成的“判定测试序列”下行,直到叶节点
- 将测试示例从一个中间节点开始,沿着划分属性所构成的“判定测试序列”上行,直到根节点
- 将测试示例从叶节点开始,沿着划分属性所构成的“判定测试序列”上行,直到根节点
- 将测试示例从根节点开始,沿着划分属性所构成的“判定测试序列”下行,直到叶节点
2、决策树学习的策略是什么?
- 分而治之
- 集成
- 聚类
- 排序
3、决策树训练时,若当前结点包含的样本全属于同一类别,则____(需要/无需)划分
无需
2.信息增益划分
1、信息熵是度量样本集合 [填空1] 最常用的一种指标
- 纯度
- 对称差
- 大小
- 重要性
2、以下哪个选项是信息增益的定义?
- 划分前的信息熵-划分后的信息熵
- 划分后的信息熵-划分前的信息熵
- 划分前的信息熵/划分后的信息熵
- 划分后的信息熵+划分前的信息熵
本题选A。注意到信息熵是衡量样本纯度的概念,相对于物理中的“无序程度”,信息熵越大则代表样本无序程度大,对应样本纯度低;在决策树进行划分后,我们希望的是样本的纯度变大,对应于信息熵应该为熵减的过程;故我们想要求得的信息增益为前后两者之差,为得到一个正值,我们选取前者减后者。
3、在二分类任务中,若当前样本集合的正类和负类的数量刚好各一半,此时信息熵为____(保留一位小数)
1.0
本题答案为1.0。注意到信息熵的计算公式为Σ-pi log(pi),而我们用比特为单位时取的底数正是2,在这里,我们进行计算,信息熵应为-1/2*(-1)±1/2*(-1)=1,答案要求保留一位小数,故在这里填1.0即可。
3.其他属性划分
1、下列说法错误的是()
- CART算法在候选属性集合中选取使划分后基尼指数最大的属性
- 划分选择的各种准择对泛化性能的影响有限
- 划分选择的各种准择对决策树尺寸有较大影响
- 相比划分准则,剪枝方法和程度对决策树泛化性能的影响更为显著
本题选A。首先注意到基尼指数和信息熵一样,是衡量一个随机变量的纯度的,其定义为Σpi(1-pi),从定义可以看出随机变量越随机,亦即越不纯,基尼指数越大;我们希望的是更快做好分类,当然是要选取划分后基尼指数最小的属性,这样达到的增益是最大的。对于B选项,影响决策树泛化性能的更为直接的因素是减枝。对于C选项,不同的划分方法准则对决策树的深度宽度等影响较小。对于D,D是正确的。
2、增益率的表达式是Gain_ratio(D,a)=()
- Gain(D,a)+IV(a)
- Gain(D,a)-IV(a)
- Gain(D,a)*IV(a)
- Gain(D,a)/IV(a)
3、对西瓜数据集2.0(《机器学习》教材第76页),划分前的信息熵为0.998,若使用编号属性进行划分,则信息增益为____(保留3位小数)
0.998
本题答案为0.998。注意到对编号属性划分后,每个类里只有一个样本,故信息熵为0,故信息增益就是划分前的信息熵,故本题应该填0.998。
4.决策树的剪枝
1、剪枝是决策树学习算法对付什么现象的主要手段?
- 标记噪声
- 数据少
- 过拟合
- 欠拟合
2、提前终止某些分支的生长,这个策略的名称是什么?
- 预剪枝
- 后剪枝
- 不剪枝
- 随机剪枝
3、决策树剪枝的基本策略有“____”和“后剪枝”
预剪枝
5.缺失值的处理
1、决策树算法一般是如何对缺失属性进行处理的?
- 仅使用无缺失的样例
- 对缺失值进行随机填充
- 用其他属性值预测缺失值
- 利用“样本赋权,权重划分”的思想解决
2、决策树处理缺失值的基本思路是“样本赋权,权重划分”,其中“权重划分”指的是以下哪个选项?
- 给定划分属性,若样本在该属性上的值缺失,会按进入权重最大的一个分支
- 给定划分属性,若样本在该属性上的值缺失,会按权重随机进入一个分支
- 给定划分属性,若样本在该属性上的值缺失,会按权重同时进入所有分支
- 给定划分属性,若样本在该属性上的值缺失,会按进入权重最小的一个分支
本题选C。决策树处理划分属性时在划分属性上值缺失的问题,会将该带有缺失值的样本同时划入所有子节点,但此时要调整该样本的权重,为样本权重乘以无缺失样本中属性在对应取值上样本所占的比例。直观来看,其实就是让同一个样本以不同的概率到不同的子节点中去,这也符合我们对决策树的直观感觉。
3、决策树处理有缺失值的样本时,仅通过____(有/无)缺失值的样例来判断划分属性的优劣
无
本题填无。决策树在确定划分属性的优劣时,只采用无缺失值的样例。我们回顾选取划分属性时的准则,在含有属性缺失值时,我们修改后的信息增益公式为无缺失值样本的比例乘以用该属性划分后在无缺失值上带来的信息增益,从这里可以看出对于选取划分属性时和缺失值样本本身并无关系。
6.章节测试
1、决策树划分时,若当前结点包含的样本集合为空,则应该怎么做?
