
- 1kubeedge keadm join命令逻辑详解,keadm-join-v1.10.0
- 2LLM大语言模型(十二):关于ChatGLM3-6B不兼容Langchain 的Function Call_llmsingleactionagent
- 3微信小程序 搜索框实现模糊搜索(带模拟数据,js,wxml,wxss齐全)_微信小程序模糊搜索功能实现
- 4【Git】拉取 Pull Requests 测试的两种方法_怎么在git中 pull request
- 5AIGC职业技能如何官方考证,如何提升AI下的就业新能力_aigc考证
- 6消息中间件选型
- 7ELF文件格式分析与静态链接总结归纳_静态分析elf
- 8STL中常用数据结构方法以及常用算法_c++stl不同数据结构共有的方法
- 9Redmi AC2100上使用Hiboy Padavan固件进行子网IPv6分配,Padavan子网无法获取IPv6地址_小米路由器不能分配ipv6地址
- 10几种加密算法
【论文解读】Machine learning at the service of meta-heuristics for solving cop : A state-of-the-art_grh算法
赞
踩
Invited Review:
Machine learning at the service of meta-heuristics for solving combinatorial optimization problems: A state-of-the-art
作者:
Maryam Karimi-Mamaghana,∗ , Mehrdad Mohammadi a , Patrick Meyer a , Amir Mohammad Karimi-Mamaghanb , El-Ghazali Talbi
European journal of Operational Research 296 (2022) 393-422
论文链接:https://doi.org/10.1016/j.ejor.2021.04.032
关键词:
Meta-heuristics、Machine learning、Combinatorial optimization problems、State-of-the-art
本文工作:
本文对使用机器学习技术改进元启发式的最新进展进行了全面的技术综述。元启发式是一组可应用于解决复杂优化问题的算法。机器学习技术与元启发式的集成旨在使这些算法更高效、有效和稳健。
文章重点介绍了在元启发式中用于应用机器学习的技术,包括算法选择、适应度评估、初始化、进化、参数设置与协作。此外,文章还讨论了在元启发式中使用机器学习的优势,如更强的性能、更高的效率、更高的鲁棒性、更大的灵活性和新的观点。该综述旨在填补这一空白,并为对元启发式和机器学习领域感兴趣的研究人员和从业者提供全面的参考。
概念解释:
1、元启发式算法:元启发式算法是一类可用于解决复杂优化问题的搜索算法。这些问题通常涉及在大量可能的解决方案中找到最佳解决方案。元启发式通过迭代地细化一组候选解决方案来提高其质量。
与保证找到最优解的精确优化方法不同,元启发式方法不能保证找到最佳解,但它们通常可以在合理的时间内找到非常好的解。它们通常用于由于问题的规模或复杂性而导致精确方法不可行的情况,或者当问题没有明确定义的结构或目标函数时。
一些流行的元启发式算法包括遗传算法、模拟退火、禁忌搜索、蚁群优化和粒子群优化。这些算法中的每一种都有自己的优势和劣势,适用于不同类型的优化问题。
2、机器学习:机器学习是人工智能的一个子领域,专注于构建算法和模型,这些算法和模型可以从数据中学习,并基于这些学习做出预测或决策。换句话说,机器学习算法被设计为自动学习数据中的模式和关系,而无需为每个任务明确指定参数。
机器学习过程通常分文三个主要阶段:
数据准备和预处理,包括收集、清理原始数据,并将其转换为适合分析的格式。
模型训练,包括使用一组标记的数据来训练机器学习模型,通常使用监督学习或无监督学习等技术。
模型评估和测试,包括在一组以前从未见过的独立数据上测量模型的性能,以确保它能够很好地推广到新数据。
机器学习有着广泛的应用,包括图像和语音识别、自然语言处理、推荐系统、欺诈检测等。
3、组合优化问题:组合优化问题涉及从一组可能的解中找到最佳可能的解,其中解是离散的,可以表示为对象、变量或约束的组合或排列。这些问题通常很难解决,因为可能的解决方案数量可能非常多,因此无法单独评估每个解决方案。
组合优化问题可以在许多不同的领域找到应用,包括计算机科学、运筹学、工程、经济学和物流。组合优化问题的例子包括:
旅行推销员问题,目标是找到访问一组城市一次并返回起始城市的最短路线。
背包问题,目标是将一组物品放入到容量有限的背包中,使背包中物品的总价值最大化。
图着色问题,目标是使用尽可能少的颜色为图的顶点着色,使相邻的两个顶点都没有相同的颜色。
组合优化问题可以使用多种技术来解决,包括线性规划和动态规划等精确方法,以及遗传算法、模拟退火和禁忌搜索等元启发式方法。方法的选择取决于具体问题及其特征,例如问题的大小、解空间的结构和可用的计算资源。
目录
摘要
近年来,人们对将机器学习技术集成到元启发式算法中以解决组合优化问题的研究兴趣日益浓厚。这种集成旨在引导元启发式实现高效、有效和健壮的搜索,并在解决方案质量、收敛速度和健壮性方面提高它们的性能。
由于开发了各种不同目的的集成方法,因此有必要回顾使用机器学习技术改进元启发式的最新进展。据我们所知,目前缺少一个全面的技术审查的文献。为了填补这一空白,本文回顾了机器学习技术在设计不同目的的元启发式元素中的应用,包括算法选择、适应度评估、初始化、进化、参数设置和合作。首先,我们描述了这些集成方式的关键概念和基础。然后,根据提出的统一分类法,对每种集成方式的最新进展进行了回顾和分类。最后,我们对实现这些集成方式的优势、限制、要求和挑战进行了技术讨论,并展望了未来的研究方向。
1、引言
元启发式(Metaheuristics)是一种计算智能范式,广泛用于解决复杂的优化问题,特别是组合优化问题(Combinatorial Optimization Problem) (osman&laporte, 1996)。cop是一类具有离散决策变量和有限搜索空间的复杂优化问题。许多cop属于NP-Hard 类优化问题,需要指数级的时间来求解最优性。对于这些问题,元启发式可以在合理的计算时间内提供可接受的解决方案,因此是精确算法的良好替代品(Hertz & de Werra, 1990;Osman & Laporte, 1996; talbi, 2009)。这也是过去二十年来人们对元启发式领域的兴趣显著增长的主要原因之一。
从技术角度来看,元启发式是一类近似优化方法,它通过安排和试验局部改进过程与更高级别的策略之间的相互作用来创建一种能够逃离局部极值并执行搜索空间的鲁棒搜索的过程(Gendreau&Potvin,2010)。在这样的迭代搜索过程中,会产生大量解决方案、评估和进化,直到找到有希望的解决方案为止。事实上,在搜索过程中,元启发式产生大量的数据,包括基于适应度值的好(精英)或坏解决方案、从开始到结束的搜索操作符序列、不同解决方案的演化轨迹、局部极值等。这些数据可能包含有用的知识,如好和坏解决方案的属性、搜索过程中不同阶段的操作符性能、搜索操作符的优先级等。然而,经典元启发式不使用这些数据中任何形式的隐藏知识。
机器学习(Machine Learning)技术可以通过从生成的数据中提取有用的知识,在整个搜索过程中为元启发式服务。将此类知识纳入搜索过程可以指导元启发式做出更好的决策,从而使其更智能,并显著提高其在解决方案质量、收敛速度和鲁棒性方面的性能。机器学习是人工智能(AI)的一个子领域,涉及算法从数据中学习,并推广应用到新任务中(Song,Triguero&Ozcan,2019)。近年来,机器学习技术和元启发式的融合引起了广泛关注(Songet al,2019;Talbi,2016)。
近年来,关于元启发式在机器学习任务中的应用、机器学习技术在解决复杂优化问题中的运用以及如何将机器学习技术整合到元启发式中的综述论文得到了广泛关注。据我们所知,目前文献缺乏关于机器学习技术如何为元启发式提供服务以及其具体目的的综合和技术性审查。很少有论文对机器学习技术在不同目的下的整合进行全面性综述。
本文提供了机器学习技术整合到元启发式中的全面和技术性综述,包括算法选择、适应度评估、初始化、进化、参数设置和合作等方面。在不同的优化问题中,本文的重点是解决复杂优化问题(COPs)。本文不仅是描述主要概念和前提的教科书,还是将文献分类以确定研究空白并提供实施每种整合方法的技术讨论的技术性论文。此外,还提出了一个分类法,以提供通用术语和分类。我们相信,本文不仅对想要使用机器学习技术的元启发式领域的非专家不可或缺,而且对于旨在为研究生提供教学课程的研究者,特别是运筹学和计算机科学专业的博士生也不可或缺。
2、背景
2.1 组合优化问题
组合优化问题(COPs)是一类具有离散决策变量和有限解空间的优化问题,尽管太大以至于穷极搜索仍不是现实的选择(Korte,Vygen,Korte&Vygen,2012)。COPs的形式表示如下:
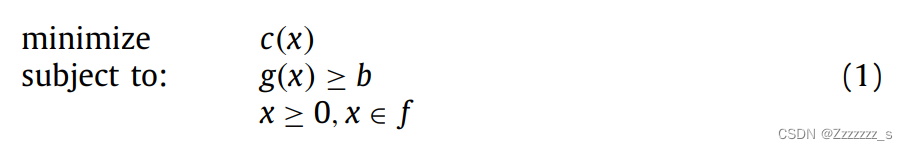
其中不等式g(x)b和x
0是指定目标函数c(x)要最小化的凸多面体的约束条件,f是满足约束条件的可行解集。许多现实生活中的问题(例如车辆路径问题、调度问题等)可以被形式化为COPs。大量的COPs属于NP-Hard类别的优化问题,需要指数时间来求解最优解(Talbi,2009)。附录A中的表A.1提供了本论文中引用的COPs列表。
2.2 启发式算法
在合理的计算时间内,以精确的方式求解大量现实生活中的COPs是困难的。近似算法是解决这些问题的替代方案。虽然近似算法不保证最优性,但它们的目标是在合理的计算时间内尽可能接近最优解,最多为多项式时间(Talbi,2009)。近似算法分为问题相关的启发式和元启发式。前者如其名称所示,描述了一组专门设计用于特定优化问题的算法。然而,如果适当定制,元启发式是更一般的适用于各种优化问题,尤其是COPs的算法。
元启发式可以以不同的方式进行分类。它们可以是自然启发式的,也可以是非自然启发式的(Talbi,2009)。许多元启发式受到自然现象的启发。进化算法(Evolutionary Algorithm)如遗传算法(GA)(Holland等人,1992年)、文化基因算法(Memetic algorithm)(Moscato等人,1989年)和差分进化(DE)(Storn&Price,1997年)受到生物学的启发;人工蜂群算法(ABC)(Karaboga,2005年)、蚁群优化算法(ACO)(Dorigo&Blum,2005年)和粒子群优化算法(PSO)(Kennedy,2006年)受到群体智能的启发。还有一些元启发式受到非自然现象的启发;帝国主义竞争算法(Imperialist Competitive Algorithm)(Atashpaz-Gargari&Lucas,2007年)由社会启发,模拟退火算法(SA)(Kirkpatrick,Gelat&Vecchi,1983年)由物理启发,和谐搜索算法(HS)(Geem,Kim&Logonathan,2001年)由音乐启发。从另一个角度来看,元启发式可以是无记忆或在搜索过程中使用记忆的(Talbi,2009)。无记忆元启发式(例如GA、SA等)在搜索过程中不动态地使用历史信息。然而,具有记忆的元启发式,例如禁忌搜索算法(TS)(Glover&Laguna,1998年),在搜索过程中记住历史信息,并帮助避免重复决策。
另外,元启发式可以在搜索过程中做出确定性或随机决策来解决优化问题(Talbi 2009)。具有确定性规则的元启发式(例如TS)在从相同的初始解开始,最终获得相同的最终解,而随机元启发式(例如SA、GA)则应用随机规则来解决问题,并在从相同的初始解开始,最终获得不同的最终解。此外,就其起点而言,元启发式分为基于单个解的元启发式或基于种群的元启发式(Talbi 2009)。基于单个解的元启发式,也称为轨迹方法,例如迭代局部搜索(ILS)(Lourenco、Martin和Stiitzle,2003)、突破局部搜索(BLS)(Benlic、Epitropakis和Burke,2017)、下降为基础的局部搜索(DLS)(Zhou、Hao和Duval,2016)、引导局部搜索(GLS)(Voudouris和Tsang,1999)、变邻域搜索(VNS)(Mladenovic和Hansen,1997)、爬山算法(HC)(Johnson、Papadimitriou和Yannakakis,1988)、大邻域搜索(LNS)(Shaw,1998)、大洪水算法(GD)(Dueck,1993)、TS、SA等都通过操纵和转换一个单独的解决方案来达到(接近)最优解。基于种群的元启发式,例如水波优化(wWO)(Zheng,2015)、GA、PSOACO等,试图通过演化一个解决方案种群来找到最优解。由于这种性质,基于种群的元启发式是更多的探索性搜索算法,它们允许在整个搜索空间中更好的多样化。基于单个解的元启发式更倾向于利用性搜索算法,并且它们具有在局部区域加强搜索的能力。
最后,根据它们的搜索机制,元启发式可以是迭代的或贪婪的(Talbi 2009)。前者(例如ILS、GA)从完整的解决方案开始,并在每次迭代中使用一组搜索操作符对其进行操作。后者也称为构造算法,从空解开始逐步构建解决方案,直到获得完整的解决方案。贪婪算法的经典示例包括最近邻算法(NN)、贪婪启发式(GH)、贪婪随机化启发式(GRH)和贪婪随机化自适应搜索过程(GRASP)(Feo & Resende 1995)。
2.3 机器学习
机器学习(Machine Learning)是人工智能的一个子领域,它使用算法和统计方法使计算机具有“从数据中学习”的能力,即在没有为每个任务显式编程的情况下提高其解决问题的性能(Bishop,2006)。这些系统随着时间的推移自主地通过从数据和信息中提取的知识以及观察和现实世界交互来改进学习。所获得的知识使这些系统能够正确地推广到新环境中。根据Bishop(2006),ML算法可以分为:
监督学习算法 - 在监督学习中,输入变量的值和相应的输出变量(标签)事先已知。监督学习算法试图自动找出输入变量和输出标签之间的关系,并利用它来预测新的输入变量的输出。根据学习的目的,监督学习算法可以分为分类和回归算法。经典的监督学习算法包括线性回归(LR)、逻辑回归(LogR)、线性判别分析(LDA)、支持向量机(SVM)、朴素贝叶斯(NB)、梯度提升(GB)、决策树(DT)、随机森林(RF)、k近邻(k-NN)、人工神经网络(ANN)等。
无监督学习算法 - 当训练数据既不分类也不标记时,它们被使用。在无监督学习中,输入变量的值已知,但输出变量没有关联值。因此,学习任务是找出并描述隐藏在输入数据中的模式。聚类和关联规则(AR)是无监督学习的两个任务。经典的无监督学习算法包括k均值聚类、共享最近邻聚类(SNNC)、自组织映射(SOM)、主成分分析(PCA)、多对应分析(MCA)和用于AR的Apriori算法。
强化学习(RL)算法 - 在这些算法中,代理通过与环境的交互迭代地学习,采取将最大化奖励或最小化风险的动作。在每次迭代中,代理自动确定特定上下文内的理想行为(动作),以根据奖励反馈最大化其性能。RL算法包括Q-Learning(QL)、学习自动机(LA)、基于反对的RL(OPRL)、蒙特卡洛RL、SARSA和深度强化学习(DRL)等。
3、分类
虽然元启发式算法和机器学习技术最初是为了不同的目的而开发的,但它们可能执行共同的任务,例如特征选择或解决优化问题。元启发式和机器学习技术经常相互作用以提高它们的搜索和(或)学习能力。几十年来,元启发式算法在机器学习任务中得到了广泛应用(Meta-heuristics-in-Machine learning)(Wagner&Affenzeller,2005;Xue等,2015)。例如,元启发式算法可以用于特征选择、机器学习技术的参数设置(Oliveira,Braga,Lima,&Cornelio,2010)或模式识别(Kiranyaz,Ince,&Gabbouj,2014)。机器学习技术正在广泛地集成到元启发式中(Machine learning-in-Meta-heuristics),以使搜索过程智能化和更自主化。例如,强化学习可以帮助在搜索过程中选择最有效的元启发式相关参数(dos Santos,de Melo,Neto,&Aloise,2014)。
本文旨在回顾将机器学习技术集成到元启发式中以解决复杂优化问题的研究。我们提出了一个关于将机器学习技术集成到元启发式中的分类法,如图1所示的“机器学习-在元启发式中”分支。发现图1中的“元启发式-在机器学习中”分支超出了本文的范围,感兴趣的读者可以参考最新的关于元启发式在机器学习任务中的应用的文献综述(Calvet等人,2017;Gambella等人,2020;Song等人,2019)。

