
- 1Paddle OCR 常用cmd命令_cmd脚本启动ocr
- 2CSS入门详细笔记【2023.07】_css 浏览器判断table样式
- 3文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论_svm中xi∈rn
- 4多模态文本分类技术_多模态分类
- 5vue-router传递参数的几种方式_this.$router.resolve传params
- 6【ChatGPT】使用 GPT-4 探索大模型在“智能数据应用”领域的应用思路:NLP ---> DSL ---> SQL(ChatGPT DSL 能力挖掘) 2_nlp转dsl
- 7【NLP】NLP从业人员必须知道的十大必备知识库(附资料下载)
- 8深度学习笔记(5)_池化层输出的是什么
- 9通过Jenkins实现Unity多平台自动打包以及相关问题解决_unity通过jenkins实现自动化打包
- 10抓包工具:Sunny网络中间件
PPO算法基本原理及流程图(KL penalty和Clip两种方法)_ppo算法流程图
赞
踩
PPO算法基本原理
PPO(Proximal Policy Optimization)近端策略优化算法,是一种基于策略(policy-based)的强化学习算法,是一种off-policy算法。
详细的数学推导过程、为什么是off-policy算法、advantage函数设计、重要性采样Importance Sampling这些概念的详细介绍和注释请参考学习:李宏毅老师的强化学习系列课程,我也将学习笔记分享到另一篇博客中:PPO算法基本原理(李宏毅课程学习笔记)https://blog.csdn.net/ningmengzhihe/article/details/131457536,欢迎感兴趣的小伙伴共同交流呀!!!
KL penalty 和 Clip
