
NLP | XLNet :用于语言理解的广义自回归预训练 论文详解_xlnet论文
赞
踩
论文:XLNet: Generalized Autoregressive Pretraining for Language Understanding
论文地址:https://proceedings.neurips.cc/paper/2019/file/dc6a7e655d7e5840e66733e9ee67cc69-Paper.pdf
1.介绍
XLNet 是从蓬勃发展的自然语言处理 (NLP) 领域中出现的最新和最伟大的模型。XLNet 论文将 NLP的 最新进展与语言建模问题处理方式的创新选择相结合。当在一个非常大的 NLP 语料库上进行训练时,该模型在包含 GLUE 基准的标准 NLP 任务中实现了最先进的性能。
XLNet 是一种自回归语言模型,它基于带有递归的变换器架构输出一系列标记的联合概率。它的训练目标以句子中单词标记的所有排列为条件计算单词标记的概率,而不仅仅是目标标记左侧或右侧的那些排列。
将无监督学习应用于预训练的方法在 NLP 领域取得了很好的效果。无监督预训练的方法主要分为自动回归(AR)和自动编码(AE)。AutoRegressive (自动回归)通过预测正向或反向的下一个语料库来学习。这样做的缺点是只能学习单向上下文。但是,由于现实中的大多数下游任务都需要双向上下文,因此这是一个巨大的限制。另一方面,自动编码是一种将转换后的输入重建回原始输入的方法,BERT就是一个典型的例子。
2.背景知识
2.1.自动回归AR
作为通用语言模型(LM)的一种学习方法,它通过查看之前的token来解决预测下一个token的问题。代表性的例子有ELMO和GPT RNNLM,LM的目标用如下公式表示。
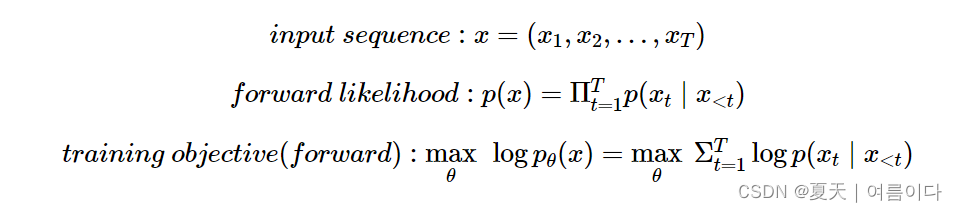
可能性和目标 Likelihood & Objective
- 给定输入序列的可能性表示为前向/后向条件概率的乘积。
- 该模型将这种条件分布作为目标(负对数似然)来学习。
由于 AR 必须确定方向(向前、向后),因此只能使用一个方向的信息。因此,使用双向上下文很难深入理解句子。ELMO 使用两个方向,但理解很浅,因为它为每个方向使用独立训练的模型。
2.2.自动编码 (AE)
Auto Encoder 解决了针对给定输入按原样预测输入的问题,而 Denoising Auto Encoder 解决了以噪声作为原始输入来预测输入的问题。在 BERT 的情况下,当给给定的输入序列任意添加噪声([MASK]token)时, [MASK]token 会恢复为原始输入 token。所以你可以通过 Denoising Auto Encoder 的方式看到它。
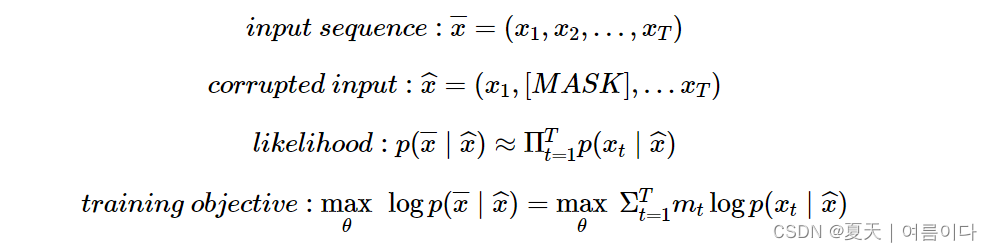 可能性和目标
可能性和目标
常见的去噪自编码器和最大化它的目标。但是,在计算它的过程中(上式右侧),有如下区别。
- 独立假设:对于给定的输入序列,每个token的正确token出现的概率
