
- 1有关神经网络的训练算法,神经网络训练过程详解_训练算法和神经网络的联系
- 2OpenHarmony开发板无法运行端云一体化项目的解决方案【坚果派-咸鱼】_replaceurl' can't support crossplatform applicatio
- 3文献学习-22-Surgical-VQLA:具有门控视觉语言嵌入的转换器,用于机器人手术中的视觉问题本地化回答
- 4NER任务语料_bosonnlp_ner_6c
- 5随身WIFI的刷机(debian系统)_随身wifi刷机
- 6excel if in函数_excel中if函数的使用技巧
- 7java中文转换拼音(HanLP)_java hanlp怎么把文字转全拼
- 8浅谈api工厂:前端Paas中台
- 9Transformer位置编码代码讲解_transformer时间戳编码
- 10一文带你了解爆火的Chat GPT_chatgpt csdn
多种方法爬取猫眼电影并分析(附代码)
赞
踩

数据科学俱乐部
中国数据科学家社区
 ♚
♚
作者:苏克,零基础转行python爬虫与数据分析
博客:https://www.makcyun.top
摘要: 作为小白,爬虫可以说是入门python最快和最容易获得成就感的途径。因为初级爬虫的套路相对固定,常见的方法只有几种,比较好上手。选取网页结构较为简单的猫眼top100电影为案例进行练习。 重点是用上述所说的4种方法提取出关键内容。一个问题采用不同的解决方法有助于拓展思维,通过不断练习就能够灵活运用。
本文知识点:
Requsts 请求库的使用
beautiful+lxml两大解析库使用
正则表达式 、xpath、css选择器的使用
1. 为什么爬取该网页?
比较懒,不想一页页地去翻100部电影的介绍,想在一个页面内进行总体浏览(比如在excel表格中);
想深入了解一些比较有意思的信息,比如:哪部电影的评分最高?哪位演员的作品数量最多?哪个国家/地区上榜的电影数量最多?哪一年上榜的电影作品最多等。这些信息在网页上是不那么容易能直接获得的,所以需要爬虫。
2. 爬虫目标
从网页中提取出top100电影的电影名称、封面图片、排名、评分、演员、上映国家/地区、评分等信息,并保存为csv文本文件。
根据爬取结果,进行简单的可视化分析。
平台:windows7 + SublimeText3
3. 爬取步骤
3.1. 网址URL分析
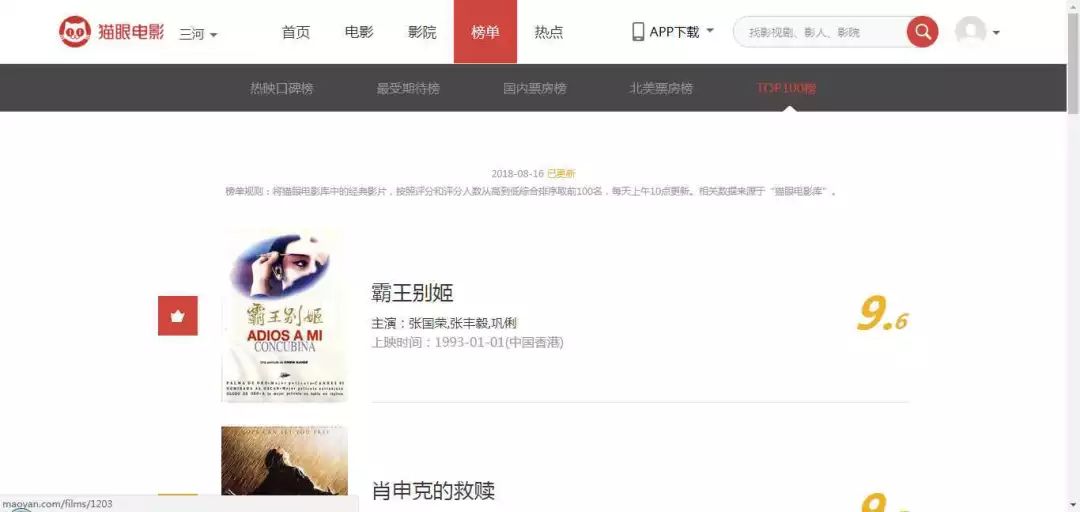
首先,打开猫眼Top100的url网址: http://maoyan.com/board/4?offset=0。页面非常简单,所包含的信息就是上述所说的爬虫目标。下拉页面到底部,点击第2页可以看到网址变为:http://maoyan.com/board/4?offset=10。因此,可以推断出url的变化规律:offset表示偏移,10代表一个页面的电影偏移数量,即:第一页电影是从0-10,第二页电影是从11-20。因此,获取全部100部电影,只需要构造出10个url,然后依次获取网页内容,再用不同的方法提取出所需内容就可以了。
下面,用requests方法获取第一个页面。
3.2. Requests获取首页数据
先定义一个获取单个页面的函数:get_one_page(),传入url参数。
1def get_one_page(url): 2 try: 3 headers = { 4 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'} 5 # 不加headers爬不了 6 response = requests.get(url, headers=headers) 7 if response.status_code == 200: 8 return response.text 9 else:10 return None11 except RequestException:12 return None13 # try-except语句捕获异常接下来在main()函数中设置url。
1def main():2 url = 'http://maoyan.com/board/4?offset=0'3 html = get_one_page(url)4 print(html)567if __name__ == '__main__':8 main()运行上述程序后,首页的源代码就被爬取下来了。如下图所示:
接下来就需要从整个网页中提取出几项我们需要的内容,用到的方法就是上述所说的四种方法,下面分别进行说明。
3.3. 4种内容解析提取方法
3.3.1. 正则表达式提取
第一种是利用正则表达式提取。
什么是正则表达式? 下面这串看起来乱七八糟的符号就是正则表达式的语法。
1'<dd>.*?board-index.*?>(d+)</i>.*?src="(.*?)".*?name"><a.*?>(.*?)</a>.*?'它是一种强大的字符串处理工具。之所以叫正则表达式,是因为它们可以识别正则字符串(regular string)。可以这么定义:“ 如果你给我的字符串符合规则,我就返回它”;“如果字符串不符合规则,我就忽略它”。通过requests抓取下来的网页是一堆大量的字符串,用它处理后便可提取出我们想要的内容。
如果还不了解它,可以参考下面的教程:
http://www.runoob.com/regexp/regexp-syntax.html
https://www.w3cschool.cn/regexp/zoxa1pq7.html
下面,开始提取关键内容。右键网页-检查-Network选项,选中左边第一个文件然后定位到电影信息的相应位置,如下图:
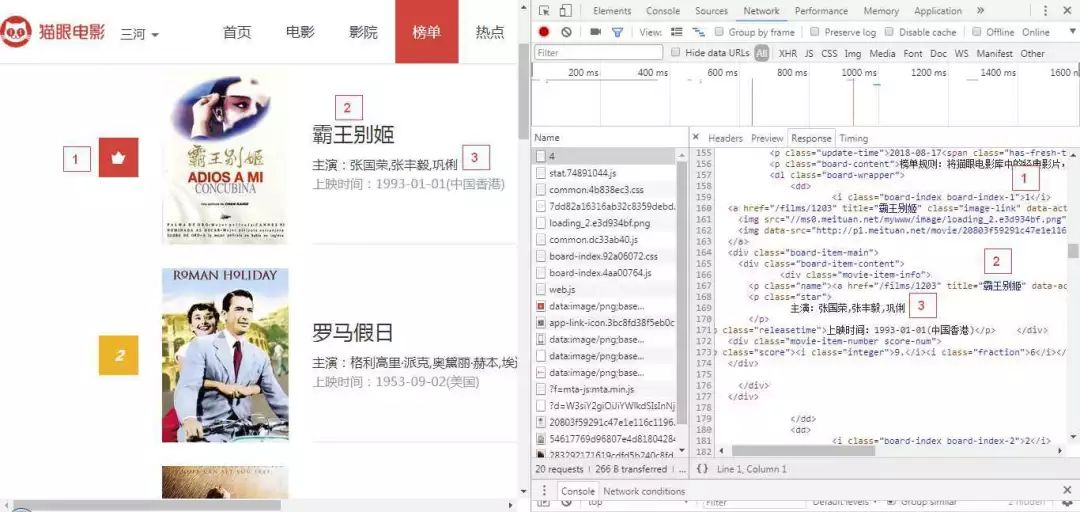
可以看到每部电影的相关信息都在dd这个节点之中。所以就可以从该节点运用正则进行提取。
第1个要提取的内容是电影的排名。它位于class="board-index"的i节点内。不需要提取的内容用'.*?'替代,需要提取的数字排名用()括起来,()里面的数字表示为(d+)。正则表达式可以写为:
1'<dd>.*?board-index.*?>(d+)</i>'接着,第2个需要提取的是封面图片,图片网址位于img节点的'src'属性中,正则表达式可写为:
1'src="(.*?)".*?'第1和第2个正则之间的代码是不需要的,用'.*?'替代,所以这两部分合起来写就是:
1'<dd>.*?board-index.*?>(d+)</i>.*?src="(.*?)"同理,可以依次用正则写下主演、上映时间和评分等内容,完整的正则表达式如下:
1'<dd>.*?board-index.*?>(d+)</i>.*?src="(.*?)".*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>'正则表达式写好以后,可以定义一个页面解析提取方法:parse_one_page(),用来提取内容:
1def parse_one_page(html): 2 pattern = re.compile( 3 '<dd>.*?board-index.*?>(d+)</i>.*?src="(.*?)".*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S) 4 # re.S表示匹配任意字符,如果不加,则无法匹配换行符 5 items = re.findall(pattern, html) 6 # print(items) 7 for item in items: 8 yield { 9 'index': item[0],10 'thumb': get_thumb(item[1]), # 定义get_thumb()方法进一步处理网址11 'name': item[2],12 'star': item[3].strip()[3:],13 # 'time': item[4].strip()[5:],14 # 用两个方法分别提取time里的日期和地区15 'time': get_release_time(item[4].strip()[5:]),16 'area': get_release_area(item[4].strip()[5:]),17 'score': item[5].strip() + item[6].strip()18 # 评分score由整数+小数两部分组成19 }Tips:
re.S:匹配任意字符,如果不加,则无法匹配换行符;
yield:使用yield的好处是作为生成器,可以遍历迭代,并且将数据整理形成字典,输出结果美观。具体用法可参考:https://blog.csdn.net/zhangpinghao/article/details/18716275;
.strip():用于去掉字符串中的空格。
上面程序为了便于提取内容,又定义了3个方法:get_thumb()、get_release_time()和 get_release_area():
1# 获取封面大图 2def get_thumb(url): 3 pattern = re.compile(r'(.*?)@.*?') 4 thumb = re.search(pattern, url) 5 return thumb.group(1) 6# http://p0.meituan.net/movie/5420be40e3b755ffe04779b9b199e935256906.jpg@160w_220h_1e_1c 7# 去掉@160w_220h_1e_1c就是大图 8 910# 提取上映时间函数11def get_release_time(data):12 pattern = re.compile(r'(.*?)((|$)')13 items = re.search(pattern, data)14 if items is None:15 return '未知'16 return items.group(1) # 返回匹配到的第一个括号(.*?)中结果即时间171819# 提取国家/地区函数20def get_release_area(data):21 pattern = re.compile(r'.*((.*))')22 # $表示匹配一行字符串的结尾,这里就是(.*?);(|$,表示匹配字符串含有(,或者只有(.*?)23 items = re.search(pattern, data)24 if items is None:25 return '未知'26 return items.group(1)Tips:
'r':正则前面加上'r' 是为了告诉编译器这个string是个raw string,不要转意''。当一个字符串使用了正则表达式后,最好在前面加上'r';
'|' 正则'|'表示或','′:∗∗正则′∣′表示或′,′'表示匹配一行字符串的结尾;
.group(1):意思是返回search匹配的第一个括号中的结果,即(.*?),gropup()则返回所有结果2013-12-18(,group(1)返回'('。
接下来,修改main()函数来输出爬取的内容:
1def main(): 2 url = 'http://maoyan.com/board/4?offset=0' 3 html = get_one_page(url) 4 5 for item in parse_one_page(html): 6 print(item) 7 8 9if __name__ == '__main__':10 main()Tips:
if _ name_ == '_ main_':当.py文件被直接运行时,if _ name_ == '_ main_'之下的代码块将被运行;当.py文件以模块形式被导入时,if _ name_ == '_ main_'之下的代码块不被运行。
参考:https://blog.csdn.net/yjk13703623757/article/details/77918633。
运行程序,就可成功地提取出所需内容,结果如下:
1{'index': '1', 'thumb': 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg', 'name': '霸王别姬', 'star': '张国荣,张丰毅,巩俐', 'time': '1993-01-01', 'area': '中国香港', 'score': '9.6'}2{'index': '2', 'thumb': 'http://p0.meituan.net/movie/54617769d96807e4d81804284ffe2a27239007.jpg', 'name': '罗马假日', 'star': '格利高里·派克,奥黛丽·赫本,埃迪·艾伯特', 'time': '1953-09-02', 'area': '美国', 'score': '9.1'}3{'index': '3', 'thumb': 'http://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg', 'name': '肖申克的救赎', 'star': '蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿', 'time': '1994-10-14', 'area': '美国', 'score': '9.5'}4{'index': '4', 'thumb': 'http://p0.meituan.net/movie/e55ec5d18ccc83ba7db68caae54f165f95924.jpg', 'name': '这个杀手不太冷', 'star': '让·雷诺,加里·奥德曼,娜塔莉·波特曼', 'time': '1994-09-14', 'area': '法国', 'score': '9.5'}5{'index': '5', 'thumb': 'http://p1.meituan.net/movie/f5a924f362f050881f2b8f82e852747c118515.jpg', 'name': '教父', 'star': '马龙·白兰度,阿尔·帕西诺,詹姆斯·肯恩', 'time': '1972-03-24', 'area': '美国', 'score': '9.3'}67...8}9[Finished in 1.9s]以上是第1种提取方法,如果还不习惯正则表达式这种复杂的语法,可以试试下面的第2种方法。
3.3.2. lxml结合xpath提取
该方法需要用到lxml这款解析利器,同时搭配xpath语法,利用它的的路径选择表达式,来高效提取所需内容。lxml包为第三方包,需要自行安装。如果对xpath的语法还不太熟悉,可参考下面的教程:
http://www.w3school.com.cn/xpath/xpath_syntax.asp
1</div> 2 3 4 <div class="container" id="app" class="page-board/index" > 5 6<div class="content"> 7 <div class="wrapper"> 8 <div class="main"> 9 <p class="update-time">2018-08-18<span class="has-fresh-text">已更新</span></p>10 <p class="board-content">榜单规则:将猫眼电影库中的经典影片,按照评分和评分人数从高到低综合排序取前100名,每天上午10点更新。相关数据来源于“猫眼电影库”。</p>11 <dl class="board-wrapper">12 <dd>13 <i class="board-index board-index-1">1</i>14 <a href="/films/1203" title="霸王别姬" class="image-link" data-act="boarditem-click" data-val="{movieId:1203}">15 <img src="//ms0.meituan.net/mywww/image/loading_2.e3d934bf.png" alt="" class="poster-default" />16 <img src="http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c" alt="霸王别姬" class="board-img" />17 </a>18 <div class="board-item-main">19 <div class="board-item-content">20 <div class="movie-item-info">21 <p class="name"><a href="/films/1203" title="霸王别姬" data-act="boarditem-click" data-val="{movieId:1203}">霸王别姬</a></p>22 <p class="star">23 主演:张国荣,张丰毅,巩俐24 </p>25<p class="releasetime">上映时间:1993-01-01(中国香港)</p> </div>26 <div class="movie-item-number score-num">27<p class="score"><i class="integer">9.</i><i class="fraction">6</i></p> 28 </div>2930 </div>31 </div>3233 </dd>34 <dd>根据截取的部分html网页,先来提取第1个电影排名信息,有两种方法。
