
- 1线程操作6.1_pthread_create创建的线程执行时间
- 2LSTM实现短时交通流量预测
- 3nginx,文件下载,预览,防止浏览器下载时直接打开,防止预览时直接下载文件,解决nginx谷歌浏览器不支持下载问题...
- 4springboot的最核心的27个注解详解_springboot核心注解
- 5如何安装微擎?微擎安装教程
- 6Python广东广州二手房源爬虫数据可视化分析大屏全屏系统 开题报告_广州二手房项目爬虫
- 72019多校第二场 HDU6602 Longest Subarray(思维,线段树区间修改维护最值)_2019hdu多校第二场
- 82016 cvpr HyperNet论文原理理解_chrome-extension://ibllepbpahcoppkjjllbabhnigcbffp
- 9使用netty实现一个多人聊天室--failed: Error during WebSocket handshake: Unexpected response code: 200
- 10Centos7中修改网卡IP地址固定,还可以通过本地主机访问外网_centos 7.6 图形化界面改网卡地址
python爬虫学习笔记(一)—— 爬取腾讯视频影评_腾讯视频评论爬虫
赞
踩
前段时间我忽然想起来,以前本科的时候总有一些公众号,能够为我们提供成绩查询、课表查询等服务。我就一直好奇它是怎么做到的,经过一番学习,原来是运用了爬虫的原理,自动登陆教务系统爬取的成绩等内容。我觉得挺好玩的,于是自己也琢磨了一段时间,今天呢,我为大家分享一个爬虫的小实例,也算是记录自己的学习过程吧。
我发现腾讯视频出了一部新的电视剧,叫做《新笑傲江湖》,也不知道好看不好看,反正我只喜欢陈乔恩版的东方教主。言归正传,假如,我们若要对腾讯视频中的某个视频的影评进行批量爬取并实现自动加载新评论,这个时候,我们就可以写一个爬虫来帮我们完成工作。接下来,我们开始爬虫的编写之旅吧!
一、 Fiddler的使用
我们要爬取影评的视频网址是:https://v.qq.com/x/cover/8jkko7n7si6k04m.html,首先我们打开该网址,看看里面的内容。内容如下,使劲往下拉,就可以看到下面的影评啦,如下所示:


我们发现,该网站下面的评论每次只能加载10条评论,当我们单击“加载更多”的时候,就会又加载出10条,但是网页的网址并没有变化,那么整个过程是怎样实现的呢?要想弄明白整个过程,我们需要用到一个工具——Fiddler。Fiddler是一种常见的抓包分析软件,同时,我们可以利用Fiddler详细地对HTTP请求进行分析,并模拟对应的HTTP请求。
Fiddler是基本工作原理是怎样的呢?如果没有Fiddler,本地应用如果要与服务器进行通信,可以直接向服务器发送Request请求,待服务器处理之后将处理结果返回本地,本地应用接收响应Response。如果有了Fiddler,本地应用与服务器之间所有的Request和Response都将经过Fiddler,由Fiddler进行转发,因此Fiddler以代理服务器的方式存在,由于所有的网络数据都会经过Fiddler,自然Fiddler能够截获这些数据,实现网络数据的抓包。
要使用Fiddler,首先需要安装Fiddler这款软件。我们可以从Fiddler的官网(http://www.telerik.com/fiddler)下载Fiddler,下载之后打开直接安装即可。安装好Fiddler之后,我们将学习如何使用Fiddler来捕获浏览器与服务器之间的会话信息。在此,我们将以360浏览器为例进行讲解。
因为Fiddler是以代理服务器的方式进行工作的,所以我们首先应当设置360浏览器,让360浏览器使用Fiddler作为其代理服务器。设置360浏览器的方式如下:
(1)首先单击“打开菜单”,如下所示:

(2)选择菜单中的“工具”,然后选择“代理服务器”,最后选择”代理服务器设置“,弹出以下对话框,在列表中添加”127.0.0.1:8888”,因为Fiddler监控的地址是127.0.0.1:8888。如下所示:


(3)此时,我们就可以使用Fiddler来捕获360浏览器与服务器之间的会话信息了。我们知道,现在的网站有的使用HTTP协议,有的使用的是HTTPS协议。如果想让Fiddler能够捕获HTTPS的会话信息,还需要设置一下Fiddler。打开Fiddler,然后单击“Tools”,选择“Options”,在弹出来的界面中选择“HTTPS”标签,将下方选项全部勾选上,如下所示:

至此,现在Fiddler就能捕获360浏览器与服务器之间的HTTP和HTTPS会话信息了。
在我们编写爬虫之前,我们需要找到加载影评时所触发的真实网址,这个就需要Fiddler来捕捉。操作如下:
(1)首先,在Fiddler的QuickExec命令行中输入cls,清理列表屏幕,如下所示:

(2)单击腾讯视频网页中底部的“加载更多”,观察Fiddler的会话列表的变化,找到所触发的会话信息,如下所示:

(3)选中该会话,对其单击鼠标右键,选择复制URL,如下所示:

(4)得到单机"加载更多"时所触发的真实网址,如下所示:
https://video.coral.qq.com/varticle/2451377986/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6374514531154423930&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1522384207407
为了便于观察加载评论信息时触发的网址之间的规律,再次在视频网页中的评论处单机“加载更多”,用同样的方法可以在Fiddler中捕获到新触发的对应的真实网址,将其URL复制出来,如下所示:
https://video.coral.qq.com/varticle/2451377986/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6380041197477962010&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1522384207408
https://video.coral.qq.com/varticle/2451377986/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6378846293964012868&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1522384207409
观察这三个网址之间的差异,可以分析出如下结果:
1) 三次都出现了2451377986,可以分析并推断得出这个值为对应视频的一种编号,即2451377986代表的是《新笑傲江湖》的视频评论。
2)三次都出现orinum=10,观察每次加载的评论数,发现也是10条,所以可以推断得出,orinum字段代表的是每次评论加载的数量。
3)三次cursor字段的值不一样,该字段代表的应该是每10条评论中的起始id。
4)网址中后续的“&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1522384207407”等信息可以省略,我们可以省略后再访问该网址进行验证。即登陆如下网址:
https://video.coral.qq.com/varticle/2451377986/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6374514531154423930

没错,正是我们想要的。
5)因此,我们可以推断出,视频评论的URL地址格式为“https://video.coral.qq.com/varticle/视频编号/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor=评论标号"
我们观察用视频评论URL地址打开的网页,仔细分析其内容,我们发现有一些需要进行unicode编码才能够显示的内容,主要有:
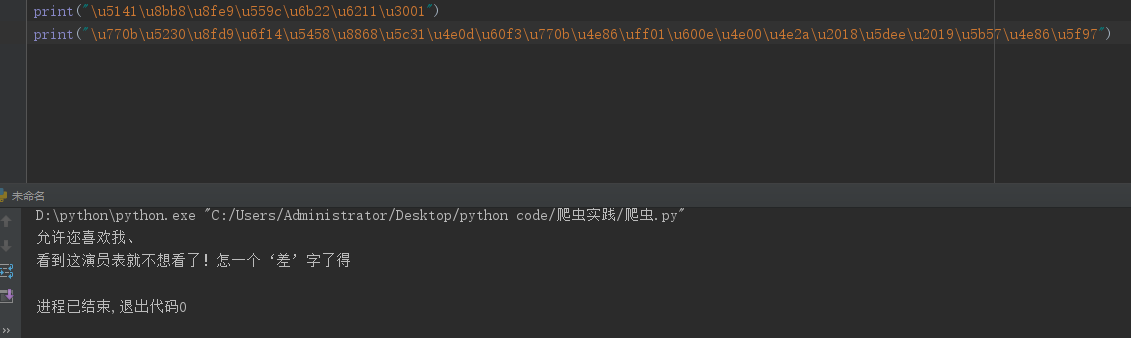
1)"content":"\u770b\u5230\u8fd9\u6f14\u5458\u8868\u5c31\u4e0d\u60f3\u770b\u4e86\uff01\u600e\u4e00\u4e2a\u2018\u5dee\u2019\u5b57\u4e86\u5f97"
2) "nick":"\u5141\u8bb8\u8fe9\u559c\u6b22\u6211\u3001"
我们用python对这两段信息进行解读,并输出对应的结果,如下所示:
随后,我们打开该视频的网页,找到对应的评论信息,如下所示:

通过对比,我们可以很容易发现这些字段名与评论的关系如下:
1)"content" 对应具体的评论内容
2)"nick" 对应评论者的昵称
在理清楚了这个关系之后,我们则可以构造对应的正则表达式(不难,这里就不介绍了)定向地爬取出评论地具体内容出来啦!
二、爬虫代码展示
- import urllib.request
- import http.cookiejar
- import re
-
-
- ##############################################
- #该代码用来爬取腾讯视频《新笑傲江湖》的影评
- #时间:2018.3.30
- #作者:行歌
- ###############################################
-
- cursor_id = "6374188293605193032"
- url = "https://video.coral.qq.com/varticle/2451377986/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor="
- temp_headers = {"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding":"utf-8","Accept-Language":"zh-CN,zh;q=0.8","User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"}
- cjar = http.cookiejar.CookieJar()
- opener = urllib.request.build_opener( urllib.request.HTTPCookieProcessor(cjar))
- headers = []
- for key,value in temp_headers.items():
- item = (key,value)
- headers.append( item )
- opener.addheaders = headers
- urllib.request.install_opener( opener)
- userid_and_content = '"userid":"(.*?)","content":"(.*?)"'
- id_re ='"id":"(.*?)"'
- for i in range(1,20):
- url_new = url + cursor_id
- data = urllib.request.urlopen( url_new ).read().decode("utf-8")
- userid_and_content_list = re.findall(userid_and_content,data,re.S)
- id_value = re.findall(id_re ,data ,re.S)
- cursor_id = id_value[-1]
- content_list = [ i[1] for i in userid_and_content_list ]
-
- for i in range(len(content_list)):
- with open("comment.txt","wb") as fr:
- fr.write('评论内容:'+ eval('u"'+content_list[i]+'"'))
- fr.write('\n')

在写代码的时候我就遇到了一个坑,为了伪装成浏览器,我们需要设置好对应用户请求的Headers信息,因此我选择通过opener.addheaders为爬虫添加Headers信息,但是此时添加的Headers信息要具备指定的格式,格式为:[(字段名1,对应的值1),(字段名2,对应的值2),...,(字段名n,对应的值n)]。
其中刚开始的时候,我将Accept-Encoding设置为gzip,deflate,结果出现乱码问题,因此,正确的办法就是将该字段信息省略不写或者将该字段信息的值设置为utf-8或gb2312。为什么将该字段的值设置为gzip,deflate会出现问题呢?是因为如果设置该字段为gzip,deflate,那么从服务器返回来的是对应的gzip,deflate压缩的代码,此时没有进行解码,故而会出现乱码的情况,而一些常规浏览器中,从服务器返回对应的gzip,deflate压缩的代码后,浏览器可以自动进行解压缩,故而不会出现乱码。
最后我们把爬取的内容保存在comment.txt文件中,如下所示:
成功啦!!!!

