- 1《决胜B端》读书笔记07:B端产品的需求管理_在b端产品的需求管理工作中,以下说法正确的是
- 2B+树与B树的区别、Hash索引与B+树索引的区别_索引b树和b+树的区别
- 3学堂在线课程字幕下载_学堂在线的字幕怎么提取
- 4【C++】哈希应用:位图 哈希切分 布隆过滤器
- 5YOLO电动车检测识别数据集:12617张图像,yolo标注完整_电动车的图片数据集
- 6Linux环境搭建和安装步骤_vmware-workstation-full-17.0.0-20800274
- 7coalesce函数_pgsql coalesce
- 8Linux驱动开发
- 9【百度松果菁英班】码蹄集题库5(优化版)_码蹄集答案
- 10800 篇顶会论文纵览推荐系统的前沿进展(转载)_user-event graph embedding learning for context-aw
看图识药,python开发实现基于VisionTransformer的119种中草药图像识别系统_中药材识别建模
赞
踩
中药药材图像识别相关的实践在前面的系列博文中已经有了相应的实践了,感兴趣的话可以自行移步阅读即可,每篇文章的侧重点不同:
《python基于轻量级GhostNet模型开发构建23种常见中草药图像识别系统》
《基于轻量级MnasNet模型开发构建40种常见中草药图像识别系统》
《基于ResNet模型的908种超大规模中草药图像识别系统》
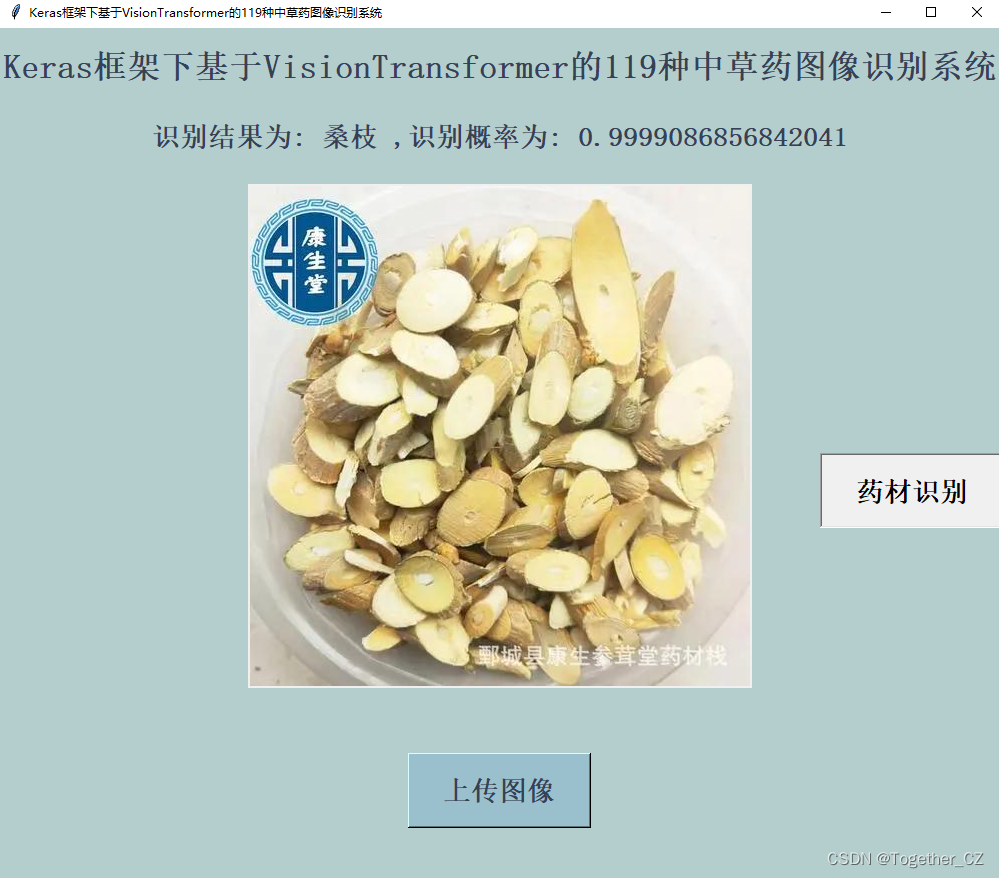
本文的核心思想是想要应用实践VIT(Vision Transformer)来开发构建图像识别系统,首先看下实例效果:
Vision Transformer(ViT)是一种基于自注意力机制的视觉模型,用于图像分类和其他计算机视觉任务。它是由Dosovitskiy等人在2020年提出的,将Transformer模型成功应用于图像领域。
ViT的构建原理如下:
-
输入图像划分为固定大小的图像块(或称为“补丁”),并通过一个线性变换将每个图像块映射为一个向量。这些向量组成了输入序列。
-
使用位置编码将位置信息引入输入序列。位置编码是一个学习的过程,用于为每个输入位置提供相对和绝对位置信息。
-
输入序列首先通过多头注意力(Multi-Head Attention)模块进行处理。多头注意力允许模型在不同的表示子空间中学习关注不同的图像特征。
-
在多头注意力模块中,每个补丁向量都与其他补丁向量进行交互,并计算其自注意力得分。这些得分表示了补丁之间的相关性,模型可以根据这些得分对不同补丁的重要性进行加权。
-
通过加权和补丁向量的线性组合,得到了每个补丁向量的新表示。这个表示包含了该补丁与其他补丁的相关性信息。
-
接下来,通过一个前馈神经网络(Feed-Forward Network)对每个补丁向量的新表示进行非线性变换,以更好地捕捉图像特征。
-
经过多个注意力和前馈神经网络堆叠的层,最终得到了一个编码了整个图像信息的向量序列。
-
为了进行图像分类,可以使用一个全局平均池化层(Global Average Pooling)将向量序列转换为一个固定长度的向量表示。然后,可以通过一个全连接层将这个向量映射到不同类别的概率分布。
总体来说,Vision Transformer通过将图像划分为补丁并利用自注意力机制对这些补丁进行交互,实现了对图像特征的学习和编码。相较于传统的卷积神经网络,ViT不需要使用卷积操作,而是完全基于自注意力机制进行图像特征的建模。
