
- 1自然语言处理库——Gensim之Word2vec_gensim中的word2vec
- 2面试阿里JavaP7岗本以为凉凉:4轮技术面终拿下offer,终圆我大厂梦
- 3毕业设计 基于Spark网易云音乐数据分析_网易云音乐评论数据分析
- 4C# Web控件与数据感应之 TreeView 类 续篇
- 5流式大数据处理的三种框架:Storm,Spark和Flink_开源分布式存储和处理框架,例如spark和storm
- 6【Java】 Java中解码Base64数据的简易指南_java base64 解码
- 7基于NLU的智能对话系统_nlu协议
- 8大模型入门教程(非常详细)从零基础入门到精通,看完这一篇就够了_大模型推理详细流程
- 9电脑键盘上每个键的作用_Mac键盘不起作用?苹果电脑键盘失灵解决教程
- 10【人工智能】AI 人工智能技术近十年演变发展历程_在过去10年中,ai技术
ChromaDB初探_chromadbcontainer
赞
踩
探索ChromaDB
在当今数据驱动的世界中,随着人工智能和机器学习的广泛应用,如何高效地存储、检索和操作大量向量数据成为了一个关键问题。ChromaDB作为一种强大的向量数据库,正在为解决这一问题提供全新的解决方案。在这篇博客中,我们将介绍什么是RAG(Retrieval-Augmented Generation),Embedding的概念,并深入探讨ChromaDB的安装、Docker部署以及通过Python客户端进行交互的具体方法。
什么是RAG?
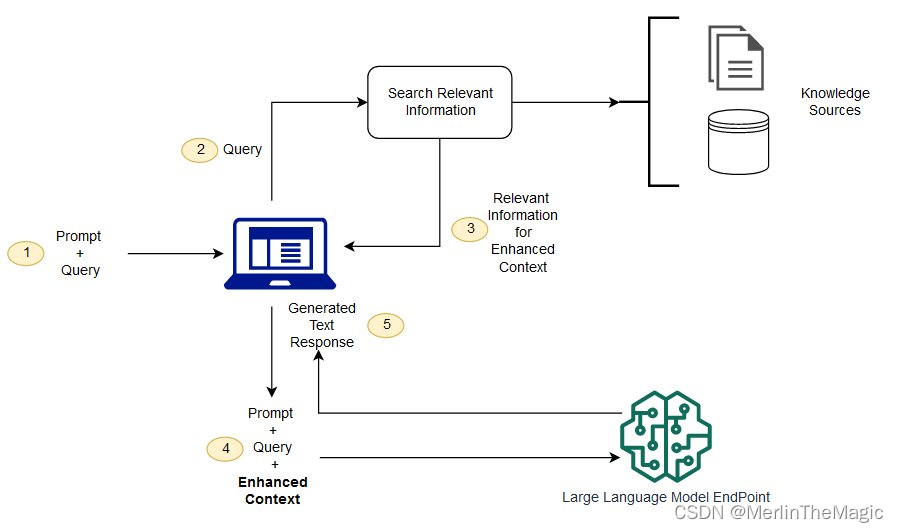
RAG,全称为Retrieval-Augmented Generation,是一种结合检索和生成的技术。它通过首先从数据库或知识库中检索相关信息,然后利用这些信息来生成答案。RAG技术在问答系统、对话生成和信息检索等应用中表现出色。其工作流程一般如下:
- 检索(Retrieval):从大量数据中检索出与输入相关的片段。
- 生成(Generation):利用检索到的片段,生成更为准确和上下文相关的回答。
RAG技术的关键在于高效、准确的检索,这正是向量数据库如ChromaDB所擅长的。从文本到向量,我们需要用到embedding技术。
什么是Embedding?
Embedding是将高维数据(例如文本、图像)转换为低维连续向量的过程。通过这种转换,我们可以在一个高效、可计算的空间中表示复杂的数据。常见的Embedding方法包括Word2Vec、BERT等。Embedding不仅能够降低数据的维度,还能够保留数据的语义信息,使得在向量空间中相似的数据点更接近。
ChromaDB简介
ChromaDB是一种专门为处理和管理向量数据而设计的数据库。它提供了高效的向量存储、检索和管理功能,非常适合用于需要快速相似度检索的应用场景。
ChromaDB的安装
你可以通过以下步骤在本地安装ChromaDB:
- 确保你的系统已经安装了Python(>= 3.6)。
- 使用pip安装ChromaDB:
pip install chromadb- 1
使用Docker部署ChromaDB
为了简化部署过程,你可以使用Docker来部署ChromaDB。以下是使用Docker部署的步骤:
- 首先,确保你的系统已经安装了Docker。
- 创建一个Dockerfile:
FROM python:3.8-slim WORKDIR /app RUN pip install chromadb COPY . /app CMD ["python", "your_script.py"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 构建Docker镜像:
docker build -t chromadb_image .- 1
- 运行Docker容器:
docker run -d --name chromadb_container -p 8000:8000 chromadb_image- 1
通过Python客户端与ChromaDB进行交互
安装完ChromaDB后,可以通过Python客户端与其进行交互。以下是一个简单的示例:
-
导入必要的库:
from chromadb.client import Client from chromadb.config import Settings- 1
- 2
-
初始化客户端:
client = Client(Settings( chromadb_host='localhost', chromadb_port=8000 ))- 1
- 2
- 3
- 4
-
插入向量数据:
vectors = [ [0.1, 0.2, 0.3], [0.4, 0.5, 0.6] ] metadata = [ {'id': 'vector1', 'info': 'First vector'}, {'id': 'vector2', 'info': 'Second vector'} ] client.insert(vectors, metadata)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
检索向量数据:
query_vector = [0.1, 0.2, 0.3] results = client.search(query_vector, top_k=1) print(results)- 1
- 2
- 3
通过这些步骤,你可以轻松地在本地或通过Docker部署ChromaDB,并使用Python客户端与其进行交互。
总结
ChromaDB作为一种专为向量数据设计的数据库,结合了高效的检索和存储能力,非常适合用于RAG等需要快速相似度检索的应用。通过了解RAG和Embedding的基本概念,以及ChromaDB的安装和使用方法,相信你能够在自己的项目中充分发挥ChromaDB的强大功能。