根据图1中提出的分类,我们提出将不同类型的集成分为以下目的:
算法选择 - 当使用元启发式解决优化问题时,首先需要选择一种或一组元启发式算法来解决问题。机器学习技术可以预测元启发式在解决优化问题方面的性能。
适应度评估 - 在搜索过程中,任何元启发式成功实现特定目标(目标)的成功与否都通过解决方案的适应度评估方法进行评估。机器学习技术可以通过近似计算昂贵的适应度函数来加速搜索过程。
初始化 - 任何元启发式都从初始解或一组解开始搜索过程。机器学习技术可以通过利用相似实例中的好解的知识来生成好的初始解,或者通过将输入数据空间分解为更小的子空间来加速初始化。
进化 - 它代表了整个搜索过程,从初始解(种群)开始,朝着最终解(种群)发展。机器学习技术可以智能地选择搜索操作符(即操作符选择),使用在搜索过程中获得的好和坏解的知识来进化一个解决方案的种群(即可学习的进化模型),并使用在搜索过程中获得的知识来指导邻居生成过程(即邻居生成)。
参数设置 - 任何元启发式都具有一组需要在搜索过程开始之前设置的参数。机器学习技术可以帮助在搜索过程之前或期间设置或控制参数的值。
合作 - 几种元启发式算法可以相互协作以并行或顺序解决优化问题。机器学习技术可以通过调整它们在搜索过程中的行为来提高合作元启发式算法的性能。
图1中每种集成还可以从另一个角度分类为:问题级、高级别和低级别集成(Talbi,2020)。算法选择和适应度评估分别代表了机器学习集成到元启发式算法中的高级别和问题级集成。根据生成初始解的策略(参见第6节),初始化属于问题级或低级别集成。进化和参数设置属于低级别集成的范畴。最后,合作可能属于高级别或低级别集成,具体取决于合作的程度。

无论哪种类型的集成,图2显示了在过去二十年中将机器学习技术集成到元启发式的不同目的的论文数量显著增加,这表明该主题的知识水平和受欢迎程度都有意义的增长。在所有类型的集成中,对进化的研究对总论文数量的贡献最大,并且在过去十年中呈现出不断增长的趋势。算法选择和初始化一直是关注的重点,并在过去二十年中获得了广泛的关注。合作、参数设置和适应度评估也是关注度变化不大的集成类型。
总之,图2表明算法选择、进化和初始化正在受到密切研究,而适应度评估、参数设置和合作是较少研究的方向,值得在未来进一步探索。本文其余部分的结构如下:每个章节详细解释了将机器学习技术集成到元启发式的各种方式,并以相应类型的集成的介绍为开头。然后,相关论文进行了审查、分类和分析。最后,该章节以关于相应指南、要求、挑战和未来研究方向的综合讨论结束。更精确地说,第4-9章分别致力于算法选择、适应度评估、初始化、进化、参数设置和合作。最后,结论和展望在第10章给出。
4、算法选择
文献中有许多研究人员开发了针对经典COP的高性能元启发式算法。然而,没有一种单一的元启发式算法可以支配所有其他元启发式算法在解决所有问题实例方面的表现。相反,不同的元启发式算法在不同的问题实例上表现良好(即性能互补),例如Kerschke等人(2019年)的研究。因此,总是存在一个未解决的问题:“对于给定的COP,哪个算法可能表现最佳?”(Rice等人,1976年)。当计算资源是无限制的时,找到最佳算法来解决COP的理想方法是穷尽所有可用算法并选择最佳解决方案,无论它是由哪个算法获得的。然而,由于计算资源有限,实际上不可能在特定的问题实例上测试所有可用算法。在这种情况下,一个主要问题是如何选择最适合解决特定问题实例的现有算法?机器学习技术通过选择最合适的算法来帮助回答这个问题。这就是算法选择问题(Algorithm Selection Problem)介入的地方。
ASP旨在使用机器学习技术自动选择最适合解决特定问题实例的算法(Kerschke等人,2019年;Kothoff,2014年)。ASP最初的框架由Rice等人(1976年)开发,基于四个主要组成部分:1)问题空间,包括一组问题实例;2)特征空间,包括一组问题的定量特征;3)算法空间,包括一组用于解决问题实例的所有可用算法;4)性能空间,将每个算法从算法空间映射到一组性能指标(如目标函数值(Objective Function Value)、CPU时间(CT)等)。最终目标是找到具有最高性能的问题-算法映射。
为了找到最佳的问题-算法映射,ASP使用机器学习的子领域元学习,该方法在一组训练实例上学习问题-算法映射并创建一个元模型。然后,元模型被用于预测新问题实例的适当映射(Kotthoff,2014)。在解决COPs时,研究ASP使研究人员能够系统地选择现有算法中最合适的算法,并取得了显著的性能改进(Kotthoff,2016)。在文献中,ASP被称为算法选择(Kanda,de Carvalho. Hruschka,Soares,& Brazdil,2016),每个实例的算法选择(Kerschke等人,2019),算法推荐模型(Chu等人,2019)和自动算法选择(Dantas & Pozo,2018)。然而,它们都共享自动选择特定问题实例的最佳算法的目标。
我们将在图3中说明ASP的步骤。如图3所示,ASP涉及两个主要步骤:1)元数据提取,2)元学习和元模型创建。

元数据提取 - 在给定问题和算法空间,目标是确定称为元数据的特征和性能空间。元数据分为两类:元特征和元目标特征(Kanda等人,2016)。元特征是一组定量特征,表示问题实例的属性,而元目标特征是一组性能数据,描述每个算法在特定问题实例上的表现。考虑到定义适当元特征的重要性,文献中有许多工作旨在为不同COP识别良好的元特征,包括SAT(Kerschkeet等人,2019)、TSP(Kerschke等人,2019;Mersmann等人,2013;Smith-Miles&Lopes,2012)、AP(Angel&Zissimopou-los,2002;Smith-Miles&Lopes,2012)、OP(Bossek、Grimme、Meisel、Rudolph&Trautmann,2018)、KP(Smith-Miles&Lopes,2012)、BPP(Smith-Miles&Lopes,2012)和GCP(Smith-Miles&Lopes,2012)。
元学习和元模型创建 - 使用元数据创建一个元模型,该模型可以预测每个算法对于每个问题实例的表现并确定问题-算法映射。根据从元模型中预期的预测类型,可以使用不同的机器学习技术进行元学习和创建元模型。不同类型的预测包括选择最佳算法(Smith-Miles,2008)、选择一组最合适的算法(Kanda、Carvalho、Hruschka&Soares,2011a)和对一组适当的算法进行排序(Kanda等人,2016),用于解决一个问题实例。根据预测类型,元学习任务可以是单标签分类(SLC)、多标签分类(MLC)和标签排序分类(LRC),分别对应于单一预测类型。除了分类技术外,回归技术如LR也可以用于预测每个算法的表现。使用回归技术,元学习问题是一个多元回归问题,其中每个算法都考虑一个目标变量。
考虑到创建元模型的方式,ASP可以是在线或离线的。在离线ASP中,使用一组特定的训练实例构建元模型,目的是预测新问题实例的问题-算法映射(Kanda等人,2016; Miranda、Fabris、Nascimento、Freitas和Oliveira,2018;Smith-Miles,2008)。然而,在在线ASP中,元模型在解决一组问题实例时动态构建并使用(Armstrong、Christen、McCreath和Rendell,2006;Degroote、Bischl、Kotthoff和De Causmaecker,2016;Gagliolo和Schmidhuber,2010;Kerschke等人,2019)。此外,算法空间通常称为算法组合或算法投资组合,被分类为静态或动态。静态组合包含一组固定的算法,这些算法在解决一个问题实例之前就被包括在组合中,并且在解决一个问题实例期间,组合及其内部算法的组成和配置不会发生变化;而动态组合包含一组算法,其组成和配置可以在解决一个问题实例期间发生变化(Kotthoff,2014)。在本节剩余部分中,研究ASP用于COPs的研究论文进行了回顾和分类,然后详细讨论了相应的指导方针、要求、挑战和未来研究方向。
4.1.文献分类与分析

从图3中得到灵感,表1根据不同的特征对研究ASP解决COP的论文进行了分类,包括问题空间、算法空间、算法组合类型、性能空间、学习机制、元学习任务、使用的机器学习技术以及训练集的大小。据我们所知,表1列出了所有相关的论文,包括文献中最近的研究ASP使用机器学习技术选择元启发式解决COP的论文。其他至少缺少这三个主要组件之一(即元启发式、机器学习技术和COP)的论文超出了本论文的范围,不予审查。
就问题空间而言,TSP和OAP是与其他COP相比研究最多的问题。此外,表1显示大多数研究的COP具有一个共同的特征;它们要么基于排列表示(例如,TSP、VRP 、FSP)或离散值表示(例如,AP、OAP)。这样的观察结果的一个主要原因是这些表示形式可用各种强大的元启发式实现,并且操作这些类型表示形式的简单性(Abdel-Basset Manogaran,Rashad,& Zaied,2018; Arora & Agarwal,2016; KocBektas, Jabali,& Laporte, 2016)。
考虑到算法空间,表1揭示了大多数研究中的算法组合由具有不同机制的不同元启发式算法组成,从单解到基于群体的解决方案,从无记忆元启发式算法(例如LS)到具有记忆的元启发式算法(例如TS),从仅接受更好解决方案的元启发式(例如ILS)到仅接受更差解决方案的元启发式(例如SA),以及从固定邻域大小的元启发式(例如TS和SA)到具有可变邻域大小的元启发式(例如VNS)。在组合中使用这些不同的算法突出表明具有不同搜索机制的不同元启发式对于不同的COP实例表现不同(dos Santos et al., 2014)。表1还显示所有审查过的论文都使用了静态组合。由于算法及其配置在静态组合中不会更改,因此它们的选择对于整个解决过程的成功至关重要。构建组合的有效方法是涉及互补算法,以便在广泛的不同问题实例上实现良好的性能。在审查过的论文中已经存在关于组合和算法内部特征的辩论。构建组合的最直接方式是从大量多样的元启发式中随机选择算法。第二种方式是将具有最好总体性能的元启发式纳入组合。然而,第三种也是最有前途的方式是构建具有互补优势算法的组合。具有互补优势的ASP似乎比具有最佳总体性能的ASP更有效。然而,大多数研究论文在构建组合时不太明确地使用文献中表现良好的元启发式来解决手头特定COP实例的问题,而不管它们在新问题实例上的强弱。
考虑到性能空间,我们可以看到大多数论文基于所得到的解决方案的OFV评估算法的性能。尽管考虑解决方案的OFV质量是最常见的比较算法的标准,但在选择算法时还有其他重要的标准,其中CT和鲁棒性具有很高的重要性,尤其是在解决COPs(Choong,Wong&Lim,2019;Mosadegh,Ghomi&Ser,2020;dosSantos等,2014)方面。因此,OFV、CT和鲁棒性是三个最重要的标准,可以用来比较算法。虽然这些度量之间存在权衡,通常没有一种算法在所有标准中表现最好,但考虑到这些标准可以提高解决COPs时的算法选择效率(Beham,Affenzeller&Wagner,2017;Wawrzy-niak,Drozdowski&Sanlaville,2020)。多标准ASP可以通过多目标视角进行建模(Kerschke等人,2019)。
表1显示,所有已审阅的论文都是以离线方式创建元模型的,并且没有研究使用在线ASP解决COPs。离线ASP的一个主要缺点是,在这种方式下,所选算法的性能无法得到监控以确认它们是否满足导致它们被选中的期望。因此,离线ASP本质上容易受到元启发式选择不佳的影响;然而,离线ASP的优势在于其计算成本较低,因为元模型仅基于一组训练实例创建一次。相反,在线ASP的主要优势在于可以在算法选择过程中做出更合理的决策,从而减少不良选择带来的的负面影响。然而,由于在解决一组问题实例时需要动态创建和使用元模型,这会增加额外的成本,因此在解决新问题实例的过程中需要更频繁地做出关于算法选择的决定。总的来说,没有证据表明一种方法优于另一种方法,两种方法都导致了性能的提高(Kandaet等人,2016;Wawrzyniak等人,2020)。因此,选择在离线还是在线方式创建元模型取决于特定应用的需求。
表1中另一个研究的特征是元学习任务。ASP最常见的输出是从投资组合中选择一个最佳算法并用于解决问题实例(即SLC任务的结果)。选择单一最佳算法的缺点是没有补偿错误选择的方法。事实上,如果选择了一种单一算法并在新问题实例上表现出不满意的表现,则没有其他推荐算法可以替换这种低效的算法。另一种方法是选择多个算法(即MLC和RLC任务的结果)。然而,没有报告显示其中一个方法优于另一个方法。
4.2 讨论和未来研究方向
本节分为三部分:首先,提供研究ASP的时间和满足研究ASP的要求的指南;其次,讨论研究ASP的技术挑战;最后,根据从表1中提取的研究空白提供未来的研究方向。
4.2.1. 指南&要求
提供研究ASP的指南的目的是帮助研究人员了解,虽然研究ASP可能为解决COPs提供最合适的元启发式,但并不总是最佳选择。接下来,我们将首先描述ASP有用的情况;然后,详细阐述使用ASP的要求。当解决一个问题实例的计算资源(即可用时间和可用核心数)有限时,研究ASP是有用的。这种情况适用于操作层面上的优化问题,其中可用时间有限且需要更频繁地解决问题。另一方面,对于战略层面上的优化问题(例如FLP),有足够的时间时,最佳选择是执行所有算法并选择最合适的一个,因为在战略层面上,找到更好的解决方案比执行所有算法的计算成本更重要。此外,当存在针对手头问题的多个高效竞争算法且无法确定哪个算法最适合解决问题实例时,研究ASP变得不可或缺。此外,ASP可以帮助非专家选择适当的算法来解决优化问题。换句话说,在候选算法数量较大且对问题缺乏先验知识的情况下,ASP可以被传统的试错优化任务取代。
经过仔细检查,以下是我发现的错别字、语法错误和表达不清的问题:
1. 将“一旦证明了使用ASP的合理性”修改为“一旦证明了使用ASP的合理性”。
2. 将“满足一系列要求才能应用ASP”修改为“满足一系列要求才能应用ASP”。
3. 将“在计算资源方面具有可负担的选择过程的成本”修改为“在计算资源方面具有可负担的选择过程成本”。
4. 将“事实上,如果研究一个问题实例的ASP比使用所有算法解决该问题实例并选择最佳算法更昂贵”修改为“事实上,如果研究一个问题实例的ASP比使用所有算法解决该问题实例并选择最佳算法更昂贵”。
5. 将“另一个可能也是ASP的挑战的重要要求是数据可用性”修改为“另一个可能也是ASP的挑战的重要要求是数据可用性”。
6. 在“在创建元模型时,有必要提供足够多的训练实例池以充分代表新实例”后添加“。需要注意的是,拥有足够多的实例并不保证ASP的效率”。
7. 在“而实例不相似性和算法歧视性是另外两个需要满足的要求(Smith-Miles等人,2014)”前添加“前者指的是提供尽可能多样化且分散在不同区域的实例的必要性。”。
8. 在“后者指的是提供在不同算法中显示不同行为但在投资组合中由不同算法解决的实例的必要性。”后添加“实际上,一些实例应该对某些算法容易而对其他算法困难。”。
9. 在“算法歧视性要求有助于在解决具有不同特征的不同实例时学习不同算法的优势和劣势。”后添加“这一要求有助于在解决具有不同特征的不同实例时学习不同算法的优势和劣势。”。
经过修改后的稿件如下:
一旦证明了使用ASP的合理性,就应该满足一系列要求才能应用ASP。使用ASP的第一个要求是在计算资源方面具有可负担的选择过程成本。事实上,如果研究一个问题实例的ASP比使用所有算法解决该问题实例并选择最佳算法更昂贵,则根本不需要研究ASP。另一个可能也是ASP的挑战的重要要求是数据可用性。在创建元模型时,有必要提供足够多的训练实例池以充分代表新实例。需要注意的是,拥有足够多的实例并不保证ASP的效率,而实例不相似性和算法歧视性是另外两个需要满足的要求。前者指的是提供尽可能多样化且分散在不同区域的实例的必要性。后者指的是提供在不同算法中显示不同行为但在投资组合中由不同算法解决的实例的必要性。实际上,一些实例应该对某些算法容易而对其他算法困难。这一要求有助于在解决具有不同特征的不同实例时学习不同算法的优势和劣势。
4.2.2 挑战
尽管ASP在解决COPs方面有效,但实施算法选择程序并不总是直截了当的,研究人员在整个设计到实施ASP过程中可能面临几个挑战。首先要处理的挑战被称为数据生成挑战。如前所述,ASP的两个重要要求是实例不相似性和算法歧视性,这允许生成具有不同特征的丰富数据集,从而导致更高效的元模型创建。为了生成这样的丰富数据集,算法需要提供广泛的实例。这个挑战有两个方面:1)找到或生成一组足够多的实例以确保数据可用性要求,特别是实例不相似性和算法歧视性是一项复杂的任务;2)如果实例数量很大,将所有候选算法执行在其上可能会非常耗时,这使得元模型创建计算成本高昂。如果手头的COP缺乏知识,第一个挑战会变得更加复杂。另一方面,对于经典的COP,存在多个实例库(例如TSPLIB(Reinelt,1991)和Taillard(Taillard,1993)),因此生成满足上述要求的一组足够实例相对不那么具有挑战性。
除了数据生成挑战外,第二个挑战是实例表征。创建元模型的主要问题是通过一组适当的度量来表征问题实例,称为元特征(Smith-Miles&Lopes 2012)。元特征必须揭示影响算法性能的实例属性。更详细和适当的特征会导致更好的元特征之间的映射,包括“边和顶点度量”:如顶点数、最低/最高顶点成本和最低/最高边成本等,更复杂的元特征可以是“复杂网络度量”,如平均测地线距离、网络脆弱性和目标熵(Kanda等人,2016)。根据元特征的类型,特征提取可以是基本特征的计算廉价任务,也可以是更复杂特征的昂贵任务。因此,在选择元特征时,应该考虑它们提供的信息的级别以及相应的计算时间。最优的方法是选择一组尽可能信息丰富的特征,同时计算成本可承受。从这个角度来看,创建高质量的元模型是一个复杂的相互作用过程,涉及使用一组具有不同行为的不同算法的不同训练实例以及使用计算成本低廉的信息丰富的元特征子集。
在算法选择性能和复杂性之间的权衡问题上,特别是在提取元特征方面,一直存在着未解决的问题。未来研究的一个重要方向是从特定问题的特征转向更一般、更简单的特征,这些特征在研究ASP时计算成本更低。有证据表明,对于特定的优化问题,少数简单的元特征足以实现ASP的卓越性能(Hoos、Peitl、Slivovsky和Szeider,2018年)。
在已审查的研究中,重点集中在由具有不同特征的不同元启发式算法组成的异质组合投资组合上,而单一元启发式在同质组合投资组合中的不同配置也显示出在解决COP时不同的行为。另一个有趣的未来研究方向可能是研究具有同质组合的投资组合的ASP,以在一组特定配置中选择单个启发式算法的特定配置,这与处理不同算法的投资组合相比更具挑战性。
如4.2.1节所解释的那样,实例不相似性和算法歧视是ASP的两个要求和挑战。一个有趣的研究方向可能是使用EAs( Evolutionary Algorithms)(Bossek和Trautmann,2016年;van Hemert,2006年;Mersmann等人,2013年;Smith-Miles、van Hemert和Lim,2010年)来演化实例的想法。实际上,该想法是使用EAs尽可能地演化COP实例以确保实例不相似性。这样,可以获得一组多样化的实例,从而提高元模型的性能。
开发在线ASP是另一个有前途的未来研究方向。正如4.1节所示,所有论文都研究了离线ASP,其中使用一组训练实例创建元模型。然而,使用在线ASP可能会获得更好的结果,因为它在解决一组问题实例时自适应地调整算法选择机制。尽管在线ASP会增加额外的计算负担,但它提高了鲁棒性,因为可以在解决COP实例期间对算法选择机制进行必要的调整。值得注意的是,通过使用计算成本较低的元特征可以减轻额外的负担。另一种应对额外负担的方法是使用增量或在线主动学习技术,其中已经训练好的模型在整个搜索过程中逐步改进(Lughofer 2017)。
当ASP的输出是多个选定的算法时,可以研究如何安排多个选定的算法来解决一个问题实例。调度的关键思想是从给定的一组算法中执行一系列算法,一个接一个地执行每个算法一定的时间(Kotthoff,2014年)。表1中提出的大多数多算法研究论文都没有研究算法调度。然而,在需要的时候使用具有特定优势(即探索和利用)的算法可以获得更多的灵活性。因此,未来的研究方向之一可能是调度多个推荐算法来解决一个问题实例。算法的调度可以是静态的或动态的(Kadioglu、Malitsky、Sabharwal、Samulowitz和Sellmann,2011年)。在静态算法调度中,算法根据给定的顺序执行。在动态调度中,算法序列可能基于其历史性能而改变,某些算法可能根本不会被使用。另一个有趣的未来研究方向可能是在研究ASP时考虑多种评估算法的标准,这些标准可以通过多目标视角进行建模(Kerschkeet等人,2019年)。最后但同样重要的是,表1显示出重点主要集中在基于排列和离散值表示的问题上。作为未来研究方向之一,ASP可以扩展到其他问题上,例如近年来已经开发出许多高效元启发式的不同类型的调度问题(Allahverdi,2015年)。
5、适应度评估
适应度评估是元启发式算法的关键组件之一,用于引导搜索过程朝着搜索空间的有前途的区域前进。对于一些优化问题,没有分析适应度函数来评估解决方案,甚至即使存在,计算成本也很高。机器学习技术可以集成到元启发式算法中,以减少解决此类优化问题的计算工作量,无论是通过适应度逼近(DiazManriquez、Toscano和Coello,2017;Jin,2005;2011)还是通过适应度降低(Saxena、Duro、Tiwari、Deb和Zhang,2012)。适应度逼近分为函数逼近和进化逼近(Jin,2005):
函数逼近:当使用原始适应度函数评估解决方案时,计算成本很高。在这种情况下,计算成本高的适应度函数被替换为尽可能模仿原始适应度函数行为的近似模型,同时计算成本更低。这些近似模型使用机器学习技术构建,例如多项式回归(Singh、Ray和Smith,2010)、随机森林(Zhou、Ong、Nguyen和Lim,2005)、人工神经网络(Jin和Sendhoff,2004)、支持向量机(GonzlezJuarez和Andrsperez,2019;Loshchilov、Schoenauer和Sebag,2010)、径向基函数RBFs(Oasem、Shamsuddin、Hashim、Darus和AlShammari.2013),以及高斯过程模型也称为Kriging(Knowles,2006)。
这些机器学习技术使用一组训练数据进行训练,其中输入变量是从解决方案实例中提取的特征集,输出变量是每个解决方案实例的原始适应度值。目的是近似新生成解决方案的适应度值。近似模型可以离线或在线创建。元启发式中特定用途的功能逼近称为代理辅助元启发式算法(Jin,2011),其中近似(代理)模型在搜索过程中迭代细化(即在线细化)。第一个代理辅助元启发式是为连续优化问题开发的,并且有许多有效的代理建模技术适用于连续函数(Pelamatti、Brevault、Balesdent、Talb和Guerin,2020年)。近年来,它们还吸引了许多离散优化问题(BartzBeielstein和Zaefferer,2017)。代理模型分为单精度、多精度和集成代理模型(BartzBeielstein和Zaefferer,2017)。
进化逼近是一种专门用于处理进化算法(EAs)的方法。与逼近适应度函数不同,进化逼近旨在通过逼近EAs的元素来减少计算工作量。进化逼近有两个主要子类别:适应度继承和适应度模仿。在适应度继承中,个体的适应度值基于其父母的适应度值进行计算。例如,后代的适应度值可以是其父母适应度值的加权平均值。在适应度模仿中,个体的适应度值使用其兄弟姐妹的适应度值进行计算。利用机器学习技术,如聚类技术,将种群分成几个簇,并仅评估每个簇的代表性个体。随后,根据簇中的相应代表计算其他个体的适应度值。文献中广泛使用了聚类技术来进行适应度模仿(iang、Tian、Xiao和Zhang,2020;YuTan、Sun和Zeng,2017)。
除了适应度逼近外,适应度降低是处理多目标优化问题中计算代价高昂的适应度函数的另一种方法(Saxena等人,2012年)。与逼近适应度函数不同,降低计算成本旨在通过机器学习技术(如PCA技术和特征选择技术(FS))以及使用聚类技术来减少适应度函数的数量(Lpez Jaimes、Coello Coello和Chakraborty,2008年),并通过聚类技术来减少适应度函数评估的数量(Sun、Zhang、Zhou、Zhang和Zhang,2019年;张等人,2016年)。接下来,我们首先回顾、分类和分析相关论文,然后提供相应的挑战和未来研究方向。
5.1文献分类和分析
表2根据不同的特征,如适应度评估方法、问题类型(单目标/多目标)、使用的机器学习技术、元启发式算法和研究的CoP,使用机器学习技术对COP进行适应度估值。
从表2中可以看出,很少有研究将适应度逼近/降低应用于COP。原因有两个:首先,对于大多数COP,存在一个分析适应度函数,其评估不耗费大量计算资源(Hao&Liu,2014),其次,为COP构建代理模型是一个复杂的任务,需要克服几个额外的问题才能创建准确可靠的代理模型(Pelamatti等人,2020)。
从表2中可以看出,适应度逼近主要用于计算原始适应度函数需要耗费大量时间的单目标COP(Hao、Liu、Lin和Wu,2016;Hung、Lin、Lee和Chen,2013)或使用近似适应度函数帮助搜索逃脱局部最优解(Lucas、Billot、Sevaux和Srensen,2020)。也有一些研究将适应度逼近应用于多目标COP。事实上,与单个适应度函数相比,元启发式使用多个适应度函数评估解决方案更加耗费计算资源,尤其是当目标函数过多时。
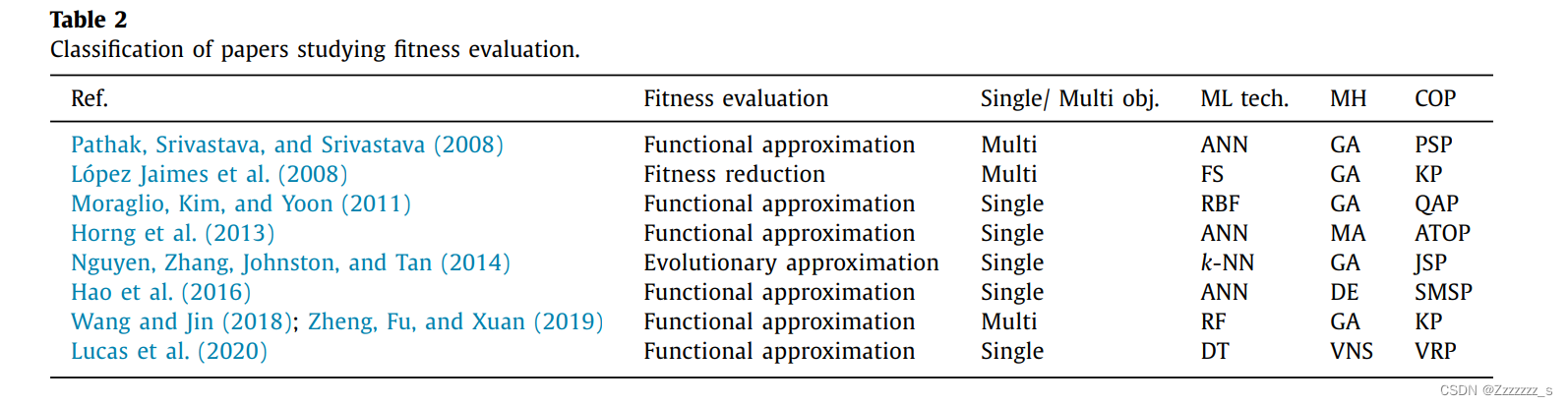
表2显示,适应度逼近/降低主要用于进化算法(如遗传算法和模拟退火算法)。主要原因是在每次迭代中,进化算法会产生并演化一组解的种群,因此在每次算法迭代中评估每个新解可能非常耗时。当每个新解的评估计算成本较高时,使用适应度逼近尤其重要(例如,使用耗时的模拟来评估一个解(Horng等人,2013))。这种需求促使开发了新的进化算法,称为辅助代理进化算法。
5.2 讨论&未来的研究方向
所有的元启发式都需要进行迭代过程来达到(接近)最优解,因此需要进行许多适应度评估以找到可接受的解决方案。适应度近似可以帮助元启发式算法显著减少计算适应度值所需的计算工作量(Jin,2005)。然而,在使用元启发式算法中的适应度逼近时,并不像人们所期望的那样简单,并且存在一些挑战。其中一个主要挑战是近似函数的准确性及其在整个搜索空间中的功能性(Jin,2005)。为了用近似函数替换元启发式的原始适应度函数,必须确保具有近似函数的元启发式算法收敛到原始函数的接近最优解。但是,由于一些问题,如训练数据数量较少和搜索空间的高维性等原因,很难构建这样的近似函数。因此,要克服这个问题的一种方法是在解决问题的过程中同时使用原始和近似适应度函数。这在文献中被称为模型管理或进化控制(Jin,2005)。
在适应度逼近方面存在的一个开放问题是如何选择最适合COPs的适应度逼近技术。答案主要取决于所研究的COP和用户偏好;然而,由于有多种逼近技术,事先选择最佳技术通常是不可能的。在这方面,首先可以尝试使用最简单的技术。如果通过最简单的技术获得的近似函数性能不佳或随时间下降,则可以使用更复杂的技术。未来的研究方向可以提供关于不同逼近技术对COPs适应度函数性能的比较研究。这些技术可能不同于简单的技术,如适应度继承或kNN,而更复杂,如多项式回归、克里金、径向基函数和聚类/分类技术(Shi和Rasheed,2010)。通常更复杂的方法提供更好的拟合精度,但需要更多的构建时间。解决这个开放问题的另一种方法是使用集成代理建模聚合多个代理模型。
除了适应度逼近,另一个值得在未来更多探索的方面是在线生成适应度。其中,根据搜索过程的状态,有针对性地设定新的目标。新的适应度函数基于当前优化问题的一些知识和在搜索过程中提取的特征来生成。例如,可以在搜索过程中提取当前COP的好解的一组代表性特征来形成新的目标,一旦元启发式算法陷入局部最优解,就用新的适应度函数替换原始适应度函数。在搜索过程中,原始和新的适应度函数可以互换以引导元启发式算法朝着有希望的解决方案前进(Lucas等人,2020年)。
另一种在线生成适应度的方法可以在元启发式算法中找到GLS(Guided Local Search),它在陷入局部最优解时修改原始适应度函数(Voudouris&Tsang,2003年)。这种修改是通过向原始适应度函数添加一组惩罚项来完成的。每当GLS陷入局部最优解时,都会修改惩罚项并继续优化转换后的适应度函数。
实时COP是指需要定期解决的问题(例如,每小时或每天),并且受到时间限制。对于这些问题,即使是元启发式的一个迭代计算时间也可能太长,无法满足实时应用的要求。因此,为了应对实时COP,特别是大规模COP,未来的一个研究方向是使用适应度逼近来降低适应度评估的计算量。
6. 初始化
为元启发式生成初始解有三种主要策略:随机、贪婪和混合策略(Talbi,2009年)。在随机策略中,会随机生成初始解,而不考虑其质量。在贪婪策略中,初始解的质量足够好。最后,混合策略结合了两种随机和贪婪策略。在使用这些策略时,总是存在一种探索和利用之间的权衡关系。事实上,元启发式的初始化方式对其探索和利用能力具有深远的影响。如果初始解没有很好地多样化,可能会过早收敛并陷入局部最优解。另一方面,从低质量的解开始可能需要更多的迭代才能收敛。在这方面,可以使用机器学习技术不仅保持解的多样性,还可以产生高质量的初始解。机器学习技术可以通过以下三大策略来帮助初始化:
完全生成 作为一个低级集成,机器学习技术可以用来代替解决方案生成策略,自行构建初始解。事实上,机器学习技术用于从空解构建完整解。这个类别中主要使用的机器学习技术是基于强化学习的技术,如QL(Khalil、Dai、Zhang、Dilkina和Song,2017年;dos Santos等人,2014年)、ANN(Bengio、FrejingerLodi、Patel&Sankaranarayanan,2020年)和反向学习(Rahnamayan、Tizhoosh和Salama,2008年)。
部分生成 作为一个低级集成,机器学习技术使用好的解决方案的先验知识来生成部分初始解。然后,可以使用任何初始化策略生成剩余部分的解。机器学习技术从先前的好解中提取知识并将其注入到新的初始解中(Li和Olafsson,2005年;Nasiri、Salesi、Rahbari、Meydani和Abdollai,2019年)。这种知识大部分以ARs(Association Rules)的形式存在,ARs描述了好解的特征。Apriori算法被广泛用于提取ARs中的规则(Li、Chu、Chen和Xing,2016年)。另一个例子是基于案例推理的想法而来的基于案例的初始化策略(Louis和McDonnell,2004年),其中初始解是根据已解决的相似实例的解生成的。
分解 作为问题级别的集成,分解要么在数据空间中进行,要么在搜索空间中进行。在数据空间分解中,机器学习技术用于将数据空间分解为几个子空间,从而通过减少所需的计算成本促进生成初始解。在这方面,每个子空间都使用任何初始化策略生成一个初始解,最终从子空间的部分解构建完整解(Ali、Essam和Kasmarik,2020年;Chang,2017年;Min、Jin和Lu,2019年)。在搜索空间分解中,机器学习技术用于在搜索空间中多样化初始解,不同的解代表搜索空间的不同区域。例如,选择要探索的搜索空间子区域的问题可以采用多臂老虎机(MAB)技术来表示,其中每个臂代表搜索空间的一个区域,该技术学习哪些区域值得进一步探索以及哪些不值得(Catteeuw、Drugan和Manderick,2014年)。
根据机器学习技术在生成初始解决方案方面的应用,学习可以在离线或在线进行。在离线学习中,知识从为一组训练实例生成的初始解决方案中收集,旨在为新的问题实例生成初始解决方案。导致更好性能的那些良好初始解决方案的属性被提取并用于为新问题实例生成有前途的初始解决方案。虽然离线学习可以提供丰富的知识,但它可能非常耗时,并且提取的知识在应用于与训练实例具有完全不同属性的新问题实例时可能不够有用。相反,在线学习在生成问题实例的初始解决方案时动态地提取和使用知识。尽管提取的知识可能不那么丰富,但它完全适合手头的问题实例。在本节其余部分中,相关论文将进行审查和分析,并提供相应的挑战以及未来的研究方向。
6.1.文献分类和分析

