
- 1FPGA的学习:数码管静态显示的实现(一)_fpga静态数码管显示
- 22024年C C++最全一、OpenCV环境搭建(采用官方已经编译好的)_编译好的opencv,不同层级的C C++开发者的不同行为_opencv c++
- 3[opencv 从零开始 2 ] 自动给人脸打马赛克,numpy生成随机图,图像通道的拆分与合并,获取图像的属性_opencv随机打码
- 4Redis三主三从集群搭建(docker版)_docker 部署redis:5.0.2 集群三主三从
- 5华为端口隔离 互通_【测试】华为R&S基础测试题,你能对几个?
- 6探索交互的本质:从指令到界面的演进与Linux基础指令的深入剖析
- 7数据结构与算法练习-题目1-解题思路及代码_数据结构练习题写思路
- 8Kafka第一天笔记_kafka第一天课堂笔记
- 9数字中国创新大赛|数据库运维安全管控信创方案荣获优胜奖!
- 10【C++20 新特性 】模板参数包展开与Lambda初始化捕获详解_c++ 参数包展开
LLMs之Llama-2 70B:《Self-Rewarding Language Models自我奖励语言模型—Llama 2》翻译与解读_llama2 的奖励模型
赞
踩
LLMs之Llama-2 70B:《Self-Rewarding Language Models自我奖励语言模型—Llama 2》翻译与解读
目录
《Self-Rewarding Language Models》翻译与解读
《Self-Rewarding Language Models》翻译与解读
| 地址 | |
| 时间 | 2024年1月18日 |
| 作者 | Weizhe Yuan1,2 Richard Yuanzhe Pang1,2 Kyunghyun Cho2 Sainbayar Sukhbaatar1 Jing Xu1 Jason Weston1,2 1 Meta 2 NYU |
| 总结 | 论文提出了自我激励语言模型的概念。 背景痛点: >> 传统方式是通过人类偏好训练奖励模型,但人类水平或会限制训练信号质量; >> 要实现超人智能水平的智能代理体,未来模型需要比人类提供更高质量的反馈信号为训练提供足够的信号。 >> 现有方法常常从人类偏好中训练奖励模型,但这可能受限于人类表现水平;同时这些独立冻结的奖励模型也无法在LLM训练过程中继续学习和提升。 解决方案:本文研究了自我奖励语言模型,其中语言模型本身通过语言模型作为裁判的提问响应方式为自己的训练提供奖励。 >> 让语言模型本身通过LLM-as-a-Judge方式给自己提供奖励,在迭代DPO训练过程中同时提高指令执行能力和提供高质量奖励能力; >> 将该方法应用于微调Llama 2 70B模型,通过3次迭代训练得到的模型在AlpacaEval 2.0排名榜上超越了许多系统,如Claude 2、Gemini Pro和GPT-4 0613。 >> 采用LLM作为裁判的迭代增强训练方法,不仅可以提升指令执行能力,还可以提升自己提供高质量奖励的能力。 核心特点: >> 语言模型可以自我监督,在训练过程中不断提高奖励质量和自身能力; >> 相比于传统固定奖励模型,自我激励模型可以在整个训练生命周期中持续学习成长; >> 旨在打破人类水平限制,培养出超越人类水平的智能代理能力。 优势: >> 相比于从人类样例学习奖励的方法,本文方法允许模型在训练过程中学习如何提供更好的奖励信号。 >> 可以自主学习并在指令执行和奖励提供两方面都不断提升,实现了模型在双向轴(执行指令和给奖能力)同时提升,目标是自主成长中的智能系统; >> 开创性地探索了语言模型内部学习机制,为未来模型设计提供了新思路。 总之,本文提出了使语言模型能够利用自己为自己提供奖励信号的自我奖励学习框架, 初步地验证此框架可以使模型在执行任务和评估任务上同时提升,开启了模型在没有外部reward 的情况下自主进化的新可能。 |
Abstract
| We posit that to achieve superhuman agents, future models require superhuman feedback in order to provide an adequate training signal. Current approaches commonly train reward models from human preferences, which may then be bottlenecked by human performance level, and secondly these separate frozen reward models cannot then learn to improve during LLM training. In this work, we study Self-Rewarding Language Models, where the language model itself is used via LLM-as-a-Judge prompting to provide its own rewards during training. We show that during Iterative DPO training that not only does instruction following ability improve, but also the ability to provide high-quality rewards to itself. Fine-tuning Llama 2 70B on three iterations of our approach yields a model that outperforms many existing systems on the AlpacaEval 2.0 leaderboard, including Claude 2, Gemini Pro, and GPT-4 0613. While only a preliminary study, this work opens the door to the possibility of models that can continually improve in both axes. | 我们认为,为了实现超人智能体,未来的模型需要超人类的反馈,以提供足够的训练信号。