PPO算法的核心在于更新策略梯度,主流方法有两种,分别是KL散度做penalty,另一种是Clip剪裁,它们的主要作用都是限制策略梯度更新的幅度,从而推导出不同的神经网络参数更新方式
采用KL penalty算法,那么神经网络参数按照下面的方式更新

采用Clip算法,那么神经网络参数按照下面的方式更新
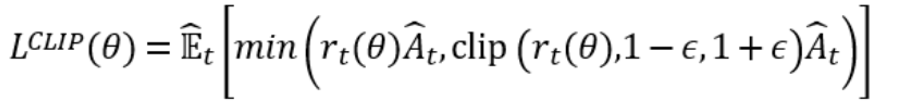
那么采用KL penalty算法的PPO算法伪代码如下


采用Clip算法的PPO算法伪代码如下

算法流程图
下面的算法流程图是基于莫烦python的PPO算法代码实现,同时参考了网络代码的算法流程,它没有用到memory,每次更新ppo用到的数据是连续的transition(包括当前状态、执行动作和累积折扣奖励值),它采用两个actor网络(一个actor_old一个actor )

PPO类包含下面四个部分,也就是四个方法

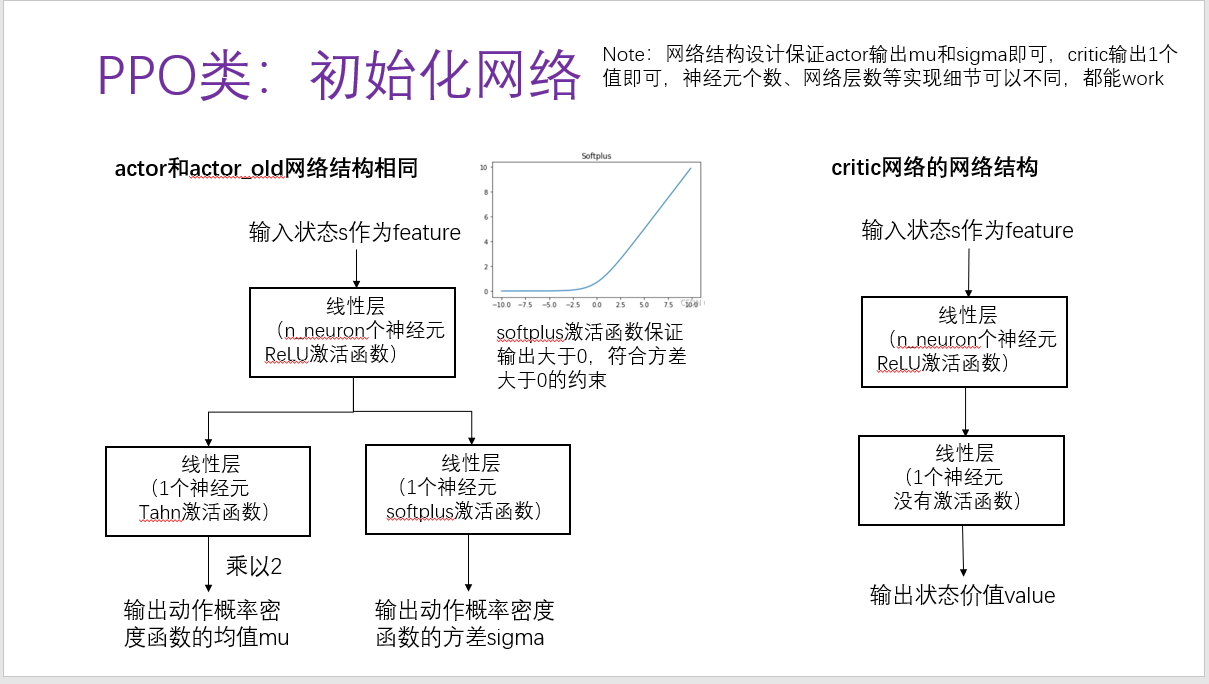
(1)初始化