[MASK]不是独立的,而是假设是独立的。→ 由于它是独立的,它可以表示为每个概率的乘积。 - Xt是一个
[MASK]令牌, 仅对令牌进行预测。虽然通过换置 , 仅预测 token 的目标不同于Denoising Autoencoder的目标[MASK](相对于输入 + 噪声恢复输入,即无论噪声的位置如何都恢复整个输入),但可以考虑在概念上类似于将噪声恢复到原始输入。
与 AR 不同,AE[MASK]的优势在于能够使用双向信息(双向自注意力)来匹配特定的令牌。然而,由于所有令牌都是通过独立假设独立预测的,[MASK]因此存在无法学习它们之间的依赖关系的致命缺点。另外,噪声([MASK]token)本身并没有出现在实际的微调过程中,因此预训练和微调之间存在不匹配。
3.语言建模
在语言建模中,我们计算标记(单词)序列的联合概率分布,这通常通过将联合分布分解为给定序列中其他标记的一个标记的条件分布来实现。
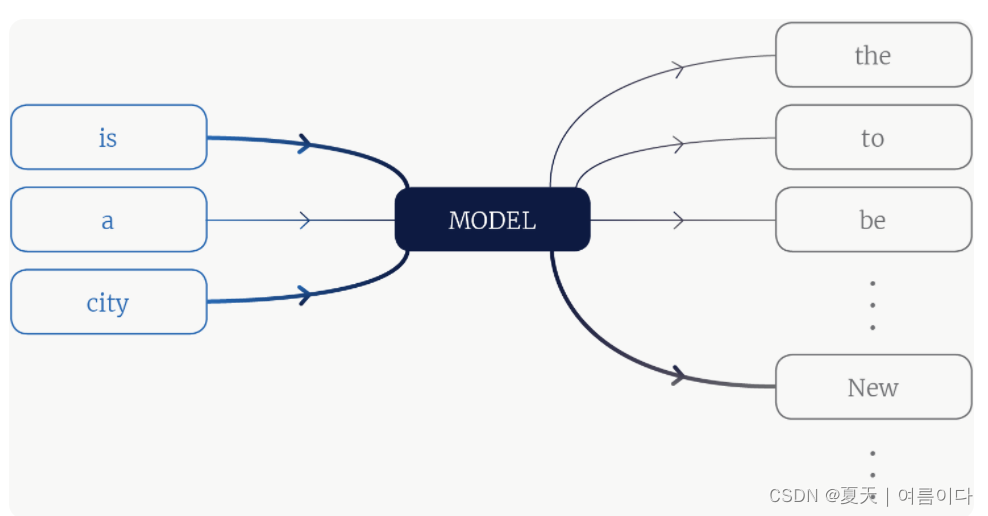
是一种语言模型。该模型是一个函数,它将一些上下文标记作为输入,并输出词汇表中每个标记的概率。较粗的线表示信息量更大的上下文词和更有可能的词汇词。
4.XL 训练目标
XLNet 的主要贡献不是架构,而是一种改进的语言模型训练目标,它学习序列中所有标记排列的条件分布。在深入了解该目标的细节之前,让我们重新审视 BERT 模型以激发 XLNet 的选择。
BERT使用了一个训练目标,该目标的任务是恢复句子中被掩盖的单词。对于给定的句子,一些标记被通用 [mask] 标记替换,并且模型被要求恢复原来的意思。
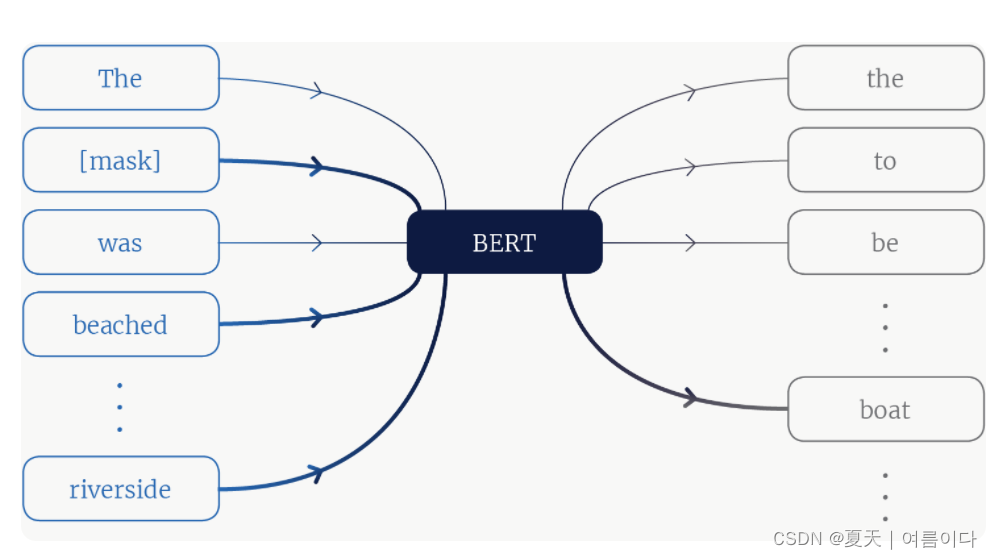
上图BERT 模型的描述。模型输入是上下文标记,其中一些是被屏蔽的。通过关注正确的上下文标记,模型可以知道船是掩码标记的可能值。
BERT 和 ELMo 等方法通过将左右上下文合并到预测中来改进现有技术。XLNet 更进一步:该模型的贡献是使用该序列中其他单词的任意组合来预测序列中的每个单词。可能会要求 XLNet 计算可能跟随的单词。
5.变压器架构
XLNET 将最先进的自回归模型 Transformer-XL 的想法集成到预训练中。Transformer 是 google 用于语言翻译的模型。它基本上围绕着“注意力”展开。它是一种编码器-解码器模型,您可以将一个序列映射到另一个序列——英语到法语。要将英语句子翻译成法语,解码器需要查看整个句子,以便在任何时间点选择性地从中提取信息(因为英语中的标记顺序不必与法语中的相同)。因此,编码器的所有隐藏状态都可供解码器使用。
这是通过对编码器的每个隐藏状态进行加权。权重由简单的前馈神经网络确定。这些被称为注意力权重,或论文术语中的值。这是注意力权重的精彩解释的链接。论文中使用的一些术语是
- 查询 (Q) — 解码器的隐藏状态。
- Keys (K) — 编码器的隐藏状态。
- 值 (V) — 处理查询时的注意力权重。
从 Transformer-XL 集成到 XLNET 中。
- 位置编码 — 跟踪序列中每个标记的位置
