
- 1大型语言模型(LLM)技术精要_首创将大语言模型(llm)技术引入静态白盒检测场景,进一步降低了白盒测试的误报率,
- 2Harmony OS 父子组件传参_鸿蒙 组件传参
- 3AKShare 快速入门
- 4Spring Boot 与 Spring Security_springboot springsecurity
- 5python--素数求和_python判断素数相加
- 6IP如何异地共享文件?
- 7Java System#exit 无法退出程序的问题探索_system.exit(-1)进程未退出
- 8鸿蒙入门开发教程:一文带你详解工具箱元服务的开发流程_鸿蒙元服务预加载
- 9Java面试八股文整理
- 10详细教程 - 进阶版 鸿蒙harmonyOS应用 第十七节——鸿蒙OS多线程编程指南_鸿蒙 多线程
10分钟揭秘Sora原理
赞
踩
相信大家这几天都被一个叫Sora的模型刷屏了。2月15号在OpenAI视频生成模型Sora亮相后,大众的目光立马从谷歌刚刚发布的Gemini1.5转移走。马斯克甚至评论到人类玩球了,而在这之前马斯克多次对OpenAI发出过AI觉醒警告,那这次OpenAI到底掷下了怎样一枚儿AI导弹引发如此热议,Sora背后的原理又是怎样的呢?
首先,Sora并不是第一个视频生成模型,Runway,Stability AI,Pika Labs等都在23年展示过视频生成能力,但是他们的生成长度没有一个超过18秒,大多模型的能力还停留在生成3秒4秒的视频,而Sora能够实现60秒的一镜到底,要知道长时间一镜到底可不容易。

因为对模型理解现实世界的物理规律要求很高,比如正确表现事物之间的互相作用,镜头转动后主体仍然需要保持一致和连贯等等。
对于我们人类来说,基于当前画面预测下一帧并不难,但要模型理解两帧画面之间的逻辑关联就需要做很多的工作。
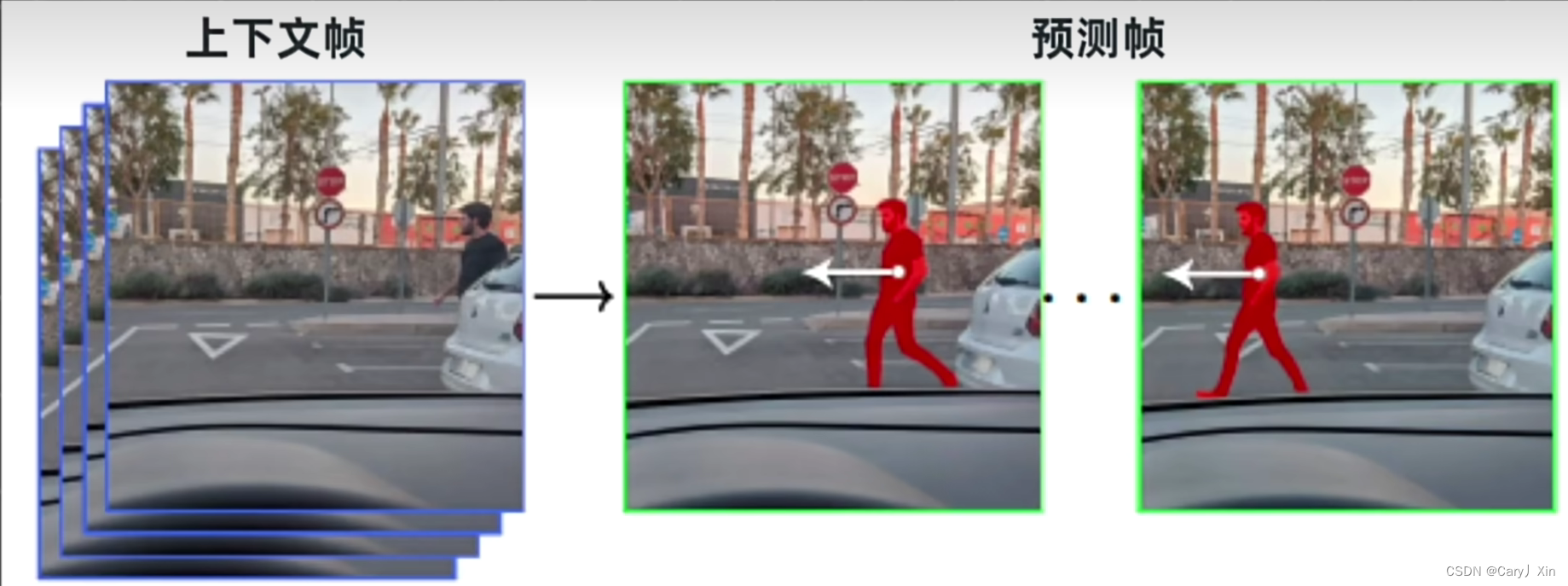
除了在时长上碾压之前的模型,Sora还能生成不同宽高比和分辨率的视频,具体来说宽屏1920×1080p,竖屏1080×1920p以及之间的所有分辨率都可以,所以生成内容能够支持不同的设备。