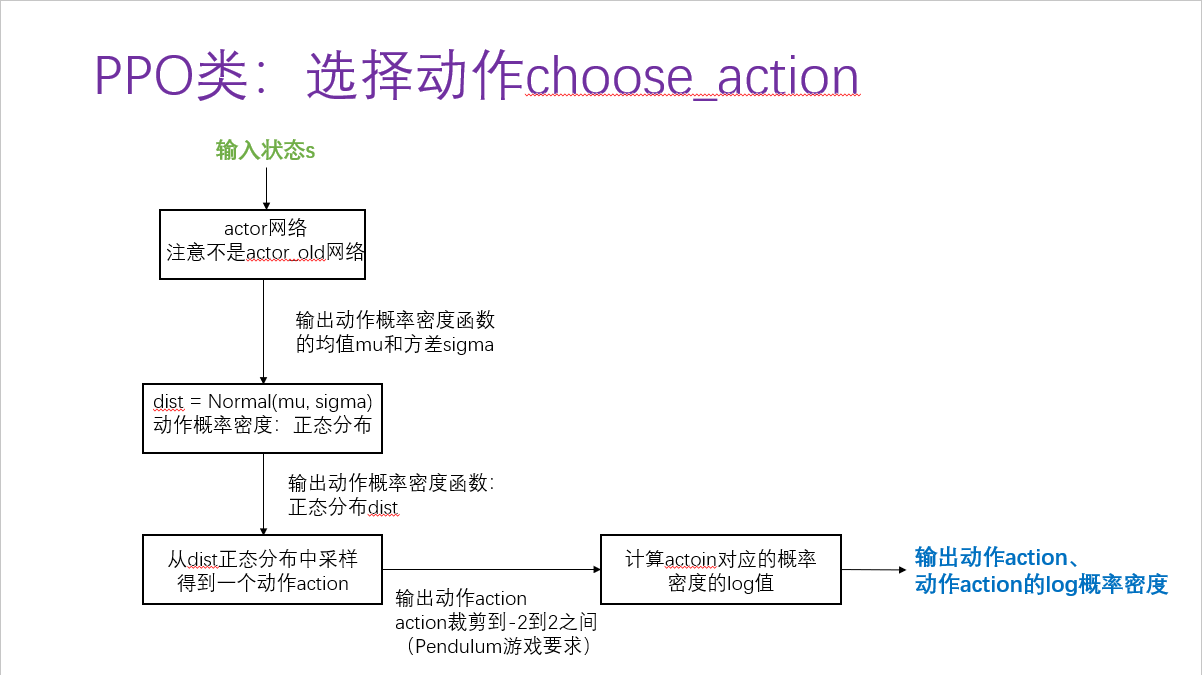
(2)选择动作
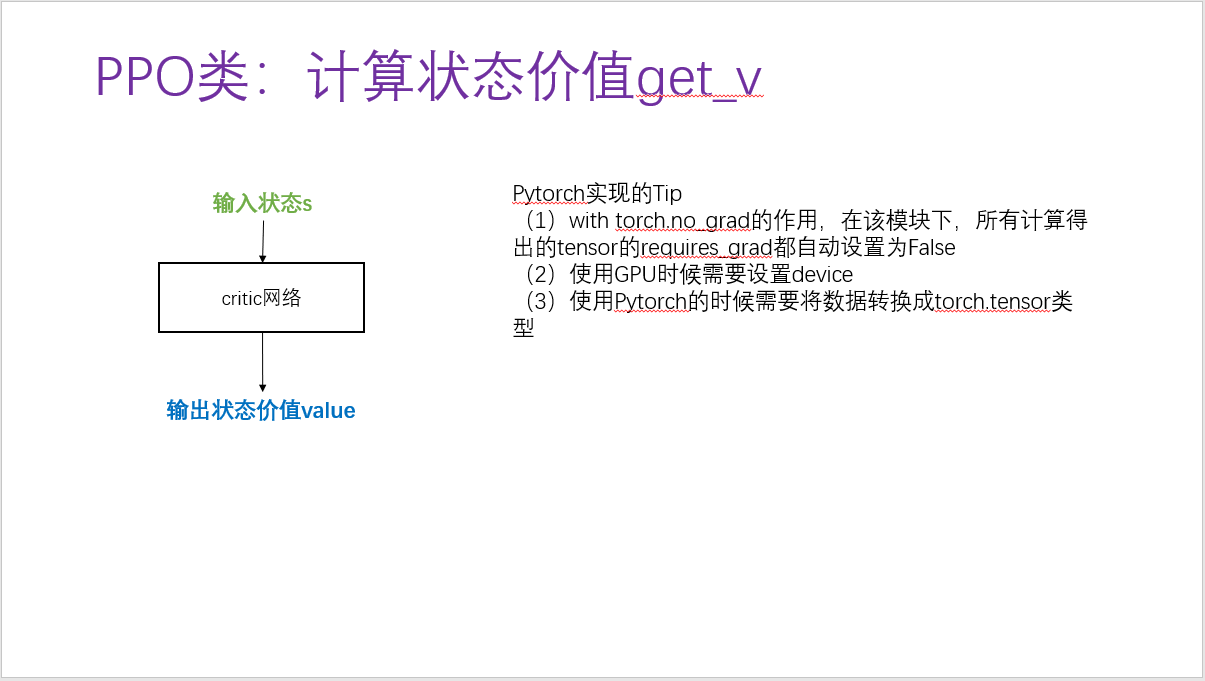
(3)计算状态价值
(4)更新/训练网络的update方法

KL penalty和Clip算法体现在更新actor网络方式不同,也就是下面流程图中的黄色框
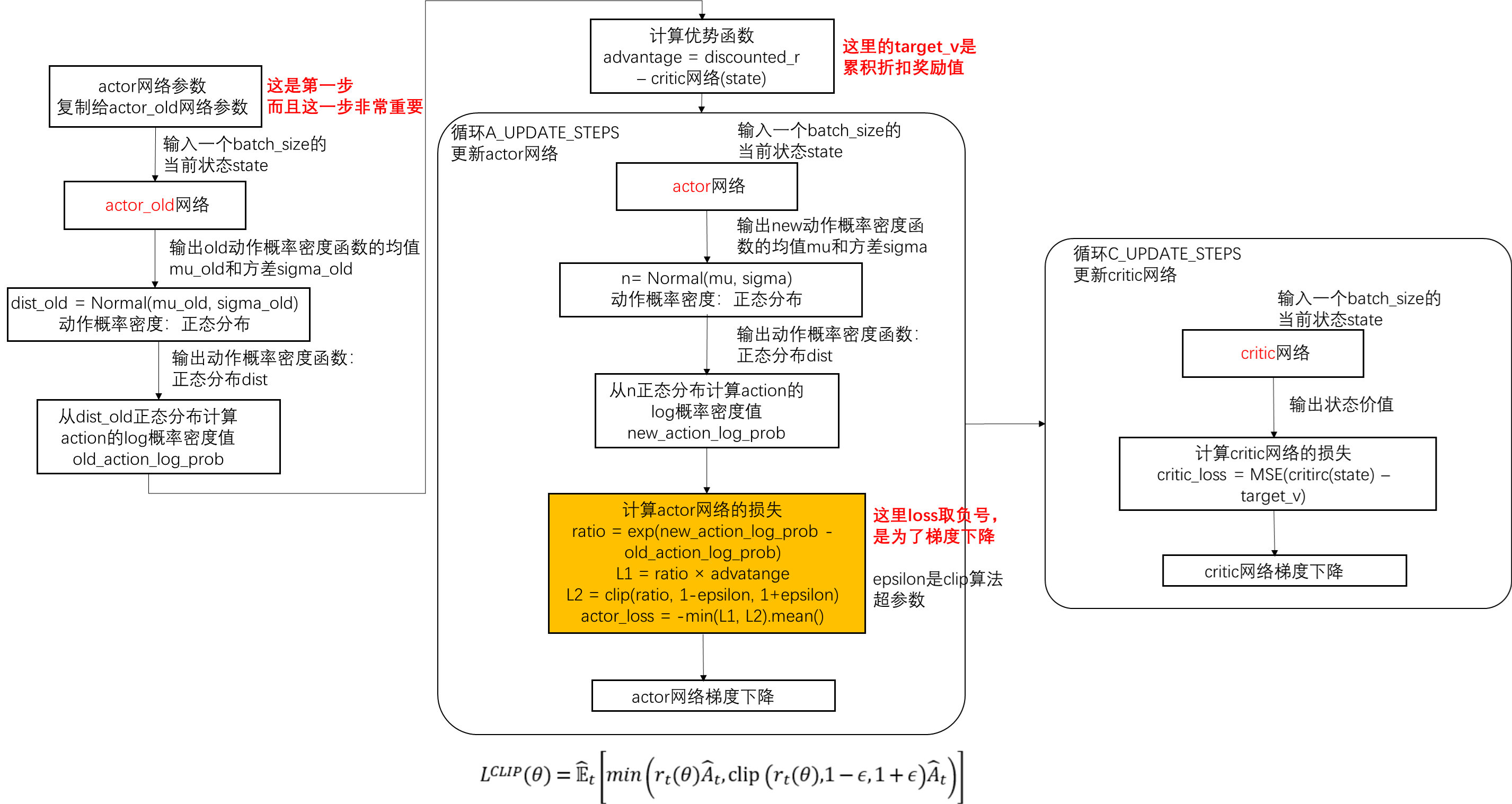
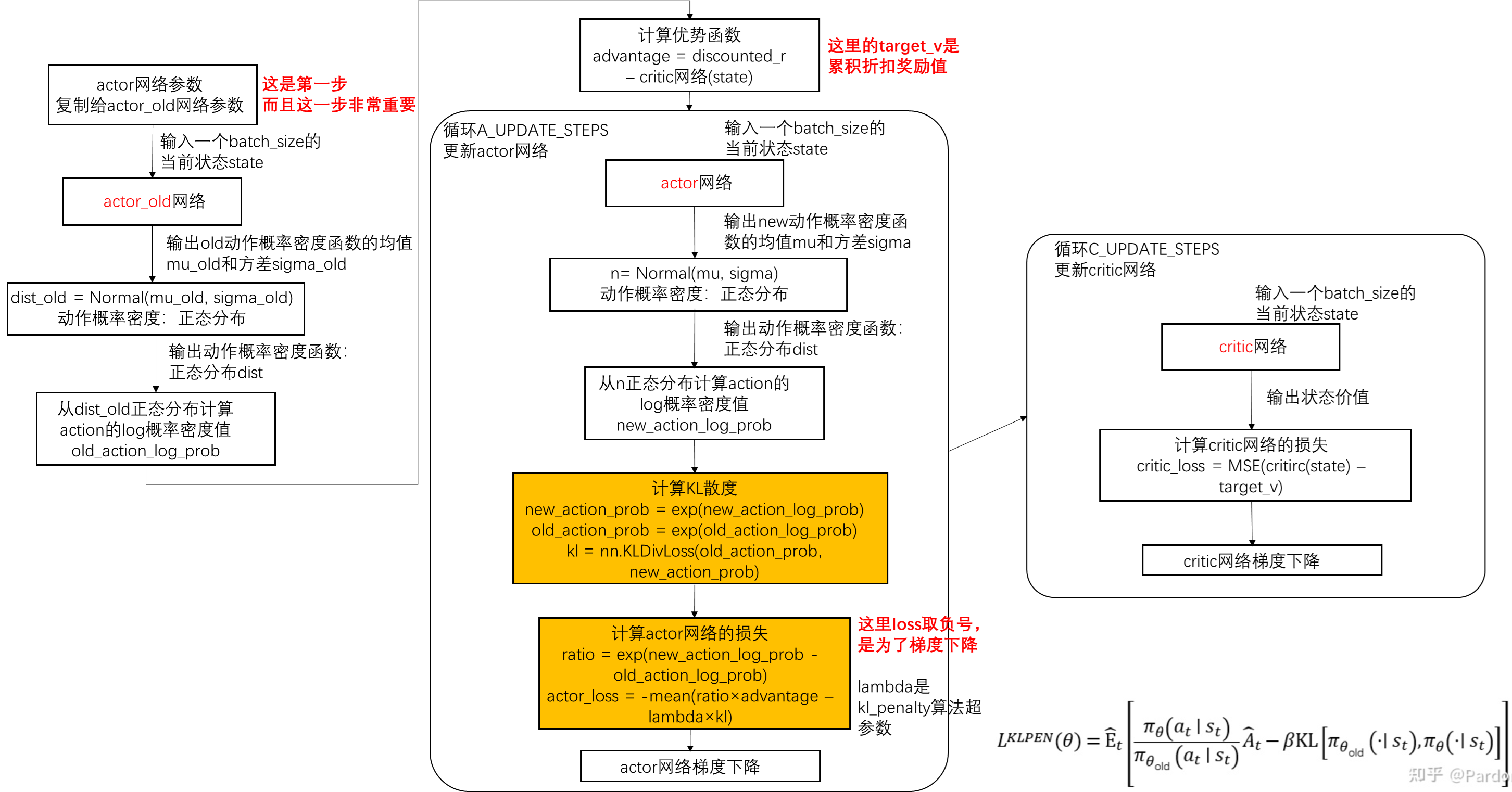
actor网络和critic网络更新实现不固定,上述算法是actor网络和critic网络分开更新,有的actor_loss和critic_loss加权后一块儿更新网络(代码请见simple_ppo.py),它们网络结构设计也不同
具体哪种方式效果更好并没有理论依据,往往需要尝试跑代码再结合具体问题选择喽
参考资料
(1)论文:Emergence of Locomotion Behaviours in Rich Environments
(2)论文:Proximal Policy Optimization Algorithms
(3)莫烦Python
(4)PPO2代码 pytorch框架 - 知乎 https://zhuanlan.zhihu.com/p/538486008,这是一份可以跑通的代码,很赞
(5)B站李宏毅强化学习课程,讲解数学原理非常厉害
(6)这份教程是李宏毅强化学习的深入讲解,也和不错:ChatGPT和PPO(中文介绍)_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1sg4y1p7hw/?spm_id_from=333.1007.top_right_bar_window_custom_collection.content.click&vd_source=1565223f5f03f44f5674538ab582448c