- 将结点标记为叶结点,其类别标记为父结点中样本最多的类
- 将结点标记为叶结点,其类别标记为父结点中样本最少的类
- 将结点标记为叶结点,其类别标记为父结点中任意一个类
- 从其他结点获得样本,继续进行划分
2、决策树划分时,当遇到以下哪种情形时,将结点标记为叶节点,其类别标记为当前样本集中样本数最多的类
- 当前属性集为空,或所有样本在所有属性上取值相同
- 当前属性集不为空,或所有样本在所有属性上取值相同
- 当前结点包含的样本集合为空,或当前属性集为空
- 当前结点包含的样本集合为空,或所有样本在所有属性上取值相同
本题选A。在决策树基本算法中,有三种情形会导致递归返回:(1)当前结点包含的样本全属于同一类别,无需划分; (2)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分; (3)当前结点包含的样本集合为空,不能划分。 在第(2)种情形下,我们把当前结点标记为叶节点,并将其类别设定该结点所含样本最多的类别。 在第(3)种情形下,同样把当前结点标记为叶节点,但将其类别设定为其父结点所含样本最多的类别。综上,本题选A。其他选项错误。
3、ID3决策树划分时,选择信息增益最____(大/小)的属性作为划分属性
大
4、若数据集的属性全为离散值,决策树学习时,____(可以/不可以)把用过的属性再作为划分属性。
不可以
5、下列说法错误的是()
- 信息增益准则对可取值较少的属性有所偏好
- C4.5算法并不是直接选择增益率最大的候选划分属性
- 基尼指数反映了从数据集中随机抽取两个样本,其类别标记不一致的概率
- 基尼指数越小,数据集的纯度越高
本题选A。信息增益准则对可取值较多的属性有所偏好。比如我们选取编号属性作为属性进行划分,由于编号独特唯一,条件熵为0了,每一个结点中只有一类,所以 “纯度” 非常高。其他正确。
6、对西瓜数据集2.0(《机器学习》教材第76页),属性“触感”和“色泽”,____(触感/色泽)的增益率更大
色泽
7、对西瓜数据集2.0(《机器学习》教材第76页),属性“色泽”的基尼指数为____(保留2位有效数字)
0.43
6 / 17 ∗ ( 1 − ( 1 / 2 ) 2 − ( 1 / 2 ) 2 ) + 6 / 17 ∗ ( 1 − ( 4 / 6 ) 2 − ( 2 / 6 ) 2 ) + 5 / 17 ∗ ( 1 − ( 1 / 5 ) 2 − ( 4 / 5 ) 2 ) = 0.4275 6/17*(1-(1/2)^2-(1/2)^2)+6/17*(1-(4/6)^2-(2/6)^2)+5/17*(1-(1/5)^2-(4/5)^2)=0.4275 6/17∗(1−(1/2)2−(1/2)2)+6/17∗(1−(4/6)2−(2/6)2)+5/17∗(1−(1/5)2−(4/5)2)=0.4275
8、随着决策树学习时的深度增加,会发生什么现象?
- 位于叶结点的样本越来越少
- 不会把数据中不该学到的特性学出来
- 决策树不会过拟合
- 叶结点一定学到一般规律
本题选A。在决策树选取属性进行划分后,每个叶结点的样本数都比上一个结点要少,越来越少是正确的。对于B选项,过拟合后就会学到不该学到的特性。C选项任何模型都会过拟合,决策树解决过拟合的方法就是剪枝。D选项过拟合后学不到一般规律。
9、只学习一颗决策树作为模型时,一般____(要/不要)选择剪枝
要
不剪枝容易造成过拟合
10、(本题需阅读教材79-83页中剪枝的例子)考虑如图的训练集和验证集,其中“性别”、“喜欢ML作业”是属性,“ML成绩高”是标记。假设已生成如图的决策树,用精度(accuracy)衡量决策树的优劣,预剪枝的结果____(是/不是)原本的决策树。
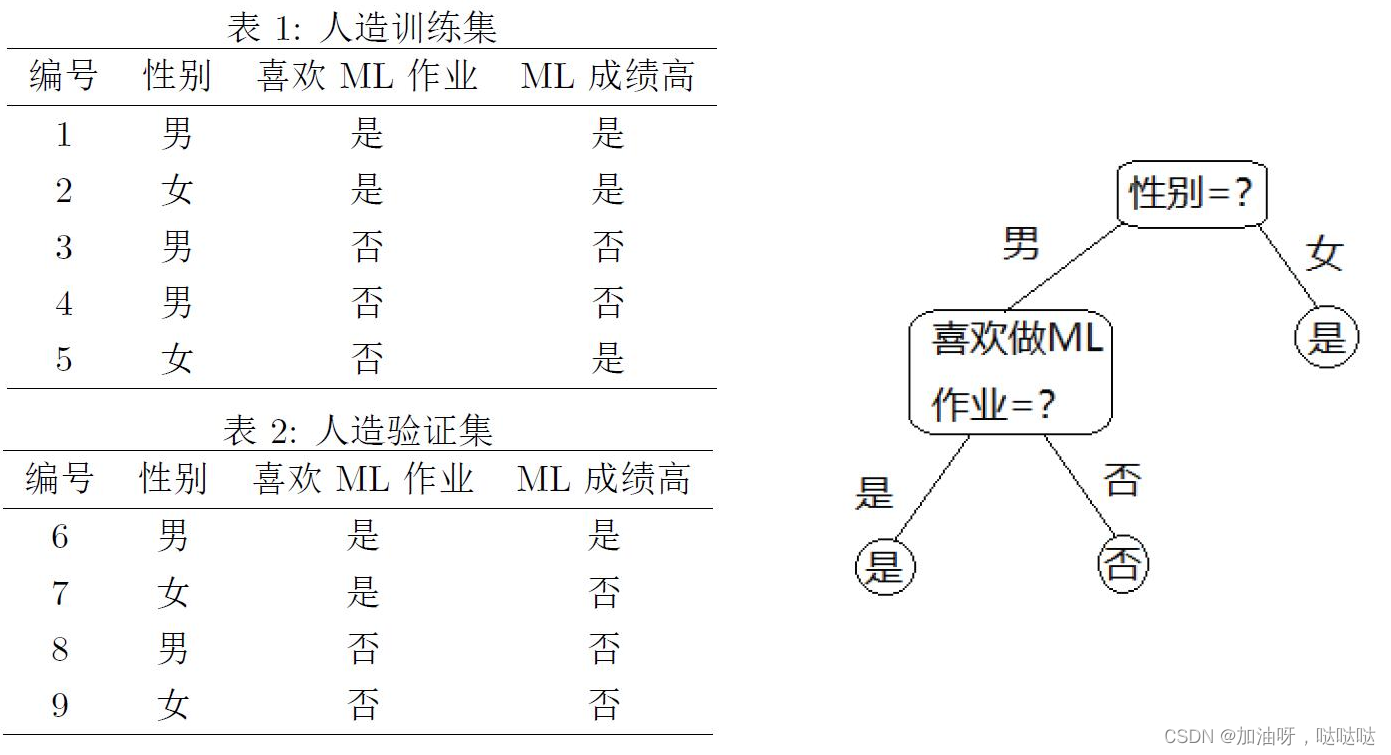
不是
首先看性别,划分之前选择标记均为“是”,验证集精度为25%;划分后性别男标记为“否”,性别女标记为“是”,验证集精度为25%,因此没有带来泛化性能的提升。剪枝后决策树为直接判定标记为“是”。
11、(本题需阅读教材79-83页中剪枝的例子)考虑如图的训练集和验证集,其中“性别”、“喜欢ML作业”是属性,“ML成绩高”是标记。假设已生成如图的决策树,用精度(accuracy)衡量决策树的优劣,后剪枝的结果____(是/不是)原本的决策树。
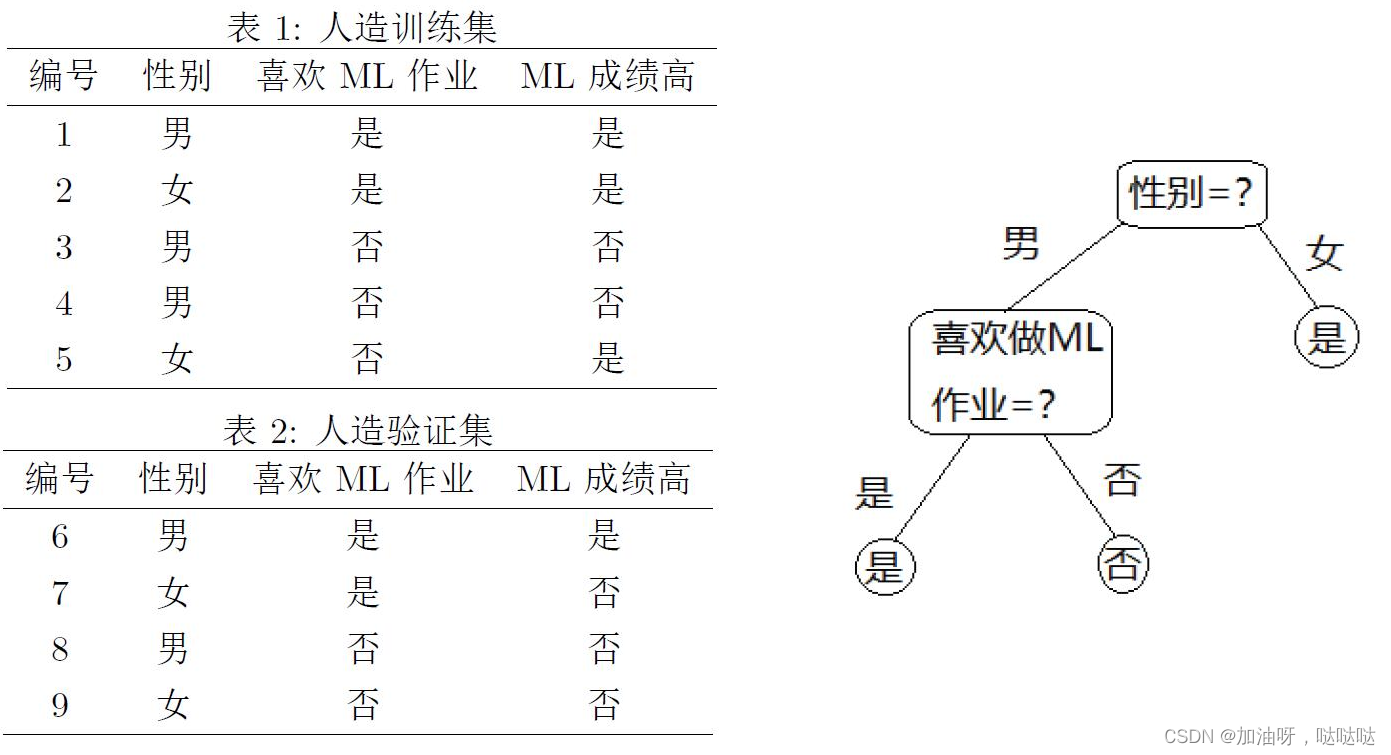
是
首先看喜欢,剪枝前验证集精度为50%,剪枝后该结点标记为“否”,验证集精度为25%,因此不剪枝。最终决策树为原本的决策树。
12、下列说法正确的是()
- 决策树处理缺失值时,仅通过无缺失值的样例来判断划分属性的优劣
- 若数据中存在缺失值,决策树会仅使用无缺失的样例
- 若数据维度很高,不容易出现大量缺失值