目前的方法通常从人类偏好中训练奖励模型,然后可能受到人类性能水平的瓶颈限制,其次,这些分离的冻结奖励模型在LLM(Language Model)训练过程中无法学习改进。在这项工作中,我们研究了自我奖励语言模型,其中语言模型通过LLM作为裁判的提示在训练过程中提供自己的奖励。结果表明,在迭代DPO(Deep Policy Optimization)训练过程中,不仅指导遵循能力得到提高,而且提供高质量奖励的能力也得到了改善。通过在我们方法的3个迭代上对Llama 2 70B进行微调,得到的模型在AlpacaEval 2.0排行榜上超越了许多现有系统,包括Claude 2、Gemini Pro和GPT-4 0613。虽然这只是一个初步研究,但这项工作为模型在两个方向上持续改进的可能性敞开了大门。 |
1 Introduction
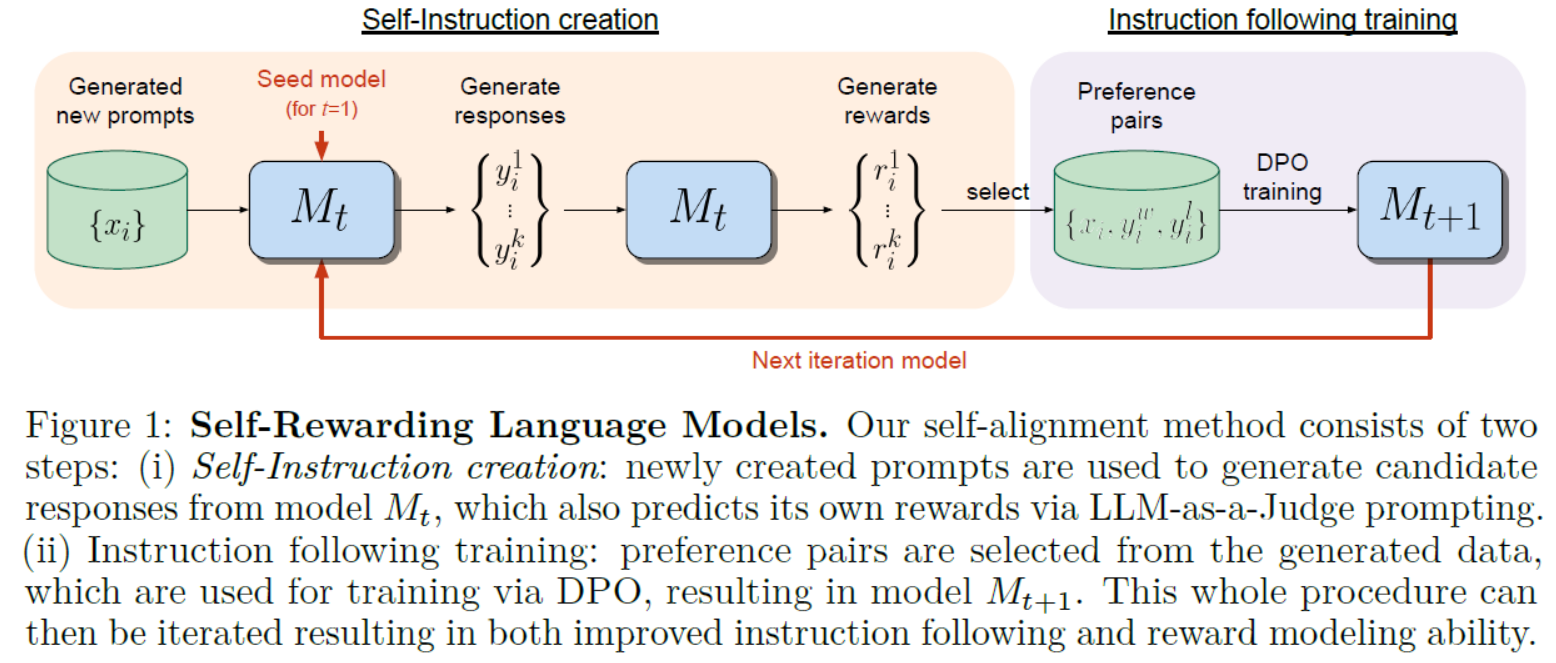
Figure 1: Self-Rewarding Language Models. Our self-alignment method consists of two steps: (i) Self-Instruction creation: newly created prompts are used to generate candidate responses from model Mt, which also predicts its own rewards via LLM-as-a-Judge prompting.(ii) Instruction following training: preference pairs are selected from the generated data, which are used for training via DPO, resulting in model Mt+1. This whole procedure can then be iterated resulting in both improved instruction following and reward modeling ability.图1:自我奖励语言模型。我们的自对齐方法包括两个步骤:(i)自我指令创建:使用新创建的提示从模型Mt中生成候选响应,并通过LLM-as-a-Judge提示预测其自身的奖励。(ii)训练后的指令:从生成的数据中选择偏好对,通过DPO进行训练,得到模型Mt+1。然后,整个过程可以迭代,从而提高指令遵循和奖励建模能力。
5 Conclusion结论
| We have introduced Self-Rewarding Language Models, models capable of self-alignment via judging and training on their own generations. The method is trained in an iterative manner, where in each iteration the model creates its own preference-based instruction training data. This is done by assigning rewards to its own generations via LLM-as-a-Judge prompting, and using Iterative DPO to train on the preferences. We showed that this training both improves the instruction following capability of the model, as well as its reward-modeling ability across the iterations. While this is only a preliminary study, we believe this is an exciting avenue of research because this means the model is better able to assign rewards in future iterations for improving instruction following – a kind of virtuous circle. While this improvement likely saturates in realistic scenarios, it still allows for the possibility of continual improvement beyond the human preferences that are typically used to build reward models and instruction following models today. | 我们介绍了自我奖励语言模型,这是能够通过评判和训练自身生成进行自我调整的模型。该方法以迭代方式训练,每次迭代中模型都会创建自己基于偏好的指导性训练数据。通过LLM作为裁判的提示为自己的生成分配奖励,并使用迭代DPO训练模型的偏好。我们展示了这种训练既提高了模型的指导遵循能力,也改善了模型在迭代过程中的奖励建模能力。虽然这只是一个初步研究,但我们认为这是一个令人兴奋的研究方向,因为这意味着模型更能够在未来的迭代中为改进指导遵循分配奖励,形成一种良性循环。尽管在现实场景中,这种改进可能会饱和,但仍然存在超越当前通常用于构建奖励模型和指导遵循模型的人类偏好的可能性,实现持续改进的可能性。 |
6 Limitations限制