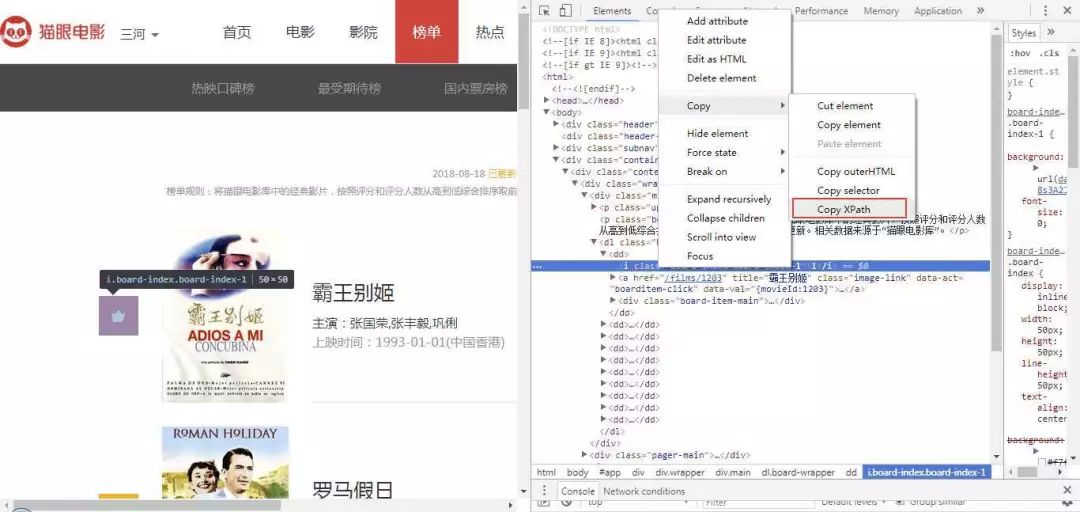
第一种:直接复制。
右键-Copy-Copy Xpath,得到xpath路径为://*[@id="app"]/div/div/div[1]/dl/dd[1]/i,为了能够提取到页面所有的排名信息,需进一步修改为://*[@id="app"]/div/div/div[1]/dl/dd/i/text(),如果想要再精简一点,可以省去中间部分绝对路径'/'然后用相对路径'//'代替,最后进一步修改为://*[@id="app"]//div//dd/i/text()。
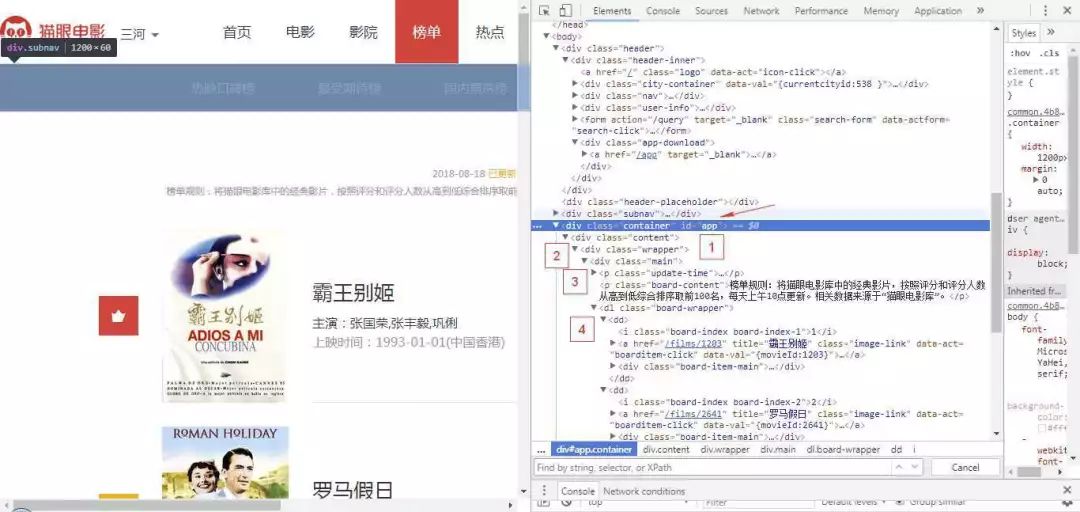
第二种:观察网页结构自己写。
首先注意到id = app的div节点,因为在整个网页结构id是唯一的不会有第二个相同的,所有可以将该div节点作为xpath语法的起点,然后往下观察分别是3级div节点,可以省略写为://div,再往下分别是是两个并列的p节点、dl节点、dd节点和最后的i节点文本。中间可以随意省略,只要保证该路径能够选择到唯一的文本值'1'即可,例如省去p和dl节点,只保留后面的节点。这样,完整路径可以为://*[@id="app"]//div//dd/i/text(),和上式一样。
根据上述思路,可以写下其他内容的xpath路径。观察到路径的前一部分://*[@id="app"]//div//dd都是一样的,从后面才开始不同,因此为了能够精简代码,将前部分路径赋值为一个变量items,最终提取的代码如下:
1# 2 用lxml结合xpath提取内容 2def parse_one_page2(html): 3 parse = etree.HTML(html) 4 items = parse.xpath('//*[@id="app"]//div//dd') 5 # 完整的是//*[@id="app"]/div/div/div[1]/dl/dd 6 # print(type(items)) 7 # *代表匹配所有节点,@表示属性 8 # 第一个电影是dd[1],要提取页面所有电影则去掉[1] 9 # xpath://*[@id="app"]/div/div/div[1]/dl/dd[1] 10 for item in items:11 yield{12 'index': item.xpath('./i/text()')[0],13 #./i/text()前面的点表示从items节点开始14 #/text()提取文本15 'thumb': get_thumb(str(item.xpath('./a/img[2]/@src')[0].strip())),16 # 'thumb': 要在network中定位,在elements里会写成@src而不是@src,从而会报list index out of range错误。17 'name': item.xpath('./a/@title')[0],18 'star': item.xpath('.//p[@class = "star"]/text()')[0].strip(),19 'time': get_release_time(item.xpath(20 './/p[@class = "releasetime"]/text()')[0].strip()[5:]),21 'area': get_release_area(item.xpath(22 './/p[@class = "releasetime"]/text()')[0].strip()[5:]),23 'score' : item.xpath('.//p[@class = "score"]/i[1]/text()')[0] + 24 item.xpath('.//p[@class = "score"]/i[2]/text()')[0]25 }Tips:
[0]:xpath后面添加了[0]是因为返回的是只有1个字符串的list,添加[0]是将list提取为字符串,使其简洁;
Network:要在最原始的Network选项卡中定位,而不是Elements中,不然提取不到相关内容;
class属性:p[@class = "star"]/text()表示提取class属性为"star"的p节点的文本值;
提取属性值:img[2]/@src':提取img节点的src属性值,属性值后面无需添加'/text()'
运行程序,就可成功地提取出所需内容,结果和第一种方法一样。
以上是第2种提取方法,如果也不太习惯xpath语法,可以试试下面的第3种方法。
3.3.3. Beautiful Soup + css选择器
Beautiful Soup 同lxml一样,是一个非常强大的python解析库,可以从HTML或XML文件中提取效率非常高。关于它的用法,可参考下面的教程:
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