表3根据不同的特征对使用机器学习技术生成COPs的初始解决方案的论文进行了分类,例如初始化策略、学习机制、使用的机器学习技术、执行初始化操作的元启发式算法、研究的城市规划、离线学习情况下的训练集大小等。考虑表3,强化学习(特别是在线学习)是一种广泛用于生成完整初始解决方案的技术。在线学习可以被视为一种混合初始化策略,通过其参数平衡元启发式搜索空间的知识利用和探索能力。在线学习通过奖励矩阵逐步构建解决方案,利用搜索空间的知识。以TSP为例,在线学习从随机城市开始构建,然后使用带来最大回报的城市进行构建,其中回报代表问题的客观函数(例如,回报与当前选定城市到下一个潜在城市的距离成反比)。dos Santos等人(2014)已经表明,在线学习相对于其他典型初始化策略在解决方案质量和算法收敛率方面的优越性。
表3显示,分解策略主要用于基于路由的COPs,包括VRP和TSP。聚类算法如kmeans是这些研究中广泛使用的机器学习技术,其中城市被分组成几个组。每个组使用贪婪策略获得一个初始解决方案,最后创建连接不同组的完整路径。
6.2.讨论&未来研究方向
在将机器学习技术集成到元启发式算法以生成初始解决方案的过程中,经典的随机和贪婪策略的简单性被牺牲,以通过更先进的初始化策略(即完全生成、部分生成和分解)在探索和利用之间的权衡方面获得更好的性能。将机器学习技术集成到元启发式的初始化已经报告可以导致在比经典随机和贪婪策略更少的计算努力情况下发现更好的解决方案时,元启发式的收敛率得到提高(Ali等人,2020年;Hassanat等人,2018年;Louis&McDonnell,2004年;dos Santos等人,2014年)。这些改进在解决更大的COP实例时更加具有表现力,因为元启发式从一组好的初始解(集合)开始(Hassanat等人,2018年;dos Santo等人,2014年)。这种现象节省了在搜索过程中探索/利用更有可能的区域所需的计算精力,而不是花费大量精力寻找主要的局部(local)优秀解。
这些高级初始化策略带来了自己的挑战。一个重要的挑战是使用此类先进技术的复杂性,需要仔细调整参数以获得最高的性能。根据解决问题的方式的不同,会出现一系列其他挑战。例如,在使用强化学习时的一个重大挑战是如何定义状态和动作集,以便它们满足马尔可夫决策过程的性质。其中一个主要要求是定义一组状态,以便足以描述系统而无需达到目前为止的信息历史。以TSP为例,如果我们考虑状态为当前选定的城市,行动为下一个要添加到旅行中的城市,那么状态不足以描述系统,并且行动取决于状态历史的信息。
作为一种机器学习的新概念,并受到实体之间相反关系的启发,反向学习可以提供有效的生成初始种群的方法。使用这个概念,初始种群是从两个对立的侧面近似得到的(Rahnamayan等人,2008年),其中首先随机生成一个初始种群。接下来,基于解决方案向量值的相反种群被生成到随机生成的种群中。然后元启发式合并这两个种群并选择一半的最佳解决方案形成初始种群。反对学习的主要目的是保持初始解决方案之间的多样性以增加元启发式的探索能力。除了反向学习外,还可以使用插值技术生成初始种群。该技术尝试通过插值一组随机生成的解决方案来提供良好的解决方案。然后使用插值后的解决方案形成初始种群。因此,使用这些技术和像ANNs(Yalcinoz&Altun,2001年)这样的其他先进的机器学习技术来生成COP的初始解决方案可能是未来的研究方向。
7. 进化
机器学习技术可以以三种主要方式整合到进化过程中:
机器学习技术有助于在搜索过程中使用操作性能的反馈信息来选择最合适的操作(见第7.1节)。
机器学习技术提供了一种学习模式,用于生成EAs中的新种群(见第7.2节)。
机器学习技术有助于提取优秀解决方案的属性,以生成新解决方案(见第7.3节)。
7.1. 操作选择
操作选择源于超启发式。超启发式可以被定义为探索低级别启发式搜索空间(即邻域或搜索操作)或启发式组件以解决优化问题的高级自动搜索方法论(Burke等人,2013年)。关于启发式搜索空间的性质,超启发式可分为启发式选择和启发式生成方法论(Drake、Kheiri、Ozcan和Burke,2019年)。前者旨在在一组启发式中进行选择,而后者旨在生成新的启发式。操作选择本质上属于超启发式的启发式选择方法论;然而,它也被用于设计元启发式算法(Mosadegh等人,2020年;dos Santos等人,2014年)。因此,这导致了文献中对涉及操作选择的元启发式算法与超启发式的区分程度存在一定程度的混淆。尽管超启发式和元启发式的设计与性能之间存在差异,但两种方法中的操作选择都旨在实现相同的目标,即在搜索过程中选择和应用适当操作。
本文的重点是涉及操作选择的元启发式算法。在这方面,已经开发出一种名为自适应大邻域搜索的元启发式,是对经典大邻域搜索的扩展,其特定目的是在搜索过程中选择操作(Turkes、Srensen和Hvattum 2020年)对自适应大邻域搜索元启发式进行了元分析。
除了自适应大邻域搜索之外,本文还关注其他类型元启发式中的操作选择。操作选择的主要动机来自于以下事实:单个操作可能在搜索过程的某些阶段特别有效,但在其他阶段表现不佳。事实上,COPs的搜索空间是一个非静态环境,包括具有不同特征的不同搜索区域,其中不同的操作(或同一操作的不同配置)表现出不同的行为,并且只有一组它们在每个区域内工作良好(Fialho,2010)。使用单一操作解决COPs并不能保证在寻找(接近)最优解时获得最高性能。因此,合理地期望在搜索过程中以适当的方式结合使用不同的操作会产生更好的解决方案。通过设计具有多个搜索操作符的超启发式或元启发式,我们可以在搜索过程中利用具有不同性能的几个操作符之间的切换优势。此外,不同操作符的适当实现显著影响元启发式的探索和利用能力,并在搜索过程中提供探索-利用平衡。在设计此类算法时,有两个重要的决策需要做出:1)哪一个操作符(在多个操作符中),以及2)在搜索过程的每个阶段选择和应用哪些设置。前者在本节中讨论,后者将在第8节中解释。
搜索操作符被分为四种:变异/扰动操作符(MPOs)、重构/重建操作符(RROs)、局部搜索或爬山操作符(LSOs)和交叉/重组操作符(XROs)类别(Ochoa & Burke,2014;Talbi,2009)。机器学习技术有助于选择操作符,并使用反馈信息来评估其性能。在这种情况下,操作符根据分配给每个操作符的信用(即历史性能的反馈)进行选择。考虑到反馈的性质,学习可以是离线或在线的。在离线学习中,机器学习技术如基于案例推理(BurkePetrovic,& Qu,2006)帮助以规则的形式从一组训练实例中收集知识,以便在新的问题实例中选择操作符。然而,在线学习中,知识在解决问题实例时动态提取和扩展(Burke等人,2019;Talbi,2016)。使用搜索环境的在线反馈来动态选择和应用最合适的操作符的过程被称为自适应操作符选择(AOS)(Fialho,2010)。AOS旨在在解决问题实例的过程中选择每个搜索过程阶段的最合适的操作符。AOS使元启发式行为能够适应搜索空间的特征,通过在搜索过程中根据其历史性能选择它们的操作符。AOS包括五个主要步骤:
绩效指标识别:每当选择并应用于一个问题实例的操作符时,都可以收集表示该操作符性能的一组反馈信息。这种反馈可以是不同的绩效指标,如OFV、解的多样性(DOS)、CT和局部最优解的深度(DLP)。操作符的信用高度取决于如何识别和评估绩效指标。这使得绩效指标识别成为AOS的重要步骤。因此,在解决CoPs时,应有效识别和整合绩效指标(如果有多个指标),以引导元启发式朝着最优解前进。
奖励计算:一旦确定了绩效指标,此步骤将计算每个操作符的应用如何改善或恶化绩效指标。
信用分配:在此步骤中,基于奖励计算步骤中所计算的奖励,向操作符分配信用。存在不同的信用分配方法,如表4所示,包括基于分数的信用分配(SCA)(Peng、Zhang、Gajpal和Chen,2019)、基于Q-Learning的信用分配(QLCA)(Wauters、Verbeeck、De Causmaecker和Berghe,2013)、基于指南针的信用分配(CCA)(Maturana、Fialho、Saubinon、Schoenauer和Sebag,2009)、基于学习自动机的操作符信用分配(LACA)(Gunawan、Lau和Lu,2018)以及基于极端值的操作符信用分配(EVCA)(Fialho,2010)等。