根据OpenAi官方的技术报告,Sora和之前模型的不同之处在于它采用Diffusion Transformer,融合了diffusion模型以及transformer模型。Stable Diffusion、DALL-E-2等图片生成模型都是基于Diffusion模型及扩散模型的。

扩散模型的灵感来源是非平衡热力学。生成图像的过程中,就像是把一滴墨水在水中扩散的过程进行倒放,扩散模型会基于随机过程,从噪声图像中逐步去除噪声来生成满足要求的图像。
模型的训练过程包括前向扩散和反向扩散,前向扩散会逐步对一张真实的照片随机添加噪声直到变成纯噪声图片,反向扩散是从纯噪声图片中去除噪声,逐步生成清晰的图像。那通过反复迭代训练,模型会逐渐学会如何更准确的从噪声中重建数据,生成质量越来越高的输出。


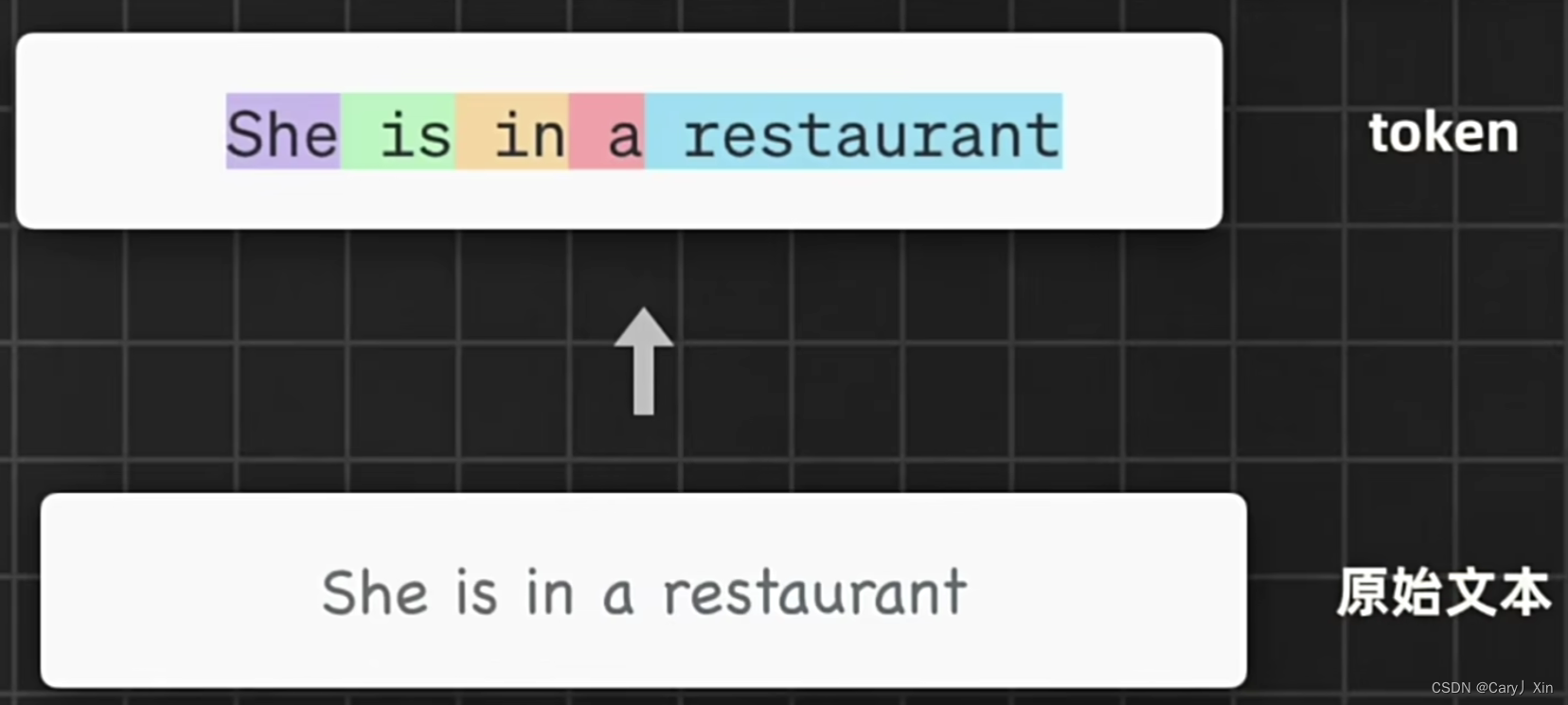
而Transformer模型则是当前主流文本生成模型的根基,包括GPT,BERT,文心一言等等。原始的transformer架构,包括编码器和解码器,输入文本首先会被Token化,也就是被拆分成一个个基本单位。
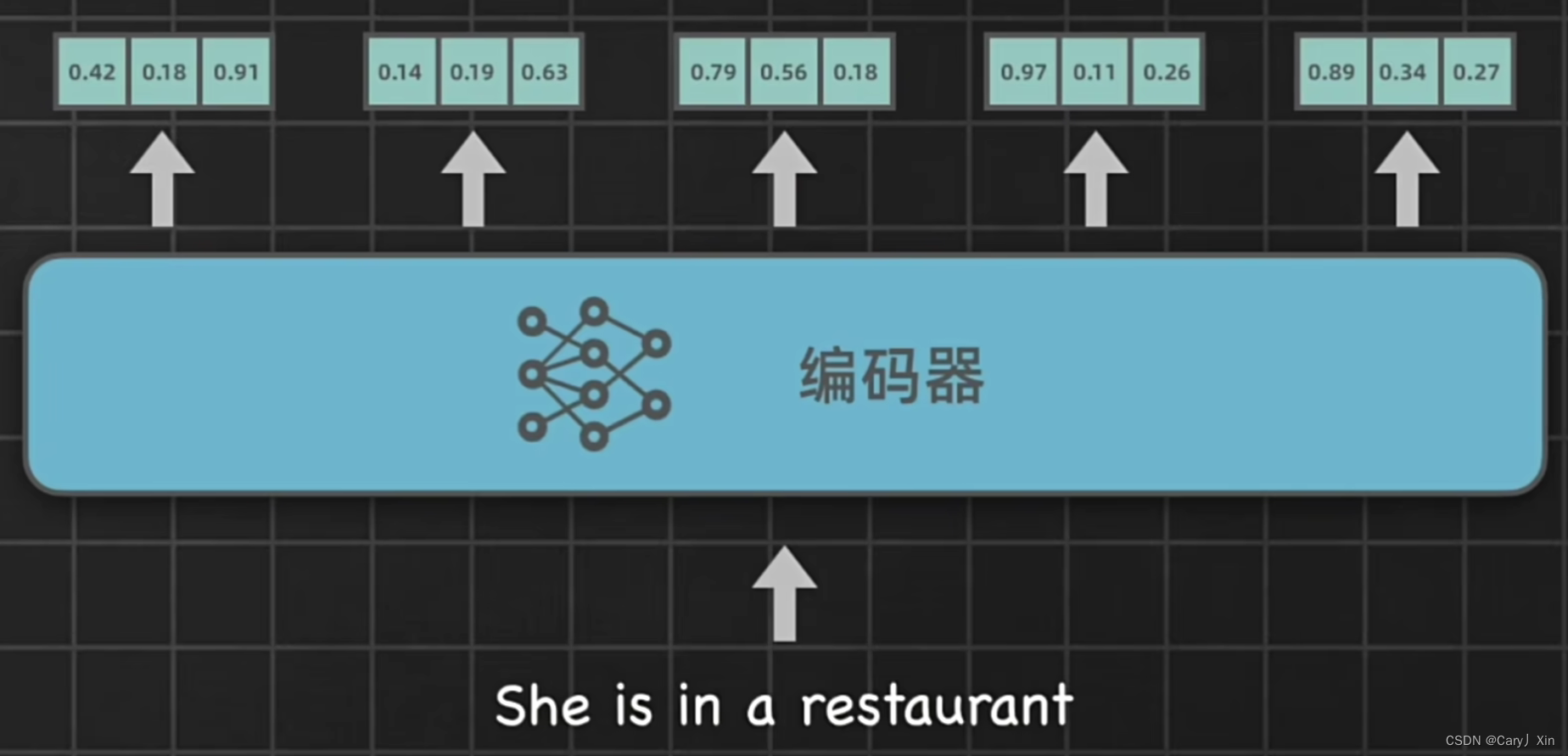
其中编码器负责把输入转换成一种更抽象的向量表示,里面既保留了输入文本的词汇信息和顺序关系,也捕捉了语法语义上的关键特征。
而解码器则负责基于编码器的输出来生成目标序列。解码器不仅会把前面得到的抽象表示作为输入,还会把之前已经生成的文本也作为输入来保持输出的连贯性和上下文相关性。
Diffusion Transformer模型则是对两者进行了融合。

