
- 1人工智能(AI)和机器学习_人工智能和机器学习
- 2unity-VRTK学习日记1(VRTK4|无头盔开发模拟器SpatialSimulator)_unityvr模拟器
- 3游戏引擎开发涉及的知识和技术_游戏开发涉及的系统
- 4Python 中的多线程和多进程 | 长文详解
- 5金融数据挖掘Jupyter—北京市二手房数据分析—课设_jupyter数据处理课设
- 6Efuse介绍及安全启动浅析
- 7new FormData() - FormData对象的作用及用法
- 8用23种设计模式打造一个cocos creator的游戏框架----(十八)责任链模式_cocos creator中好用的游戏框架
- 9Android 机器学习模型的轻量级框架 TensorFlow Lite_tensorflow android
- 10初中数学知识点总结_初中数学知识点总结(北师大)[1]最新版
Dubbo介绍
赞
踩
一 重要的概念
1.1 什么是 Dubbo?
Apache Dubbo (incubating) |ˈdʌbəʊ| 是一款高性能、轻量级的开源Java RPC 框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。简单来说 Dubbo 是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。
Dubbo 目前已经有接近 23k 的 Star ,Dubbo的Github 地址:https://github.com/apache/incubator-dubbo 。 另外,在开源中国举行的2018年度最受欢迎中国开源软件这个活动的评选中,Dubbo 更是凭借其超高人气仅次于 vue.js 和 ECharts 获得第三名的好成绩。
Dubbo 是由阿里开源,后来加入了 Apache 。正式由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
我们上面说了 Dubbo 实际上是 RPC 框架,那么什么是 RPC呢?
1.2 什么是 RPC?RPC原理是什么?
什么是 RPC?
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。比如两个不同的服务 A、B 部署在两台不同的机器上,那么服务 A 如果想要调用服务 B 中的某个方法该怎么办呢?使用 HTTP请求当然可以,但是可能会比较麻烦。 RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。
RPC原理是什么?
我这里这是简单的提一下。详细内容可以查看下面这篇文章:
http://www.importnew.com/22003.html
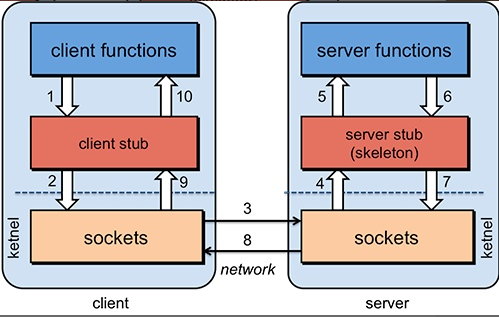
- 服务消费方(client)调用以本地调用方式调用服务;
- client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
- client stub找到服务地址,并将消息发送到服务端;
- server stub收到消息后进行解码;
- server stub根据解码结果调用本地的服务;
- 本地服务执行并将结果返回给server stub;
- server stub将返回结果打包成消息并发送至消费方;
- client stub接收到消息,并进行解码;
- 服务消费方得到最终结果。
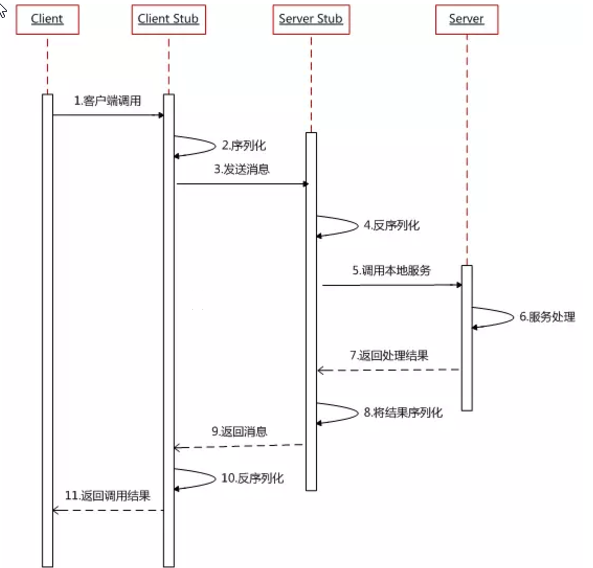
下面再贴一个网上的时序图:
说了这么多,我们为什么要用 Dubbo 呢?