选择:一旦为每个操作员分配信用,AOS选择在下一轮迭代中应用的操作员。表5所示不同的选择方法包括随机选择(RS)、最大信用选择(MCS)、转盘赌选择(RWS)(Gunawan等人,2018年)、概率匹配选择(PMS)(Fialho、Da Costa、Schoenauer和Sebag,2008年)、自适应追求选择(APS)(Fialho等人,2008年)、SoftMax选择(SMS)(Gretsista和Burke,2017年)、Upper Confidence Bound MultiArmed Bandit Selection (UCBMABS)(Fialho等人,2008年)、Dynamic MultiArmed Bandit Selection(DMABS)(Maturana等人,2009年)、Epsilon Greedy选择(EGS)(dos Santos等人,2014年)和基于启发式的选择(HS)(Choong、Wong和Lim,2018年)。

接受移动:在应用操作员后,AOS决定是否接受该操作提供的移动。不同的移动接受方法包括所有移动接受(AMA)、只有改进接受(OIA)、朴素接受(NA)、阈值接受(TA)、Metropolis接受(MA)(Metropolis、Rosenbluth、Rosenbluth、Teller和Teller,1953年)、概率更差接受(PWA)、模拟退火接受(SAA)(Mosadegh等人,2020年)和晚期接受(LTA),见表6。

7.1.1.文献分类分析
表7根据不同特征对研究COP的AOS(自适应操作符选择)进行分类,例如性能标准、信用分配方法、选择方法、移动接受方法、元启发式算法、要选择的操作类型和Cop研究。
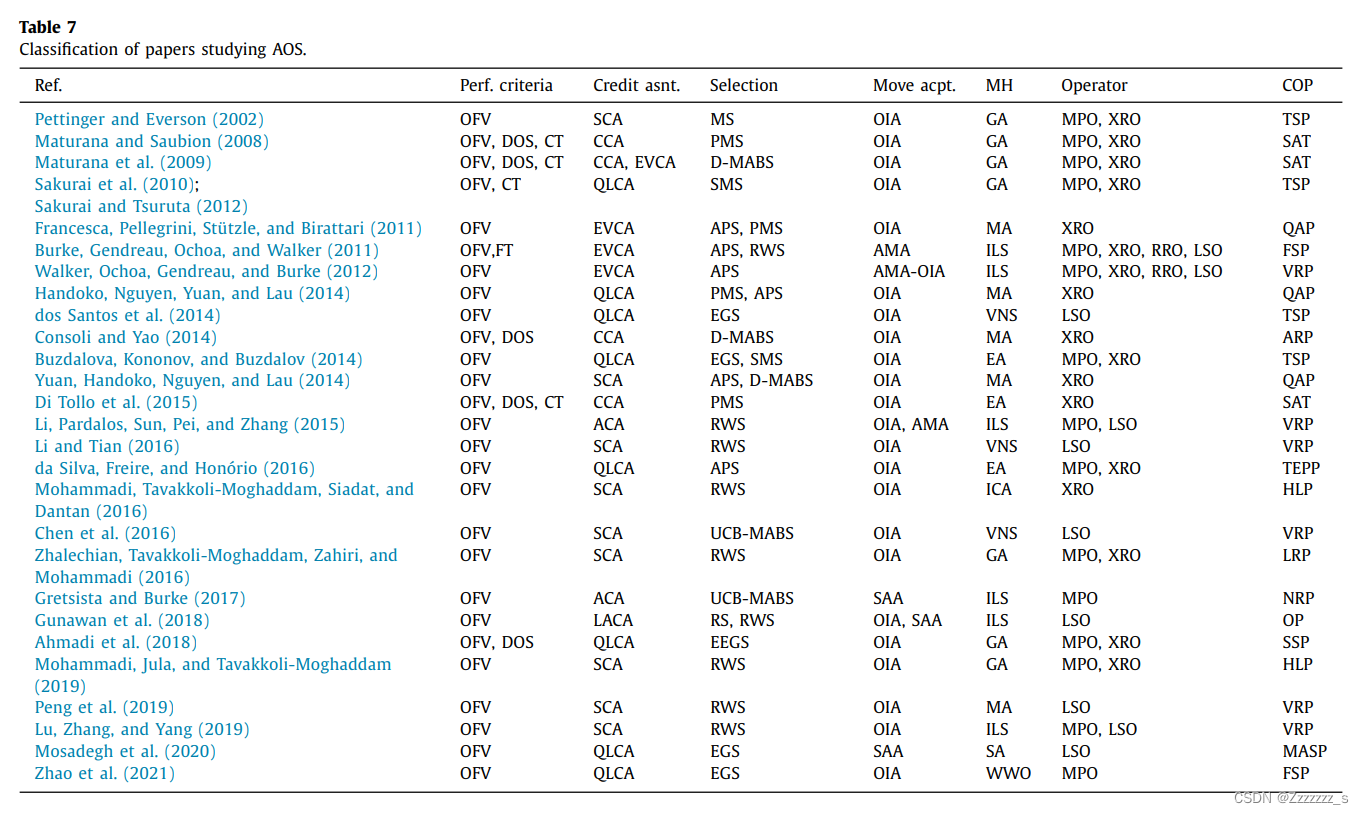
考虑到性能标准,表7表明,所有审查过的论文都使用OFV作为评估操作的标准。同时,只有少数论文将CT和DOS等其他标准纳入其评估过程中(Di Tollo、Lardeux、Maturana和Saubinon,2015; Maturana等人,2009年;Maturana和Saubinon,2008年; Sakurai、Takada、Kabe和Tsuruta,2010年; Sakurai和Tsuruta,2012年)。尽管OFV是最简单的评估操作的标准,但DOS也必须使用以避免过早收敛(Di Tollo等人,2015年)。
通过查看表7,可以看出在信用分配方法中,基于RL的方法(例如,简单的SCA和QLCA)已经被广泛研究。在所研究的信用分配方法中,ACA方法偏向于保守策略。事实上,使用该方法时,更经常有小改进的操作优于罕见但有高改进的操作。尽管ACA方法如此,EVCA方法假设罕见但高改进比频繁但适度更重要(Fialho等人,2008年)。使用EVCA方法时,操作根据他们在最后W次应用中的最大改进获得信用。为了避免过早收敛,CCA方法将其评估过程纳入了DOS。该方法考虑了OFV和DOS,它们分别与元启发式算法的利用和探索能力相关。ACA、EVCA和CCA方法根据操作的即时表现(通过最后W次应用)为其分配信用。这可能会导致优化过于短视。另一方面,包括SCA、QLCA和LACA方法在内的RL基础方法根据操作从第一次应用开始的表现为其分配信用。事实上,它们能够学习一种最大化长期收益的政策,这使得获得最优操作员选择策略成为可能。除了长期展望外,一些RL基础方法如QL是无模型的,不需要完整的系统模型,包括每个状态动作对的转移概率矩阵和每个状态动作对的期望奖励值。这对于COPs尤其有用,因为通常情况下无法获得完整的系统模型(Wauters等人,2013年)。此外,许多RL基础方法能够在几种条件下收敛到最优状态动作对。其中,QL已经证明在三种条件下可以收敛到最优状态动作对:系统模型为马尔可夫决策过程、每个状态动作对被访问多次、立即给予的每个行动奖励不是无限制的(即有限于某些常数)(Watkins,1989年)。在表7中的RL基础方法中,基于时间差异的技术如QL利用了延迟奖励的概念。它们基于这样的假设:一个行动的效果可能不会立即出现。因此,它们将延迟奖励与立即奖励一起考虑。另一方面,LACA方法(Gunawan等人,2018年)和SCA方法(Chen、Cowling、Polack& Mourdjis,2016年)仅在一个单一的状态环境中工作,只考虑立即奖励。
选择步骤决定在下一迭代中应用哪个操作符。该步骤也可以视为探索与开发之间的权衡,即需要在选择迄今为止表现最好的操作符(即开发)和给其他操作符一个机会,它们可能会带来更好的性能(即探索)之间进行取舍。图4说明了不同选择方法如何平衡元启发式的方法的探索和开发能力。对于每种选择方法,负责使这种平衡的参数及其对应效果也已确定。例如,在APS方法中,增加参数和
会增强该方法的探索能力,而减小参数
和
则会增强该方法的开发能力。

