
热门标签
热门文章
- 1快速入门 FastAPI APIRouter:全面使用指南与技巧
- 2【NLP】用python实现文本转语音处理_python 文本转语音
- 3生成式AI - 基于大模型的应用架构与方案_基于大模型的应用系统设计
- 4神经机器翻译技术、Attention与Seq2Seq、Transformer_引用from .attention import seq_transformer
- 5搜索引擎:优势与不足一览_搜索引擎优缺点
- 6Skin Lesion Classification Using Ensembles of Multi-Resolution EfficientNets with Meta Data_isic2019
- 7DataWhale一周算法实践3---模型评估(accuracy、precision,recall和F-measure、auc值)_randomforestclassifier recall
- 8第十七届恩智浦杯室外ROS无人车竞速赛仿真搭建_室外ros无人车赛套件
- 9PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据_python使用神经网络预测数据并进行优化
- 10未明学院学员报告:做了微博数据分析后,我发现现在最火的明星原来是……_微博收到花数
当前位置: article > 正文
Python 使用TF-IDF_python tf-idf向量化模型代码 import tfidfvectorizer as tfi
作者:盐析白兔 | 2024-04-06 02:16:18
赞
踩
python tf-idf向量化模型代码 import tfidfvectorizer as tfidf
第一个 简易版本 直接来至 jieba 包,
一下代码直接来源 https://blog.csdn.net/qq_38923076/article/details/81630442
这里记录 进行对比
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence:待提取的文本语料
topK:返回 TF/IDF 权重最大的关键词个数,默认值为 20
withWeight:是否需要返回关键词权重值,默认值为 False
allowPOS:仅包括指定词性的词,默认值为空,即不筛选
————————————————
版权声明:本文为CSDN博主「碧空之戈」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_38923076/article/details/81630442
#简易版 from jieba import analyse tfidf = analyse.extract_tags #加载停用词 analyse.set_stop_words('stopword.txt') text = '6月19日,《2012年度“中国爱心城市”公益活动新闻发布会》在京举行。' + \ '中华社会救助基金会理事长许嘉璐到会讲话。基金会高级顾问朱发忠,全国老龄' + \ '办副主任朱勇,民政部社会救助司助理巡视员周萍,中华社会救助基金会副理事长耿志远,' + \ '重庆市民政局巡视员谭明政。晋江市人大常委会主任陈健倩,以及10余个省、市、自治区民政局' + \ '领导及四十多家媒体参加了发布会。中华社会救助基金会秘书长时正新介绍本年度“中国爱心城' + \ '市”公益活动将以“爱心城市宣传、孤老关爱救助项目及第二届中国爱心城市大会”为主要内容,重庆市' + \ '、呼和浩特市、长沙市、太原市、蚌埠市、南昌市、汕头市、沧州市、晋江市及遵化市将会积极参加' + \ '这一公益活动。中国雅虎副总编张银生和凤凰网城市频道总监赵耀分别以各自媒体优势介绍了活动' + \ '的宣传方案。会上,中华社会救助基金会与“第二届中国爱心城市大会”承办方晋江市签约,许嘉璐理' + \ '事长接受晋江市参与“百万孤老关爱行动”向国家重点扶贫地区捐赠的价值400万元的款物。晋江市人大' + \ '常委会主任陈健倩介绍了大会的筹备情况。' keywords = tfidf(text, topK=10, withWeight=False, allowPOS=()) print('结果为:') print([keyword for keyword in keywords]) 结果为: ['晋江市', '救助', '爱心', '基金会', '公益活动', '城市', '中华', '许嘉璐', '陈健倩', '孤老']

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
以下是函数版本:
from jieba import analyse def textrank_extract(text,keyword_num=10): textrank = analyse.textrank analyse.set_stop_words('stopword.txt') keywords = textrank(text, keyword_num) # 输出抽取出的关键词 for keyword in keywords: print(keyword + "/ ", end='') print() def tfidf_extract(text,keyword_num=10): tfidf = analyse.extract_tags analyse.set_stop_words('stopword.txt') keywords = tfidf(text, keyword_num) # 输出抽取出的关键词 for keyword in keywords: print(keyword + "/ ", end='') print() if __name__ == '__main__': text = '6月19日,《2012年度“中国爱心城市”公益活动新闻发布会》在京举行。' + \ '中华社会救助基金会理事长许嘉璐到会讲话。基金会高级顾问朱发忠,全国老龄' + \ '办副主任朱勇,民政部社会救助司助理巡视员周萍,中华社会救助基金会副理事长耿志远,' + \ '重庆市民政局巡视员谭明政。晋江市人大常委会主任陈健倩,以及10余个省、市、自治区民政局' + \ '领导及四十多家媒体参加了发布会。中华社会救助基金会秘书长时正新介绍本年度“中国爱心城' + \ '市”公益活动将以“爱心城市宣传、孤老关爱救助项目及第二届中国爱心城市大会”为主要内容,重庆市' + \ '、呼和浩特市、长沙市、太原市、蚌埠市、南昌市、汕头市、沧州市、晋江市及遵化市将会积极参加' + \ '这一公益活动。中国雅虎副总编张银生和凤凰网城市频道总监赵耀分别以各自媒体优势介绍了活动' + \ '的宣传方案。会上,中华社会救助基金会与“第二届中国爱心城市大会”承办方晋江市签约,许嘉璐理' + \ '事长接受晋江市参与“百万孤老关爱行动”向国家重点扶贫地区捐赠的价值400万元的款物。晋江市人大' + \ '常委会主任陈健倩介绍了大会的筹备情况。' print('TF-IDF模型结果:') tfidf_extract(text) print('TextRank模型结果:') textrank_extract(text) TF - IDF模型结果: 晋江市 / 救助 / 爱心 / 基金会 / 公益活动 / 城市 / 中华 / 许嘉璐 / 陈健倩 / 孤老 / TextRank模型结果: 城市 / 爱心 / 救助 / 中国 / 社会 / 晋江市 / 基金会 / 大会 / 介绍 / 公益活动 /
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
下面使用 sklearn 试试
from sklearn.feature_extraction.text import TfidfVectorizer, TfidfTransformer corpus = [ 'This This is the first document.', 'This This is the second second document.', 'And the third one.', 'Is this the first document?', ] tfidf_model = TfidfVectorizer() tfidf_matrix = tfidf_model.fit_transform(corpus) word_dict = tfidf_model.get_feature_names_out() print(word_dict) print(tfidf_matrix)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
案例二
from sklearn.feature_extraction.text import TfidfVectorizer, TfidfTransformer # 1 tfidf_model = TfidfVectorizer(binary=False, decode_error='ignore', stop_words='english') vec = tfidf_model.fit_transform(corpus) tfidf_model.get_feature_names() # 2 from sklearn.feature_extraction.text import TfidfVectorizer tfidf_model = TfidfVectorizer(stop_words='english', ngram_range=(1, 1), analyzer='word', max_df=.57, binary=False, token_pattern=r"\w+",sublinear_tf=False) vec = tfidf_model.fit_transform(corpus) tfidf_model.get_feature_names_out() # stop_words:string {'english'}, list, or None(default)如果为english,用于英语内建的停用词列表。 # - 如果为list,该列表被假定为包含停用词,列表中的所有词都将从令牌中删除; # - 如果None,不使用停用词。 # ngram_range(min,max):是指将text分成min,min+1,min+2,.........max 个不同的词组。 # 比如'Python is useful'中ngram_range(1,3)之后可得到'Python' 'is' 'useful' 'Python is' 'is useful' 和'Python is useful' # 如果是ngram_range (1,1) 则只能得到单个单词'Python' 'is'和'useful' # analyzer:string,{'word', 'char'} or callable定义特征为词(word)或n-gram字符 # max_df可以被设置为范围[0.7, 1.0)的值,基于内部预料词频来自动检测和过滤停用词。 # max_df: float in range [0.0, 1.0] or int, optional, 1.0 by default当构建词汇表时,严格忽略高于给出阈值的文档频率的词条,语料指定的停用词。 # - 如果是浮点值,该参数代表文档的比例,整型绝对计数值,如果词汇表不为None,此参数被忽略。 # binary:boolean, False by default # - 如果为True,所有非零计数被设置为1,这对于离散概率模型是有用的,建立二元事件模型,而不是整型计数。 # token_pattern: 正则表达式显示了”token“的构成,仅当analyzer == ‘word’时才被使用。 # sublinear_tf:boolean, optional应用线性缩放TF,例如,使用1+log(tf)覆盖tf
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
TF-IDF 分词
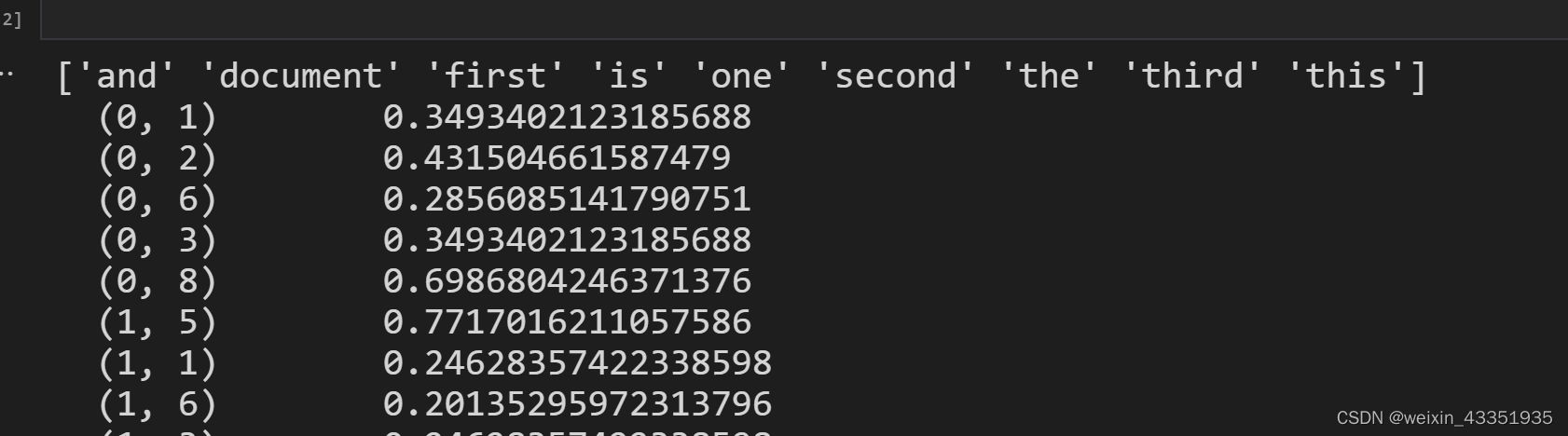
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
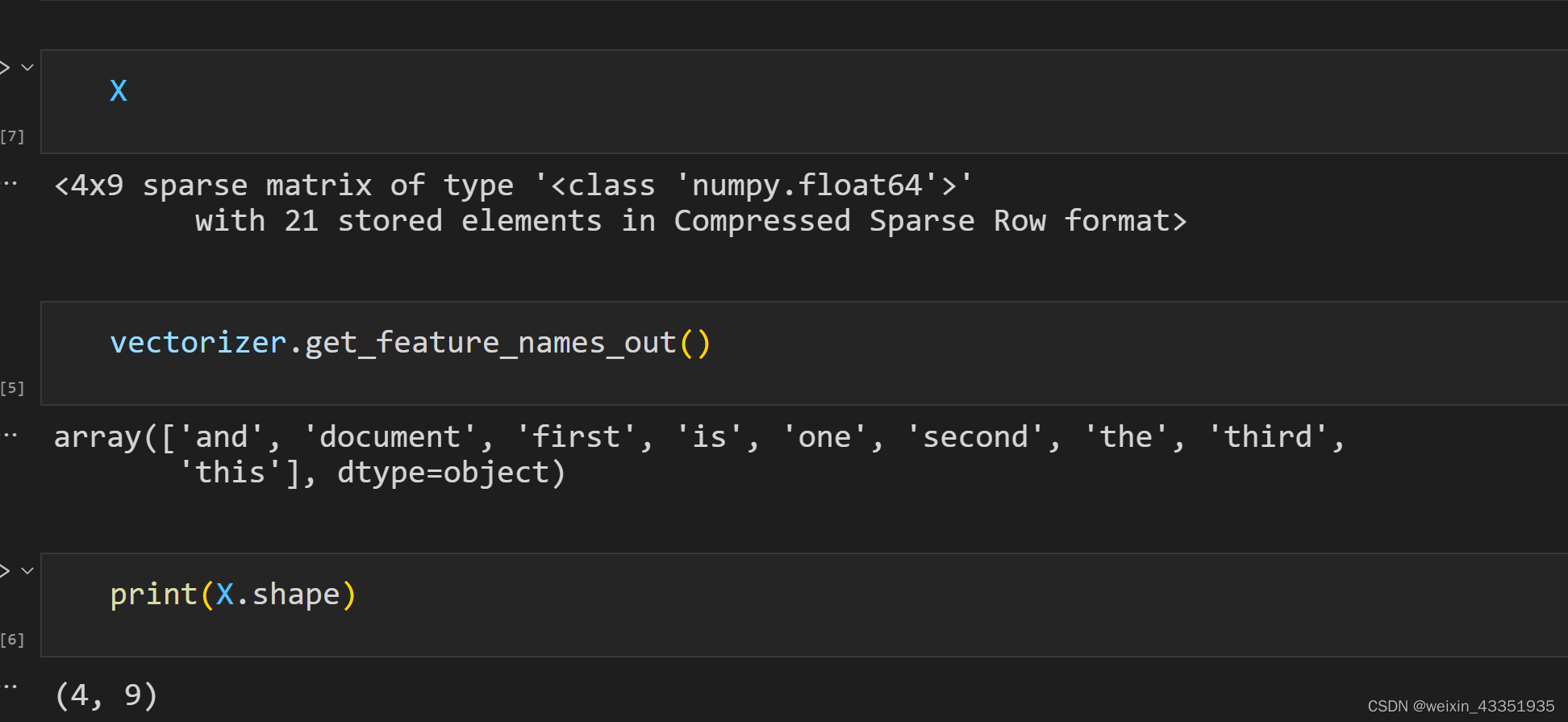
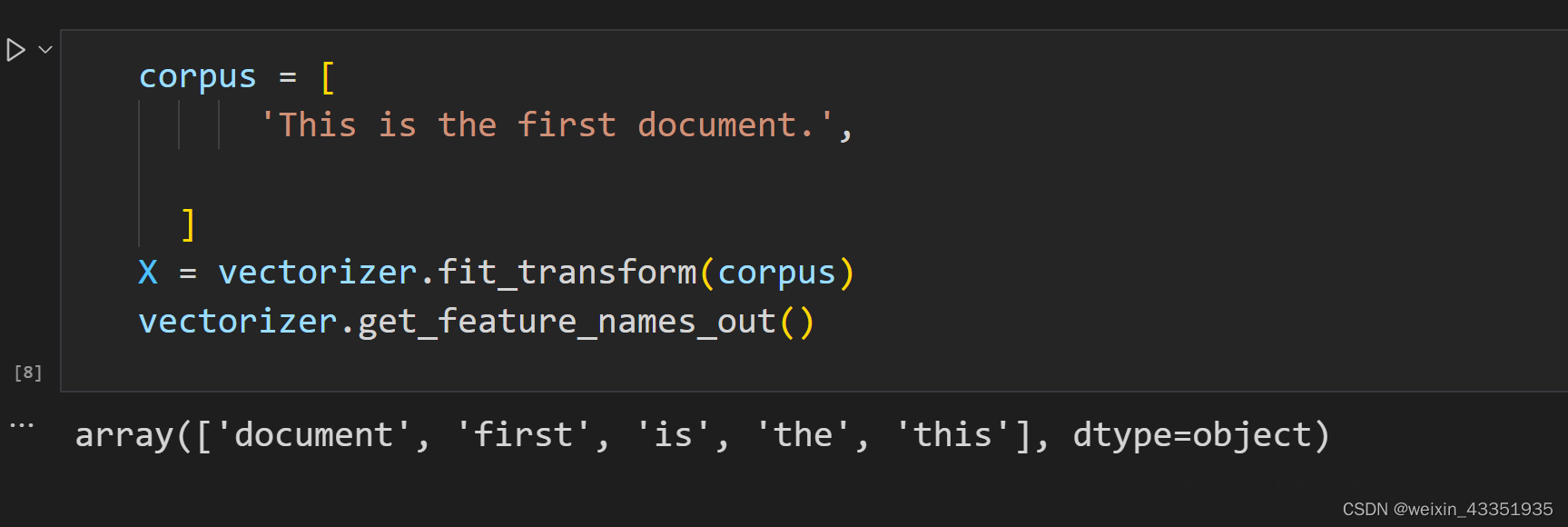
corpus = [
'This is the first document.',
]
X = vectorizer.fit_transform(corpus)
vectorizer.get_feature_names_out()
- 1
- 2
- 3
- 4
- 5
- 6
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
text = {"good movie", "not a good movie", "did not like",
"i like it", "good one"}
tfidf = TfidfVectorizer(min_df=2, max_df=0.5, ngram_range=(1, 2))
features = tfidf.fit_transform(texts)
pd.DataFrame(
features.todense(),
columns=tfidf.get_feature_names()
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签