1.3 为什么要用 Dubbo?
Dubbo 的诞生和 SOA 分布式架构的流行有着莫大的关系。SOA 面向服务的架构(Service Oriented Architecture),也就是把工程按照业务逻辑拆分成服务层、表现层两个工程。服务层中包含业务逻辑,只需要对外提供服务即可。表现层只需要处理和页面的交互,业务逻辑都是调用服务层的服务来实现。SOA架构中有两个主要角色:服务提供者(Provider)和服务使用者(Consumer)。
如果你要开发分布式程序,你也可以直接基于 HTTP 接口进行通信,但是为什么要用 Dubbo呢?
我觉得主要可以从 Dubbo 提供的下面四点特性来说为什么要用 Dubbo:
- 负载均衡——同一个服务部署在不同的机器时该调用那一台机器上的服务。
- 服务调用链路生成——随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
- 服务访问压力以及时长统计、资源调度和治理——基于访问压力实时管理集群容量,提高集群利用率。
- 服务降级——某个服务挂掉之后调用备用服务。
另外,Dubbo 除了能够应用在分布式系统中,也可以应用在现在比较火的微服务系统中。不过,由于 Spring Cloud 在微服务中应用更加广泛,所以,我觉得一般我们提 Dubbo 的话,大部分是分布式系统的情况。
我们刚刚提到了分布式这个概念,下面再给大家介绍一下什么是分布式?为什么要分布式?
1.4 什么是分布式?
分布式或者说 SOA 分布式重要的就是面向服务,说简单的分布式就是我们把整个系统拆分成不同的服务然后将这些服务放在不同的服务器上减轻单体服务的压力提高并发量和性能。比如电商系统可以简单地拆分成订单系统、商品系统、登录系统等等,拆分之后的每个服务可以部署在不同的机器上,如果某一个服务的访问量比较大的话也可以将这个服务同时部署在多台机器上。
1.5 为什么要分布式?
从开发角度来讲单体应用的代码都集中在一起,而分布式系统的代码根据业务被拆分。所以,每个团队可以负责一个服务的开发,这样提升了开发效率。另外,代码根据业务拆分之后更加便于维护和扩展。
另外,我觉得将系统拆分成分布式之后不光便于系统扩展和维护,更能提高整个系统的性能。你想一想嘛?把整个系统拆分成不同的服务/系统,然后每个服务/系统 单独部署在一台服务器上,是不是很大程度上提高了系统性能呢?
二 Dubbo 的架构
2.1 Dubbo 的架构图解
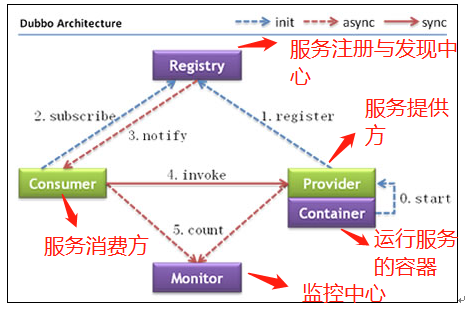
上述节点简单说明:
- Provider: 暴露服务的服务提供方
- Consumer: 调用远程服务的服务消费方
- Registry: 服务注册与发现的注册中心
- Monitor: 统计服务的调用次数和调用时间的监控中心
- Container: 服务运行容器
调用关系说明:
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
重要知识点总结:
- 注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
- 监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
- 注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
- 注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
- 注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
- 注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
