
热门标签
热门文章
- 1Nuitka打包python代码教程_nuitka打包python代码教程 csdn
- 2Cuda 和 GPU版torch安装最全攻略,以及在GPU 上运行 torch代码_torch gpu
- 3StableDiffusion(四)——高清修复与放大算法_stable diffusion 放大算法
- 4自学记录:阿里云天池推荐系统实践 - 多路召回
- 5完美解决:yum -y install nginx 报出 没有可用软件包 nginx。错误:无须任何处理
- 6html网页制作之简单登入界面_html表格登录界面
- 7rabbitMQ是什么:_socket与rabbitmq
- 8Java+SSM+JSP校园车辆管理系统源码+论文+开题报告
- 9pycharm使用conda创建虚拟环境_pycharm选择conda虚拟环境
- 10【深度学习实战(5)】使用OPENCV库实现自己的letter_box操作
当前位置: article > 正文
消息队列:Kafka入门学习笔记_卡夫卡消息
作者:盐析白兔 | 2024-04-18 10:21:46
赞
踩
卡夫卡消息
前言
消息队列是一种进程间通信或同一进程的不同线程间的通信方式,软件的贮列用来处理一系列的输入,通常是来自用户。消息队列提供了异步的通信协议,每一个贮列中的纪录包含详细说明的资料,包含发生的时间,输入设备的种类,以及特定的输入参数,也就是说:消息的发送者和接收者不需要同时与消息队列交互。
主流消息队列的对比
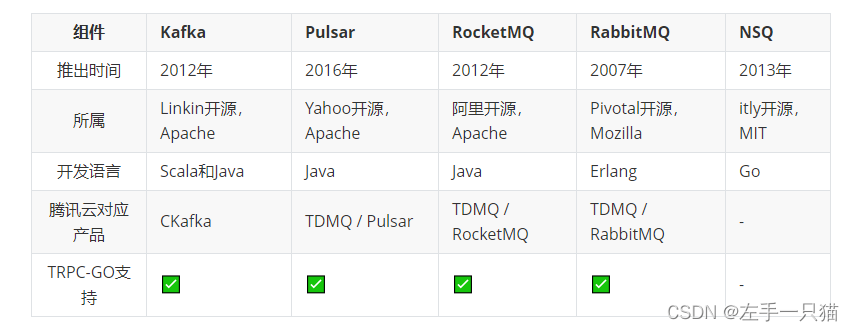
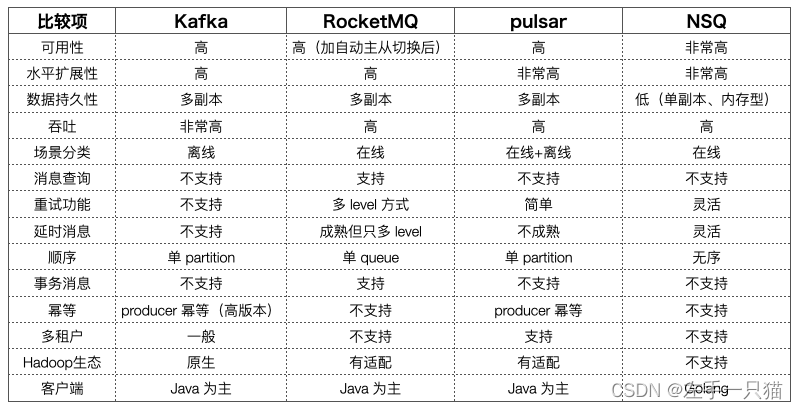
Kafka地址:https://github.com/apache/kafkaRocketMq地址:https://github.com/apache/rocketmqPulsar地址:https://github.com/apache/pulsarRabbitMq地址:https://github.com/rabbitmq/rabbitmq-serverNsq地址:https://github.com/nsqio/nsq
Nsq和kafka走势强劲
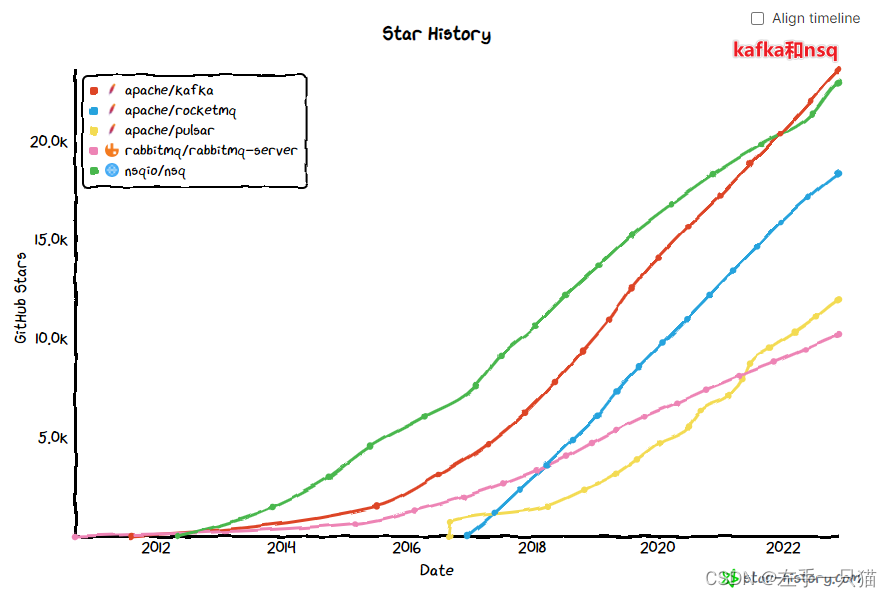
提示:以下是本篇文章正文内容,下面案例可供参考
一、Kakfa是什么?
Kafka定义?
- kafka是开源流处理平台,由Scala和Java编写(rabitMq由Erlang语言)。本质上是一个按照分布式事务日志架构的发布/订阅消息队列
- Apache Kafka 是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。
Kafka 适合离线和在线消息消费。 Kafka 消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka 构建在 ZooKeeper 同步服务之上。 它与 Apache Storm 和 Spark 非常好地集成,用于实时流式数据分析。 - Kafka 是一个分布式消息队列,具有高性能、持久化、
多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
Kafka名字来源?
- kafka名字是因为kafka作者喜欢《变形记》作者卡夫卡的作品,于是用kafka作为命名。
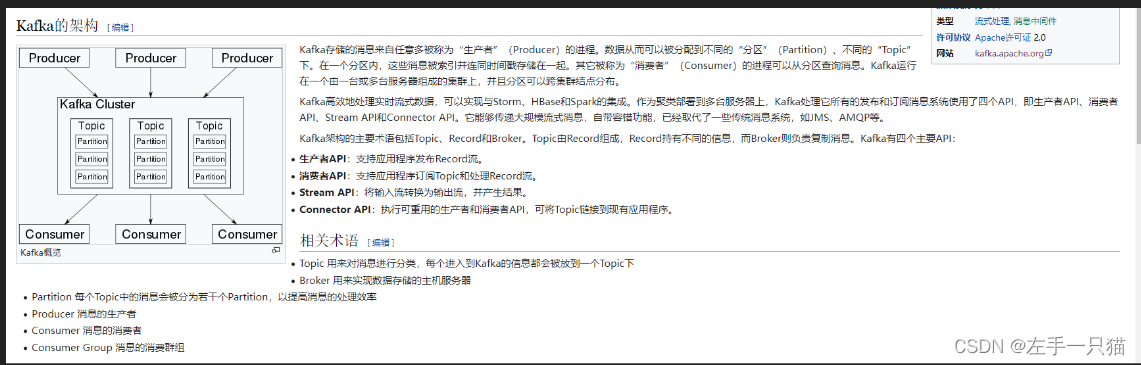
kafka有哪些术语?
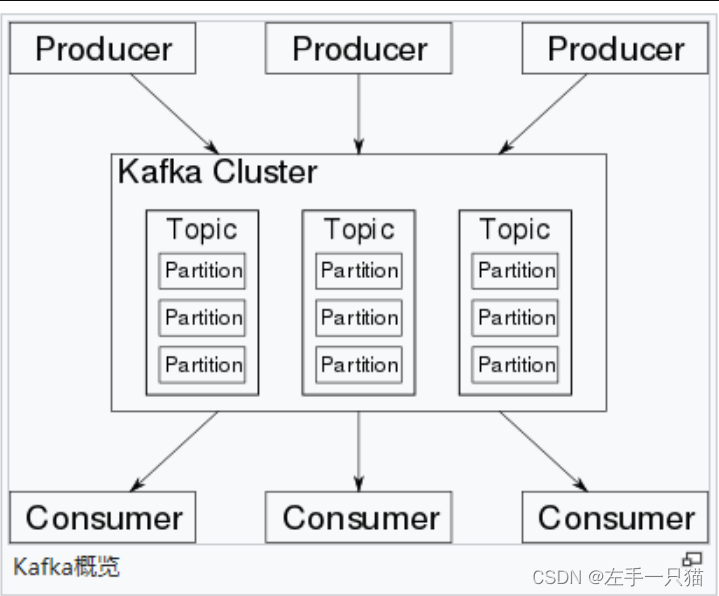
-
broker(经纪人,代理人): Kafka实例broker:Kafka 集群中有很多台 Server,其中每一台 Server 都可以存储消息,将每一台 Server 称为一个 kafka 实例,也叫做 broker。- 一台Server == 一个kafka实例 == 一个broker
-
Topic(主题): 同类消息集合- 一个
topic里保存的是同一类消息,相当于对消息的分类,每个 producer 将消息发送到 kafka 中,都需要指明要存的 topic 是哪个,也就是指明这个消息属于哪一类。
- 一个
-
Partition(分区):每个 partition 在存储层面是append log 文件每个 topic 都可以分成多个 partition,每个 partition 在存储层面是append log 文件。任何发布到此 partition 的消息都会被直接追加到 log 文件的尾部。为什么要进行分区呢?最根本的原因就是:kafka基于文件进行存储,当文件内容大到一定程度时,很容易达到单个磁盘的上限,因此,采用分区的办法**,一个分区对应一个文件**,这样就可以将数据分别存储到不同的server上去,另外这样做也可以负载均衡,容纳更多的消费者。- 分区不是副本,是消息分开存储,类似磁盘分区,如果一个主题有多个分区,那么
多个消息就会分别分布在多个分区里面
-
偏移量(Offset):- 一个分区Partition对应一个磁盘上的文件,而消息在文件中的位置就称为 offset(偏移量),offset 为一个 long 型数字,它可以唯一标记一条消息。由于kafka 并没有提供其他额外的索引机制来存储 offset,文件只能顺序的读写,所以在kafka中几乎
不允许对消息进行“随机读写”。
- 一个分区Partition对应一个磁盘上的文件,而消息在文件中的位置就称为 offset(偏移量),offset 为一个 long 型数字,它可以唯一标记一条消息。由于kafka 并没有提供其他额外的索引机制来存储 offset,文件只能顺序的读写,所以在kafka中几乎
-
分组(Group):同组消费者每个topic的订阅单位都是以组位单位,同一组内的消费者消费消息是互斥的关系,类似我们微信的多个终端,一个处理之后,其他都不用处理。
总之:一个 topic 对应的多个 partition 分散存储到集群中的多个 broker 上,存储方式是一个 partition 对应一个文件,每个 broker 负责存储在自己机器上的 partition 中的消息读写。
二、Kafka解决了什么技术场景或者业务场景?
- 解决了大数据里面(收集、存储、计算)的存储场景
Kafka常用场景
- 1、日志服务监控
- Kafka与ELK(ElasticSearch、Logstash和Kibana)整合构建应用服务监控系统。
- 2、消息队列系统

- kafka在短信服务中的应用
三、Kakfa数据消费过程?
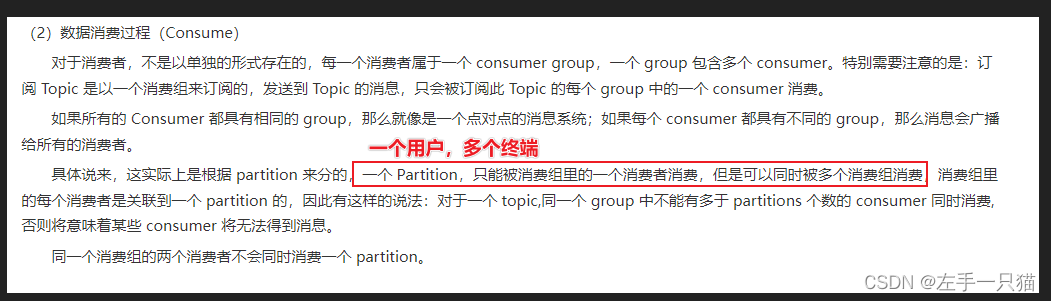
三、Kafka发布-订阅和用户组的工作流程?

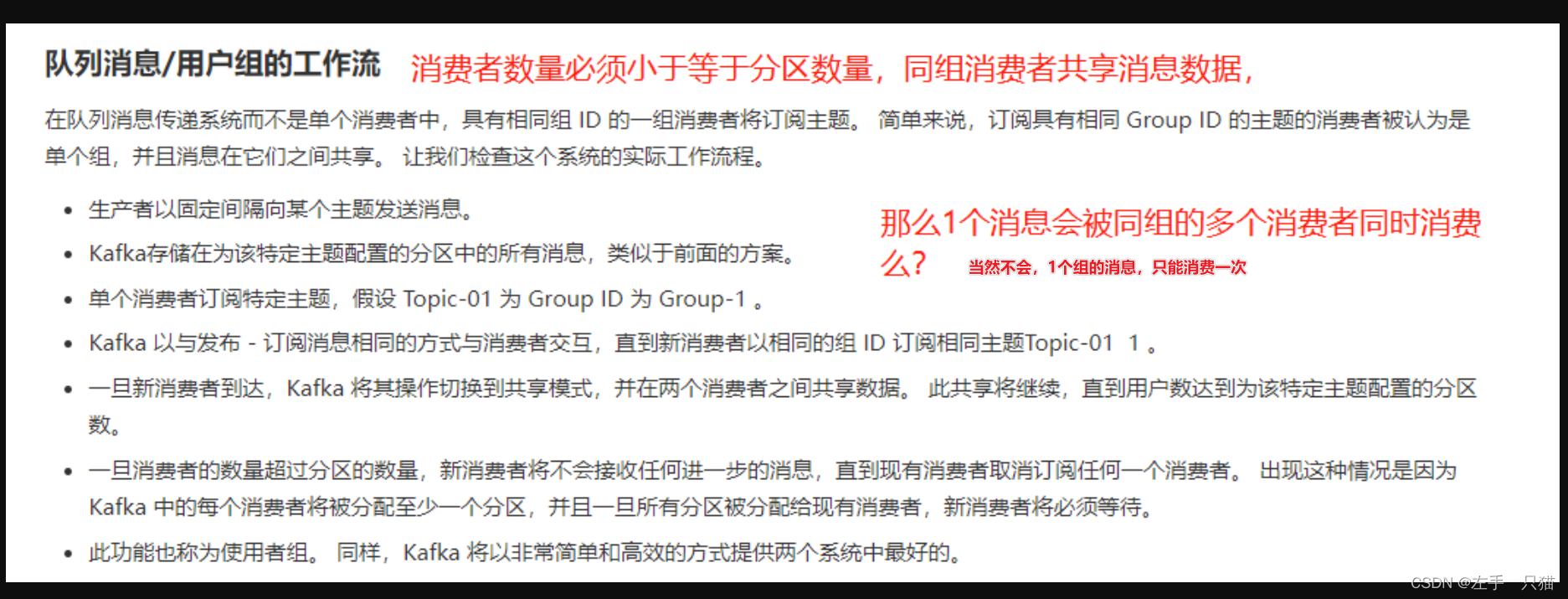
四、Zookeeper的作用
-
Zookeeper是一个分布式配置和同步服务
-

-
Kafka 在 Zookeeper 中存储基本元数据(如偏移量Offset、主题Topic)
-
由于所有关键信息存储在 Zookeeper 中,并且它通常在其整体上复制此数据,因此Kafka代理/ Zookeeper 的故障不会影响 Kafka 集群的状态。
五、Kafka安装使用-Kafka docker安装
# 1, 安装Zookeeper kafka docker pull wurstmeister/kafka docker pull zookeeper # 2.1, 启动Zookeeper docker run -d --name zookeeper -p 2181:2181 -v /mnt/d/apps/kafkaData/zookeeper/data:/data -v /mnt/d/apps/kafkaData/zookeeper/log:/datalog zookeeper # 2.2, 启动Kafka # PS 172.27.107.133 是宿主机地址 docker run -d --name kafka --publish 9092:9092 \ --link zookeeper \ --env KAFKA_ZOOKEEPER_CONNECT=172.28.207.86:2181 \ --env KAFKA_ADVERTISED_HOST_NAME=172.28.207.86 \ --env KAFKA_ADVERTISED_PORT=9092 \ --env KAFKA_LOG_DIRS=/kafka/kafka-logs-1 \ -v /mnt/d/apps/kafkaData/kafka/log:/kafka/kafka-logs-1 \ wurstmeister/kafka # 3. CRUD Topic # 创建 topic docker exec kafka kafka-topics.sh --create --zookeeper 172.28.207.86:2181 --replication-factor 1 --partitions 1 --topic topic_gbc_order # 查看 topic docker exec kafka kafka-topics.sh --list --zookeeper 172.28.207.86:2181 # docker exec -it kafka kafka-console-producer.sh --broker-list 192.168.60.133:9092 --topic test # 4. CRUD 消费者Consumer和生产者 # 创建 生产者 docker exec -it kafka kafka-console-producer.sh --broker-list 172.28.207.86:9092 --topic topic_gbc_order # 创建 消费者 docker exec -it kafka kafka-console-consumer.sh --bootstrap-server 172.28.207.86:9092 --topic topic_gbc_order --from-beginning

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
-
通过Docker compose 创建 kafka和zookeeper
- 启动命令
docker-compose up -d
- 启动命令
compose.yaml
version: '3' services: zookeeper: image: zookeeper # 镜像名称 restart: unless-stopped ports: - "2181:2181" volumes: - /mnt/d/apps/kafkaData/zookeeper/data:/data # 数据文件夹挂载 - /mnt/d/apps/kafkaData/zookeeper/log:/datalog # 日志文件夹挂载 container_name: zookeeper # 容器名称 kafka: image: wurstmeister/kafka # 镜像名称 ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: "172.27.107.133" # 宿主机地址 KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181" KAFKA_LOG_DIRS: "/kafka/kafka-logs-1" # 日志路径 volumes: - /mnt/d/apps/kafkaData/kafka/log:/kafka/kafka-logs-1 # 日志挂载 depends_on: - zookeeper # 依赖镜像 container_name: kafka # 容器名称
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
六、Kafka的客户端有哪些?
- Sarama: Shopify开源的Golang客户端
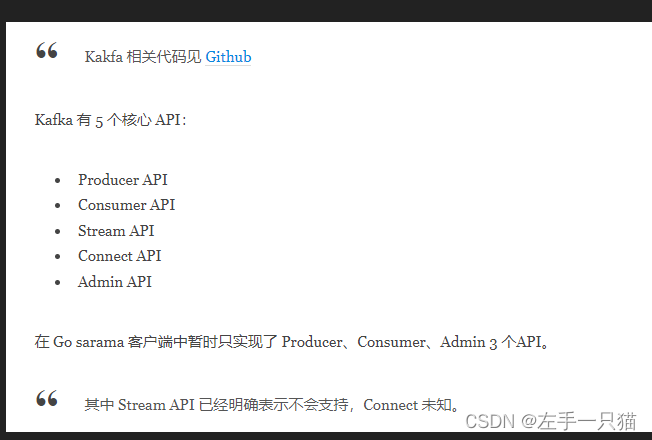
- confluent-kafka-go是Confluent公司的开源的Golang客户端。
总结
- Kafka是个好东西,希望你也能拥有
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/445457
推荐阅读
相关标签