如图4所示,MCS(Max Credit Selection)方法是一种纯粹的探索方法,没有探索其他操作符的机会。换句话说,MCS方法在每次迭代中选择信用最高的操作符,不给其他质量较低的操作符被选择的机会。RWS(Roulettewheel Selection)方法基于操作符的比例信用进行选择,这也为所有操作符提供了被选择的机会。然而,使用RWS方法时,长期表现不佳的操作符几乎没有或甚至零被选中的机会,而它们可能在搜索过程的后期表现出色。为了解决这个问题,PMS(Probability Matching Selection)方法为每个操作符分配了一个最小的选择概率,无论其性能如何。这通过保持最小程度的探索来维护探索与开发的平衡,并在整个搜索过程中保持固定的最小探索水平。实际上,具有零信用的操作符的选择概率逐渐接近
。这样,即使中等性能的操作符也会被选中,从而降低了该方法的性能(Maturana等人,2009年)。为了解决这个缺点,所提出的APS(Adaptive Pursuit Selection)方法使用赢者通吃策略更新选择概率。实际上,APS方法不仅根据操作符的比例信用更新概率,而且还会增加最佳操作符的选择概率,同时降低所有其他操作符的选择概率。这旨在快速提高当前最佳操作符的应用概率(Fialho,2010年)。考虑到探索与开发的权衡关系,该方法通过
保持最低程度的探索水平,并在整个搜索过程中保持固定的最小探索水平。
在SMS(SoftMax Selection)方法中,通过温度参数t控制探索与开发之间的平衡。当温度增加时,所有操作符的选择概率趋于相等。而降低温度则导致选择概率之间的差异变大。从极端观点来看,当温度降至零时,SMS成为一种纯粹的利用方法,只选择最好的操作符。UCBMABS(Upper Confidence Bound MultiArmed Bandit Selection )方法也通过

(一个缩放因子)来控制元启发式算法的探索和开发能力,其中G保持每个被选择的操作符的最小选择概率。类似地,EGS(Epsilon Greedy Selection)方法使用预定义参数e来控制探索和开发的权衡关系。增加e会增加算法的探索能力,给其他操作符提供被选择的机会,而减少e则有利于选择最好的操作符。因此,当e=1时,EGS方法成为一种纯粹的探索方法。最后,HS(Heuristicbased Selection)方法使用启发式规则来选择操作符。例如,规则可以是一个禁忌列表,在某些迭代次数内排除成功的操作符不被选中。禁忌列表的大小在探索和开发之间取得平衡。随着禁忌列表的增大,成功的操作符在禁忌列表中停留的时间更长,给其他操作符选择的机会,从而使该方法朝着探索方向发展。表7表明AOS主要应用于EAs(如GA和MA)以选择突变和交叉操作符。这可能是因为EAs在解决COPs方面的流行度以及问题特定突变和交叉操作符的可用性,这些需要在搜索过程中仔细选择,因为EAs的性能受到其操作符的影响。与此同时,AOS还应用于ILS和VNS中的局部搜索操作符的选择。
7.1.2 讨论与未来研究方向
在本节中,首先提供了研究人员何时使用AOS的指南,并确定了使用AOS的基本要求。接下来,讨论了挑战和未来的研究方向。
选择和应用这些元启发式中的特定操作符(启发式)以高效解决优化问题的数量和种类不断增加。在元启发式中选择和应用这些操作符需要对该领域的专业知识。特别是对于已经提出了大量特定操作符的问题,其中常规操作符不如特定操作符能力更强。事实上,对于具有标准表示(例如排列表示)的COP,用户可以利用非专用经典操作符,这并不一定需要很多专业知识。然而,对于超出该标准框架的COP,必须对特定操作符有足够的知识才能有效地选择操作符。这个问题突出了自动选择最合适的操作符(基于其性能而不需要在该领域具备专业知识)的必要性。这样,即使是没有经验的用户也能够为解决COP选择适当的操作符。此外,当处理多个竞争性的高级操作符来解决COP时,AOS最有用,因为它们无法在事先被偏好于其他操作符,并且穷尽地选择最佳操作符是计算上昂贵的。在这种情况下,需要自动选择操作符。
作为AOS中最常用的基于RL的方法之一,QLCA方法有一些特定的需求。在将QLCA方法应用于AOS之前,需要定义可能的状态和动作集合。在定义状态时,应检查以下先决条件:
~状态应该完全描述问题状态以便选择正确的动作。有三种定义状态的方法。状态可以是1)搜索相关的,反映搜索过程的属性,如无改进迭代次数;2)问题相关的,通过通用特征反映问题的属性;3)实例相关的,反映问题实例的属性,如装箱问题中的箱子数量(Wauters等人,2013)。
~状态应以不呈指数增长的方式定义,并允许算法多次访问每个状态-动作对。这是CA方法收敛的主要条件之一。例如,如果状态随问题规模呈指数增长,则算法可能需要执行更多次以满足收敛条件。
将机器学习技术集成到AOS中已导致解决方案质量和甚至计算时间方面的改进。使用AOS中的先进机器学习技术(如QLCA Ahmadi、Goldengorin、Sier、Mosadegh等人,2018年;Mosadegh等人,2020年;赵、张、曹、汤等人,2021年)和LACA(Gunawan等人,2018年)等技术与元启发式相比带来了显著的改进。此外,对于某些COPs甚至获得了新的已知最优解(Ahmadi等人,2018年;Gunawan等人,2018年)。更有趣的是,这种集成据报道随着问题实例的大小增加更加高效,而且所提出的元启发式在解决更大的COP实例时表现出更稳定的行为(dos Santos等人,2014年;赵等人,2021年)。
除了AOS应用带来的优势,这方面也出现了一套重要的挑战。第一个挑战与元启发式学习的计算开销有关。虽然AOS通过在搜索过程中选择操作符来给用户灵活性,使其能够适应元启发式行为的特点,但实现这种灵活性会增加额外的计算开销。在搜索过程中跟踪操作符的性能、分配学分以及更新它们的选择概率都会产生额外的计算开销。可以通过优化AOS机制来补偿这些开销,使元启发式更快地收敛到(接近)最优解,从而节省计算时间弥补额外的开销。
另一个挑战与AOS参数的调整有关。大多数学分分配和选择方法引入了需要在应用AOS之前进行调整的新参数。调整这些参数的值可以显著影响AOS的性能,因此需要仔细调整。例如,在QLCA方法中,有两个新参数:学习率()和折扣因子(
)。前者控制接受新学到的信息的比例,后者控制未来奖励的影响。较高的
值倾向于用新信息替换旧信息;较低的
值则强调现有信息。此外,随着
值的增加,未来奖励相对于即时奖励的重要性更大。
当调整一组负责平衡元启发式探索和利用能力的参数时,这一挑战变得更加关键,因为它们直接控制元启发式的行为并影响AOS的性能。一种克服这一挑战的方法是使用第8节中解释的参数设置方法,其中元启发式的参数可以在离线或在线方式下进行调优。迄今为止,几乎所有论文都将这些参数视为搜索过程期间固定的,但可以根据搜索空间的特征进行动态调整。因此,在AOS中采用在线参数控制方法(见第8节)可能是有前途的未来研究方向。
AOS中的另一个挑战与涉及的操作符数量有关。增加操作符的数量可能会降低AOS的性能。随着操作符数量的增加,执行AOS所需的成本也会增加,从而对AOS施加更高的开销。此外,如果某些操作符表现不佳,AOS的性能可能会下降,并且长期来看,它们将被选择得越来越少。这些操作符的存在增加了没有明显收益的计算开销。一个克服这一挑战的方法是使用自适应操作符管理(AOM),其目的是通过排除低效的操作符并将其他操作符包含在AOS中来管理搜索过程中的操作符(Maturana等人,2011年)。作为未来研究方向,可以在AOS中进一步研究AOM的使用。
另一个有前途的研究方向是将AOS应用于多目标COP中,其中同时评估几个目标。在这方面的问题是如何为改进一个目标函数但降低其他目标的优化器分配奖励。此外,将多个奖励整合到每个优化器所获得的单一信用值中也是需要解决的问题。一种应对这些问题的方法是将拥挤距离以及非支配前沿的排名纳入计算奖励/信用的考虑范围。
7.2. 可学习进化模型
达尔文类型的EA(例如遗传算法)受到达尔文的进化理论的启发。它们应用常用的遗传操作符,如变异、交叉和选择来生成新的种群。这些半随机的操作符,即进化过程的控制者,不考虑单个解决方案的经验,也即整个种群或多个种群的经验。因此,新解是通过并行试错过程生成的,因此在这类元启发式中无法利用过去几代的经验教训。为了克服这些效率低下的问题,已提出了一种新的EA类——可学习进化模型(LEMs)(Michalski, 2000)。与包含达尔文进化模式的达尔文类型EA相反,LEM包含一个学习模式,在其中使用机器学习技术生成新的种群。在学习模式中,学习系统通过特定的机器学习技术(例如AQ18和AQ21规则学习、C4.5决策树等)寻求特定解决方案(或过去种群集合中的一些解决方案)相对于其他解决方案在执行指定类别的任务方面更优秀的原因(规则)。
具体而言,LEM的学习模式包括两个过程(Michalski, 2000;Wojtusiak, Warden和Herzog, 2011):
假设生成-它确定了一组假设,这些假设描述了最近或以前种群中高适应性和低适应性解决方案之间的差异。
假设实例化-它根据在假设生成过程中获得的学习假设生成新解决方案。因此,学习模式通过涉及关于解决方案群体的假设的生成和实例化的过程产生新解决方案,而不是通过半随机达尔文类型操作。
对于假设生成过程,每次迭代中都会从种群中选择两个组(集合)的个体:高性能组,简称H组和低性能组,简称L组,基于适应度函数的值。H组和L组解决方案的收集可以是种群的一个子集,也可以涵盖整个种群(Michalski,2000)。可以使用两种方法形成H组和L组(Michalski,2000):
基于适应度的分组(FBF):在这种情况下,种群根据两个适应度阈值进行划分,即高适应度阈值和低适应度阈值。这些阈值以百分比表示,并确定种群总适应度值范围内的高和低部分。这些部分随后用于形成H组和L组的解决方案。实际上,适应度值不劣于种群最佳适应度值的百分比的解决方案形成H组,而适应度值优于种群最差适应度值的百分比的解决方案形成L组。当使用基于适应度的分组方法时,H组和L组的大小会因种群而异,因为它取决于每个迭代中解决方案的适应度值范围。
基于种群的分组(PBF):在这种方法中,H组和L组根据作为种群中解决方案数量百分比表示的两个阈值形成。这些阈值被称为高种群阈值%的最佳解决方案形成H组,而低种群阈值%的最差解决方案形成L组。
上述两种方法可以应用于整个种群作为一个全局方法,或者可以应用于种群的不同子集作为一个局部方法。局部方法背后的思想是,种群中的不同解决方案可能携带不同的信息,没有一个全球信息可以描述整个种群。一旦H组和L组形成,就会使用机器学习技术生成区分这两个群体的定性描述(Michalski, 2000)。H组的定性描述表示H组所覆盖的地形包含比L组更具有高适应度值的解决方案。因此,H组的定性描述可以解释为朝着有希望的区域搜索的方向。LEMs通过这种定性描述来指导进化过程,而不是依赖于半盲目的达尔文进化操作符。这样的智能进化在LEMs中导致了对进化方向的正确检测,从而使个体的适应度值有了大幅提高。
文献中有两篇关于LEM的文章(Michalski2000):单LEM和双LEM。在单LEM版本中,进化过程仅通过学习模式进行,而在双LEM版本中,达尔文和学习进化过程相结合。
7.2.1.文献分类&分析