在Sora模型中,openai针对视频内容引入了和Transformer里文本内容的token相似的基本单位patch。
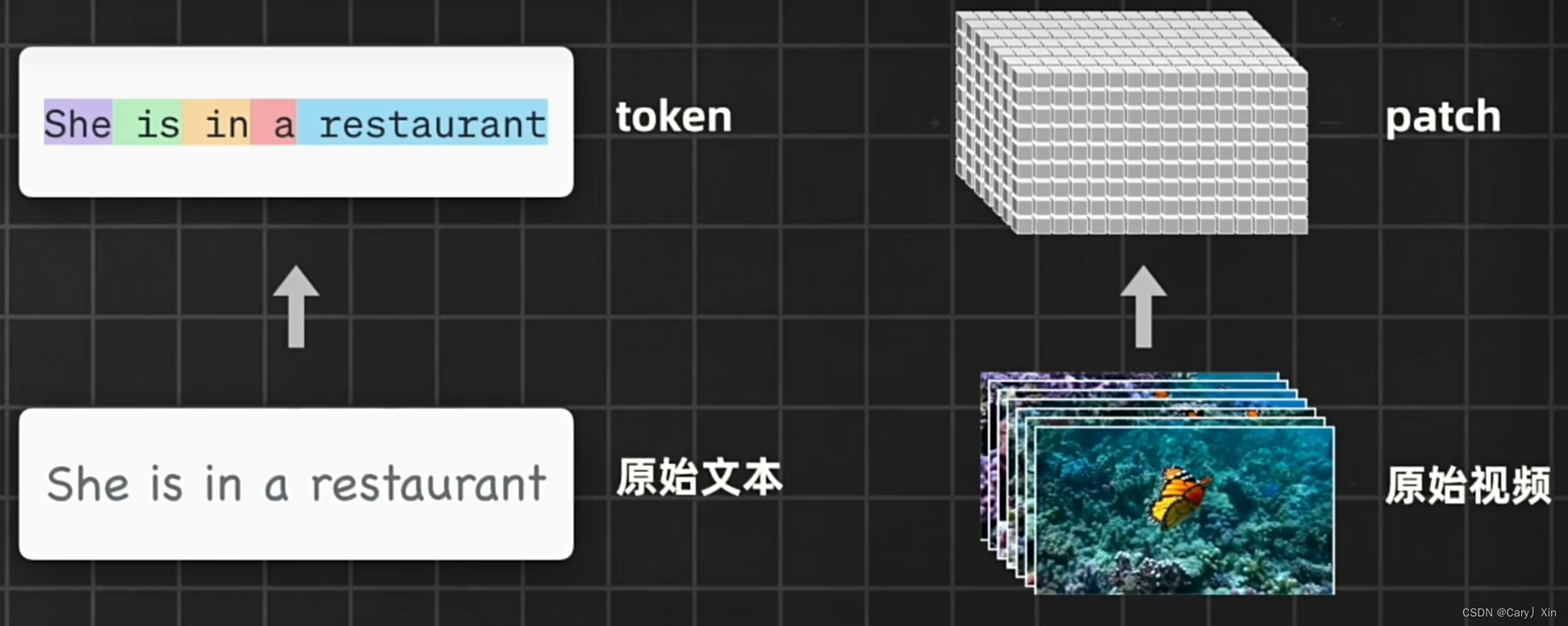
具体来说视频数据会通过视觉编码器被压缩成低维度的时间及空间潜在表示,并被分解成时空patch。