- 分段循环——在每一层的内存中缓存第一个分段的隐藏状态,并相应地更新注意力。它允许重用每个段的内存。
6.XLNET — NLU 的广义自回归模型
XLNet是一个广义的自回归模型,其中下一个令牌依赖于所有先前的令牌。XLNET 是“通用的”,因为它通过一种称为“置换语言建模”的机制来捕获双向上下文。它融合了自回归模型和双向上下文建模的思想,同时克服了 BERT 的缺点。它在 20 个任务上的表现优于 BERT,通常在问答、自然语言推理、情感分析和文档排名等任务中表现出色。
置换语言建模 (PLM)
PLM 是通过在句子中所有可能的单词排列上训练自回归模型来捕获双向上下文的想法。XLNET 不是固定的左右或左右建模,而是在序列的所有可能排列上最大化预期的对数似然。在预期中,每个位置都学习利用来自所有位置的上下文信息,从而捕获双向上下文。不需要 [MASK],输入数据也不会损坏。
XLNET 与 BERT 的比较
例如,考虑“纽约是一座城市”这一行,我们需要预测“纽约”。让我们假设当前的排列是

BERT 会相互独立地预测令牌 4 和 5。而 XLNET 作为一个自回归模型,按照序列的顺序进行预测。即,首先预测token 4,然后预测token 5。
在这种情况下,XLNET 将计算
log P(New | is a city ) + log P(York | New, is a city )
而 BERT 会减少到
log P(New | is a city ) + log P(York | is a city )
7.使用 XLNET 进行的实验
以下是论文作者测试的数据集 XLNET。
- RACE 数据集——来自英语考试的 100K 题,XLNET 的准确率比最佳模型高出 7.6 分。
- SQuAD——阅读理解任务——XLNET 比 BERT 高出 7 个百分点。
- 文本分类——在各种数据集上显着优于 BERT(有关详细信息,请参阅论文)。
- GLUE 数据集——由 9 个 NLU 任务组成——纸上报告的数据,XLNET 优于 BERT。
- ClueWeb09-B 数据集——用于评估文档排名的性能,XLNET 优于 BERT。
论文的主要贡献是:
- XLNet是一种广义的AR预训练模型,仅结合了以GPT为代表的自回归(AR)模型和以BERT为代表的自编码器(AE)模型的优点。
- 为此,我们提出了置换语言建模目标和双流注意机制。
- 在各种 NLP 任务中,与以前的性能相比,最先进的性能得到了显着改善。
8.总结
XLNet使用了一种排列的自回归预训练方法。
参考文献
【1】Understanding XLNet - Borealis AI
【2】https://towardsdatascience.com/xlnet-explained-in-simple-terms-255b9fb2c97c
【3】[NLP 논문 리뷰] Xlnet: Generalized Autoregressive Pretraining for Language Understanding – Hansu Kim 【4】꼼꼼하고 이해하기 쉬운 XLNet 논문 리뷰 – 핑퐁팀 블로그