本节将根据LEM用于解决COP的相关特征对相关文献进行分类和分析。表8根据LEM的设计和实施相关的不同特征对相关研究进行了分类,包括假设生成、假设实例化、群体形成、单LEM/双LEM进化版本、元启发式算法和正在研究的问题。可以从表8中提取一些见解。在假设生成方面,LEM的学习模式可以潜在地采用不同的学习技术来生成区分种群中不同个体类别的描述(即H组与L组之间的差异)。如果个体被描述为一组值(例如TSP中的城市排列数或FSP中的工作数),则可以使用诸如AO学习器(Domanski,Yashar,Kaufman&Michalski,2004;Kaufman&Michalski,2000;Moradi,2019;Wojtusiak等人,2011;2012)和决策树学习器(如C4.5(lourdan,Corne,Savic&Walters.2005;Jung,Kang&Kim,2018))等规则学习技术来进行描述。从表8可以看出,AQ学习器是一种最适合实现LEM的学习系统,其中学习系统利用某种形式的AO算法。
关于假设实例化,可以发现大多数研究都使用规则注入机制,其中调查H组和L组个体的强度和弱点都是基于规则进行描述。以TSP为例,经常出现在H组个体中的部分城市序列可能是一个规则,并可以使用这种规则通过注入常见序列来创造新解决方案来进化种群。然而,由于当前问题在解决方案结构和H组和L组个体的描述特征方面的复杂性,学习程序使用不同个体的抽象而不是精确规范(Jourdan等人,2005;Jung等人,2018)。因此,所学到的规则也被称为个体的抽象。系统可以在许多方面实例化这些抽象规则,以生成进一步种群中的新解决方案。但是,规则实例化过程必须遵循手头COP的约束。
7.2.2.讨论&未来的研究方向
本节确定了实现LEM解决优化问题,特别是COP的挑战。在整个讨论中,未来研究的方向也被详细阐述。
考虑到表8中的群体形成,实施LEM以及创建H组和L组时采用基于适应度的形态需要有一个要求和一个重要的挑战。事实上,LEM背后的基本假设是存在一种评估群体中个体性能的方法。因此,确定个体或此值的近似值的能力是LEM应用的前提条件。因此,对于无法定义或甚至无法近似适应度函数的COP而言,LEM无法实现。
与基于适应度的形成相关的挑战可能发生在某些特定的COP中,即在某些进化过程中,适应度函数可能不是整个过程中始终不变的,而是随时间变化。这发生在某些特定的COP中,其中参数以分段方式依赖于决策变量级别的变化。适应度函数的变化可能是渐进的(即适应度函数漂移)或突然的(即适应度函数偏移)(Michalski,2000)。实际上,如果适应度函数在进化过程中发生变化,那么以前某个种群中的一些高适应度个体(即H组)可能会在未来种群中变成低适应度个体(即L组),反之亦然。
克服这个挑战的一种方法是记录过去种群中确定的L组而不是仅当前种群中的L组。因此,一组过去L组加上当前种群中的L组成为实际提供给学习模式的L组。考虑过去的L组的数量由一个参数控制。值得一提的是,没有必要存储过去的H组,因为当前的H组本质上包含了迄今为止最好的个体。通常情况下,从当前种群中形成的H组和L组忽略了进化的历史(Michalski,2000)。
使用基于种群的形态可能发生的问题是H组和L组之间可能存在交集。在生成假设之前应解决此问题。可以使用简单的方法来处理此类问题,例如忽略不一致的解,包括将不一致的解包含在H组或L组中,或者使用统计方法来解决不一致性(Michalski,2000)。关于将LEM与达尔文进化模式耦合的方式,有研究论文(Domanski等人,2004年;Wu和Tseng,2017年)将学习模式置于达尔文进化模式之前。另一方面,LEM可以从达尔文进化模式开始(Wojtusiak、Warden和Herzog,2012年),然后两个模式交替执行,直到LEM终止准则得到满足。
经常提到的是,将机器学习技术提供的判别描述纳入EA显著加速了朝着有希望的解决方案的搜索过程。这种加速表现为频繁的适应度函数量子跃迁,表明发现了进化过程的正确方向。然而,这种进化加速对搜索过程的计算复杂度施加了更高的负担。这种额外的复杂性主要取决于使用的机器学习技术因此,采用高效的机器学习技术和AQ算法的并行实现可以降低复杂性。其中后者可以将复杂性从线性降低到对数级别。
尽管使用LEM解决COPs的初始结果很有前途,但仍然有许多未解决的问题需要进一步研究。未来研究的方向应该是进行大量的系统理论和实验实施LEM以更好地了解LEM与达尔文进化模式之间的权衡关系。在COPs中,LEM主要应用于路由问题(如TSP、VRP)和设计问题(如HEDP、WDSDP)。因此,感兴趣的研究人员的第二个重要的未来研究方向是在其他COPs上实施LEM,以确定LEM和达尔文进化模式的优势、劣势和限制,并确定它们最适用的应用领域。
7.3. 邻域生成
在选择第7.1节中最合适的操作符之后,现在就是使用所选的操作符从当前解决方案中生成邻域的时候了。邻域的一种简单方法是生成所有可能的邻域并选择具有最佳OFV的邻域。另一种方法是随机生成邻域。然而,考虑到计算时间以及引导搜索过程朝着搜索空间中的有希望区域的目标,这两种策略可能并不是非常高效。为了尽可能高效地工作,可以使用机器学习技术通过从到目前为止生成的好解中提取知识来利用好邻域的生成。
实际上,使用机器学习技术,我们可以从好解中发现经常出现在搜索过程中或搜索前的好解的特征,并利用这些知识通过固定或禁止特定解特征来生成具有相同特征的新解。这样,我们可以引导搜索朝着搜索空间中的有希望区域前进,加快找到好解的过程。通常,这种知识以一组规则或模式的形式发现(Arnold、Santana、Sorensen和Vidal,2021)。这个过程由两个阶段组成:知识提取和知识注入(Arnold等人,2021)。在知识提取中,发现的好解中的共同特征被提取出来。然后,在知识注入中,提取的知识用于生成邻域。当知识表现为一组模式时,最好用的好解中的最常见模式注入到新解中以生成邻域。
知识提取阶段可以在线或离线进行。在离线提取中,知识从一组训练实例中提取出来,旨在为新实例生成良好的解决方案。然而,在在线提取中,知识是从搜索过程中获得的好解中提取出来的,同时解决问题实例。邻居生成中最常用的机器学习技术是针对ARs、RL和DT的Apriori算法。
7.3.1. 文献分类&分析

表9根据不同的特征(如学习机制、用于提取知识的机器学习技术、执行搜索过程的元启发式算法、生成新邻域的操作符、研究的Cop和使用离线知识提取的研究的训练集大小)使用机器学习技术对论文进行分类。如表9所示,几乎所有审查过的论文都使用了在线方式以模式的形式提取知识。事实上,当处理具有未知特征的新实例时,最有效的方法是在线提取模式。在线模式提取的优势是避免了在离线方式下可能产生的误导性模式,这些模式可能无法正确表示新问题实例的良好解的特征;然而,在线模式提取的计算开销不应被忽视。
7.3.2. 讨论未来研究方向
本节讨论了应用机器学习技术进行邻居生成的要求和挑战,然后提出了一些未来研究方向。使用ARs的最重要要求之一是数据可用性。实际上,在提取模式时,拥有足够多的优秀解是不可或缺的,因为提取出的模式的准确性直接取决于是否有足够的数据可用。数据可用性越高,提取出的模式的精度和有用性就越高。
邻域生成的第一个挑战是确定应在搜索过程的哪个阶段提取知识以生成新的邻域。这个挑战有两个方面:首先,在搜索过程的开始阶段,改进较大,优秀解集经常发生变化,因此无法从优秀解集中提取精确的模式。因此,应在经过一些迭代之后提取知识。其次,如果将知识注入到搜索过程的早期阶段的邻居生成过程中,会阻止元启发式算法探索搜索空间的不同区域,并可能导致过早收敛到局部最优解。第二个挑战与应更新并注入新邻居的提取模式的频率有关。实际上,可以在搜索处理器更新时识别一次模式并在整个搜索过程中用于邻居生成,但随着时间的推移,最好解集经常根据最新信息更新模式。模式提取可能是一个耗时的过程,这会增加搜索过程的计算成本。因此,在基于搜索过程的最新信息的准确模式之间以及模式提取过程的计算开销之间存在权衡。
另一个挑战是在好解中存在多个模式且有许多可能性将其注入到新解中(即单独或组合注入模式)。没有保证将多个单个模式组合在一起也能提供良好的解决方案(Arnold等人,2021年)。换句话说,尽管许多单个模式可能在大量优秀解中出现,但它们的组合不一定会产生更好的甚至良好的解决方案。例如,在基于排列的表示中,边AB和CD可能分别出现在好解中,但没有保证边AB和CD同时导致一个良好解。
除了之前提到的所有挑战,最后一个也是最重要的是关于使用提取的知识生成新解决方案的比例的决定。这种比例的程度会影响元启发式算法的探索和利用能力。如果几乎所有的解决方案都是基于以前的知识生成的,那么元启发式算法倾向于主要利用当前观察到的领域。另一方面,如果基于以前知识生成的小比例的解决方案,则算法有机会探索搜索空间的新领域。因此,用户在决定基于提取的知识生成的解决方案的比例时必须考虑算法的探索和利用能力。
根据表9,大多数使用ARs的研究都试图识别良好解决方案的特征。一个研究方向可能是使用ARs来识别需要从新解决方案中删除的不良解决方案的特征。然后,这个知识可以仅仅用来避免不良解决方案,或者它也可以用来补充良好的解决方案的模式。此外,文献中的大多数论文都使用了良好解决方案的知识来利用搜索空间中最有希望的领域,同时还应该考虑到搜索过程的探索方面。一种方法是从访问过的解决方案中提取罕见模式并将其注入到新解决方案中以生成远离迄今为止访问过的所有解决方案的新解决方案。
8. 参数设置
任何元启发式算法的成功都显著地依赖于其参数值(Talbi,2009)。由于参数控制算法在搜索过程中的行为,因此应适当设置参数值以获得最高的性能。尽管文献中对相似的问题实例的参数值提出了一些建议,但它们不一定是解决手头问题实例的最适当的设置(Wolpert&Macready,1997)。实际上,参数设置不是一次性任务,研究人员需要在解决新问题实例时设置算法的参数(Huang,Li,&Yao,2019)。参数设置也称为算法配置(Hoos,2011),分为两个类别:参数调整和参数控制(Eiben,Hinterding,&Michalewicz,1999)。
参数调整也称为离线参数设置,在将算法应用于解决手头的问题实例之前确定适当的参数水平。在这种情况下,执行算法期间参数级别保持不变。可以使用不同的方法进行参数调整,例如暴力实验(Phan,Ellis.Barca,&Dorin,2019)、实验设计(DOE)(Talbi,2009)、竞速程序(Huang等人,2019)和元优化(Talbi,2009)。
参数控制,又称在线参数设置,专注于在算法执行期间调整算法的参数水平,而不是使用在整个执行过程中保持不变的最初精细调整的参数。基于观察到对参数进行调优并不一定保证元启发式的最佳性能的事实,已经开发了基于不同阶段搜索过程的不同设置的参数可能合适的参数控制方法(Aleti,2012)。这归因于优化问题的非静态搜索空间导致元启发式的动态行为,它需要从全局搜索模式演变为需要适合探索搜索空间的参数值的局部搜索模式,以及需要适合利用邻域的参数值。参数控制可以以三种方式进行(Karafotias,Hoogendoorn和Eiben,2014);确定性的方式,使用给定的时间表调整参数级别(例如,预定义的迭代次数),而没有来自搜索过程的反馈;自适应的方式,使用来自搜索过程的反馈调整参数级别,其中根据其性能分配信用;自适应的方式,将参数级别编码到解决方案染色体中,并在搜索过程中演化。
机器学习技术可以在参数调节和参数控制中得到应用。在参数调节中,机器学习技术如LogR(Ramos、Goldbarg、Goldbarg和Neto,2005)、LR(Caserta和Rico,2009)、SVM(Lessmann、Caserta和Arango,2011)和ANN(Dobslaw,2010)用于根据一组训练实例预测给定一组参数的性能。在参数控制中,机器学习技术可参与自适应参数控制,帮助通过搜索过程中关于参数级别的性能信息的反馈来控制参数级别。机器学习技术的集成与AOS(第71节)类似,其中使用反馈将参数级别调整到搜索空间。它也涉及四个主要步骤(除了Move Acceptance步骤):1)性能标准识别、2)奖励计算、3)信用分配和4)选择,这些已在第7.1节中详细解释。
8.1.文献分类和分析