2.2 Dubbo 工作原理
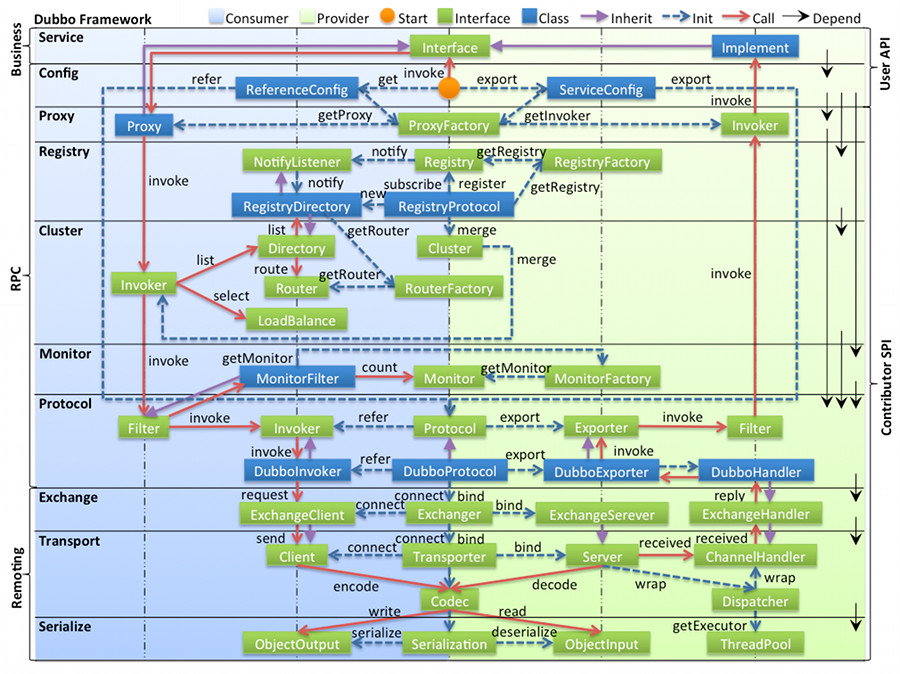
图中从下至上分为十层,各层均为单向依赖,右边的黑色箭头代表层之间的依赖关系,每一层都可以剥离上层被复用,其中,Service 和 Config 层为 API,其它各层均为 SPI。
各层说明:
- 第一层:service层,接口层,给服务提供者和消费者来实现的
- 第二层:config层,配置层,主要是对dubbo进行各种配置的
- 第三层:proxy层,服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton
- 第四层:registry层,服务注册层,负责服务的注册与发现
- 第五层:cluster层,集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务
- 第六层:monitor层,监控层,对rpc接口的调用次数和调用时间进行监控
- 第七层:protocol层,远程调用层,封装rpc调用
- 第八层:exchange层,信息交换层,封装请求响应模式,同步转异步
- 第九层:transport层,网络传输层,抽象mina和netty为统一接口
- 第十层:serialize层,数据序列化层,网络传输需要
三 Dubbo 的负载均衡策略
3.1 先来解释一下什么是负载均衡
先来个官方的解释。
维基百科对负载均衡的定义:负载均衡改善了跨多个计算资源(例如计算机,计算机集群,网络链接,中央处理单元或磁盘驱动的)的工作负载分布。负载平衡旨在优化资源使用,最大化吞吐量,最小化响应时间,并避免任何单个资源的过载。使用具有负载平衡而不是单个组件的多个组件可以通过冗余提高可靠性和可用性。负载平衡通常涉及专用软件或硬件。
上面讲的大家可能不太好理解,再用通俗的话给大家说一下。
比如我们的系统中的某个服务的访问量特别大,我们将这个服务部署在了多台服务器上,当客户端发起请求的时候,多台服务器都可以处理这个请求。那么,如何正确选择处理该请求的服务器就很关键。假如,你就要一台服务器来处理该服务的请求,那该服务部署在多台服务器的意义就不复存在了。负载均衡就是为了避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题,我们从负载均衡的这四个字就能明显感受到它的意义。
3.2 再来看看 Dubbo 提供的负载均衡策略
在集群负载均衡时,Dubbo 提供了多种均衡策略,默认为 random 随机调用。可以自行扩展负载均衡策略,参见:负载均衡扩展。
备注:下面的图片来自于:尚硅谷2018Dubbo 视频。
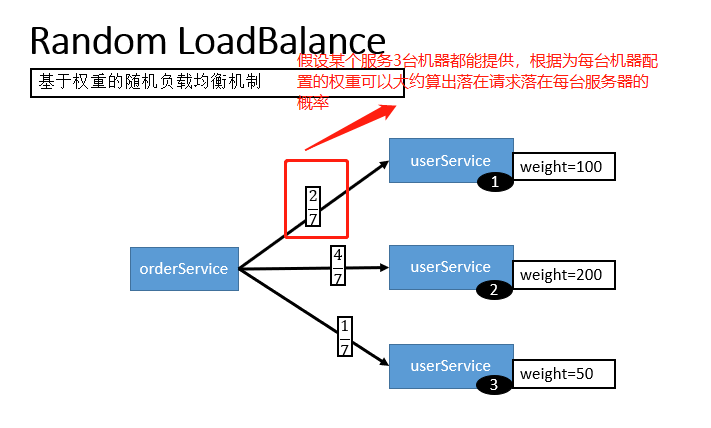
3.2.1 Random LoadBalance(默认,基于权重的随机负载均衡机制)
- 随机,按权重设置随机概率。
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
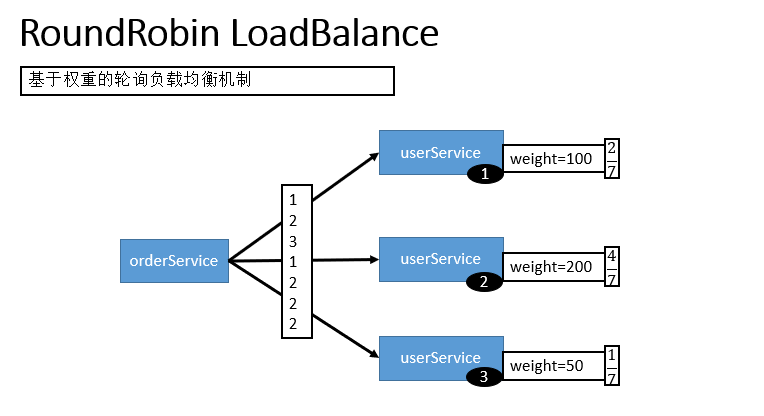
3.2.2 RoundRobin LoadBalance(不推荐,基于权重的轮询负载均衡机制)
- 轮循,按公约后的权重设置轮循比率。
- 存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
3.2.3 LeastActive LoadBalance
- 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
- 使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
3.2.4 ConsistentHash LoadBalance