- 对决策树,给定划分属性,若样本在该属性上的值缺失,会随机进入一个分支
本题选A。决策树在确定划分属性的优劣时,只采用无缺失值的样例。我们回顾选取划分属性时的准则,在含有属性缺失值时,我们修改后的信息增益公式为无缺失值样本的比例乘以用该属性划分后在无缺失值上带来的信息增益,从这里可以看出对于选取划分属性时和缺失值样本本身并无关系。对于B选项,缺失值属性的样例也需要在后续被使用。C选项数据维度高时容易出现缺失值。D选项进入的方法是“样本赋权,权重划分”。
13、决策树处理有缺失值样本时,一个样本在各子节点中的权重和为____(保留一位小数)
1.0
本题填1.0。我们知道在处理决策树样本具有缺失值的问题时我们采用的方法是“样本赋权,权重划分”的方法,缺失值样本以一定的权重进入所有的子节点,权重的给定方式为样本权重乘以无缺失样本中属性在对应取值上样本所占的比例,故对所有子节点求和即为样本的初始权重,我们知道根节点各样本的初始权重我们都设为1,故答案为1,这里保留一位小数应该填1.0。
14、关于剪枝,下列说法错误的是()
- 对于同一棵树,进行预剪枝和后剪枝得到的决策树是一样的
- 决策树的剪枝算法可以分为两类,分别称为预剪枝和后剪枝
- 预剪枝在树的训练过程中通过停止分裂对树的规模进行限制
- 后剪枝先构造出一棵完整的树,然后通过某种规则消除掉部分节点,用叶子节点替代
15、通常来说,子节点的基尼不纯度与其父节点是什么样的关系?
- 通常更低
- 通常更高
- 永远更高
- 永远更低
本题选A。首先我们决策树划分是要选取信息增益更大的属性值进行划分,目的为降低样本的不纯度,故我们希望其基尼不纯度是降低的;但并非所有划分都会让基尼不纯度一致降低,可以想到一种反例:我们假设有一个样本具有大概率,剩余其余所有样本均匀分配小概率;在一次划分中,我们将样本分为上述两类,其基尼不纯度会增大。故本题答案应为通常更低。