本文使用到的数据集来源于网络数据采集与人工处理,主要是收集了常见的100多种中药药材,数据集加载解析处理实现如下:
- # 加载解析创建数据集
- if not os.path.exists("dataset.json"):
- train_dataset = []
- test_dataset = []
- all_dataset = []
- classes_list = os.listdir(datasetDir)
- classes_list.sort()
- num_classes = len(classes_list)
- if not os.path.exists("labels.json"):
- with open("labels.json","w") as f:
- f.write(json.dumps(classes_list))
- print("classes_list: ", classes_list)
- for one_label in os.listdir(datasetDir):
- oneDir = datasetDir + one_label + "/"
- for one_pic in os.listdir(oneDir):
- one_path = oneDir + one_pic
- one_ind = classes_list.index(one_label)
- all_dataset.append([one_ind, one_path])
- train_ratio = 0.90
- train_num = int(train_ratio * len(all_dataset))
- all_inds = list(range(len(all_dataset)))
- train_inds = random.sample(all_inds, train_num)
- test_inds = [one for one in all_inds if one not in train_inds]
- for one_ind in train_inds:
- train_dataset.append(all_dataset[one_ind])
- for one_ind in test_inds:
- test_dataset.append(all_dataset[one_ind])
简单看下实例数据:
【艾叶】

【陈皮】

【党参】

【何首乌】

基础的vit实现如下:
- import tensorflow as tf
- from tensorflow.keras import layers
-
- def create_vision_transformer(input_shape, num_classes, num_layers, d_model, num_heads, mlp_dim, dropout_rate):
- inputs = tf.keras.Input(shape=input_shape)
- x = layers.Conv2D(filters=d_model, kernel_size=1)(inputs)
- x = layers.Reshape((-1, d_model))(x)
- x = layers.LayerNormalization(epsilon=1e-6)(x)