| While we have obtained promising experimental results, we currently consider them pre-liminary because there are many avenues yet to explore, among them the topics of further evaluation, including safety evaluation, and understanding the limits of iterative training. We showed that the iterations of training improve both instruction following and reward modeling ability, but only ran three iterations in a single setting. A clear line of further research is to understand the “scaling laws” of this effect both for more iterations, and with different language models with more or less capabilities in different settings. | 尽管我们获得了令人鼓舞的实验结果,但目前我们认为它们是初步的,因为还有许多待探索的方向,包括进一步评估、包括安全评估以及了解迭代训练的极限等主题。 我们展示了训练的迭代既提高了指导遵循能力,也提高了奖励建模能力,但只在一个设置中运行了三次迭代。进一步研究的一个明确方向是了解这种效果的“扩展法则”,包括更多迭代和在不同设置中具有更多或更少能力的不同语言模型。 |
| While we have evaluated our models using GPT-4 using head-to-head and AlpacaEval 2 leaderboard style evaluation, there are many other automatic evaluation benchmarks that one can measure. Further, we observed an increase in length in model generations, and there is a known correlation between length and estimated quality, which is a topic that should be understood more deeply in general, and in our results in particular as well. It would also be good to understand if so-called “’reward-hacking” can happen within our framework, and in what circumstances. As we are using both a language model as the training reward, and a language model for final evaluation, even if they are different models, this may require a deeper analysis than we have provided. We conducted a preliminary human (author) evaluation, which validated the automatic results that we see, but more detailed human evaluation would be beneficial. Another clear further avenue of study is to conduct safety evaluations – and to explore safety training within our framework. Reward models have been built exclusively for safety in existing systems [Touvron et al., 2023], and a promising avenue here would be to use the LLM-as-a-Judge procedure to evaluate for safety specifically in our self-rewarding training process. Given that we have shown that reward modeling ability improves over training iterations, this could mean that the safety of the model could potentially improve over time as well, with later iterations being able to capture more challenging safety situations that earlier iterations cannot. | 虽然我们使用GPT-4进行了头对头和AlpacaEval 2排行榜风格的评估,但还有许多其他自动评估基准可以测量。此外,我们观察到模型生成长度的增加,并且长度与估计质量之间存在已知的相关性,这是一个通常应更深入了解的主题,特别是在我们的结果中也是如此。还需要了解在我们的框架中是否可能发生所谓的“奖励欺骗”以及在什么情况下会发生。由于我们既使用语言模型作为训练奖励,又使用语言模型进行最终评估,即使它们是不同的模型,这可能需要比我们提供的更深入的分析。我们进行了初步的人类(作者)评估,验证了我们看到的自动结果,但更详细的人类评估将是有益的。 另一个明显的研究方向是进行安全评估,并在我们的框架内探索安全培训。对于现有系统,已经专门为安全性构建了奖励模型[Touvron等人,2023],在这里一个有希望的途径是使用LLM作为裁判的程序专门评估我们的自我奖励训练过程的安全性。鉴于我们已经展示了奖励建模能力随着训练迭代的进行而改善,这可能意味着模型的安全性随时间的推移也有可能改善,后续迭代能够捕捉到前期迭代无法应对的更具挑战性的安全情况。 |