css选择器选是一种模式,用于选择需要添加样式的元素,使用它的语法同样能够快速定位到所需节点,然后提取相应内容。使用方法可参考下面的教程:
http://www.w3school.com.cn/cssref/css_selectors.asp
下面就利用这种方法进行提取:
1# 3 用beautifulsoup + css选择器提取 2def parse_one_page3(html): 3 soup = BeautifulSoup(html, 'lxml') 4 # print(content) 5 # print(type(content)) 6 # print('------------') 7 items = range(10) 8 for item in items: 9 yield{1011 'index': soup.select('dd i.board-index')[item].string,12 # iclass节点完整地为'board-index board-index-1',写board-index即可13 'thumb': get_thumb(soup.select('a > img.board-img')[item]["src"]),14 # 表示a节点下面的class = board-img的img节点,注意浏览器eelement里面是src节点,而network里面是src节点,要用这个才能正确返回值1516 'name': soup.select('.name a')[item].string,17 'star': soup.select('.star')[item].string.strip()[3:],18 'time': get_release_time(soup.select('.releasetime')[item].string.strip()[5:]),19 'area': get_release_area(soup.select('.releasetime')[item].string.strip()[5:]),20 'score': soup.select('.integer')[item].string + soup.select('.fraction')[item].string2122 }运行上述程序,结果同第1种方法一样。
3.3.4. Beautiful Soup + find_all函数提取
Beautifulsoup除了和css选择器搭配,还可以直接用它自带的find_all函数进行提取。
find_all,顾名思义,就是查询所有符合条件的元素,可以给它传入一些属性或文本来得到符合条件的元素,功能十分强大。
它的API如下:
1find_all(name , attrs , recursive , text , **kwargs)常用的语法规则如下:
soup.find_all(name='ul'): 查找所有ul节点,ul节点内还可以嵌套;
li.string和li.get_text():都是获取li节点的文本,但推荐使用后者;
soup.find_all(attrs={'id': 'list-1'})):传入 attrs 参数,参数的类型是字典类型,表示查询 id 为 list-1 的节点;
常用的属性比如 id、class 等,可以省略attrs采用更简洁的形式,例如:
soup.find_all(id='list-1')
soup.find_all(class_='element')
根据上述常用语法,可以提取网页中所需内容:
1def parse_one_page4(html): 2 soup = BeautifulSoup(html,'lxml') 3 items = range(10) 4 for item in items: 5 yield{ 6 7 'index': soup.find_all(class_='board-index')[item].string, 8 'thumb': soup.find_all(class_ = 'board-img')[item].attrs['src'], 9 # 用.get('src')获取图片src链接,或者用attrs['src']10 'name': soup.find_all(name = 'p',attrs = {'class' : 'name'})[item].string,11 'star': soup.find_all(name = 'p',attrs = {'class':'star'})[item].string.strip()[3:],12 'time': get_release_time(soup.find_all(class_ ='releasetime')[item].string.strip()[5:]),13 'area': get_release_time(soup.find_all(class_ ='releasetime')[item].string.strip()[5:]),14 'score':soup.find_all(name = 'i',attrs = {'class':'integer'})[item].string.strip() + soup.find_all(name = 'i',attrs = {'class':'fraction'})[item].string.strip()1516 }以上就是4种不同的内容提取方法。
3.4. 数据存储
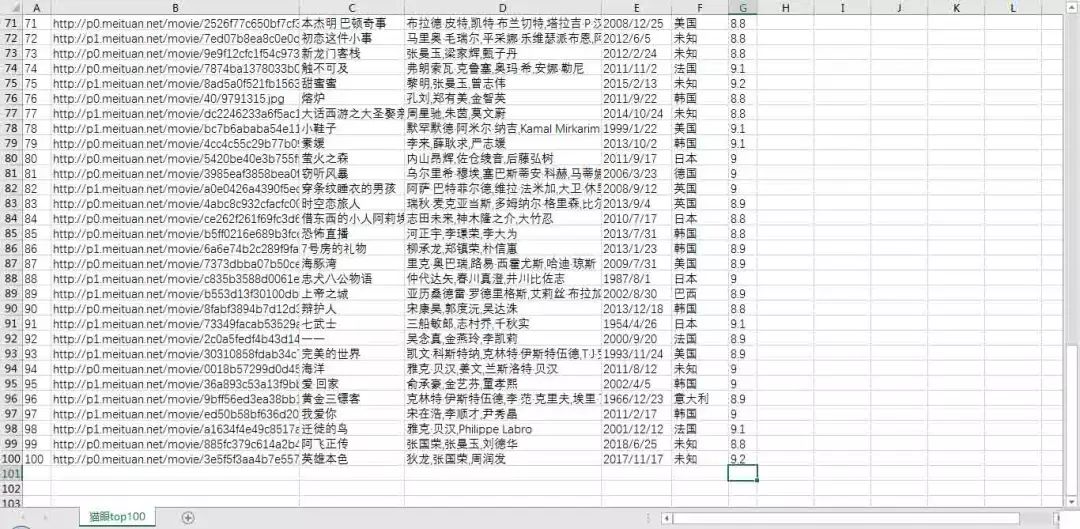
上述输出的结果为字典格式,可利用csv包的DictWriter函数将字典格式数据存储到csv文件中。
1# 数据存储到csv2def write_to_file3(item):3 with open('猫眼top100.csv', 'a', encoding='utf_8_sig',newline='') as f:4 # 'a'为追加模式(添加)5 # utf_8_sig格式导出csv不乱码 6 fieldnames = ['index', 'thumb', 'name', 'star', 'time', 'area', 'score']7 w = csv.DictWriter(f,fieldnames = fieldnames)8 # w.writeheader()9 w.writerow(item)然后修改一下main()方法:
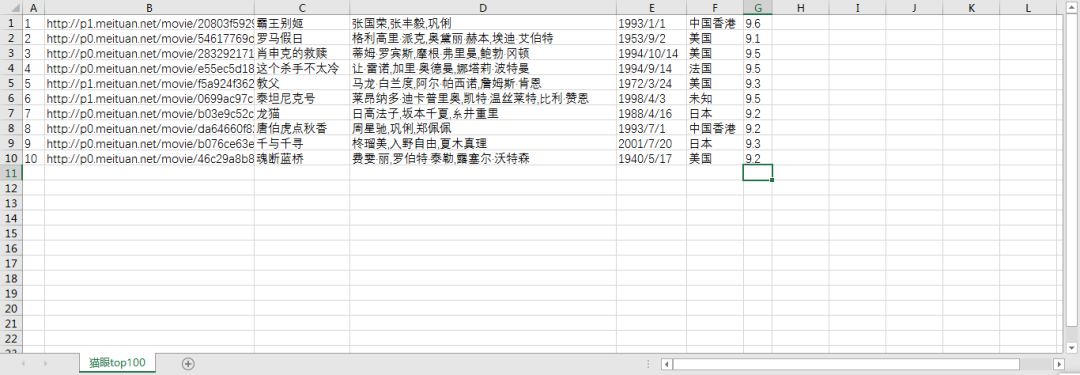
1def main(): 2 url = 'http://maoyan.com/board/4?offset=0' 3 html = get_one_page(url) 4 5 for item in parse_one_page(html): 6 # print(item) 7 write_to_csv(item) 8 910if __name__ == '__main__':11 main()结果如下图:
再将封面的图片下载下来:
1def download_thumb(name, url,num): 2 try: 3 response = requests.get(url) 4 with open('封面图/' + name + '.jpg', 'wb') as f: 5 f.write(response.content) 6 print('第%s部电影封面下载完毕' %num) 7 print('------') 8 except RequestException as e: 9 print(e)10 pass11 # 不能是w,否则会报错,因为图片是二进制数据所以要用wb3.5. 分页爬取
上面完成了一页电影数据的提取,接下来还需提取剩下9页共90部电影的数据。对网址进行遍历,给网址传入一个offset参数即可,修改如下:
1def main(offset): 2 url = 'http://maoyan.com/board/4?offset=' + str(offset) 3 html = get_one_page(url) 4 5 for item in parse_one_page(html): 6 # print(item) 7 write_to_csv(item) 8 910if __name__ == '__main__':11 for i in range(10):12 main(offset = i*10)这样就完成了所有电影的爬取。结果如下:
4. 可视化分析
俗话说“文不如表,表不如图”。下面根据excel的数据结果,进行简单的数据可视化分析,并用图表呈现。
4.1. 电影评分最高top10
首先,想看一看评分最高的前10部电影是哪些?
程序如下:
1import pandas as pd 2import matplotlib.pyplot as plt 3import pylab as pl #用于修改x轴坐标 4 5plt.style.use('ggplot') #默认绘图风格很难看,替换为好看的ggplot风格 6fig = plt.figure(figsize=(8,5)) #设置图片大小 7colors1 = '#6D6D6D' #设置图表title、text标注的颜色 8 9columns = ['index', 'thumb', 'name', 'star', 'time', 'area', 'score'] #设置表头10df = pd.read_csv('maoyan_top100.csv',encoding = "utf-8",header = None,names =columns,index_col = 'index') #打开表格11# index_col = 'index' 将索引设为index1213df_score = df.sort_values('score',ascending = False) #按得分降序排列1415name1 = df_score.name[:10] #x轴坐标16score1 = df_score.score[:10] #y轴坐标 17plt.bar(range(10),score1,tick_label = name1) #绘制条形图,用range()能搞保持x轴正确顺序18plt.ylim ((9,9.8)) #设置纵坐标轴范围19plt.title('电影评分最高top10',color = colors1) #标题20plt.xlabel('电影名称') #x轴标题21plt.ylabel('评分') #y轴标题2223# 为每个条形图添加数值标签24for x,y in enumerate(list(score1)):25 plt.text(x,y+0.01,'%s' %round(y,1),ha = 'center',color = colors1)2627pl.xticks(rotation=270) #x轴名称太长发生重叠,旋转为纵向显示28plt.tight_layout() #自动控制空白边缘,以全部显示x轴名称29# plt.savefig('电影评分最高top10.png') #保存图片30plt.show()结果如下图:
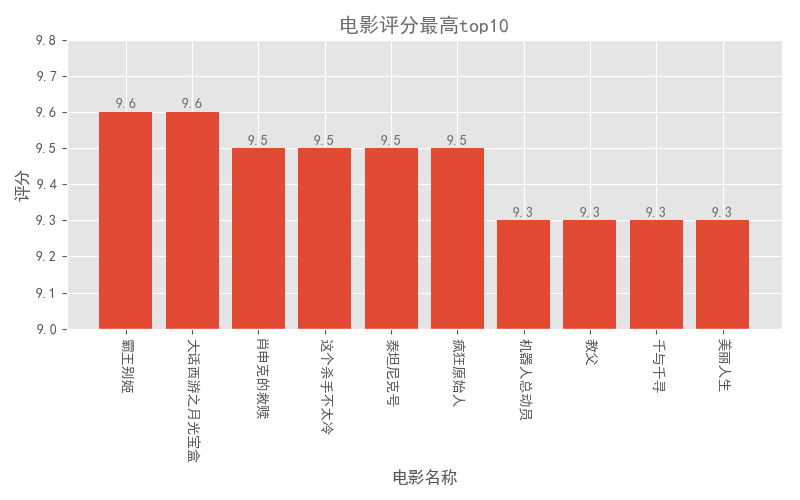
嗯,还好基本上都看过。
4.2. 各国家的电影数量比较
然后,想看看100部电影都是来自哪些国家?