-
- # Patch embeddings
- num_patches = x.shape[1]
- patch_size = x.shape[2]
- x = layers.MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(x, x)
- x = layers.Add()([x, inputs])
- x = layers.LayerNormalization(epsilon=1e-6)(x)
- x = layers.Conv1D(filters=d_model, kernel_size=1)(x)
- x = layers.LayerNormalization(epsilon=1e-6)(x)
-
- # Transformer Encoder layers
- for _ in range(num_layers):
- # Attention and MLP block
- y = layers.MultiHeadAttention(num_heads=num_heads, key_dim=d_model)(x, x)
- y = layers.Add()([y, x])
- y = layers.LayerNormalization(epsilon=1e-6)(y)
- y = layers.Conv1D(filters=mlp_dim, kernel_size=1, activation="relu")(y)
- y = layers.Conv1D(filters=d_model, kernel_size=1)(y)
- y = layers.Add()([y, x])
- x = layers.LayerNormalization(epsilon=1e-6)(y)
-
- # Classification head
- x = layers.GlobalAveragePooling1D()(x)
- x = layers.Dropout(rate=dropout_rate)(x)
- x = layers.Dense(units=num_classes, activation="softmax")(x)
-
- model = tf.keras.Model(inputs=inputs, outputs=x)
- return model
-
- # Example usage
- input_shape = (224, 224, 3)
- num_classes = 1000
- num_layers = 12
- d_model = 512
- num_heads = 8
- mlp_dim = 2048
- dropout_rate = 0.1
-
- model = create_vision_transformer(input_shape, num_classes, num_layers, d_model, num_heads, mlp_dim, dropout_rate)
- model.summary()
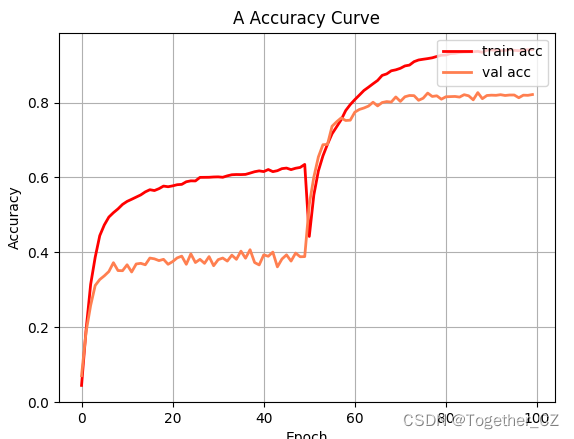
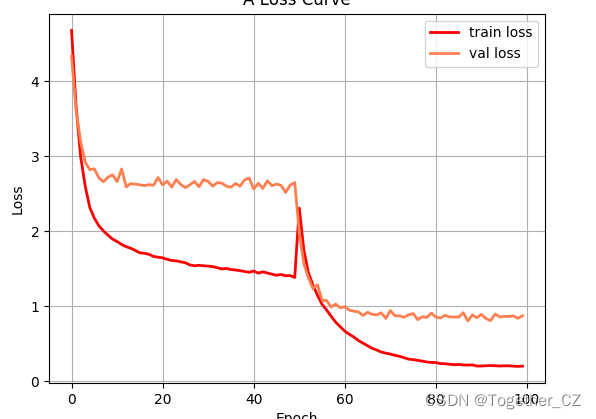
默认100次epoch的迭代计算,等待训练完成后对整体训练过程进行可视化,如下所示:
【准确率曲线】
【loss曲线】
可视化推理实例如下所示: