
- 1四、张量表示_张量显示
- 2FastDFS【FastDFS概述(简介、核心概念 、上传机制 、下载机制)】(一)-全面详解(学习总结---从入门到深化)
- 3使用openvpn连通多个机房内网
- 4linux中clear报错:terminals database is inaccessible的解决方法
- 5OpenWrt下mwan3定时重启_openwrt定时重启
- 6android从strings资源文件获取,并拼接字符串方法_android 从资源文件拼接string
- 7SQLite3移植到ARM Linux教程_sqlite3数据库移植到arm
- 8【Linux】list_for_each_entry用法
- 9Linux | firewall命令 对外开放端口、查看端口、防火墙开启、防火墙关闭_firewall永久开放端口
- 10GitHub上受欢迎的Android UI Library_github 上最受欢迎的android ui
如何防止Redis 缓存雪崩、缓存穿透、缓存击穿_请写出来防止缓存穿透的方案
赞
踩
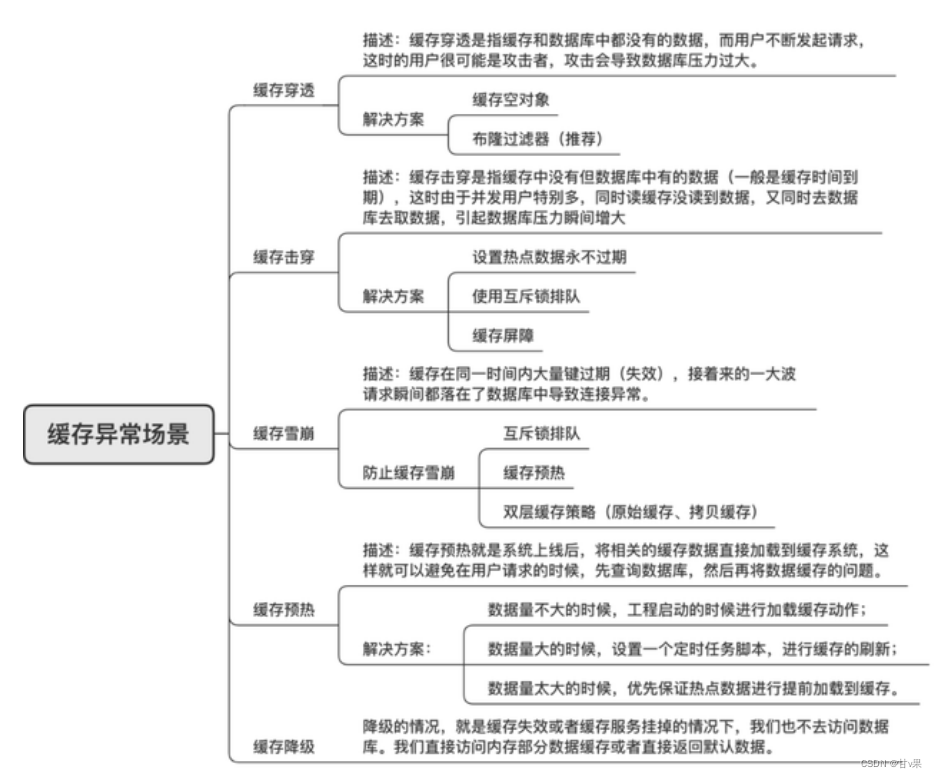
缓存异常场景分类
在实际生产环境中有时会遇到缓存穿透、缓存击穿、缓存雪崩等异常场景,为了避免异常带来巨大损失,我们需要了解每种异常发生的原因以及解决方案,帮助提升系统可靠性和高可用。
缓存穿透
什么是缓存穿透?
缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,然后返回空。
如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至击垮数据库系统。
缓存穿透常用的解决方案
(1)布隆过滤器(推荐)
布隆过滤器(Bloom Filter,简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。
布隆过滤器专门用来检测集合中是否存在特定的元素。
如果在平时我们要判断一个元素是否在一个集合中,通常会采用查找比较的方法,下面分析不同的数据结构查找效率:
采用线性表存储,查找时间复杂度为O(N)采用平衡二叉排序树(AVL、红黑树)存储,查找时间复杂度为O(logN)采用哈希表存储,考虑到哈希碰撞,整体时间复杂度也要O[log(n/m)]当需要判断一个元素是否存在于海量数据集合中,不仅查找时间慢,还会占用大量存储空间。接下来看一下布隆过滤器如何解决这个问题。
布隆过滤器设计思想
布隆过滤器由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组初始化均为0,所有的哈希函数都可以分别把输入数据尽量均匀地散列。
当要向布隆过滤器中插入一个元素时,该元素经过k个哈希函数计算产生k个哈希值,以哈希值作为位数组中的下标,将所有k个对应的比特值由0置为1。
当要查询一个元素时,同样将其经过哈希函数计算产生哈希值,然后检查对应的k个比特值:如果有任意一个比特为0,表明该元素一定不在集合中;如果所有比特均为1,表明该集合有可能性在集合中。为什么不是一定在集合中呢?因为不同的元素计算的哈希值有可能一样,会出现哈希碰撞,导致一个不存在的元素有可能对应的比特位为1,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
总结一下:布隆过滤器认为不在的,一定不会在集合中;布隆过滤器认为在的,可能在也可能不在集合中。
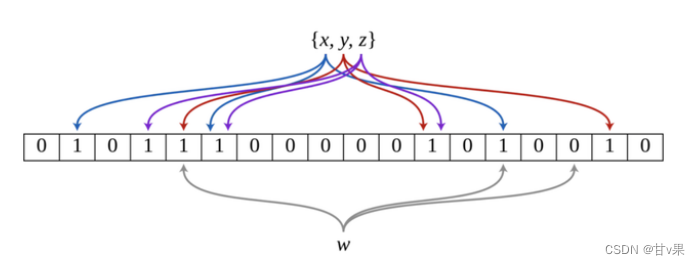
举个例子:下图是一个布隆过滤器,共有18个比特位,3个哈希函数。集合中三个元素x,y,z通过三个哈希函数散列到不同的比特位,并将比特位置为1。当查询元素w时,通过三个哈希函数计算,发现有一个比特位的值为0,可以肯定认为该元素不在集合中。
布隆过滤器优缺点
优点:
节省空间:不需要存储数据本身,只需要存储数据对应hash比特位时间复杂度低:插入和查找的时间复杂度都为O(k),k为哈希函数的个数缺点:
存在假阳性:布隆过滤器判断存在,可能出现元素不在集合中;判断准确率取决于哈希函数的个数不能删除元素:如果一个元素被删除,但是却不能从布隆过滤器中删除,这也是造成假阳性的原因了布隆过滤器适用场景
爬虫系统url去重
垃圾邮件过滤
黑名单
(2)返回空对象
当缓存未命中,查询持久层也为空,可以将返回的空对象写到缓存中,这样下次请求该key时直接从缓存中查询返回空对象,请求不会落到持久层数据库。为了避免存储过多空对象,通常会给空对象设置一个过期时间。
这种方法会存在两个问题:
如果有大量的key穿透,缓存空对象会占用宝贵的内存空间。空对象的key设置了过期时间,在这段时间可能会存在缓存和持久层数据不一致的场景。
缓存击穿
什么是缓存击穿?
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
缓存击穿危害
数据库瞬时压力骤增,造成大量请求阻塞。
如何解决
使用互斥锁(mutex key)
这种思路比较简单,就是让一个线程回写缓存,其他线程等待回写缓存线程执行完,重新读缓存即可。
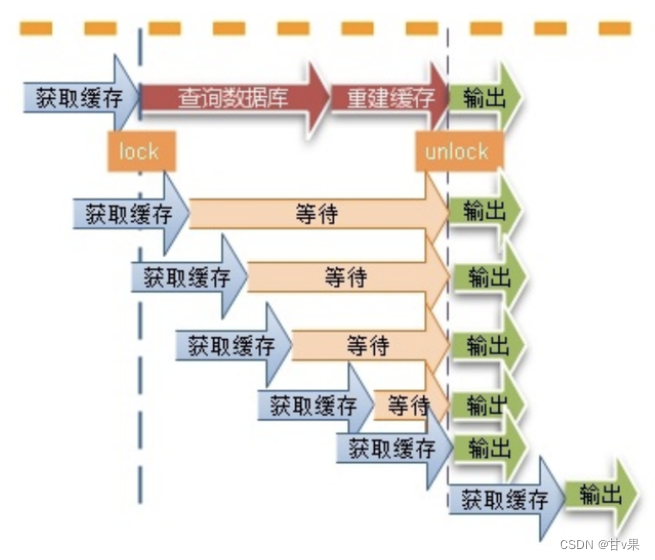
同一时间只有一个线程读数据库然后回写缓存,其他线程都处于阻塞状态。
如果是分布式应用就需要使用分布式锁。
热点数据永不过期
永不过期实际包含两层意思:
物理不过期,针对热点key不设置过期时间
逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
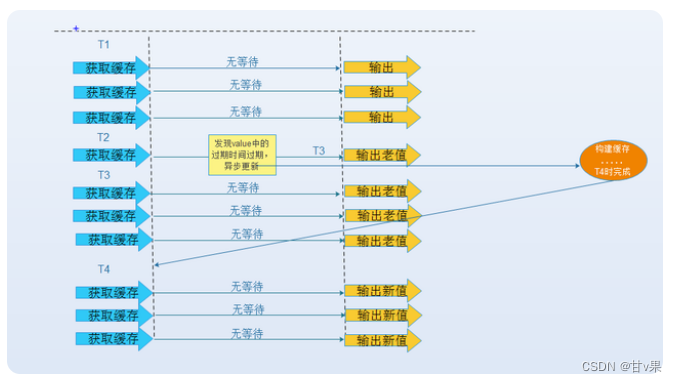
从实战看这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,对于不追求严格强一致性的系统是可以接受的。
缓存雪崩
什么是缓存雪崩?
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,请求直接落到数据库上,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
缓存雪崩解决方案
常用的解决方案有:
均匀过期加互斥锁缓存永不过期双层缓存策略
(1)均匀过期
设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
(2)加互斥锁
跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
(3)缓存永不过期
跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
(4)双层缓存策略
使用主备两层缓存:
主缓存:有效期按照经验值设置,设置为主读取的缓存,主缓存失效后从数据库加载最新值。
备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存。
缓存预热
什么是缓存预热?
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统,这样就可以避免在用户请求的时候,先查询数据库,然后再将数据回写到缓存。
如果不进行预热, 那么 Redis 初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
缓存预热的操作方法
数据量不大的时候,工程启动的时候进行加载缓存动作;
数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
数据量太大的时候,优先保证热点数据进行提前加载到缓存。
缓存降级
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。
在项目实战中通常会将部分热点数据缓存到服务的内存中,这样一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。