程序如下:
1area_count = df.groupby(by = 'area').area.count().sort_values(ascending = False) 2 3# 绘图方法1 4area_count.plot.bar(color = '#4652B1') #设置为蓝紫色 5pl.xticks(rotation=0) #x轴名称太长重叠,旋转为纵向 6 7 8# 绘图方法2 9# plt.bar(range(11),area_count.values,tick_label = area_count.index)1011for x,y in enumerate(list(area_count.values)):12 plt.text(x,y+0.5,'%s' %round(y,1),ha = 'center',color = colors1)13plt.title('各国/地区电影数量排名',color = colors1)14plt.xlabel('国家/地区')15plt.ylabel('数量(部)')16plt.show()17# plt.savefig('各国(地区)电影数量排名.png')结果如下图:
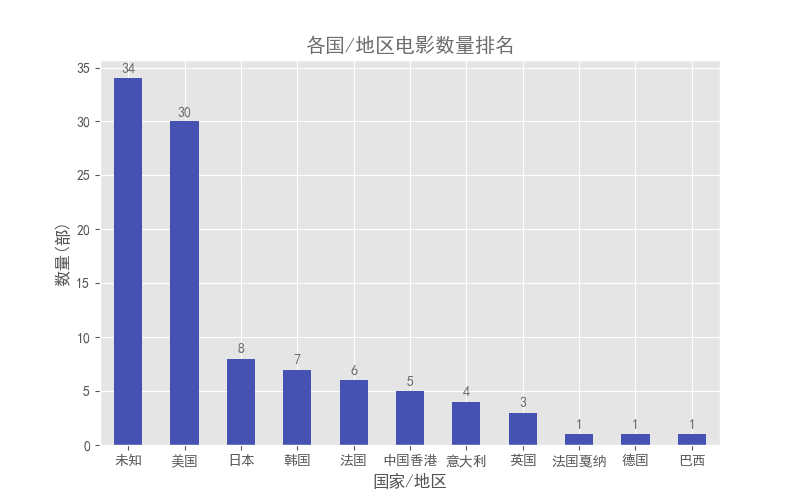 可以看到,除去网站自身没有显示国家的电影以外,上榜电影被10个国家/地区"承包"了。其中,美国以30部电影的绝对优势占据第1名,其次是8部的日本,韩国第3,居然有7部上榜。
可以看到,除去网站自身没有显示国家的电影以外,上榜电影被10个国家/地区"承包"了。其中,美国以30部电影的绝对优势占据第1名,其次是8部的日本,韩国第3,居然有7部上榜。
不得不说的是香港有5部,而内地一部都没有。。。
4.3. 电影作品数量集中的年份
接下来站在漫长的百年电影史的时间角度上,分析一下哪些年份"贡献了"最多的电影数量,也可以说是"电影大年"。
1# 从日期中提取年份 2df['year'] = df['time'].map(lambda x:x.split('/')[0]) 3# print(df.info()) 4# print(df.head()) 5 6# 统计各年上映的电影数量 7grouped_year = df.groupby('year') 8grouped_year_amount = grouped_year.year.count() 9top_year = grouped_year_amount.sort_values(ascending = False)101112# 绘图13top_year.plot(kind = 'bar',color = 'orangered') #颜色设置为橙红色14for x,y in enumerate(list(top_year.values)):15 plt.text(x,y+0.1,'%s' %round(y,1),ha = 'center',color = colors1)16plt.title('电影数量年份排名',color = colors1)17plt.xlabel('年份(年)')18plt.ylabel('数量(部)')1920plt.tight_layout()21# plt.savefig('电影数量年份排名.png')2223plt.show()结果如下图:
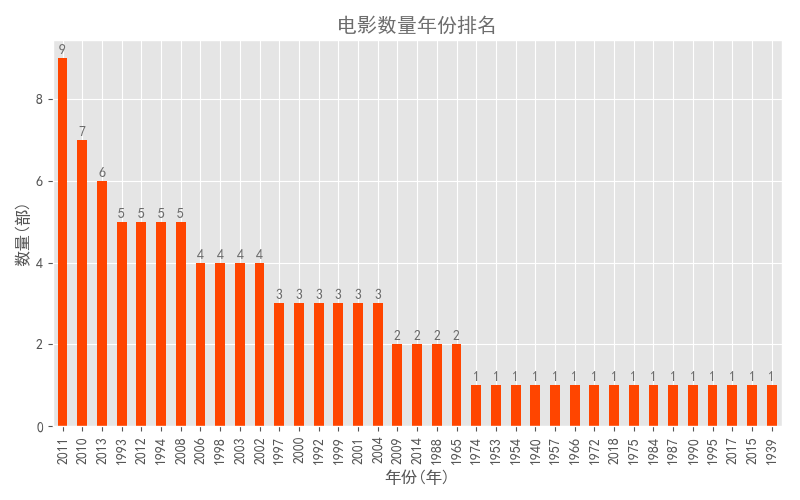 可以看到,100部电影来自37个年份。其中2011年上榜电影数量最多,达到9部;其次是前一年的7部。回忆一下,那会儿正是上大学的头两年,可怎么感觉除了阿凡达之外,没有什么其他有印象的电影了。。。
可以看到,100部电影来自37个年份。其中2011年上榜电影数量最多,达到9部;其次是前一年的7部。回忆一下,那会儿正是上大学的头两年,可怎么感觉除了阿凡达之外,没有什么其他有印象的电影了。。。
另外,网上传的号称"电影史奇迹年"的1994年仅排名第6。这让我进一步对猫眼榜单的权威性产生了质疑。
再往后看,发现遥远的1939和1940年也有电影上榜。那会儿应该还是黑白电影时代吧,看来电影的口碑好坏跟外在的技术没有绝对的关系,质量才是王道。
4.3.1. 拥有电影作品数量最多的演员