本节旨在对在元启发式参数设置中使用机器学习技术的研究进行分类、审查和分析。在这方面,表10根据不同的特征对论文进行分类,包括参数调节/控制、使用的机器学习技术、信用分配和选择方法、设置参数的元启发式、要设置的参数、研究的COP以及研究参数调节的论文的训练集大小。
从表10可以看出,在解决CoP时,相对于参数调节,参数控制受到更多的关注。事实上,主要原因是固定参数值不一定保证元启发式在整个搜索过程中的最佳性能。其根本原因是本节开头所述的搜索空间的不稳定性。从一般的角度来看,元启发式的性能显著取决于其探索和利用搜索空间有前途区域的能力,而元启发式的探索和利用能力取决于其参数水平。以GA为例,交叉和变异率应该根据算法的性能和搜索空间的性质而改变。例如,一旦发现有前途的解决方案,就应该仔细地利用它。因此,交叉和变异率应该相应地降低和增加。另一方面,当算法陷入局部最优解时,变异率可以增加以帮助解决方案逃脱局部最优解。
根据表10,基于RL的机器学习技术在搜索过程中控制参数时被广泛采用。其根本原因是RL代理通过与其环境的交互迭代地学习采取最大化奖励的行为。在参数设置方面,可以定义一组不同的配置作为一组行动,每次提供更好的解决方案时都会分配奖励给该配置集。事实上,在搜索过程开始时,所有可能的配置集具有相同的被选中的概率。在搜索过程中,这些概率可以根据它们创建更好解决方案的成功程度而改变(Andre&Parpinelli,2014)。文献报道称,在搜索过程的前几个阶段中,每个配置集的选择概率比后几个阶段更经常地发生变化。这是由于搜索过程中发生的多样性损失所解释的(Andr&Parpinelli,2014;Benlic等人,2017;Liao&Ting.2012;Segredo等人,2016)。此外,还有证据表明,在元启发式正在探索搜索空间时,代表探索的参数水平(如GA和DE中的突变率、TS中的Tabu列表大小)更频繁地在搜索过程的早期阶段发生变化。另一方面,在元启发式需要利用迄今为止找到的有前途的解决方案时,代表利用的参数级别更加受到重视(Andre&Parpinelli,2014;Benlic等人,2017;Liao&Ting.2012;Zennaki&EchCherif.2010)。
表10的另一个见解是,大多数论文都为基于种群的元启发式设置了参数。基于种群的元启发式具有探索和利用代表性参数的能力,并且应该建立这两个能力之间的平衡。否则,搜索过程要么陷入局部最优解中,要么进行随机搜索。
8.2. 未来研究方向讨论
在进行参数设置时,面临的第一个挑战是决定是否调整或控制参数。每种设置模式都有其优缺点。实验证据表明,最优参数设置不仅因不同问题实例而异,也因相同问题实例的不同搜索阶段而异。在这种情况下,尽管会对搜索过程造成计算开销,但仍建议执行参数控制。与参数控制相关的一个重大挑战是如何权衡探索和利用以选择当前的最佳配置(s)或寻找新的好配置。一旦在搜索过程中更改了配置,新的配置应能运行一定数量的迭代才能评估其性能。然后需要定义另一个参数来控制何时更改配置(即配置更改速率)。配置更改速率本身是另一个需要在搜索过程中调整或控制的参数。因此,参数控制本身引入了一系列其他参数(即参数控制机制的参数),需要调整或控制,从而导致参数控制的复杂性增加。
当处理连续参数时,参数控制面临另一个挑战,每个参数都存在无数个值。解决这一挑战的一种方法是将参数设置视为单独的优化问题,并将参数级别作为要优化的决策变量。另一种方法是开发自适应参数控制机制。文献中研究的另一种方法是将参数级别划分为可行区间(Aleti,2012)。这样,区间边界通常固定且不由搜索过程操纵。结果,用户必须事先确定区间的数量和大小,这可能会危及区间的准确性以及元启发式算法的效率。如果一个参数的级别被划分为几个狭窄的区间,则这些区间的准确性会更高,但在这些区间之间进行选择的计算工作显著增加。因此,找到好的区间可能较晚,或者可能有一些区间根本没有被选中。如果区间很宽,属于单个区间的不同参数值可能导致元启发式算法不同的性能表现,因为宽区间可能包含较小的区间,这些区间的行为不同。因此,无法将这样的宽区间赋予唯一的性能行为。为了解决这个问题,自适应范围参数控制方法(Aleti、Moser和Mostaghim,2012)在搜索过程中调整区间,基于性能的熵自适应范围参数控制方法(Aleti和Moser,2013)根据性能对参数值进行聚类。然而,确实需要更多的研究来了解连续参数值的小变化对元启发式算法性能的影响。
考虑表10,一个未来研究方向是将参数设置方法应用于其他元启发式算法,例如基于单一解的元启发式算法。首先可以尝试开发一种控制SA(模拟退火)参数的参数设置机制,例如冷却温度,这一直是实践者的挑战问题。此外,还可以进一步研究目前未受到足够关注的其他参数的控制。另一个应优先实施的研究方向是使用机器学习技术在多目标约束规划中实现参数设置。需要指出的是,在多目标优化问题中自适应参数控制的挑战之一是如何将反馈定义为单一值,以便它能代表多个目标函数下的参数值的质量。
9.合作
在同一问题实例上工作的不同具有特定优势和劣势的元启发式算法会产生不同的结果。在这种情况下,使用一种允许在合作方式下使用不同元启发式的框架可能会导致改进的搜索过程。发展合作元启发式的主要动机是在同一个框架中利用不同元启发式的优势、平衡探索和利用,并引导搜索朝着搜索空间的有希望的区域前进(Martin、Ouelhadj、Beullens和Ozcan,2011年)。由于这些框架的成功结果,对解决COP(约束优化问题)使用这种框架的兴趣有所增加(Martin等人,2016年;Talbi,2002年)。合作框架可以建模为多智能体系统,其中搜索过程由一组交换关于状态、模型、子问题、解决方案或其他搜索空间特性的信息的代理人执行(Blum和Roli,2003年)。
在基于多智能体的合作元启发式中,每个代理人都可能是一个元启发式或元启发式的一部分,例如操作、搜索策略、解决方案等,试图解决问题,同时与其他代理人进行通信(Silva、de Souza、Souza和de Franca Filho,2018年)。合作可以在算法级别(即几个具有特定特征的元启发式之间)发生,其中不同的具有特定特征的元启发式合作解决一个约束优化问题,也可以在操作员级别(即一个元启发式内部)发生,其中不同的操作员在发现搜索空间的不同区域时合作。前者属于将机器学习技术集成到元启发式中的高级别集成类别,而后者属于集成的低级别类别。
机器学习技术可以通过从不同代理人解决问题实例的过程中提取知识来帮助设计智能合作框架。然后将此知识纳入使框架能够不断适应搜索空间的框架中。这样机器学习技术可以通过提高合作框架的整体性能来改进合作框架。将机器学习技术集成到合作框架中可以在两个学习级别上进行:交互式和内部级别。前者是调整整个框架的行为以适应搜索空间,后者是调整每个代理人的行为以适应搜索空间。

图5展示了代理人之间的合作过程。代理人可以顺序或并行地合作(Talbi,2002年)。代理人之间的合作可以是同步的,即代理人以并行方式工作,没有一个等待其他代理人的结果,或者是异步的(Martin等人,2016年)。如图5所示,代理人之间的信息交换是直接的(多对多),即每个代理人都允许与其他任何代理人通信,间接的(Martin等人,2016年),即代理人只允许使用共同池中提供的信息。在合作过程中,代理人可以共享部分或完整的解决方案以继续搜索过程。
9.1. 文献分类与分析

表11根据合作级别、并行/顺序合作模式、学习程度、所使用的机器学习技术、直接/间接信息共享、代理人之间共享的解决方案类型、参与合作的元启发式算法以及最后研究的COP(约束优化问题)等因素对研究合作解决COP问题的论文进行了分类。据我们所知,表11回顾了最相关的论文,包括最近在文献中研究利用机器学习技术帮助元启发式(或元启发式的组成部分)解决COP问题的研究。
如表11所示,大多数研究采用并行方式进行合作。主要动机是试图减少依次执行多个元启发式的计算时间(即顺序合作)。在并行性中,元启发式同时执行,因此搜索过程的时间得以减少。事实上,合作和并行性的结合使得自给自足的算法可以同时运行,同时交换关于搜索的信息(Silva等人,2018年)。这种组合在优化领域引起了越来越多的关注,尤其是解决COP问题,因为它们已经在不同类型的COP上显示出良好的结果(KarimiMamaghan,Mohammadi,Jula,Pirayesh&Ahmadi,2020年a;Martinet al.,2016年)。此外,正如Talbi(2002年)和CottaTalbi以及Alba(2005年)所提到的,许多优化问题的最佳结果是由合作算法获得的。此外,访问并行计算资源的机会更大,为开发这些技术提供了新的可能性(Silva等人,2018年)。
关于同步或异步合作,大多数研究重点在于异步合作。实际上,在大多数情况下,当元启发式并行执行时,它们的合作也是异步的,其中没有一个元启发式等待其他元启发式的结果。异步合作具有较少的操作挑战,并为修改合作框架提供了机会。使用异步合作,元启发式可以轻松地添加或删除而不会对整体框架进行任何更改。另一方面,同步合作面临更多的挑战。在同步合作中,代理人必须协调其行动时间。换句话说,只有在所有代理人都准备好行动时才会激活代理人(Barbucha,2010年b)。确实,尽管代理人独立工作,但代理人的激活时间取决于彼此。因此,有必要确定一个同步点,在该点上代理人宣布其准备就绪并开始行动。因此,代理人的时间依赖性可能会导致一些代理人等待,从而导致一些处理器在一段时间内处于空闲状态。
根据表格11,合作系统的代理人可以是元启发式或元启发式的组成部分。合作可以在算法级别或操作员级别发生。在操作员级别上的合作与AOS(第7.1节)之间的差异在于,在AOS中,操作员根据其性能历史选择一个接一个地被选中,而在合作框架中,操作员共享信息以共同寻找解决方案。合作元启发式的主要机器学习技术是RL和用于AR的Apriori算法。RL已被用于帮助系统根据搜索过程中获得的经验调整其行为。RL分为两个级别使用:在代理人(内部代理人级别)内,通过修改其组件(选择操作)来适应搜索过程中搜索空间的特点;在更高的级别(代理人级别),适应代理人的应用,基于与其他代理人的性能比较。另一方面,AR用于识别优秀解决方案的共同特征。然后,这些知识以部分解决方案的形式在代理人之间共享,这使每个代理人都可以根据确定的模式生成新解决方案并引导搜索朝着有希望的区域发展。
9.2.讨论&未来研究方向
本节旨在介绍在设计元启发式合作框架时所需的要求和潜在挑战。接下来提供一组未来研究的方向。
高效合作的元启发式的设计和实施需要对不同元启发式具有足够的先验知识。要充分利用不同算法的优势,这是开发合作算法的主要动机之一,需要了解广泛范围的算法及其强弱点。例如,基于人口的元启发式在探索方面很强大。另一方面,基于单一解决方案的元启发式在利用方面很强大。如表格11所示,采用异质算法的研究将基于人口的和基于单一解决方案的元启发式纳入其合作框架中,以利用探索和利用的能力。正如前面所讨论的那样,在代理人之间共享信息的方式可以是部分解决方案,其中AR可用于生成这些部分解决方案。在这方面,需要解决AR在部分解决方案生成方面的一系列挑战,这些挑战已在第7.3节中详细阐述。考虑到表格11,在大多数研究中,代理人(元启发式)试图部分或完全保存和共享获得的良好解决方案。这样,每个元启发式都将了解其他元启发式开采的有希望的区域。作为未来的研究方向之一,共享不良解决方案及其相应的特征也可能有助于防止元启发式探索非有希望的区域。事实上,已访问过的非有希望区域可能已被禁止由其他元启发式进一步探索和利用。
本节审查的大部分论文都使用了合作的元启发式来解决单个目标COP问题,只有少数论文研究了多目标COP中的合作(KarimiMamaghan等人,2020a;KarimiMamaghan、Mohammadi、Pirayesh、KarimiMamaghan和Irani,2020b)。这两篇论文使用kmeans将多目标基于人口的元启发式与基于单一解决方案的元启发式联系起来。一旦通过基于人口的元启发式获得了非支配解,则使用kmeans对这些解进行聚类。然后,将每个簇的代表分配给基于单一解决方案的元启发式以进行更充分的开发。这种合作导致了更好的非支配解,无论是在搜索过程的质量还是计算时间方面。在这方面,另一个未来研究方向可能是将合作的概念扩展到多目标COP中。
结论与展望
近年来,机器学习技术已广泛地应用于元启发式算法以解决复杂优化问题,并取得了在解决方案质量、收敛速率和鲁棒性方面的令人鼓舞的结果。本文对机器学习技术在元启发式设计中不同元素的不同目的的整合进行了全面和技术性的审查,包括算法选择、适应度评估、初始化、进化、参数设置和合作等。在整个论文中,针对每种整合方式,都详细阐述了特定的挑战。无论采用何种整合方式,在使用机器学习技术于元启发式时也存在一系列共同的挑战,如下:
当将机器学习技术集成到元启发式中时,会引入一组额外的参数,需要仔细调整/控制以获得最佳性能。迄今为止的几乎所有论文都将这些参数视为搜索过程中固定的。为了应对这一挑战,我们提出根据集成的特点动态调整额外参数。
在训练机器学习技术处理特定大小的问题实例时,规模扩展是一个挑战。为了克服这个问题,可以尝试使用更大的实例进行训练,但这可能非常耗时,并且成为计算问题,除非是非常简单的机器学习和优化问题。数据量越大,机器学习技术的性能就越高。收集或生成足够数据是将机器学习技术集成到元启发式中的另一个挑战。事实上,收集甚至生成足够的数据是一项艰巨的任务。即使有足够的历史数据可用,从历史数据中采样以适当模拟反映在该数据中的行为的方式也是一个挑战(Bengio等人,2021)。应对数据可用性挑战的一种方法是使用少样本学习(FewShot Learning)来训练一个具有非常少量训练数据的模型(Wang等人,2020b)。通过利用类似问题的先验知识,少样本学习可以快速地泛化到仅包含少量问题实例的新任务(带有监督信息)。随着新技术的快速发展,现实世界中的问题变得越来越复杂,而随着数字化的进步,大量实时数据被收集,无法由经典机器学习技术处理。这些大数据携带着需要考虑的几个问题(Emrouznejad,2016)。为了应对这些大数据,可以集成更先进的机器学习技术如深度学习到元启发式中。
除了上述应对常见挑战的方法之外,将机器学习技术集成到元启发式中的一组共同的未来研究方向如下:
本文所审查的大多数研究仅涉及将机器学习技术集成到元启发式中单一目的的研究,而当机器学习技术为元启发式服务于多个目的时,期望获得更高的性能。因此,一个有趣的未来研究方向可能是同时将机器学习技术集成到元启发式算法中以满足不同目的的需求。例如,在一个元启发式中同时实现参数控制和自适应操作符选择可能会在整个搜索过程中提高元启发式的总体性能。
随着超级计算机的发展,探索使用GPU图形处理单元(GPU)和TPU加速器(Tensor Processing Units accelerators)在将机器学习技术集成到元启发式中的并行概念可能成为一个有趣的未来研究方向(Alba,2005; Cahon, Melab,& Talbi, 2004; Van Luong, Melab,& Talbi, 2011)。文献中的大部分论文使用传统的机器学习技术,如kNN、kmeans、SVM、LR等。随着机器学习技术的最近迅速发展,更先进的现代机器学习技术,如深度强化学习和迁移学习,可以作为有前途的研究方向。在这方面,当各种机器学习技术可用于特定目的集成到元启发式中时,可以研究算法选择问题来选择最合适的机器学习技术。
现实世界优化问题的一个重要问题是输入数据的不确定性,尤其是当输入数据具有不同的分布时。在这方面,一个有前途的研究方向是使用聚类方法(如kmeans、SoM)对输入数据进行聚类,旨在区分具有不同分布的数据。这些数据类别然后可以用于/集成解决手头的优化问题。解决动态优化问题时,输入数据的动态性是另一个可以通过机器学习技术处理的问题。事实上,机器学习技术可以用来监测/预测输入数据的变化,一旦通过机器学习技术检测到新的演变趋势,就可以相应地更新优化变量。最后但同样重要的是,另一个未来研究方向是将机器学习技术集成到元启发式中以解决新的问题集或其他复杂的优化问题,如多目标优化、双层次优化等。这个方向还引发了其他值得进一步研究的问题。
附录