- 一致性 Hash,相同参数的请求总是发到同一提供者。(如果你需要的不是随机负载均衡,是要一类请求都到一个节点,那就走这个一致性hash策略。)
- 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
- 算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
- 缺省只对第一个参数 Hash,如果要修改,请配置
<dubbo:parameter key="hash.arguments" value="0,1" /> - 缺省用 160 份虚拟节点,如果要修改,请配置
<dubbo:parameter key="hash.nodes" value="320" />
3.3 配置方式
xml 配置方式
服务端服务级别
<dubbo:service interface="..." loadbalance="roundrobin" />
- 1
客户端服务级别
<dubbo:reference interface="..." loadbalance="roundrobin" />
- 1
服务端方法级别
<dubbo:service interface="...">
<dubbo:method name="..." loadbalance="roundrobin"/>
</dubbo:service>
- 1
- 2
- 3
客户端方法级别
<dubbo:reference interface="...">
<dubbo:method name="..." loadbalance="roundrobin"/>
</dubbo:reference>
- 1
- 2
- 3
注解配置方式:
消费方基于基于注解的服务级别配置方式:
@Reference(loadbalance = "roundrobin")
HelloService helloService;
- 1
- 2
四 zookeeper宕机与dubbo直连的情况
zookeeper宕机与dubbo直连的情况在面试中可能会被经常问到,所以要引起重视。
在实际生产中,假如zookeeper注册中心宕掉,一段时间内服务消费方还是能够调用提供方的服务的,实际上它使用的本地缓存进行通讯,这只是dubbo健壮性的一种体现。
dubbo的健壮性表现:
- 监控中心宕掉不影响使用,只是丢失部分采样数据
- 注册中心宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
我们前面提到过:注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。所以,我们可以完全可以绕过注册中心——采用 dubbo 直连 ,即在服务消费方配置服务提供方的位置信息。
xml配置方式:
<dubbo:reference id="userService" interface="com.zang.gmall.service.UserService" url="dubbo://localhost:20880" />
- 1
注解方式:
@Reference(url = "127.0.0.1:20880")
HelloService helloService;
- 1
- 2
通信
序列化和反序列化
- 序列化:把Java对象转换为字节序列的过程。
- 反序列化:把字节序列恢复为Java对象的过程。
对象的序列化主要有两种用途:
- 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;(持久化对象)
- 在网络上传送对象的字节序列。(网络传输对象)
-
java自带的
- 性能差一点
-
Protocol Buffer
-
thrift