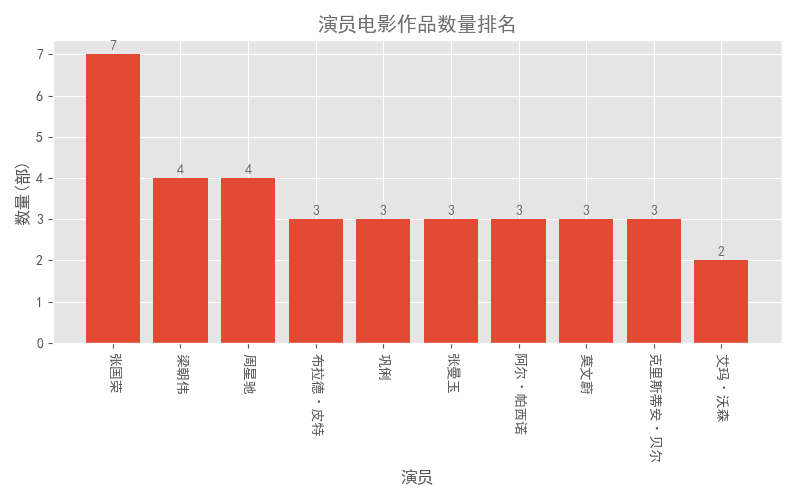
最后,看看前100部电影中哪些演员的作品数量最多。
程序如下:
1#表中的演员位于同一列,用逗号分割符隔开。需进行分割然后全部提取到list中 2starlist = [] 3star_total = df.star 4for i in df.star.str.replace(' ','').str.split(','): 5 starlist.extend(i) 6# print(starlist) 7# print(len(starlist)) 8 9# set去除重复的演员名10starall = set(starlist)11# print(starall)12# print(len(starall))1314starall2 = {}15for i in starall:16 if starlist.count(i)>1:17 # 筛选出电影数量超过1部的演员18 starall2[i] = starlist.count(i)1920starall2 = sorted(starall2.items(),key = lambda starlist:starlist[1] ,reverse = True)2122starall2 = dict(starall2[:10]) #将元组转为字典格式2324# 绘图25x_star = list(starall2.keys()) #x轴坐标26y_star = list(starall2.values()) #y轴坐标2728plt.bar(range(10),y_star,tick_label = x_star)29pl.xticks(rotation = 270)30for x,y in enumerate(y_star):31 plt.text(x,y+0.1,'%s' %round(y,1),ha = 'center',color = colors1)3233plt.title('演员电影作品数量排名',color = colors1)34plt.xlabel('演员')35plt.ylabel('数量(部)')36plt.tight_layout()37plt.show() 38# plt.savefig('演员电影作品数量排名.png')结果如下图:
张国荣排在了第一位,这是之前没有猜到的。其次是梁朝伟和星爷,再之后是布拉德·皮特。惊奇地发现,前十名影星中,香港影星居然占了6位。有点严重怀疑这是不是香港版的top100电影。。。
对张国荣以7部影片的巨大优势雄霸榜单第一位感到好奇,想看看是哪7部电影。
1df['star1'] = df['star'].map(lambda x:x.split(',')[0]) #提取1号演员2df['star2'] = df['star'].map(lambda x:x.split(',')[1]) #提取2号演员3star_most = df[(df.star1 == '张国荣') | (df.star2 == '张国荣')][['star','name']].reset_index('index')4# |表示两个条件或查询,之后重置索引5print(star_most)可以看到包括排名第1的"霸王别姬"、第17名的"春光乍泄"、第27名的"射雕英雄传之东成西就"等。
突然发现,好像只看过"英雄本色"。。。有时间,去看看他其他的作品。
1 index star name20 1 张国荣,张丰毅,巩俐 霸王别姬31 17 张国荣,梁朝伟,张震 春光乍泄42 27 张国荣,梁朝伟,张学友 射雕英雄传之东成西就53 37 张国荣,梁朝伟,刘嘉玲 东邪西毒64 70 张国荣,王祖贤,午马 倩女幽魂75 99 张国荣,张曼玉,刘德华 阿飞正传86 100 狄龙,张国荣,周润发 英雄本色由于数据量有限,故仅作了上述简要的分析。
4.4. 完整代码
因篇幅有限,请长按扫描关注下方公众号“数据科学俱乐部”后回复“猫眼”获取本文完整代码下载地址。


Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击下方阅读原文,免费成为社区会员