因为针对视频里的任意部分,不仅需要关注它在当前帧上的空间位置,也是要关注它在整个视频里的时间位置, Sora会在压缩后的潜在空间中训练以及后续进行生成。由于Sora属于扩散模型,给它噪声Patch以及对应的文本提示作为输入,被训练来生成清晰的Patch,Open AI也训练出了对应的解码器,负责把生成的低维度潜在时空表示转化为高维度可视化的视频像素。

虽然所有的视频生成能力碾压过往模型,但是仍然会生成有瑕疵和逻辑硬伤的视频,比如身体互相穿过的狼崽,以及吹不动的蜡烛,飘浮在空中的椅子等等。

不过生成视频里的"灵异现象"并没有减少Sora的惊艳感。马斯克说有了AI加持的人类将在未来几年里创造出最好的作品。
英伟达科学家范麟熙表示,这是视频生成的GPT3时刻。GPT3在2020年推出的时候,生成的文本存在各种硬伤,但它也展现出了惊人的情境学习能力。

经过后续更大规模的训练后,Sora有可能出现精准模拟现实世界的智能涌现,就像一个没来过地球的外星人在持续不断观看人类生产的无数部电影后,对地球上各种现象的推测也可能逐渐准确,这会是一条通往世界通用模型的路,既学习世界如何运作,并能真实模拟现实世界未来世界的AI系统。
不过关于Sora也存在很多争议,比如图灵奖获得者杨立坤表示,生成看起来像现实的视频模型距离真正理解物理世界还远得很。

但在Sora成为世界模型之前,它的出现已经重击了一批专注于视频生成的AI初创公司,并且有重塑影视广告动画游戏等行业的势头,也顺手干掉了视频版权素材公司。就像《三体2》里的那句话——毁灭你与你有何相干。

